The future of browsers and artificial intelligence. Zen in Yandex Browser
In the future, it seems to us, all popular browsers will go beyond the scope of programs to open web pages and learn to better understand the people who use them. Today I will tell you how we see this future on the example of a personalized Zen ribbon in Yandex. Browser, which is now available to users of Windows, Android and iOS.
Despite the seeming simplicity, rather complex technologies are at the heart of Zen. I will tell you a little about how this is implemented in our country, where and why we used traditional machine learning, and where - neural networks and artificial intelligence, and I will be grateful for your opinion on this approach.
')
The recommendations are well known to all who actively use the network. Online stores offer similar products. Online movie theaters advise movies. Music, books, games, applications - in any niche you can find examples of such solutions. In the modern world, where the amount of information is growing exponentially, recommendations help people find something new and interesting.
Yandex has always specialized in search. In the broad sense of the word. Find answers to your questions. Search for the best route. And even search for a free taxi near you. About two years ago, we had another idea. Teach the car to search the network for the content that would be of interest to a particular person. Personalized search, where as a query are not words, but interests. From this idea was born the tape of recommended Zen content.
Zen is an endless tape of content, which is formed on the basis of the interests of a particular person. We want to help users find interesting content, and to publishers - targeted traffic (click on the recommendations opens the material on the original site). Usually, stories about new products start with a description of ideology and product strategy, and here I recommend that you read the post of Roman kukutz Ivanov on the Yandex blog , and you and I will immediately move on to the most important for Habr, to technologies. Especially since it is they who distinguish Zen in Yandex. Browser from any other browser (and not only) analogues.

By the way, an attentive reader may recall that the first experiments with Zen were carried out in 2015 on the zen.yandex.ru page. Why is the recommendation feed now part of the Browser? This time I’ll answer the question a bit later.
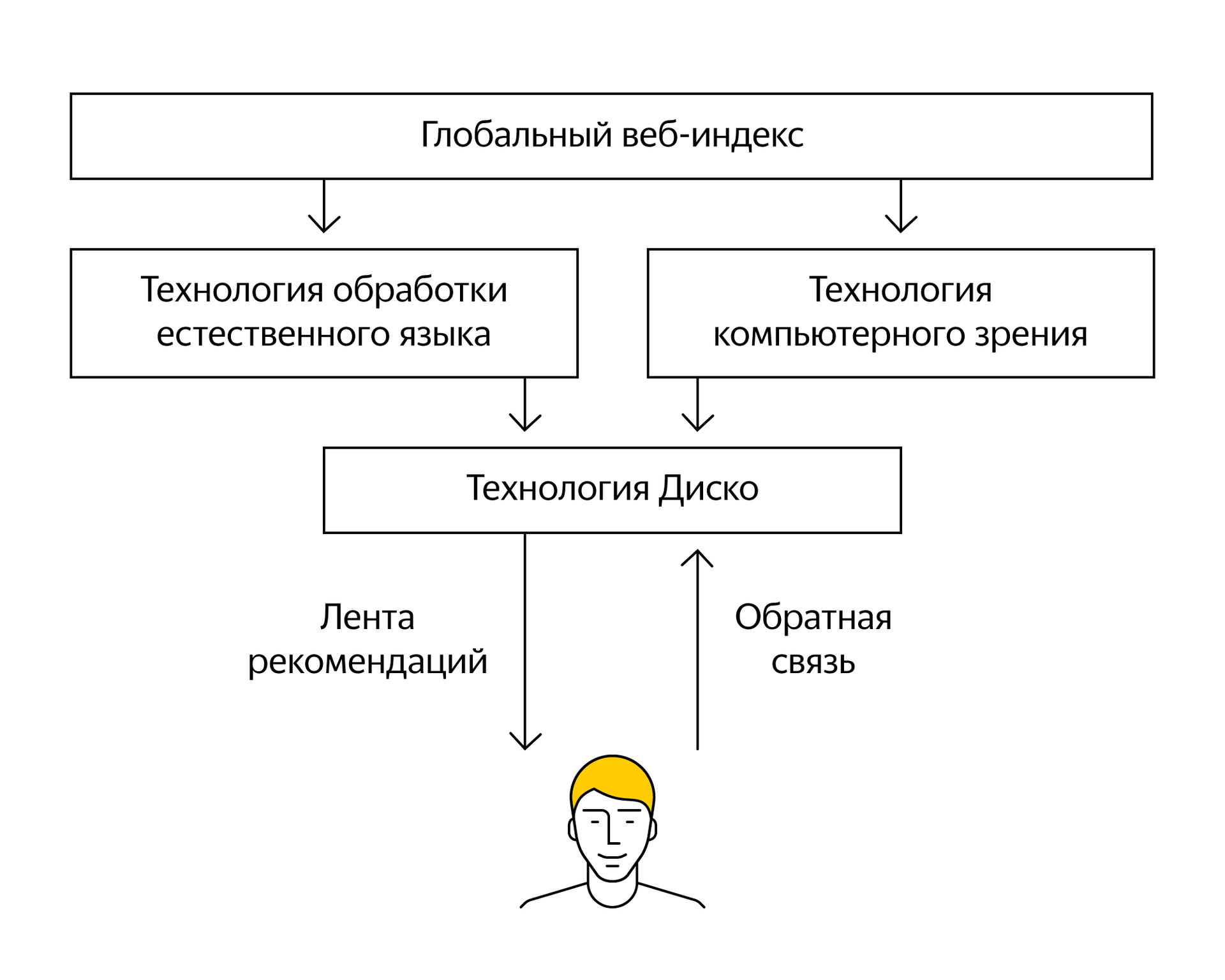
Zen is based on Disco's recommender technology, developed in Yandex and already used in Yandex.Music and Yandex.Market. The word "disco" is consonant with the English word discovery, which means "discovery of the new" and well describes the essence of technology.
