Selecting and configuring the Garbage Collector for Highload system in the Hotspot JVM

Introduction
When working in the field of RTB (Real Time Bidding), one of the key characteristics is the time taken to display an advertisement to a user who has visited the site. It consists of several stages, one of which is an auction for an advertising space held by the Supply Side Platform SSP between several DSP (Demand Side Platform) systems. In this case, the critical value is the time over which the DSP will have time to respond with its inventory and cash rate for the given show. As a rule, the upper limit of this time is approximately 100 milliseconds. Given that the optimal performance of advertising campaigns requires tens of thousands of requests per second, the implementation of this requirement can be a very trivial task.
Our Ad Server, responsible for the core work of GetIntent DSP, is designed in Java and runs on the standard Hotspot JVM, which has well-known garbage collection (GC) mechanisms. Therefore, the best option lies in the analysis of exactly how the work with memory occurs, and as a result, the selection of the most appropriate garbage collection algorithm and its optimal tuning. This will be discussed in this article.
In aggregate, our expected result is the maximum balance between the number of servers (the smaller, the better) and the total duration and frequency of GC pauses, during which we can lose potential impressions.
')
How we tested
For testing, 2 workstations were used. On the first one, the JVM started with:
-Xmx4500m On the second:
-Xmx12g JVM Version: Oracle 1.8.0_66-b17
CMS (Concurrent Mark Sweep) and G1 (Garbage First) garbage collectors were compared
Testing was carried out within 16 hours on a load that is fully consistent with the combat.
CMS (Concurrent Mark Sweep)
CMS allows you to significantly reduce delays associated with garbage collection. However, its use inevitably faces two main problems, which create the need for additional configuration:
- Memory fragmentation
- High allocation rate
You can positively influence the first parameter by controlling the promotion rate of the indicator. To do this, it is necessary to determine how many objects fall into the Tenured, and what “dies young” in the Eden area.
Testing was performed with the following parameters:
-XX:+UseConcMarkSweepGC -XX:NewRatio=1, 3, 5 for logging were used:
-XX:+PrintGCDetails -XX:+PrintGC -XX:+PrintGCTimeStamps -XX:+PrintTenuringDistribution -XX:+PrintGCDateStamps -XX:+PrintCMSInitiationStatistics -XX:PrintCMSStatistics=1 G1 (Garbage First)
G1 GC looks like a tempting choice for the RTB bidder, as its main goal is to maintain stable and predictable Stop The World (STW) pauses. It also determines the simplicity and clarity of its settings. In fact, it is necessary to operate with only one parameter - the maximum allowed STW pause duration: -XX: MaxGCPauseMillis
In our case, in order to eliminate random long pauses, you can donate a small amount of throughput.
Regarding G1 GC, since its appearance as a garbage collector available for experiments, some prejudices have been formed, the main one being that MaxGCPauseMillis is not maintained. There is also a recommendation voiced by Oracle to use it on fairly large heap sizes (> = 6 Gb).
How all this is relevant, we learn after our testing. We will also spend some time on such an exclusive G1 GC function as String Deduplication.
Testing was performed with the following parameters:
-XX:+UseG1GC -XX:MaxGCPauseMillis=100, 60, 40 Additionally tests were carried out with the parameter:
-XX:MaxTenuringThreshold=8 for logging were used:
-XX:+PrintGCDetails -XX:+PrintGC -XX:+PrintGCTimeStamps -XX:+PrintTenuringDistribution -XX:+PrintGCDateStamps -XX:+PrintAdaptiveSizePolicy -XX:+PrintReferenceGC Max Heap Size 4.5Gb
Pivot table distribution Stop The World pauses:

The clear winner in this configuration is the CMS with the flag
-XX:NewRatio=5 As you can see, despite the pauses ms / sec indicator of this configuration is slightly worse than the others, it still shows itself as the most stable - ~ 12 ms average pause and almost 98% fit into the norm - an excellent result for us. With such indicators on one Full GC for 16 hours, you can close your eyes.
The latency distribution graph for the best G1 and CMS performance:

