The evolution of neural networks for image recognition in Google: Inception-ResNet
I will slowly tell you about Inception.
The previous part here - https://habrahabr.ru/post/302242/ .
We stopped at the fact that Inception-v3 did not win the Imagenet Recognition Challange in 2015, because ResNets (Residual Networks) appeared.

Disclaimer: The post is written on the basis of the edited chat logs closedcircles.com , hence the style of presentation, and clarifying questions.
')
This is the result of the work of people at Microsoft Research Asia on the problem of training very deep networks ( http://arxiv.org/abs/1512.03385 ).
It is known that if you stupidly increase the number of levels in any VGG - it will start to get worse and worse, both in terms of accuracy on the training set, and on validation.
Which in a sense is strange - a deeper network has a strictly large representational power.
And, generally speaking, you can trivially get a deeper model that is not worse than a less deep one by stupidly adding several identity layers, that is, layers that simply let the signal through without changes. However, it is impossible to test in the usual way to such accuracy deep models.
This observation, which can always be made no worse than identity, is the main idea of ResNets.
Let's formulate the task so that deeper levels predict the difference between what previous leers give out and target, that is, they can always divert weights to 0 and just skip the signal.
Hence the name - Deep Residual Learning, that is, we learn how to predict deviations from past leers.
More specifically, it looks like this.
The main building block of the network is such a construction:
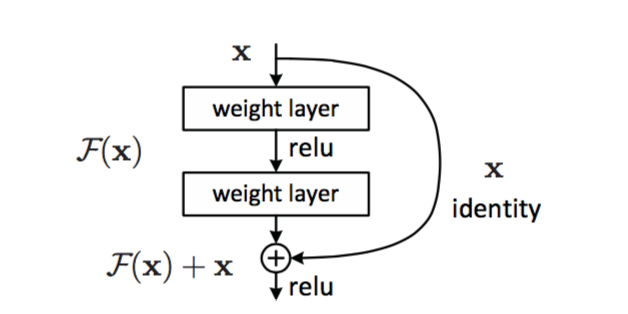
Two layers with scales (there can be convolution, there can be no), and a shortcut connection, which is stupid identity. The result after two leads is added to this identity. Why every two levels, but not every first? There is no explanation, apparently in practice it worked like this.
Therefore, if there is 0 everywhere in the scales of a certain level, it will simply pass on a pure signal.
And first, they build a version of VGG for 34 rails in which such blocks are inserted and all the rails are made smaller so as not to inflate the number of parameters.
It turns out that it trains well and shows better results than VGG!
How to develop success?
MOAR LAYERS !!!
In order to get more handrails, you need to make them easier - there is an idea instead of two convolutions to do for example one and smaller thickness:
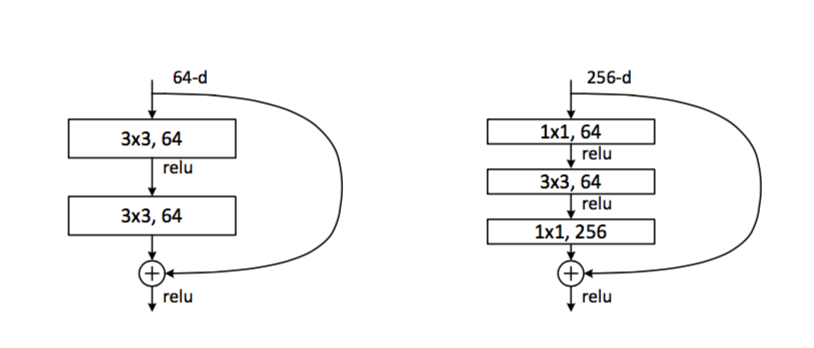
It was like on the left, let's do it like on the right. The number of calculations and parameters decreases radically.
And here the boys begin to shove and they begin to train the version for 101 and 152 (!) Lifts. Moreover, even in such ultra-deep networks the number of parameters is less than that of thick versions of VGG.
The final result on the ensemble, as mentioned earlier - 3.57% top5 on Imagenet.