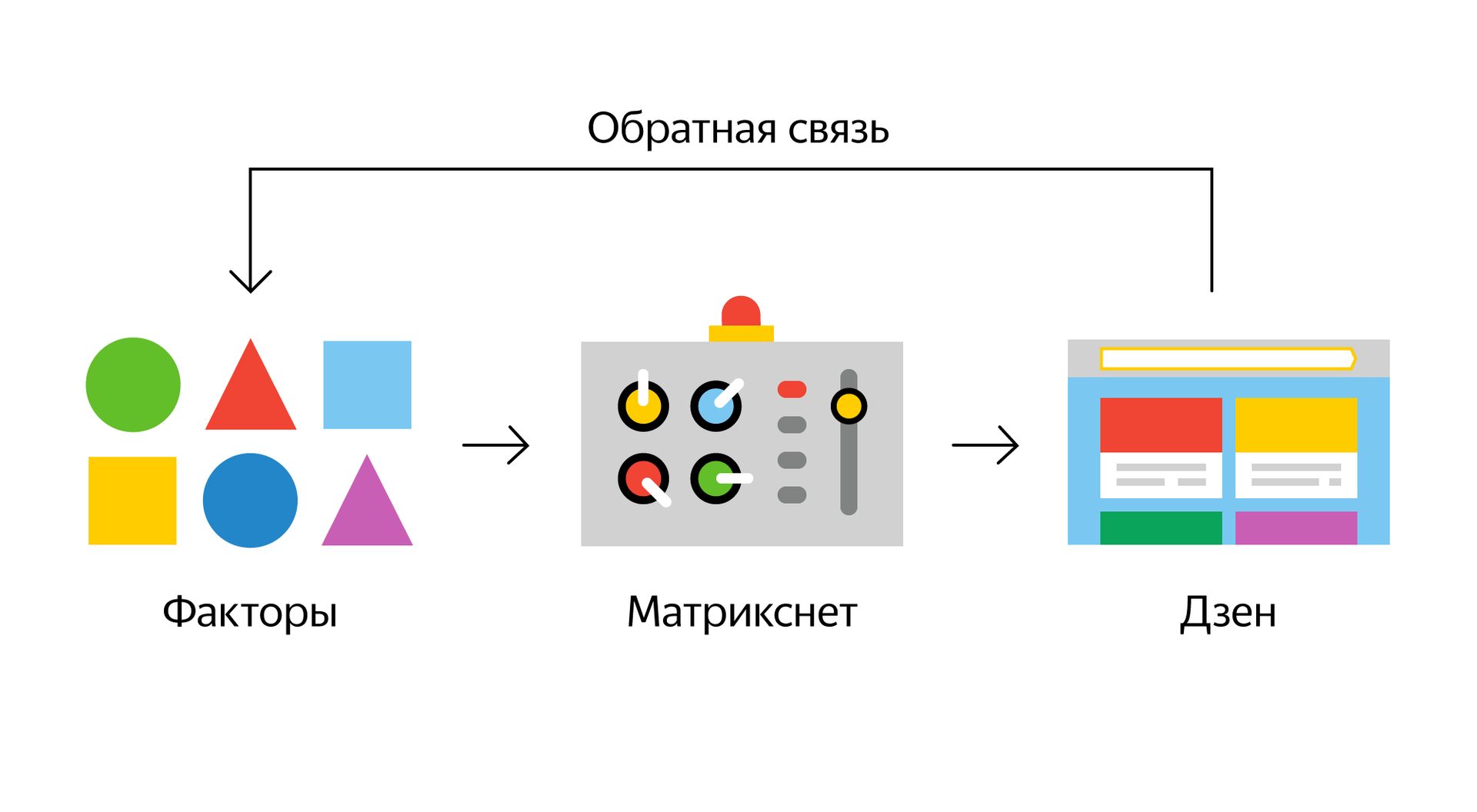
A simplified logical scheme for the disco in the case of Zen looks like this:
Let's start from the very beginning, with the initial data, which have yet to somehow turn into factors.
