Pitfalls when using Linked Server
A rather interesting project has come to our company related to processing the queue of tasks. The project was previously developed by another team. We needed to deal with the problems that arise when a large load on the queue, and, accordingly, to correct the found.
In short, the project consists of several databases and applications located on different servers. The “task” in this project is a stored procedure or .Net application. Accordingly, the “task” should be performed on a specific database and on a specific server.

All data that pertains to the queue is stored on a dedicated server. On servers where tasks need to be performed, only metadata is stored, i.e. procedures, functions, and service data related to this server. Accordingly, we receive the data relating to tasks by inquiries using LinkedServer.
')
All data that pertains to the queue is stored on a dedicated server. On servers where tasks need to be performed, only metadata is stored, i.e. procedures, functions, and service data related to this server. Accordingly, we receive the data relating to tasks by inquiries using LinkedServer.
The following are the two most popular classic queue processing methods:
Initially, the project was implemented the second option. To minimize the waiting time for processing tasks, our application polls the queue every 100-500ms.
Actually, this is nothing terrible and there is no one except for this: with such an implementation, the table is once again blocked. I will say in advance that the query uses row lock with the ability to only read unlocked rows:
So back to the problem. In the analysis, I noticed the value of the counter - batch requests / sec in Active Monitor. This value, with a small number (about 50) of the tasks in the queue, went off scale beyond 1000, and the CPU load increased sharply.
First thought: you need to go to the implementation of the first option (sending a notification to the task handler). This method was implemented using Service Broker and SignalR :
This tool is already used in the project, and the dates have been compressed, so I did not implement something similar, for example, NServiceBus .
There was no limit to my surprise when this decision did not help. Yes, a performance gain was obtained, but this did not completely solve the problem. A stress test was written for debugging, when more than 500 tasks are added to the queue.
The creation of such a stress test allowed us to find the " root of evil ."
Analysis of the list of active queries and performance reports, during a heavy load of showing the presence of "very interesting queries", which consisted of one command:
Further analysis revealed that these are requests from LinkedServer. The question immediately arose: “Is this type of select * from RemoteServer.RemoteDatabase.dbo.RemoteTable where the FieldId = Value generates a request (fetch api_cursor000000000000000003) on the RemoteServer?” It turns out, yes, even when LinkedServer is MS SQL.
For a more illustrative example, create a “Test” table (the table creation code is available in the appendix to the article) on the server “A”, and on the server “B” we will run the query:
where dev2 is our server “A”.
When you first perform such a request, we will have a similar log in the profiler on server A:
And now let's execute the queries already by ID:
As you can see in the screenshot, the query plan has been added to the cache. If you perform this query a second time, then a little better.
As we can see, the data is already taken from the cache.
When conditions change, we will get a similar sample - the first sample according to the specified Id . But the bottom line is that with large numbers of different cache requests are not enough. And sql begins to fence a bunch of queries to the table, which leads to "brakes". You ask: “But what about the indices?” There are indices, but requests, even with the Primary Key (PK) condition, caused this problem.
And what does Google say about this? And a lot of things, just no use:
More sensible answers were found only in 3 articles:
As far as I understood, you cannot configure LinkedServer to always use Pull technology to get data from LinkedServer. It all depends on where you are processing the request.
Time was running out, and the only solution that could save us was to rewrite part of the queries for dynamic sql. Those. perform queries on the server where the data is stored.
There are several ways to work with data on LinkedServer:
The fourth method was used to solve the problem.
Below are some graphs of incoming and outgoing traffic on the server where the main base of the queue is located before and after using sp_executesql. The size of the database is 200-300Mb.
Outgoing peaks are copying backup to NFS.
The conclusion suggests itself: initially the MS driver for working with “MS sql linked server” cannot execute queries on the data source server itself. Therefore, colleagues, let's try to perform them at the data source, to solve at least some of the performance issues.
Files for the article.
In short, the project consists of several databases and applications located on different servers. The “task” in this project is a stored procedure or .Net application. Accordingly, the “task” should be performed on a specific database and on a specific server.
All data that pertains to the queue is stored on a dedicated server. On servers where tasks need to be performed, only metadata is stored, i.e. procedures, functions, and service data related to this server. Accordingly, we receive the data relating to tasks by inquiries using LinkedServer.
')
All data that pertains to the queue is stored on a dedicated server. On servers where tasks need to be performed, only metadata is stored, i.e. procedures, functions, and service data related to this server. Accordingly, we receive the data relating to tasks by inquiries using LinkedServer.
Why is that?
- Convenience. We can indicate at any time that data is now stored on server B.
- So it was implemented before us.
