Yandex opens ClickHouse
Today, the internal development of the company Yandex - analytical ClickHouse database , has become available to everyone. Sources are published on GitHub under the Apache 2.0 license.

ClickHouse allows you to perform analytical queries online using real-time updated data. The system can scale up to tens of trillion records and petabytes of stored data. Using ClickHouse opens up opportunities that were previously even hard to imagine: you can save the entire data stream without prior aggregation and quickly receive reports in any sections. ClickHouse was developed in Yandex for the tasks of Yandex. Metrics - the second largest web analytics system in the world.
In this article, we will explain how and why ClickHouse appeared in Yandex and what it can do; Let's compare it with other systems and show how to raise it in ourselves with minimal effort.
Why would someone need to use ClickHouse when there are many other technologies for working with big data?
')
If you just need to keep logs, you have many options. You can upload logs to Hadoop, analyze them using Hive, Spark or Impala. In this case, it is not at all necessary to use ClickHouse. Everything becomes more complicated if you need to perform online requests for non-aggregated data coming into the system in real time. To solve this problem, open technologies of suitable quality still did not exist.
There are separate areas in which other systems can be used. They can be classified as follows:
As part of the rather narrow niche in which ClickHouse is located, it still has no alternatives. Within the wider field of application, ClickHouse may be more profitable than other systems in terms of request processing speed , resource efficiency and ease of operation.

Map of clicks in Yandex. Metric and the corresponding request in ClickHouse
Initially, we developed ClickHouse exclusively for Yandex.Metrica tasks - in order to build reports interactively using non-aggregated logs of user actions. Due to the fact that the system is a full-fledged DBMS and has a very broad functionality, already at the beginning of its use in 2012, detailed documentation was written. This distinguishes ClickHouse from many typical internal developments — specialized and embedded data structures for solving specific problems, such as, for example, Metrage and OLAPServer, which I described in a previous article .
The developed functionality and availability of detailed documentation has led to the fact that ClickHouse has gradually spread to many departments of Yandex. Suddenly it turned out that the system can be installed according to the instructions and works out of the box, that is, does not require the involvement of developers. ClickHouse was used in Direct, Market, Mail, AdFox, Webmasters, in monitoring and in business analytics. ClickHouse allowed either to solve problems for which there were no suitable tools before, or to solve tasks by orders of magnitude more efficiently than other systems.
Gradually, there was a demand for the use of ClickHouse, not only in the internal products of Yandex. For example, in 2013, ClickHouse was used to analyze metadata about the events of the LHCb experiment at CERN . The system could be used more widely, but at the time this was hindered by a closed status. Another example: Yandex’s open-source Yandex.Tank technology uses ClickHouse for storing telemetry data, whereas for external users only MySQL was available as a database, which is poorly suited for this task.
As the user base expanded, it became necessary to spend a little more effort on the development, although not very much as compared to the effort required to solve the Metric tasks. But as a reward we get improved product quality, especially in terms of usability.
Expansion of the user base allows us to consider examples of use, which without this would hardly have occurred to me. It also allows you to quickly find bugs and inconveniences that are important, including for the main use of ClickHouse, in Metric. Without a doubt, all this improves the quality of the product. Therefore, it is beneficial for us to make ClickHouse open today.
Let's try working with ClickHouse on the example of “toy” open data - information on air travel in the United States from 1987 to 2015. This cannot be called big data (only 166 million lines, 63 GB of uncompressed data), but you can quickly download them and start experimenting. You can download data from here .
Data can also be downloaded from the source. How to do this is written here .
First, install ClickHouse on one server. Below you will also see how to install ClickHouse on a cluster with sharding and replication.
On Ubuntu and Debian Linux, you can install ClickHouse from prebuilt packages . On other Linux-based systems, you can build ClickHouse from source and install it yourself.
The clickhouse-client package contains the clickhouse-client program, a ClickHouse client for working interactively. The clickhouse-server-base package contains a clickhouse-server binary, and clickhouse-server-common contains configuration files for the server.
Server configuration files are in / etc / clickhouse-server /. The main thing you should pay attention to before starting work is the path element - the place where data is stored. It is not necessary to directly modify the config.xml file — this is not very convenient when updating packages. Instead, you can override the desired items in the files in the config.d directory .
It also makes sense to pay attention to the settings of access rights .
The server does not start itself when installing the package and does not restart itself when updating.
To start the server, run:
- /var/log/clickhouse-server/.