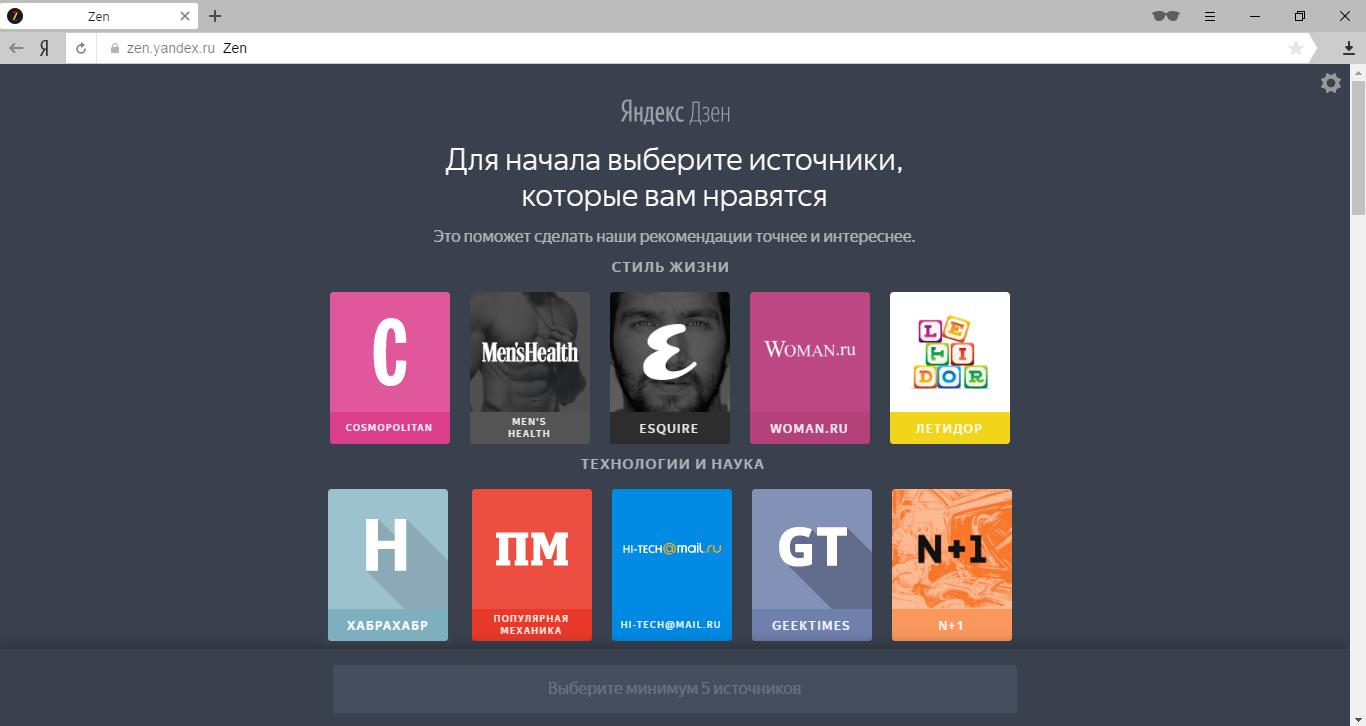
Before advising a person, you need to understand his interests and preferences. Zen for this uses knowledge of Yandex about the sites visited by people. Thanks to this knowledge, many new users of Zen will be able to immediately see the tape of personal recommendations without the need to customize something. But sometimes they are not enough. One could try to solve this problem with a tape that focuses on the average person. But we know that such a person does not exist in reality (which was well shown by the example of the American air force). Therefore, we went the other way and suggested that people independently limit their interests. These settings do not have their own name, but inside we call them “Onboarding”.
It is important to understand that Onboarding is not an obligatory stage of initial settings, but only a backup option for those who have absolutely nothing to offer. The tape of recommendations immediately after the passage of Onboarding can be quite different from the compilations formed after a few weeks of active use of Zen. These settings are already available to users of Yandex. Browser for Android and iPhone. For Windows, they will be available soon (for now, you can use a temporary solution ).
Knowledge of a person’s interests is only half of the required information. In order to recommend something, you first need to find something. Usually, reference services solve this problem in a primitive way - they form a limited catalog of RSS feeds of interest. In the case of Zen, there are no such restrictions. Search robots are looking for any materials. This can be both author publications from popular blogs, as well as high-quality stories from forums or YouTube videos. This is what we call the wild web. The main thing is that the site was not abandoned and the page contained a sufficient amount of useful content.
So, on the one hand, we have knowledge about the favorite publications of millions of users, on the other - all the power of the global search index Yandex. It remains the most "simple". Teach the car to build recommendations.
In the history of recommender technologies, two of their main types are well known: content filtering and collaborative filtering. Let's start with the first one, which is based on comparing the contents of the recommended objects. For example, I propose to consider movies. If two films belong to the same genre, and the user has already praised one of them, then with a certain probability you can advise him and the second. And here it is interesting to recall the Netflix online cinema, which increased the number of genres from several hundred to tens of thousands , among which you can even find “Cult horror films with evil children.” Most of these genres are hidden from viewers and used only to build recommendations.
In our case, there are no genres. To make a conclusion about the compliance of a web page with the interests of a person, it is necessary to compare its content with known samples. And this should be done by a computer, which needs not only to read the material, but also to understand its meaning. And the only way to solve this problem accurately enough is to use the Yandex experience in the field of artificial intelligence.
When it comes to artificial intelligence, many users imagine SkyNet wishing to enslave humanity. Fortunately, the future is not predetermined and everything is in our hands. But seriously, the groundwork in the field of AI already helps us to solve complex problems. The ability of the machine to read, see, and, most importantly, understand the meaning opens up great prospects.
Natural language processing (Natural Language Processing, NLP) and computer vision (Computer Vision, CV) are two widely used directions in Zen from the field of artificial intelligence.