Separately, it must be said that the region is actively developing and discussing the mechanisms of ResNets, combining the results of layers with arithmetic operations turned out to be a fertile idea.
Here are just a few examples:
http://torch.ch/blog/2016/02/04/resnets.html - Facebook guys are exploring where it is better to insert residual connections.
https://arxiv.org/abs/1605.06431 - the theory that ResNets is a huge ensemble of nested networks.
https://arxiv.org/abs/1605.07146 - using ResNets ideas for training very wide, not deep networks. By the way, the top result on CIFAR-10, for what it's worth.
https://arxiv.org/abs/1605.07648 - an attempt to construct and train deep networks without residual connections in their pure form, but still with arithmetic between the outputs of the layers.
The result of the work is Inception-v4 and Inception-Resnet ( http://arxiv.org/abs/1602.07261 )
Besides ResNets, the main thing that has changed is the appearance of TensorFlow.
The article says that before the TensorFlow, the Inception model did not fit into the memory of one machine, and it was necessary to train it distributedly, which limits the possibilities of optimization. But now you can not hold back the creative.
(I don’t really understand how exactly this happened, here’s a discussion of guesswork - https://closedcircles.com/chat?circle=14&msg=6207386 )
After this phrase, the boys stop explaining what caused changes in the architecture, and stupidly post three pages full of such pictures:
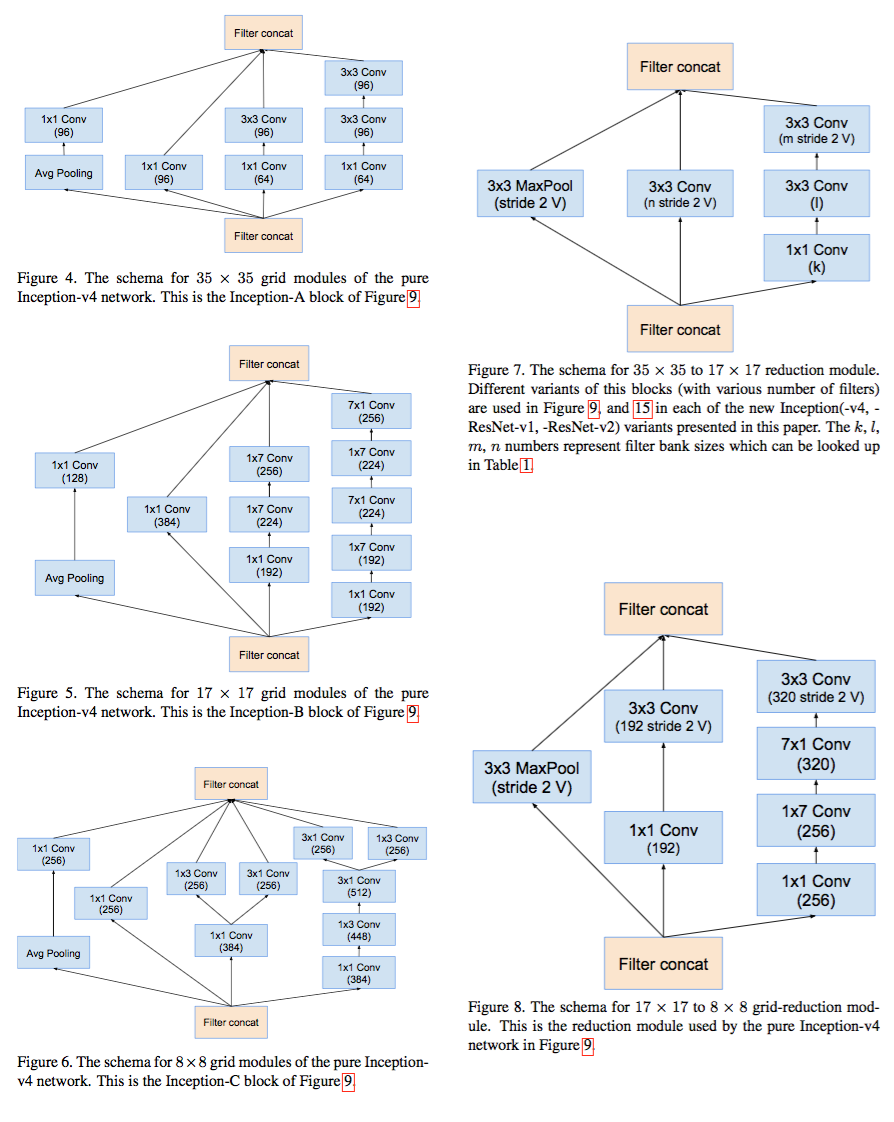
And I have a feeling that there are a lot of automation in building architecture there, but they are not scorching yet.