Ready for connections , .
, clickhouse-client.
MergeTree. MergeTree . , , .
, -, , , .
INSERT ClickHouse . O(1) . INSERT . . max_insert_block_size (= 1 048 576 ), : , . , , . exactly-once , , : , , . localhost, exactly-once .
INSERT MergeTree , SELECT. SELECT-.
, String , Enum . (: , ), , Enum- . (: , URL), String.
-, , Year, Quarter, Month, DayOfMonth, DayOfWeek, FlightDate. , , , . ClickHouse , . , : ClickHouse — , . — ClickHouse.
ClickHouse , . ClickHouse , , Distributed-.
Distributed- «» ClickHouse. SELECT- , . Distributed-, .
:
, :
Distributed- — , . Distributed- remote.
, , INSERT SELECT Distributed-.
, , , .
, - , , .
, . , -. ( .)
( ) ZooKeeper. ClickHouse . ZooKeeper .
ZooKeeper : , , . — ClickHouse .
, — .
, , — , . - , , — .
, ReplicatedMergeTree, ZooKeeper, , .
multi-master. , . , , . , . . .
, StackOverflow «clickhouse». clickhouse-feedback@yandex-team.ru. ClickHouse , . .
ClickHouse allows you to perform analytical queries online using real-time updated data. The system can scale up to tens of trillion records and petabytes of stored data. Using ClickHouse opens up opportunities that were previously even hard to imagine: you can save the entire data stream without prior aggregation and quickly receive reports in any sections. ClickHouse was developed in Yandex for the tasks of Yandex. Metrics - the second largest web analytics system in the world.
In this article, we will explain how and why ClickHouse appeared in Yandex and what it can do; Let's compare it with other systems and show how to raise it in ourselves with minimal effort.
Where is the ClickHouse niche
Why would someone need to use ClickHouse when there are many other technologies for working with big data?
')
If you just need to keep logs, you have many options. You can upload logs to Hadoop, analyze them using Hive, Spark or Impala. In this case, it is not at all necessary to use ClickHouse. Everything becomes more complicated if you need to perform online requests for non-aggregated data coming into the system in real time. To solve this problem, open technologies of suitable quality still did not exist.
There are separate areas in which other systems can be used. They can be classified as follows:
- Commercial OLAP DBMS for use in its own infrastructure.
Examples: HP Vertica , Actian Vector , Actian Matrix , EXASol , Sybase IQ and others.
Our differences: we made the technology open and free. - Cloud solutions.
Examples: Amazon Redshift and Google BigQuery .
Our differences: the client can use ClickHouse in its infrastructure and not pay for the clouds. - Add-ins over Hadoop.
Examples: Cloudera Impala , Spark SQL , Facebook Presto , Apache Drill .
Our differences:- Unlike Hadoop, ClickHouse allows you to serve analytical queries even as part of a publicly available public service such as Yandex.Metrica;
- ClickHouse does not need to deploy Hadoop infrastructure to function, it is easy to use, and even suitable for small projects;
- ClickHouse allows you to download data in real time and independently deals with their storage and indexing;
- Unlike Hadoop, ClickHouse works in geographically distributed data centers.
- Open-source OLAP DBMS.
Examples: InfiniDB , MonetDB , LucidDB .
The development of all these projects has been abandoned; they have never been mature enough and, in fact, never left the alpha version. These systems were not distributed, which is critical for processing large data. The active development of ClickHouse, the maturity of technology and the orientation to the practical needs arising from the processing of big data are provided by the tasks of Yandex. Without the use of “in combat” on real tasks that go beyond the capabilities of existing systems, it would be impossible to create a quality product. - Open-source systems for analytics, non-Relational OLAP DBMS.
Examples: Metamarkets Druid , Apache Kylin .
Our differences: ClickHouse does not require data pre-aggregation. ClickHouse supports the SQL language dialect and provides the convenience of relational databases.
As part of the rather narrow niche in which ClickHouse is located, it still has no alternatives. Within the wider field of application, ClickHouse may be more profitable than other systems in terms of request processing speed , resource efficiency and ease of operation.
Map of clicks in Yandex. Metric and the corresponding request in ClickHouse
Initially, we developed ClickHouse exclusively for Yandex.Metrica tasks - in order to build reports interactively using non-aggregated logs of user actions. Due to the fact that the system is a full-fledged DBMS and has a very broad functionality, already at the beginning of its use in 2012, detailed documentation was written. This distinguishes ClickHouse from many typical internal developments — specialized and embedded data structures for solving specific problems, such as, for example, Metrage and OLAPServer, which I described in a previous article .