When we talk about recommendations, we mean to ourselves materials that would be sufficiently close in their semantic content to the user's samples. In other words, the machine should read two texts and make a conclusion: are they close in meaning or not. Exactly what we are learning to do. A specially trained neural network transforms the text into a vector, which contains the meaning of the text. Two texts can be written using different words and even in different languages, but they will have the same meaning. Comparing these vectors, we can with a certain probability predict a person’s interest in a new material. By the way, if the vectors almost coincide, then this already speaks of a semantic duplicate (rewriting of the text or different articles about the same event) with which we fight in the tape.
Another approach to NLP that the Zen team is working on is the automatic labeling of any text. Remember the example of Netflix and tens of thousands of genres. So it is here. The classification of publications using tags helps to improve the accuracy of the final recommendations.
Working with computer vision is generally similar to NLP. Only instead of reading the text, the machine learns to “look” and understand the meaning of the image. In addition to the direct application of the recommendations in computer vision, there are other tasks in Zen. For example, thumbnails of pictures are not always conveniently scaled, and they have to be cut off, and computer vision helps to find people in pictures and saves them from the fate of Ned Stark from Game of Thrones.
Computer vision is used to find the text in the pictures. Some sites like to duplicate the title as an image. In the tape, it does not look so beautiful, so these images are detected and not used as thumbnails. There is also such a difficult to explain concept, as the "quality" of the picture. The machine learns to choose on the site those images that are more popular with people, and uses them as all the same miniatures.