CMS results analysis
We experimented with parameter sets in which the size of Eden (-XX: NewRatio) was 1/2, 1/4, and 1/6 of the total memory size. The average promotion rate for these configurations was distributed accordingly: 1.7, 2.75 and 2.79 mb / sec, which is quite logical - the smaller the size of Eden, the more debris manages to seep directly into the Old Gen. As you can see, from a certain point on, the size of the Eden area begins to have little effect on this indicator. In our case, we can sacrifice a higher promotion rate (as a result, more frequent OldGen assemblies and a high probability of fragmentation) for the lowest possible average delay during the operation of the application.
G1 Results Analysis
It can be seen that G1 is closely in such a small heap. Mixed pauses are very frequent.
-XX: MaxGCPauseMillis has little effect on the final result, and the configuration with the desired 40ms pause could not do without Full GC.
However, there is another point that confused us. By default, G1 selects 15 ages for the Survivor area. We decided to see if we really need so much:
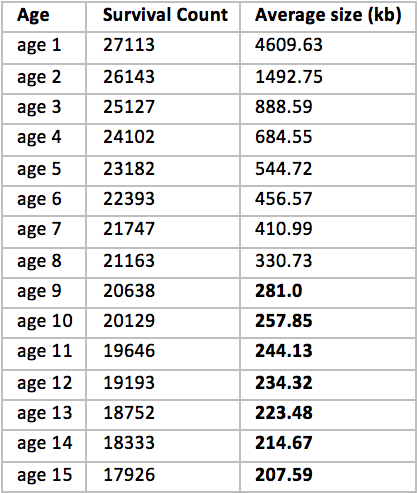
Obviously a strange sign. Starting from about age 8, the size always remains at about the same level; this suggests that these are long-lived objects that are likely to fall into the Tenured area anyway, and before that at every minor assembly we just pour it from empty to empty, whereas we could immediately put all this in OldGen. A good solution is to set MaxTenuringThreshold = 8.
However, in the case of heap 4.5Gb, we did not notice a big difference in the results, so for brevity we omit them. See if something changes on a big heap.
Max Heap Size 12Gb
Pivot table distribution Stop-the-World pauses:

The composition of the representatives of the G1 has changed slightly, because MaxTenuringThreshold = 8 (in the table mtt = 8) in this configuration began to bring noticeable results.
On the big heap, the G1 spread its wings and stepped forward both in the overall distribution of pauses and in the very short maximum pause. The average time spent on the GC was less than 7ms every second, i.e. less than 0.7%
The latency distribution graph for the best G1 and CMS performance:

CMS results analysis
It is believed that the main problem of CMS is a matter of scalability. Our testing confirms this. Almost all indicators are worse than when using a small heap. From the advantages it can be noted that due to the larger memory capacity, the effects of fragmentation are noticeably lower here - not a single Full GC during the whole experiment.
G1 Results Analysis
The result clearly shows that the G1 is indeed much more stable on large amounts of memory; The conditions specified in the settings are quite clearly fulfilled. Here is the undisputed winner with 40 ms latency. The average pause increased by only 3 ms, while the memory size increased almost 2.4 times! What to say about the ms / sec indicator is twice as good.
G1 String Deduplication
Since our bidder works with the text OpenRTB protocol, writes a lot of string logs, stores string caches, etc., it is quite logical to expect a big effect from this new function. In theory, the number of garbage collections should be reduced, while the average assembly time will increase. We added this flag for configuration with MaxGCPauseMillis = 100ms and Xmx = 4500m:

Although the average pause is within the specified limits, the number of pauses exceeding 1000ms exceeded the permissible limits. This can be seen on the chart:

Attempts to set a shorter pause time led to a very strong increase in CPU consumption. It was decided to abandon the use of this parameter.
Results
We conducted a detailed analysis of CMS and G1 garbage collectors, whose main goal was to understand how much we can reduce the impact of GC on latency - the most critical indicator for our system.
Quite an expected result - there are no unambiguous conclusions here. For a VM with a memory size of 5Gb, the winner is a CMS with the -XX configuration: NewRatio = 5; despite the large maximum pause, during the life of the application, it showed a more stable result, better percentile and average delay. However, on a VM with a heap of 12Gb G1, it is far ahead of CMS, which justifies the recommendations of Oracle; ms / sec delay is 1.94 times better, max pause is 13.3 times!
Thanks to this research, we could no longer work blindly, guided only by individual recommendations and heterogeneous opinions; on the contrary, we were able to find the perfect balance for our heterogeneous system in terms of system configuration, obtaining maximum stability and, as a result, profit from what we have today.
Article authors - absorbb and dmart28
Source: https://habr.com/ru/post/302910/
All Articles