The developed functionality and availability of detailed documentation has led to the fact that ClickHouse has gradually spread to many departments of Yandex. Suddenly it turned out that the system can be installed according to the instructions and works out of the box, that is, does not require the involvement of developers. ClickHouse was used in Direct, Market, Mail, AdFox, Webmasters, in monitoring and in business analytics. ClickHouse allowed either to solve problems for which there were no suitable tools before, or to solve tasks by orders of magnitude more efficiently than other systems.
Gradually, there was a demand for the use of ClickHouse, not only in the internal products of Yandex. For example, in 2013, ClickHouse was used to analyze metadata about the events of the LHCb experiment at CERN . The system could be used more widely, but at the time this was hindered by a closed status. Another example: Yandex’s open-source Yandex.Tank technology uses ClickHouse for storing telemetry data, whereas for external users only MySQL was available as a database, which is poorly suited for this task.
As the user base expanded, it became necessary to spend a little more effort on the development, although not very much as compared to the effort required to solve the Metric tasks. But as a reward we get improved product quality, especially in terms of usability.
Expansion of the user base allows us to consider examples of use, which without this would hardly have occurred to me. It also allows you to quickly find bugs and inconveniences that are important, including for the main use of ClickHouse, in Metric. Without a doubt, all this improves the quality of the product. Therefore, it is beneficial for us to make ClickHouse open today.
How to stop being afraid and start using ClickHouse
Let's try working with ClickHouse on the example of “toy” open data - information on air travel in the United States from 1987 to 2015. This cannot be called big data (only 166 million lines, 63 GB of uncompressed data), but you can quickly download them and start experimenting. You can download data from here .
Data can also be downloaded from the source. How to do this is written here .
First, install ClickHouse on one server. Below you will also see how to install ClickHouse on a cluster with sharding and replication.
On Ubuntu and Debian Linux, you can install ClickHouse from prebuilt packages . On other Linux-based systems, you can build ClickHouse from source and install it yourself.
The clickhouse-client package contains the clickhouse-client program, a ClickHouse client for working interactively. The clickhouse-server-base package contains a clickhouse-server binary, and clickhouse-server-common contains configuration files for the server.
Server configuration files are in / etc / clickhouse-server /. The main thing you should pay attention to before starting work is the path element - the place where data is stored. It is not necessary to directly modify the config.xml file — this is not very convenient when updating packages. Instead, you can override the desired items in the files in the config.d directory .
It also makes sense to pay attention to the settings of access rights .
The server does not start itself when installing the package and does not restart itself when updating.
To start the server, run:
sudo service clickhouse-server start- /var/log/clickhouse-server/.
Ready for connections , .
, clickhouse-client.
:
:
batch :
:
clickhouse-client
clickhouse-client --host=... --port=... --user=... --password=...
:
clickhouse-client -m
clickhouse-client --multiline
batch :
clickhouse-client --query='SELECT 1'
echo 'SELECT 1' | clickhouse-client
:
clickhouse-client --query='INSERT INTO table VALUES' < data.txt
clickhouse-client --query='INSERT INTO table FORMAT TabSeparated' < data.tsv
$ clickhouse-client --multiline
ClickHouse client version 0.0.53720.
Connecting to localhost:9000.
Connected to ClickHouse server version 0.0.53720.