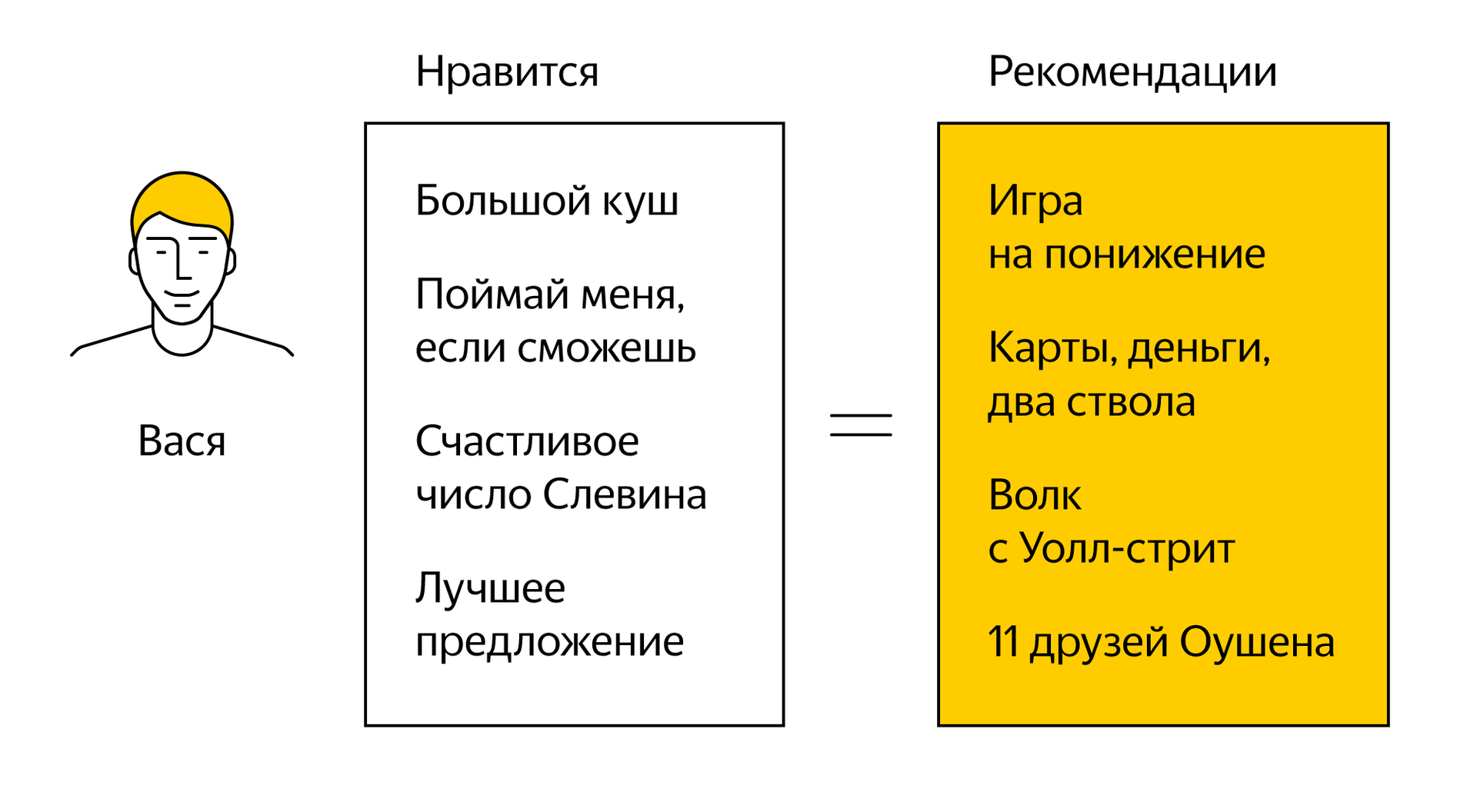
Above, I told you about the approach to building recommendations, which is based on filtering by the contents of objects. Now it's time to remember about collaborative filtering. At the core of this approach is the idea that similar people like similar objects. In this case, you do not need to know the properties of the recommended objects, it is enough to collect statistics about how they correspond to the interests of users. On the example of movies, it might look like
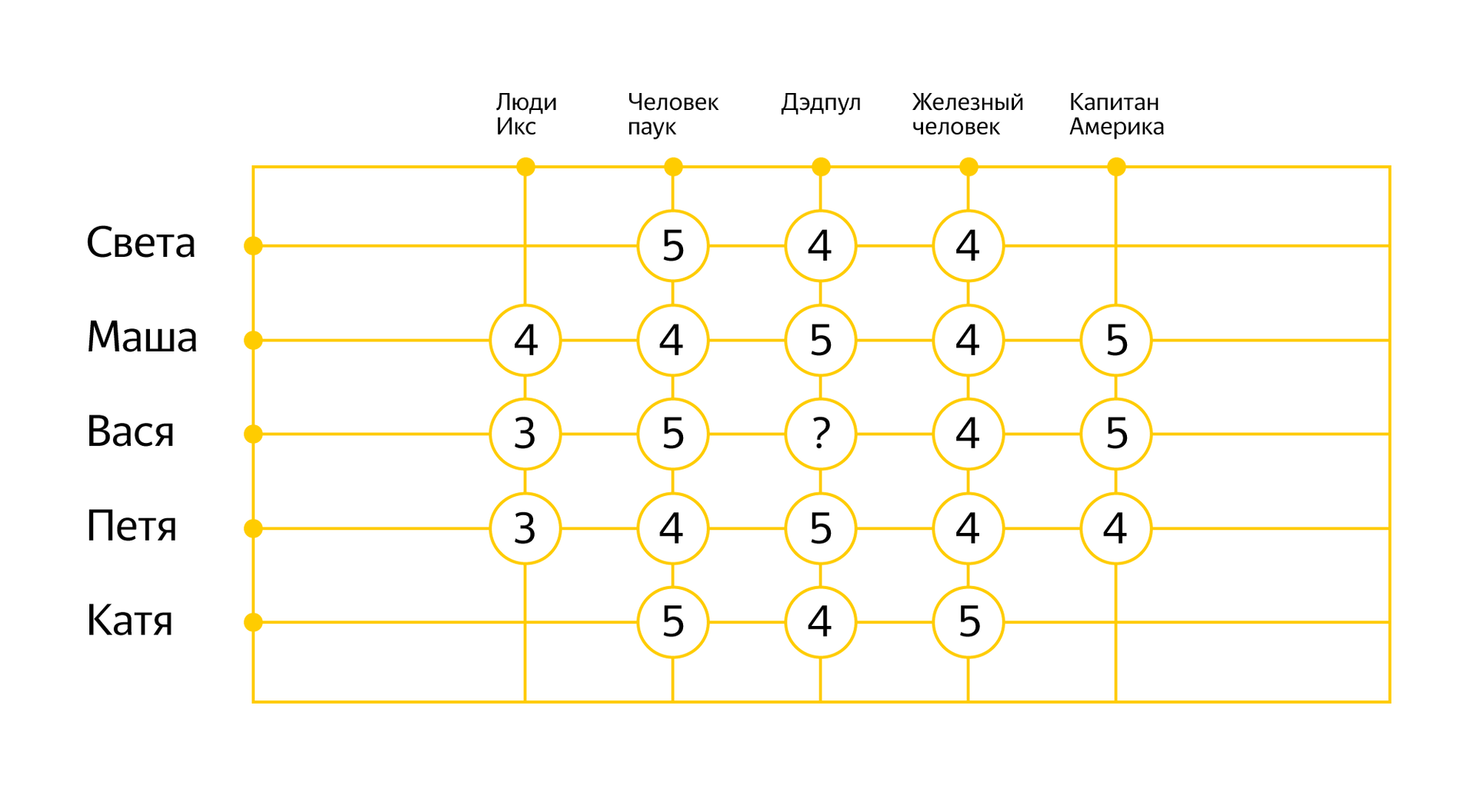
Based on already known estimates, it is possible to identify patterns in the behavior of different people and try to predict the reaction to a new film. At the mathematical level, various algorithms were invented for applying collaborative filtering, which my colleague Mikhail Roizner had a good talk about in his time at Habré.
In the case of Zen, we use collaborative filtering (or rather, the SVD algorithm) to predict a person’s interest in a particular site as a whole. This information complements the recommendations built for individual materials using artificial intelligence (NLP + CV). Allows you to weed out unnecessary noise and to identify non-trivial patterns (for example, it may turn out that people who are interested in Habr and the stories with Peek-a-boo read N + 1 more often than others).
To summarize Using the source data about the sites and users, we use the technologies of natural language processing, computer vision and the SVD algorithm to form a set of various factors that characterize a person’s interests in various sites / materials.