The following are the two most popular classic queue processing methods:
- Send a notification to the task handler about the presence of the task.
- To poll the queue for the presence of tasks.
Initially, the project was implemented the second option. To minimize the waiting time for processing tasks, our application polls the queue every 100-500ms.
Actually, this is nothing terrible and there is no one except for this: with such an implementation, the table is once again blocked. I will say in advance that the query uses row lock with the ability to only read unlocked rows:
READPAST, ROWLOCK, UPDLOCK So back to the problem. In the analysis, I noticed the value of the counter - batch requests / sec in Active Monitor. This value, with a small number (about 50) of the tasks in the queue, went off scale beyond 1000, and the CPU load increased sharply.
First thought: you need to go to the implementation of the first option (sending a notification to the task handler). This method was implemented using Service Broker and SignalR :
- Service Broker used to send a notification when a task appeared;
- SignalR was used to send notifications to task handlers.
Why SignalR?
This tool is already used in the project, and the dates have been compressed, so I did not implement something similar, for example, NServiceBus .
There was no limit to my surprise when this decision did not help. Yes, a performance gain was obtained, but this did not completely solve the problem. A stress test was written for debugging, when more than 500 tasks are added to the queue.
The creation of such a stress test allowed us to find the " root of evil ."
Analysis of the list of active queries and performance reports, during a heavy load of showing the presence of "very interesting queries", which consisted of one command:
fetch api_cursor0000000000000003 Further analysis revealed that these are requests from LinkedServer. The question immediately arose: “Is this type of select * from RemoteServer.RemoteDatabase.dbo.RemoteTable where the FieldId = Value generates a request (fetch api_cursor000000000000000003) on the RemoteServer?” It turns out, yes, even when LinkedServer is MS SQL.
For a more illustrative example, create a “Test” table (the table creation code is available in the appendix to the article) on the server “A”, and on the server “B” we will run the query:
select * from dev2.test_db.dbo.test where dev2 is our server “A”.
When you first perform such a request, we will have a similar log in the profiler on server A:
Part of the log on server A
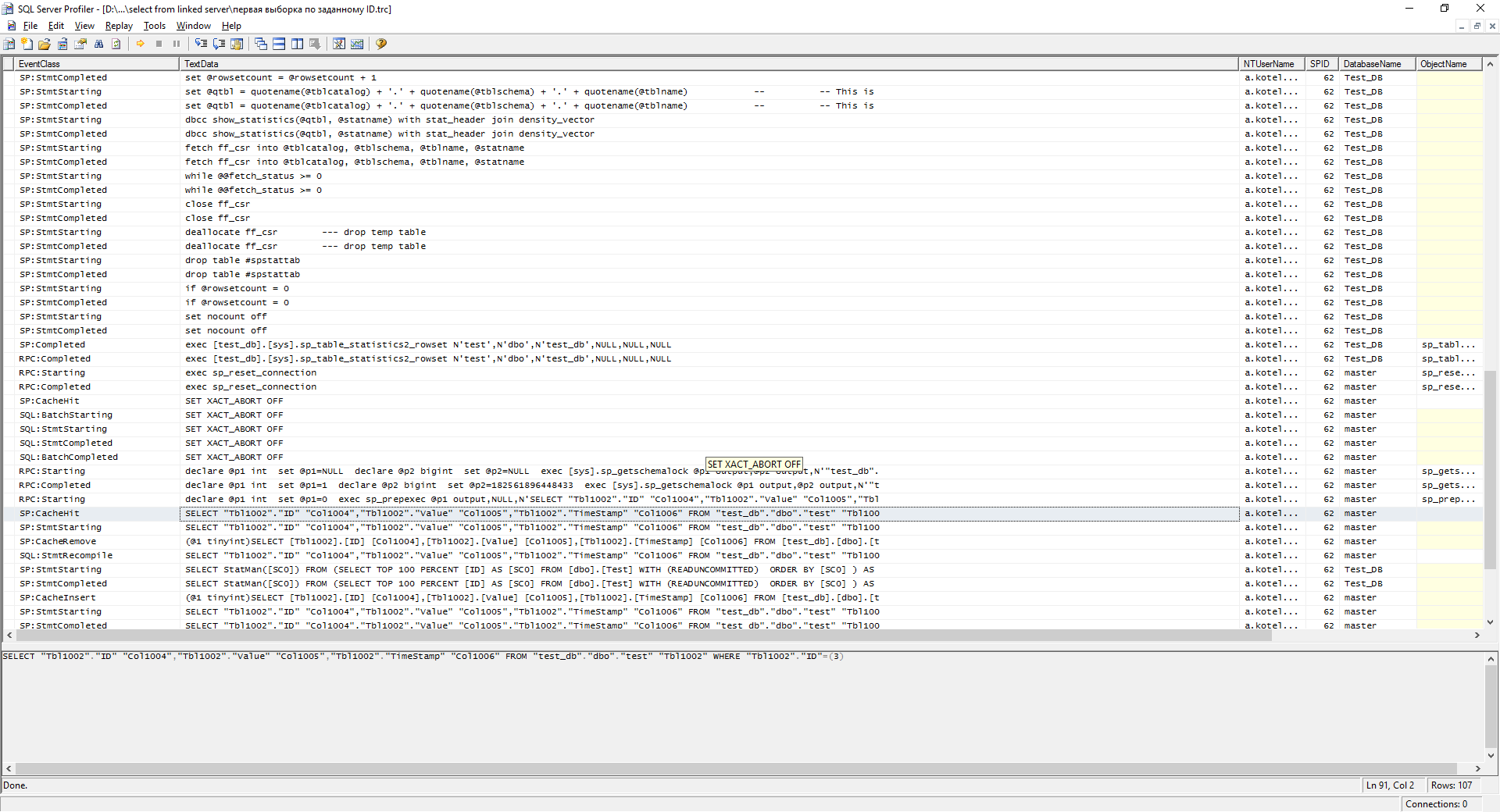
And now let's execute the queries already by ID:
select * from dev2.test_db.dbo.test where ID = 3 Profiler log for the second request

As you can see in the screenshot, the query plan has been added to the cache. If you perform this query a second time, then a little better.
profiler log after restart
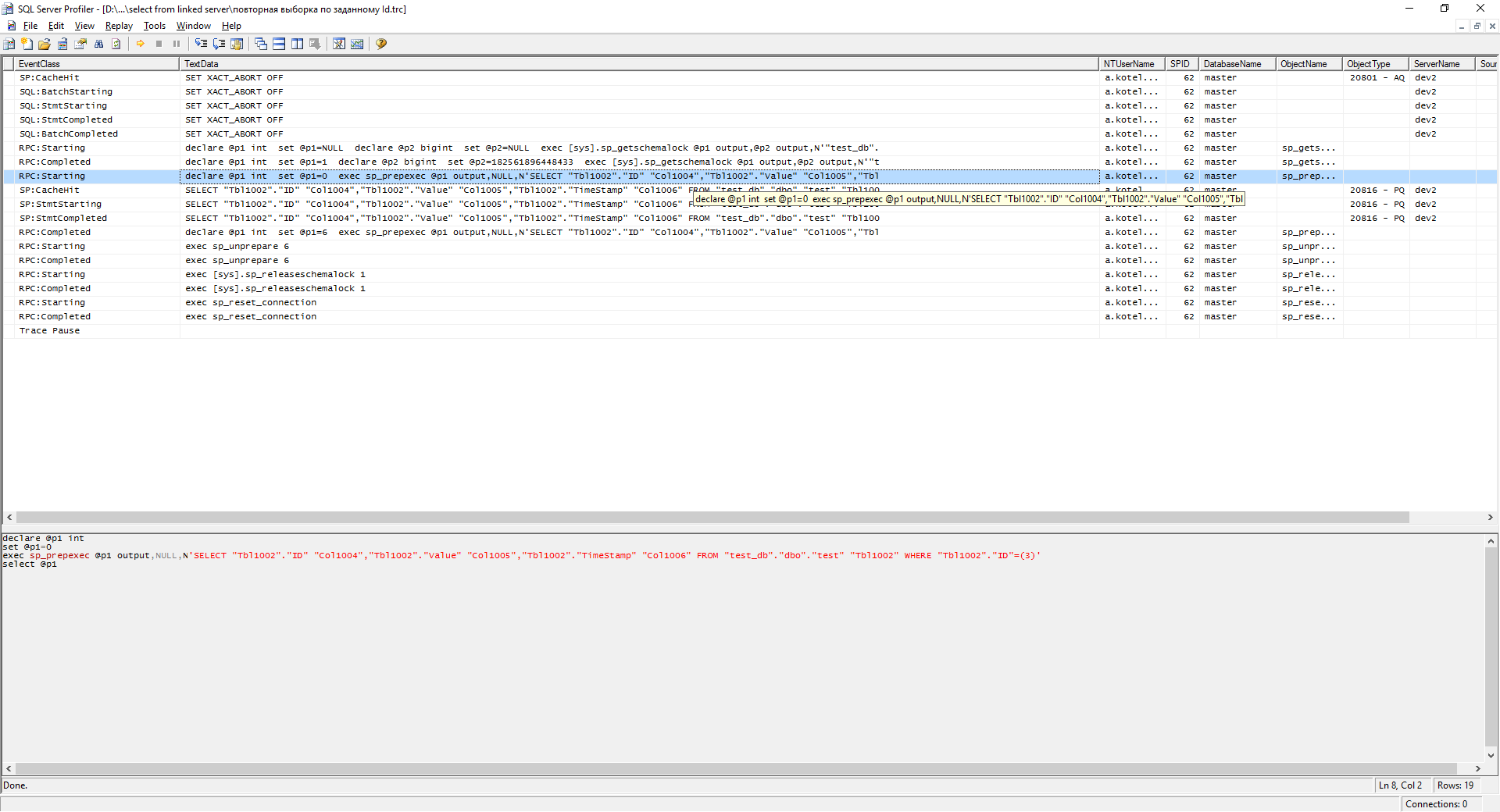
As we can see, the data is already taken from the cache.