:) CREATE TABLE ontime
(
Year UInt16,
Quarter UInt8,
Month UInt8,
DayofMonth UInt8,
DayOfWeek UInt8,
FlightDate Date,
UniqueCarrier FixedString(7),
AirlineID Int32,
Carrier FixedString(2),
TailNum String,
FlightNum String,
OriginAirportID Int32,
OriginAirportSeqID Int32,
OriginCityMarketID Int32,
Origin FixedString(5),
OriginCityName String,
OriginState FixedString(2),
OriginStateFips String,
OriginStateName String,
OriginWac Int32,
DestAirportID Int32,
DestAirportSeqID Int32,
DestCityMarketID Int32,
Dest FixedString(5),
DestCityName String,
DestState FixedString(2),
DestStateFips String,
DestStateName String,
DestWac Int32,
CRSDepTime Int32,
DepTime Int32,
DepDelay Int32,
DepDelayMinutes Int32,
DepDel15 Int32,
DepartureDelayGroups String,
DepTimeBlk String,
TaxiOut Int32,
WheelsOff Int32,
WheelsOn Int32,
TaxiIn Int32,
CRSArrTime Int32,
ArrTime Int32,
ArrDelay Int32,
ArrDelayMinutes Int32,
ArrDel15 Int32,
ArrivalDelayGroups Int32,
ArrTimeBlk String,
Cancelled UInt8,
CancellationCode FixedString(1),
Diverted UInt8,
CRSElapsedTime Int32,
ActualElapsedTime Int32,
AirTime Int32,
Flights Int32,
Distance Int32,
DistanceGroup UInt8,
CarrierDelay Int32,
WeatherDelay Int32,
NASDelay Int32,