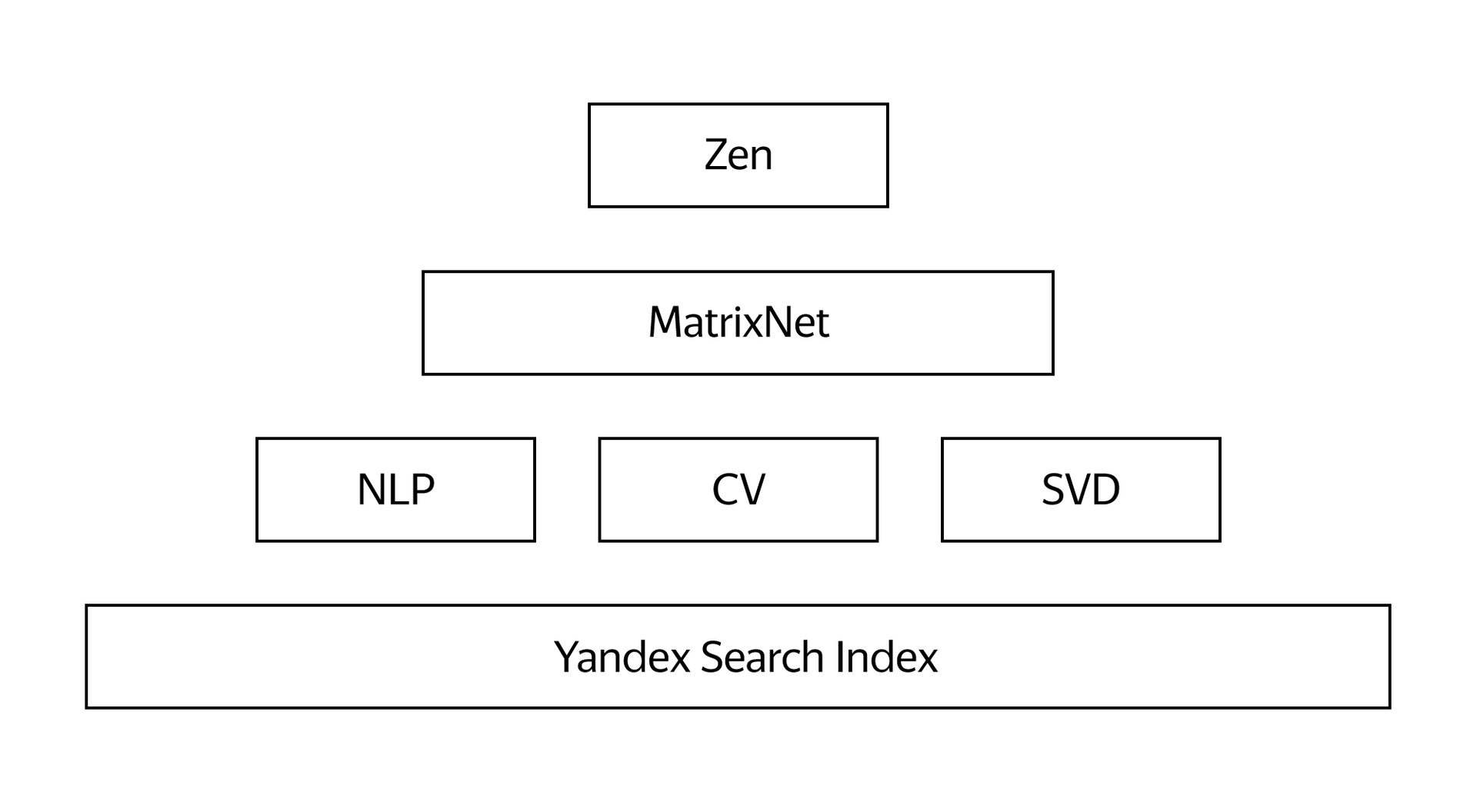
The accuracy of the final recommendations is directly dependent on the number and variety of input data, so many of our other knowledge is used as factors. For example, Yandex’s knowledge of a particular site or page, information about how a person uses Zen, his feedback in the form of clicks, “more such” and “less such”, location and even time of day. The total number of individual factors that we lay in the recommendation system is in the thousands. The complexity of the system reaches such a level that some algorithms are already small. We need a technology that will itself calculate the ideal formula for building the final tape. And here Yandex’s machine learning experience came in handy.
The term "machine learning" appeared in the 50s. It means an attempt to teach a computer to solve problems that are easily given to a person, but it is difficult to formalize the way to solve them. As a result of machine learning, a computer may exhibit behavior that was not explicitly incorporated into it.
Every day our search engine responds to millions of queries, many of which are non-recurring. Therefore, it is impossible to write such a program in which each request is provided and the best answer is known for each request. The search system should be able to make decisions on its own, that is, to choose from the millions of documents the one that best responds to the user. For this you need to teach her to learn.
Since 2009, Yandex search has been using Matrixnet’s own machine learning method. With it, you can build a very long and complex ranking formula, which takes into account many different factors and their combinations. In addition, MatrixNet itself determines different sensitivity for different values of ranking factors. This technology is quite versatile, so it subsequently found application not only in Yandex, but also in the European Center for Nuclear Research .
The ability of a computer to take into account thousands of factors and independently search for the best solution is something without which it is impossible to build a modern recommendation system. That is why MatrixNet was taken as the basis for creating its own recommender technology.