In general, they have Inception-v4, in which there are no Residual connections, and Inception-ResNet-2, which has a comparable number of parameters, but has residual connections. At the level of one model, their results are very close, ResNet wins a little bit.
But the ensemble of one v4 and three ResNet-2 shows a new record for Imagenet - 3.08%.
Let me remind you of past milestones. The first grid, which won the Imagenet Recongition challenge, did this with an error of 15% in 2012. At the end of 2015, it was finished to 3.08%. A reasonable estimate of the average result of a person is ~ 5%. Progress, I think, is impressive.
Initially, a very simple architecture with a set of convolution layers, followed by several fully connected layers, every year becomes more and more monstrous for the sake of efficiency. And perhaps there is one person who understands all the details of architectural micro decisions. Or maybe not already.
I didn’t find the complete Inception-ResNet architecture in one picture. Looks like it never occurred to anyone to draw it.
Funny detail unrelated to the rest - they often make non-padded convolutions, that is, convolution layers, which reduce the size of the image by 2 pixels from each side. Optimize bytes, practically!
The previous part here - https://habrahabr.ru/post/302242/ .
We stopped at the fact that Inception-v3 did not win the Imagenet Recognition Challange in 2015, because ResNets (Residual Networks) appeared.
What are ResNets in general?
Disclaimer: The post is written on the basis of the edited chat logs closedcircles.com , hence the style of presentation, and clarifying questions.
')
This is the result of the work of people at Microsoft Research Asia on the problem of training very deep networks ( http://arxiv.org/abs/1512.03385 ).
It is known that if you stupidly increase the number of levels in any VGG - it will start to get worse and worse, both in terms of accuracy on the training set, and on validation.
Which in a sense is strange - a deeper network has a strictly large representational power.
And, generally speaking, you can trivially get a deeper model that is not worse than a less deep one by stupidly adding several identity layers, that is, layers that simply let the signal through without changes. However, it is impossible to test in the usual way to such accuracy deep models.
This observation, which can always be made no worse than identity, is the main idea of ResNets.
Let's formulate the task so that deeper levels predict the difference between what previous leers give out and target, that is, they can always divert weights to 0 and just skip the signal.
Hence the name - Deep Residual Learning, that is, we learn how to predict deviations from past leers.
More specifically, it looks like this.
The main building block of the network is such a construction:
Two layers with scales (there can be convolution, there can be no), and a shortcut connection, which is stupid identity. The result after two leads is added to this identity. Why every two levels, but not every first? There is no explanation, apparently in practice it worked like this.
Therefore, if there is 0 everywhere in the scales of a certain level, it will simply pass on a pure signal.
And first, they build a version of VGG for 34 rails in which such blocks are inserted and all the rails are made smaller so as not to inflate the number of parameters.
It turns out that it trains well and shows better results than VGG!
How to develop success?
MOAR LAYERS !!!
In order to get more handrails, you need to make them easier - there is an idea instead of two convolutions to do for example one and smaller thickness:
It was like on the left, let's do it like on the right. The number of calculations and parameters decreases radically.
And here the boys begin to shove and they begin to train the version for 101 and 152 (!) Lifts. Moreover, even in such ultra-deep networks the number of parameters is less than that of thick versions of VGG.
The final result on the ensemble, as mentioned earlier - 3.57% top5 on Imagenet.