SecurityDelay Int32,
LateAircraftDelay Int32,
FirstDepTime String,
TotalAddGTime String,
LongestAddGTime String,
DivAirportLandings String,
DivReachedDest String,
DivActualElapsedTime String,
DivArrDelay String,
DivDistance String,
Div1Airport String,
Div1AirportID Int32,
Div1AirportSeqID Int32,
Div1WheelsOn String,
Div1TotalGTime String,
Div1LongestGTime String,
Div1WheelsOff String,
Div1TailNum String,
Div2Airport String,
Div2AirportID Int32,
Div2AirportSeqID Int32,
Div2WheelsOn String,
Div2TotalGTime String,
Div2LongestGTime String,
Div2WheelsOff String,
Div2TailNum String,
Div3Airport String,
Div3AirportID Int32,
Div3AirportSeqID Int32,
Div3WheelsOn String,
Div3TotalGTime String,
Div3LongestGTime String,
Div3WheelsOff String,
Div3TailNum String,
Div4Airport String,
Div4AirportID Int32,
Div4AirportSeqID Int32,
Div4WheelsOn String,
Div4TotalGTime String,
Div4LongestGTime String,
Div4WheelsOff String,
Div4TailNum String,
Div5Airport String,
Div5AirportID Int32,
Div5AirportSeqID Int32,
Div5WheelsOn String,
Div5TotalGTime String,
Div5LongestGTime String,
Div5WheelsOff String,
Div5TailNum String
)
ENGINE = MergeTree(FlightDate, (Year, FlightDate), 8192);
MergeTree. MergeTree . , , .
, -, , , .