The result of the work of MatrixNet is exactly what the user sees in the Zen ribbon. On the part of the developers, there are no rules of the form “If a person loves A, then we recommend him B”. All such patterns are born and are constantly changing within the Matriksnet. And the more data he has, the more accurate the recommendations. That is why Zen is part of Yandex. Browser, and not an independent web service or application. A separate application is more difficult to understand the interests of the user, who, after two or three days, can simply stop running it. In order for Zen magic and machine learning to come into full force, they need to actively use or at least regularly run alongside. And the browser, as a single point of access to the Internet, is best suited for this. Of course, any user can opt out of using Zen in the Browser.
In this post, I told you about how the personal recommendation feed is formed in Yandex.Browser, and why Zen is not just another “news feed”, but the result of serious technology. Developments from the field of artificial intelligence now help the machine to understand the meaning of content and human interests. But this is only the beginning. Who knows, maybe one day computers will understand us better than ourselves?
Despite the seeming simplicity, rather complex technologies are at the heart of Zen. I will tell you a little about how this is implemented in our country, where and why we used traditional machine learning, and where - neural networks and artificial intelligence, and I will be grateful for your opinion on this approach.
')
The recommendations are well known to all who actively use the network. Online stores offer similar products. Online movie theaters advise movies. Music, books, games, applications - in any niche you can find examples of such solutions. In the modern world, where the amount of information is growing exponentially, recommendations help people find something new and interesting.
Yandex has always specialized in search. In the broad sense of the word. Find answers to your questions. Search for the best route. And even search for a free taxi near you. About two years ago, we had another idea. Teach the car to search the network for the content that would be of interest to a particular person. Personalized search, where as a query are not words, but interests. From this idea was born the tape of recommended Zen content.
Zen
Zen is an endless tape of content, which is formed on the basis of the interests of a particular person. We want to help users find interesting content, and to publishers - targeted traffic (click on the recommendations opens the material on the original site). Usually, stories about new products start with a description of ideology and product strategy, and here I recommend that you read the post of Roman kukutz Ivanov on the Yandex blog , and you and I will immediately move on to the most important for Habr, to technologies. Especially since it is they who distinguish Zen in Yandex. Browser from any other browser (and not only) analogues.
By the way, an attentive reader may recall that the first experiments with Zen were carried out in 2015 on the zen.yandex.ru page. Why is the recommendation feed now part of the Browser? This time I’ll answer the question a bit later.
Zen is based on Disco's recommender technology, developed in Yandex and already used in Yandex.Music and Yandex.Market. The word "disco" is consonant with the English word discovery, which means "discovery of the new" and well describes the essence of technology.
A simplified logical scheme for the disco in the case of Zen looks like this:
Let's start from the very beginning, with the initial data, which have yet to somehow turn into factors.
How do the recommendations begin
Before advising a person, you need to understand his interests and preferences. Zen for this uses knowledge of Yandex about the sites visited by people. Thanks to this knowledge, many new users of Zen will be able to immediately see the tape of personal recommendations without the need to customize something. But sometimes they are not enough. One could try to solve this problem with a tape that focuses on the average person. But we know that such a person does not exist in reality (which was well shown by the example of the American air force). Therefore, we went the other way and suggested that people independently limit their interests. These settings do not have their own name, but inside we call them “Onboarding”.
It is important to understand that Onboarding is not an obligatory stage of initial settings, but only a backup option for those who have absolutely nothing to offer. The tape of recommendations immediately after the passage of Onboarding can be quite different from the compilations formed after a few weeks of active use of Zen. These settings are already available to users of Yandex. Browser for Android and iPhone. For Windows, they will be available soon (for now, you can use a temporary solution ).
Knowledge of a person’s interests is only half of the required information. In order to recommend something, you first need to find something. Usually, reference services solve this problem in a primitive way - they form a limited catalog of RSS feeds of interest. In the case of Zen, there are no such restrictions. Search robots are looking for any materials. This can be both author publications from popular blogs, as well as high-quality stories from forums or YouTube videos. This is what we call the wild web. The main thing is that the site was not abandoned and the page contained a sufficient amount of useful content.
So, on the one hand, we have knowledge about the favorite publications of millions of users, on the other - all the power of the global search index Yandex. It remains the most "simple". Teach the car to build recommendations.
Types of recommendation systems
In the history of recommender technologies, two of their main types are well known: content filtering and collaborative filtering. Let's start with the first one, which is based on comparing the contents of the recommended objects. For example, I propose to consider movies. If two films belong to the same genre, and the user has already praised one of them, then with a certain probability you can advise him and the second. And here it is interesting to recall the Netflix online cinema, which increased the number of genres from several hundred to tens of thousands , among which you can even find “Cult horror films with evil children.” Most of these genres are hidden from viewers and used only to build recommendations.
In our case, there are no genres. To make a conclusion about the compliance of a web page with the interests of a person, it is necessary to compare its content with known samples. And this should be done by a computer, which needs not only to read the material, but also to understand its meaning. And the only way to solve this problem accurately enough is to use the Yandex experience in the field of artificial intelligence.
NLP + CV
When it comes to artificial intelligence, many users imagine SkyNet wishing to enslave humanity. Fortunately, the future is not predetermined and everything is in our hands. But seriously, the groundwork in the field of AI already helps us to solve complex problems. The ability of the machine to read, see, and, most importantly, understand the meaning opens up great prospects.