Wasn’t there the main idea that Vanishing Gradients is an acute problem in very deep networks, and the Residual architecture allows to solve it somehow?
This is a good question!
The authors of ResNets are investigating this issue to the best of their abilities, and it seems to them that the problem of vanishing gradients is well solved by sensible initialization and Batch Normalization. They look at the magnitude of the gradients that fall into the lower layers, it is generally reasonable and does not fade.
Their theory is that the deeper grids simply exponentially slower converge in the process of training, and therefore we simply do not have the time to wait for the same accuracy with the same computing resources.
the question is how does back propagation with an identity link work?
Transmits a unit, the usual derivative.
Separately, it must be said that the region is actively developing and discussing the mechanisms of ResNets, combining the results of layers with arithmetic operations turned out to be a fertile idea.
Here are just a few examples:
http://torch.ch/blog/2016/02/04/resnets.html - Facebook guys are exploring where it is better to insert residual connections.
https://arxiv.org/abs/1605.06431 - the theory that ResNets is a huge ensemble of nested networks.
https://arxiv.org/abs/1605.07146 - using ResNets ideas for training very wide, not deep networks. By the way, the top result on CIFAR-10, for what it's worth.
https://arxiv.org/abs/1605.07648 - an attempt to construct and train deep networks without residual connections in their pure form, but still with arithmetic between the outputs of the layers.
Well, men on Google look at this world and continue to work
The result of the work is Inception-v4 and Inception-Resnet ( http://arxiv.org/abs/1602.07261 )
Besides ResNets, the main thing that has changed is the appearance of TensorFlow.
The article says that before the TensorFlow, the Inception model did not fit into the memory of one machine, and it was necessary to train it distributedly, which limits the possibilities of optimization. But now you can not hold back the creative.
(I don’t really understand how exactly this happened, here’s a discussion of guesswork - https://closedcircles.com/chat?circle=14&msg=6207386 )
After this phrase, the boys stop explaining what caused changes in the architecture, and stupidly post three pages full of such pictures:
And I have a feeling that there are a lot of automation in building architecture there, but they are not scorching yet.
In general, they have Inception-v4, in which there are no Residual connections, and Inception-ResNet-2, which has a comparable number of parameters, but has residual connections. At the level of one model, their results are very close, ResNet wins a little bit.
But the ensemble of one v4 and three ResNet-2 shows a new record for Imagenet - 3.08%.
Let me remind you of past milestones. The first grid, which won the Imagenet Recongition challenge, did this with an error of 15% in 2012. At the end of 2015, it was finished to 3.08%. A reasonable estimate of the average result of a person is ~ 5%. Progress, I think, is impressive.
Overall, Inception is an example of applied R & D in the world of deep learning.
Initially, a very simple architecture with a set of convolution layers, followed by several fully connected layers, every year becomes more and more monstrous for the sake of efficiency. And perhaps there is one person who understands all the details of architectural micro decisions. Or maybe not already.
I didn’t find the complete Inception-ResNet architecture in one picture. Looks like it never occurred to anyone to draw it.
The full diagram on page 7, Fig. 15, only there all the layers are not painted in their entirety, but simply in blocks. I think otherwise only the paperman would have to be printed, but I wouldn't add much understanding.
I meant that the full accuracy of the final blocks. For past versions, I post such pictures.
There will be a picture three times wider :)
Yes Yes.
Funny detail unrelated to the rest - they often make non-padded convolutions, that is, convolution layers, which reduce the size of the image by 2 pixels from each side. Optimize bytes, practically!
you are comparing strange things. the human result is top1, and komputterny is top5 when 5 suitable categories are selected. in the top1, the results are still somewhere around double digits ...
No, human is also top5. Top1 people on imagenet also have nothing to do, too much uncertainty.
Here is an example -
What class does this picture have? For example, there are classes "horse" and "woman's clothing".
But the correct answer, of course, is "hay".
good luck with top1.
of course. hay something how much. and women with a horse barely!

Source: https://habr.com/ru/post/303196/
All Articles