xz -v -c -d < ontime.csv.xz | clickhouse-client --query="INSERT INTO ontime FORMAT CSV"INSERT ClickHouse . O(1) . INSERT . . max_insert_block_size (= 1 048 576 ), : , . , , . exactly-once , , : , , . localhost, exactly-once .
INSERT MergeTree , SELECT. SELECT-.
, String , Enum . (: , ), , Enum- . (: , URL), String.
-, , Year, Quarter, Month, DayOfMonth, DayOfWeek, FlightDate. , , , . ClickHouse , . , : ClickHouse — , . — ClickHouse.
- 2015 ;
SELECT OriginCityName, DestCityName, count(*) AS flights, bar(flights, 0, 20000, 40) FROM ontime WHERE Year = 2015 GROUP BY OriginCityName, DestCityName ORDER BY flights DESC LIMIT 20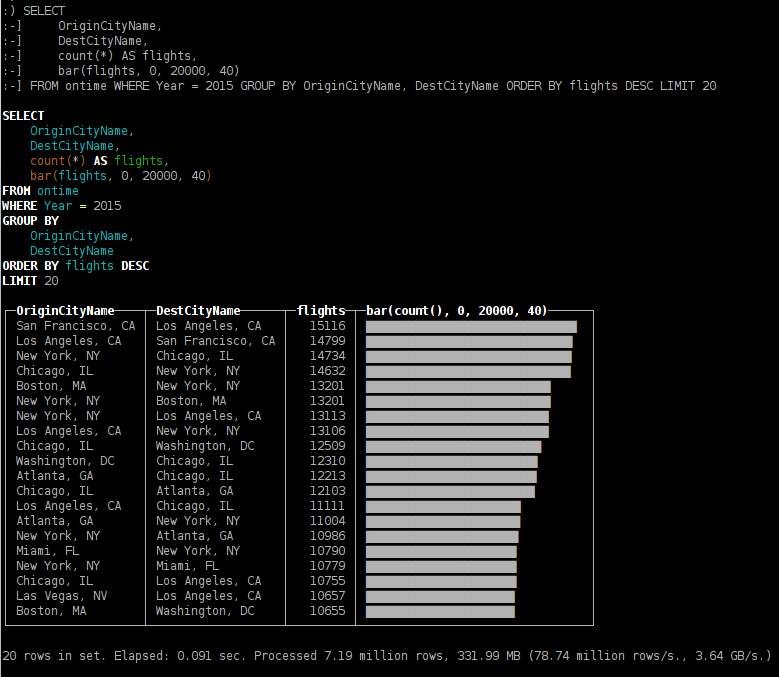
SELECT OriginCityName < DestCityName ? OriginCityName : DestCityName AS a, OriginCityName < DestCityName ? DestCityName : OriginCityName AS b, count(*) AS flights, bar(flights, 0, 40000, 40) FROM ontime WHERE Year = 2015 GROUP BY a, b ORDER BY flights DESC LIMIT 20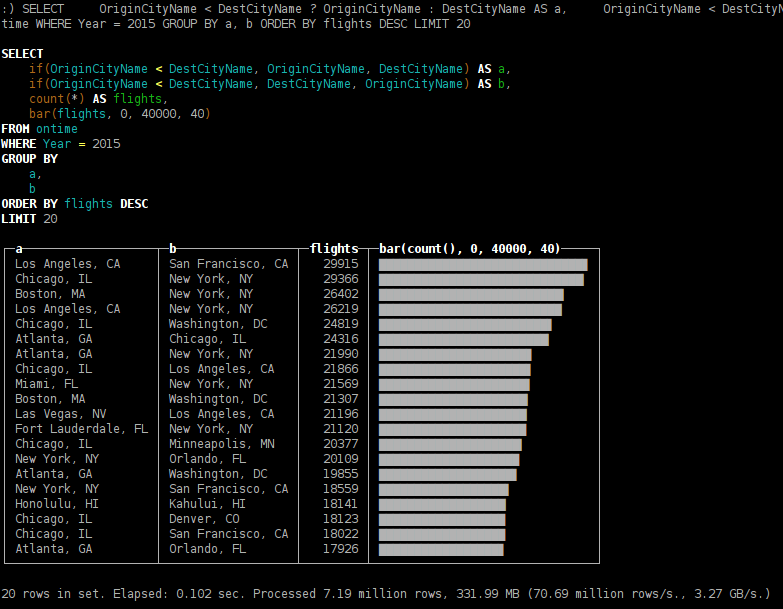
- ;
SELECT OriginCityName, count(*) AS flights FROM ontime GROUP BY OriginCityName ORDER BY flights DESC LIMIT 20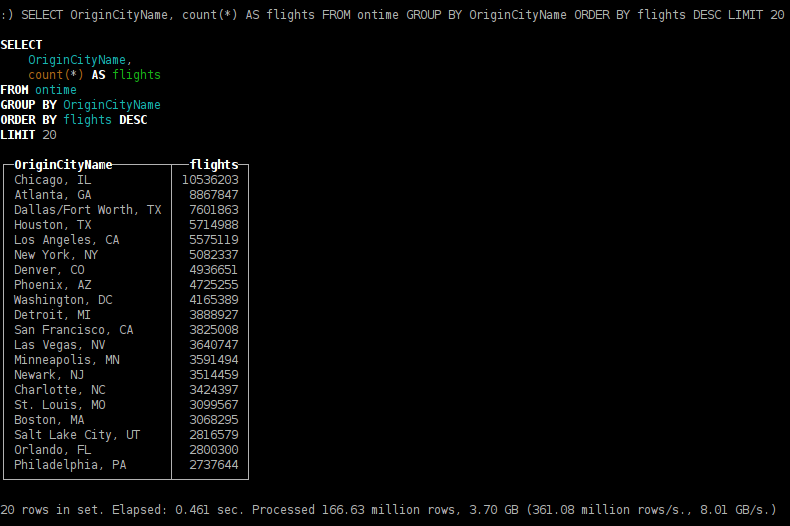
- ;