Natural language processing (Natural Language Processing, NLP) and computer vision (Computer Vision, CV) are two widely used directions in Zen from the field of artificial intelligence.
When we talk about recommendations, we mean to ourselves materials that would be sufficiently close in their semantic content to the user's samples. In other words, the machine should read two texts and make a conclusion: are they close in meaning or not. Exactly what we are learning to do. A specially trained neural network transforms the text into a vector, which contains the meaning of the text. Two texts can be written using different words and even in different languages, but they will have the same meaning. Comparing these vectors, we can with a certain probability predict a person’s interest in a new material. By the way, if the vectors almost coincide, then this already speaks of a semantic duplicate (rewriting of the text or different articles about the same event) with which we fight in the tape.
Another approach to NLP that the Zen team is working on is the automatic labeling of any text. Remember the example of Netflix and tens of thousands of genres. So it is here. The classification of publications using tags helps to improve the accuracy of the final recommendations.
Working with computer vision is generally similar to NLP. Only instead of reading the text, the machine learns to “look” and understand the meaning of the image. In addition to the direct application of the recommendations in computer vision, there are other tasks in Zen. For example, thumbnails of pictures are not always conveniently scaled, and they have to be cut off, and computer vision helps to find people in pictures and saves them from the fate of Ned Stark from Game of Thrones.
Computer vision is used to find the text in the pictures. Some sites like to duplicate the title as an image. In the tape, it does not look so beautiful, so these images are detected and not used as thumbnails. There is also such a difficult to explain concept, as the "quality" of the picture. The machine learns to choose on the site those images that are more popular with people, and uses them as all the same miniatures.
Svd
Above, I told you about the approach to building recommendations, which is based on filtering by the contents of objects. Now it's time to remember about collaborative filtering. At the core of this approach is the idea that similar people like similar objects. In this case, you do not need to know the properties of the recommended objects, it is enough to collect statistics about how they correspond to the interests of users. On the example of movies, it might look like
Based on already known estimates, it is possible to identify patterns in the behavior of different people and try to predict the reaction to a new film. At the mathematical level, various algorithms were invented for applying collaborative filtering, which my colleague Mikhail Roizner had a good talk about in his time at Habré.
In the case of Zen, we use collaborative filtering (or rather, the SVD algorithm) to predict a person’s interest in a particular site as a whole. This information complements the recommendations built for individual materials using artificial intelligence (NLP + CV). Allows you to weed out unnecessary noise and to identify non-trivial patterns (for example, it may turn out that people who are interested in Habr and the stories with Peek-a-boo read N + 1 more often than others).
To summarize Using the source data about the sites and users, we use the technologies of natural language processing, computer vision and the SVD algorithm to form a set of various factors that characterize a person’s interests in various sites / materials.
The accuracy of the final recommendations is directly dependent on the number and variety of input data, so many of our other knowledge is used as factors. For example, Yandex’s knowledge of a particular site or page, information about how a person uses Zen, his feedback in the form of clicks, “more such” and “less such”, location and even time of day. The total number of individual factors that we lay in the recommendation system is in the thousands. The complexity of the system reaches such a level that some algorithms are already small. We need a technology that will itself calculate the ideal formula for building the final tape. And here Yandex’s machine learning experience came in handy.
Matrixnet
The term "machine learning" appeared in the 50s. It means an attempt to teach a computer to solve problems that are easily given to a person, but it is difficult to formalize the way to solve them. As a result of machine learning, a computer may exhibit behavior that was not explicitly incorporated into it.
Every day our search engine responds to millions of queries, many of which are non-recurring. Therefore, it is impossible to write such a program in which each request is provided and the best answer is known for each request. The search system should be able to make decisions on its own, that is, to choose from the millions of documents the one that best responds to the user. For this you need to teach her to learn.
Since 2009, Yandex search has been using Matrixnet’s own machine learning method. With it, you can build a very long and complex ranking formula, which takes into account many different factors and their combinations. In addition, MatrixNet itself determines different sensitivity for different values of ranking factors. This technology is quite versatile, so it subsequently found application not only in Yandex, but also in the European Center for Nuclear Research .
The ability of a computer to take into account thousands of factors and independently search for the best solution is something without which it is impossible to build a modern recommendation system. That is why MatrixNet was taken as the basis for creating its own recommender technology.
The result of the work of MatrixNet is exactly what the user sees in the Zen ribbon. On the part of the developers, there are no rules of the form “If a person loves A, then we recommend him B”. All such patterns are born and are constantly changing within the Matriksnet. And the more data he has, the more accurate the recommendations. That is why Zen is part of Yandex. Browser, and not an independent web service or application. A separate application is more difficult to understand the interests of the user, who, after two or three days, can simply stop running it. In order for Zen magic and machine learning to come into full force, they need to actively use or at least regularly run alongside. And the browser, as a single point of access to the Internet, is best suited for this. Of course, any user can opt out of using Zen in the Browser.
In this post, I told you about how the personal recommendation feed is formed in Yandex.Browser, and why Zen is not just another “news feed”, but the result of serious technology. Developments from the field of artificial intelligence now help the machine to understand the meaning of content and human interests. But this is only the beginning. Who knows, maybe one day computers will understand us better than ourselves?
Source: https://habr.com/ru/post/302856/
All Articles