When conditions change, we will get a similar sample - the first sample according to the specified Id . But the bottom line is that with large numbers of different cache requests are not enough. And sql begins to fence a bunch of queries to the table, which leads to "brakes". You ask: “But what about the indices?” There are indices, but requests, even with the Primary Key (PK) condition, caused this problem.
And what does Google say about this? And a lot of things, just no use:
- That requests must be executed from a user who belongs to one of the following roles: sysadmin, db_owner, db_ddladmin, so that you can use statistics;
- Incorrectly configured LinkedServer.
More sensible answers were found only in 3 articles:
- Exposing API Server Cursors
- Top 3 Performance Killers For Linked Server Queries
- Push and Pull technologies when working with linked servers in Microsoft SQL Server
As far as I understood, you cannot configure LinkedServer to always use Pull technology to get data from LinkedServer. It all depends on where you are processing the request.
Time was running out, and the only solution that could save us was to rewrite part of the queries for dynamic sql. Those. perform queries on the server where the data is stored.
There are several ways to work with data on LinkedServer:
- In the request directly specify the data source - the remote server. This implementation has several drawbacks:
- low productivity;
- returns a large amount of data.
select * from RemoteServer.RemoteDatabase.dbo.RemoteTable where Id = @Id - Use OPENQUERY. Not suitable for several reasons:
- Cannot specify the name of the remote server as a parameter;
- pass parameters to the request;
- there are also problems that were described in the Dynamic T-SQL article and how it can be useful
select * from OPENQUERY(RemoteServer, 'select * from RemoteDatabase.dbo.RemoteTable').
The links are examples of logs for the following requests. These requests will be executed on server “B”, and logs from server “A”:select * from OPENQUERY(dev2, 'select * from test_db.dbo.test') where id = 26select * from OPENQUERY(dev2, 'select * from test_db.dbo.test where ID = 26') - Run a query on a remote server. Similar to OPENQUERY:
- You cannot specify the server name as a parameter, since the name is set at the stage of the procedure compilation;
- there are also problems that were described in the Dynamic T-SQL article and how it can be useful
exec ('select * from RemoteDatabase.dbo.RemoteTable') at RemoteServer
The links are examples of logs for the following requests:exec ('select * from test_db.dbo.test') at dev2exec ('select * from test_db.dbo.test where Id = 30') at dev2- exec at server / Client side with given Id.trc
- exec at server / On the server side with the specified Id.trc
- It is still possible to execute the query on a remote server by running sp_executesql.
DECLARE @C_SP_CMD nvarchar(50) = QUOTENAME(@RemoteServer) + N'.'+@RemoteDatabase +N'.sys.sp_executesql' DECLARE @C_SQL_CMD nvarchar(4000) = 'select * from dbo.RemoteTable' EXEC @C_SP_CMD @C_SQL_CMD
The links are examples of logs of query execution using sp_executesql:- sp_executesql / Full fetch on client.trc
- sp_executesql / Full server side vybrka.trc
- sp_executesql / Fetching by Id on client.trc
- sp_executesql / Fetching by Id on server.trc
The fourth method was used to solve the problem.
Below are some graphs of incoming and outgoing traffic on the server where the main base of the queue is located before and after using sp_executesql. The size of the database is 200-300Mb.
incoming and outgoing traffic for several days on the server, before using sp_executesql
incoming and outgoing traffic after using sp_executesql
Outgoing peaks are copying backup to NFS.
The conclusion suggests itself: initially the MS driver for working with “MS sql linked server” cannot execute queries on the data source server itself. Therefore, colleagues, let's try to perform them at the data source, to solve at least some of the performance issues.
Files for the article.
Source: https://habr.com/ru/post/302958/
All Articles