SELECT OriginCityName, uniq(Dest) AS u FROM ontime GROUP BY OriginCityName ORDER BY u DESC LIMIT 20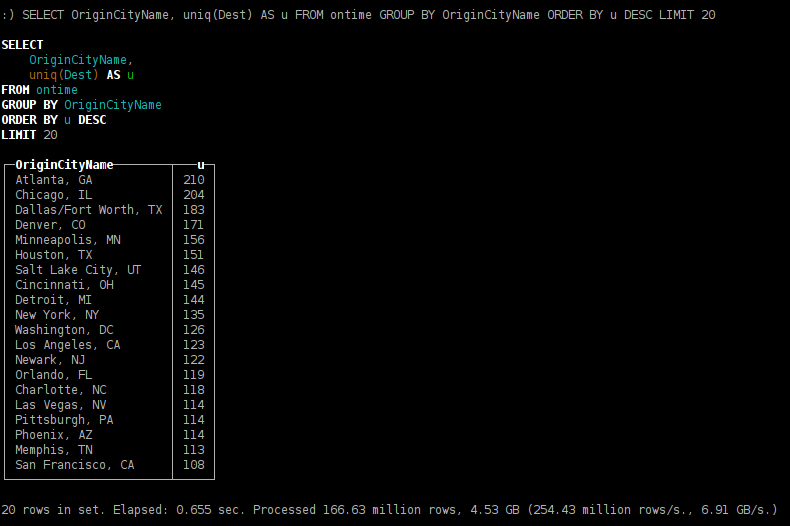
- ;
SELECT DayOfWeek, count() AS c, avg(DepDelay > 60) AS delays FROM ontime GROUP BY DayOfWeek ORDER BY DayOfWeek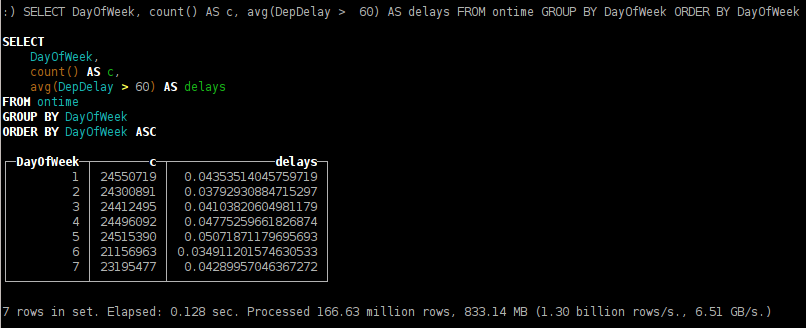
- , ;
SELECT OriginCityName, count() AS c, avg(DepDelay > 60) AS delays FROM ontime GROUP BY OriginCityName HAVING c > 100000 ORDER BY delays DESC LIMIT 20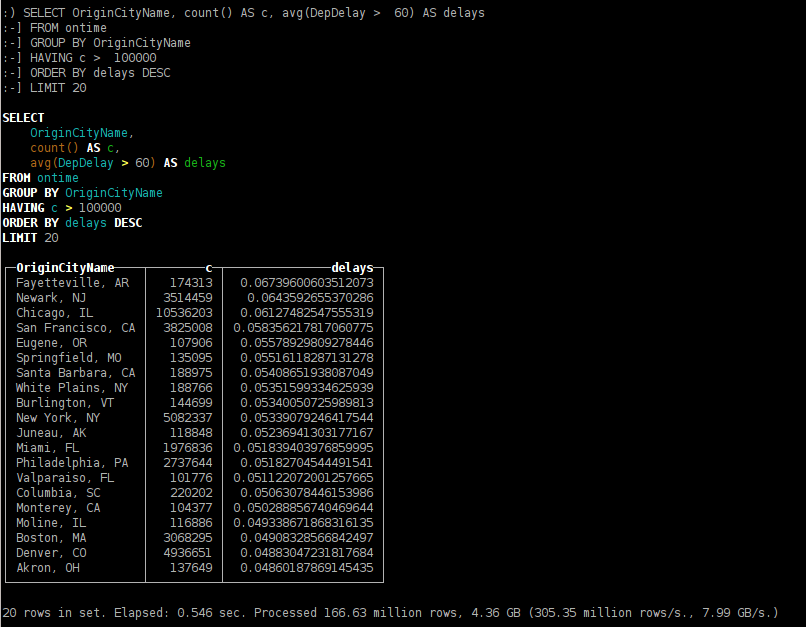
- ;
SELECT OriginCityName, DestCityName, count(*) AS flights, avg(AirTime) AS duration FROM ontime GROUP BY OriginCityName, DestCityName ORDER BY duration DESC LIMIT 20
- , ;
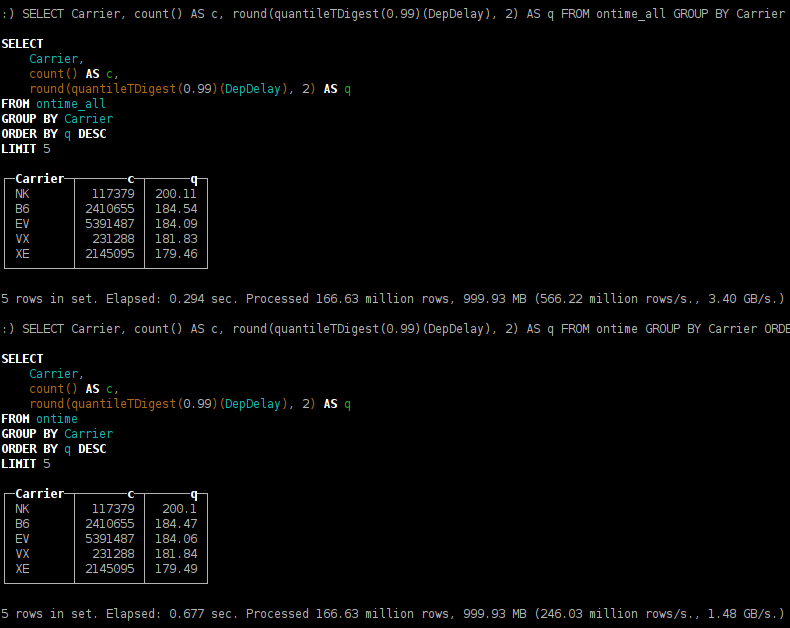
SELECT Carrier, count() AS c, round(quantileTDigest(0.99)(DepDelay), 2) AS q FROM ontime GROUP BY Carrier ORDER BY q DESC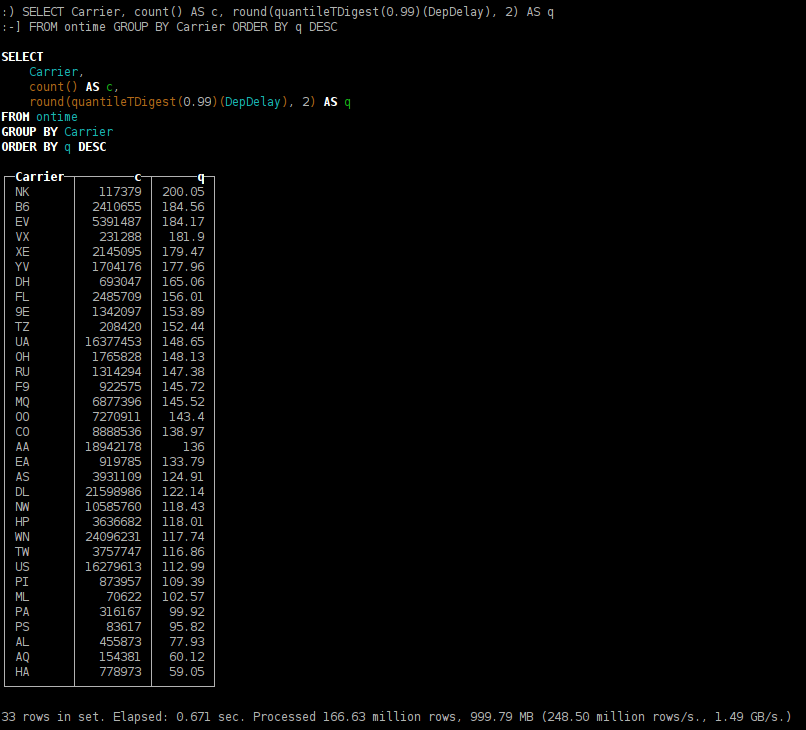
- ;
SELECT Carrier, min(Year), max(Year), count() FROM ontime GROUP BY Carrier HAVING max(Year) < 2015 ORDER BY count() DESC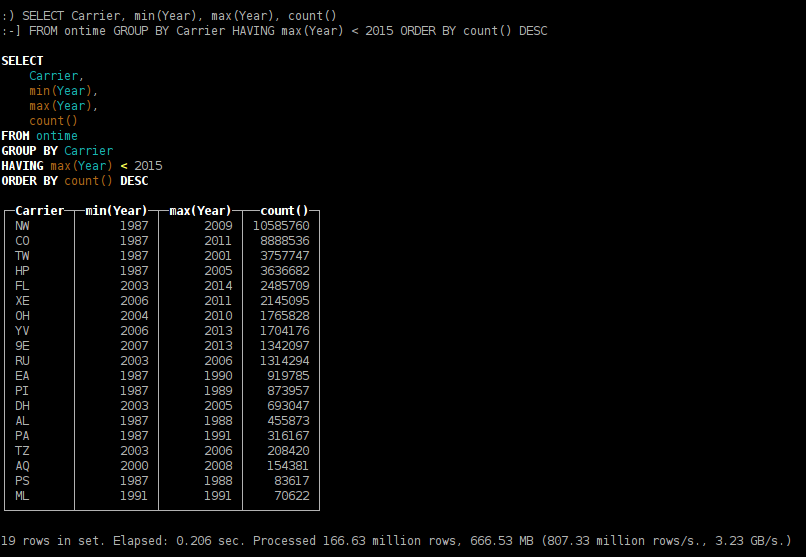
- 2015 ;
SELECT DestCityName, sum(Year = 2014) AS c2014, sum(Year = 2015) AS c2015, c2015 / c2014 AS diff FROM ontime WHERE Year IN (2014, 2015) GROUP BY DestCityName HAVING c2014 > 10000 AND c2015 > 1000 AND diff > 1 ORDER BY diff DESC
- .
SELECT DestCityName, any(total), avg(abs(monthly * 12 - total) / total) AS avg_month_diff FROM ( SELECT DestCityName, count() AS total FROM ontime GROUP BY DestCityName HAVING total > 100000 ) ALL INNER JOIN ( SELECT DestCityName, Month, count() AS monthly FROM ontime GROUP BY DestCityName, Month HAVING monthly > 10000 ) USING DestCityName GROUP BY DestCityName ORDER BY avg_month_diff DESC LIMIT 20
ClickHouse
ClickHouse , . ClickHouse , , Distributed-.
Distributed- «» ClickHouse. SELECT- , . Distributed-, .
,
<remote_servers>
<perftest_3shards_1replicas>
<shard>
<replica>
<host>example-perftest01j.yandex.ru</host>
<port>9000</port>
</replica>
</shard>
<shard>
<replica>
<host>example-perftest02j.yandex.ru</host>
<port>9000</port>
</replica>
</shard>
<shard>
<replica>
<host>example-perftest03j.yandex.ru</host>
<port>9000</port>
</replica>
</shard>
</perftest_3shards_1replicas>
</remote_servers>
:
CREATE TABLE ontime_local (...) ENGINE = MergeTree(FlightDate, (Year, FlightDate), 8192);, :
CREATE TABLE ontime_all AS ontime_local ENGINE = Distributed(perftest_3shards_1replicas, default, ontime_local, rand());Distributed- — , . Distributed- remote.
, , INSERT SELECT Distributed-.
INSERT INTO ontime_all SELECT * FROM ontime;, , , .
, - , , .
, . , -. ( .)
,
<remote_servers>
...
<perftest_1shards_3replicas>
<shard>
<replica>
<host>example-perftest01j.yandex.ru</host>
<port>9000</port>
</replica>
<replica>
<host>example-perftest02j.yandex.ru</host>
<port>9000</port>
</replica>
<replica>
<host>example-perftest03j.yandex.ru</host>
<port>9000</port>
</replica>
</shard>
</perftest_1shards_3replicas>
</remote_servers>
( ) ZooKeeper. ClickHouse . ZooKeeper .
ZooKeeper : , , . — ClickHouse .
ZooKeeper
<zookeeper-servers>
<node>
<host>zoo01.yandex.ru</host>
<port>2181</port>
</node>
<node>
<host>zoo02.yandex.ru</host>
<port>2181</port>
</node>
<node>
<host>zoo03.yandex.ru</host>
<port>2181</port>
</node>
</zookeeper-servers>
, — .
<macros>
<shard>01</shard>
<replica>01</replica>
</macros>
, , — , . - , , — .
CREATE TABLE ontime_replica (...)
ENGINE = ReplicatedMergeTree(
'/clickhouse_perftest/tables/{shard}/ontime',
'{replica}',
FlightDate,
(Year, FlightDate),
8192);
, ReplicatedMergeTree, ZooKeeper, , .
INSERT INTO ontime_replica SELECT * FROM ontime;multi-master. , . , , . , . . .
ClickHouse
, StackOverflow «clickhouse». clickhouse-feedback@yandex-team.ru. ClickHouse , . .
Source: https://habr.com/ru/post/303282/
All Articles