C / C ++ compiler based on LLVM for multicellular processors: to be or not to be?

An inquisitive reader is probably already familiar with a fundamentally new processor architecture - multicellular; and if he does not know, he will be able to be briefly acquainted in our article The architecture is so unlike traditional that creating a compiler for familiar programming languages becomes a problem with which developers unsuccessfully struggling for many years.
A bit of history
Since the founding of the Multiklet company in 2010, development of several types of compilers for multicellular architecture has been carried out:
- With the first Multiclet P1 processor in 2012, the C89 compiler based on LCC was developed as part of the software. At the same time, the development of the first version of the own compiler was carried out, suspended due to the initially complex unrealizable plan.
As it has been repeatedly pointed out in many articles on this topic, and was also recognized by the company's developers themselves, the LCC-based compiler has a number of significant flaws: support for the C89 language only, the absence of any optimizations.
Subsequently, this compiler was adapted to support the new processor Multiclet R1 (2015), the command system of which was significantly expanded, but the compiler did not take this into account.
Taking into account these shortcomings, in 2012 the company management assembled a group of programmers who were tasked with developing a new C99 compiler, devoid of these shortcomings. - After examining the available compilers (frameworks for developing compilers) with open source (GCC and LLVM), a controversial and categorical decision was made: none of the existing for the multicellular architecture is suitable for the second version of its compiler.
 And three years of development began, which ended in the fall of 2015 by the fact that the development of our own compiler was again postponed for financial reasons. The required resources exceeded the financial possibilities, which in the absence of any grant or budget support did not allow to divert resources to theoretical work.
And three years of development began, which ended in the fall of 2015 by the fact that the development of our own compiler was again postponed for financial reasons. The required resources exceeded the financial possibilities, which in the absence of any grant or budget support did not allow to divert resources to theoretical work. - In the autumn of 2015, it was decided to try to develop a compiler for the Multiclet R1 processor based on the LLVM framework. And now the development team has moved on this interesting and exciting path.
Few details
The main work was to write a compiler backend, which
converts the intermediate representation of the LLVM into an assembly code for
multicellular processor Multiclet R1. This means that you can already try to compile programs written in any LLVM language, you only need to specify that their compilers output an LLVM IR bitcode or an assembler. Then, the resulting file is submitted to the input of this backend.
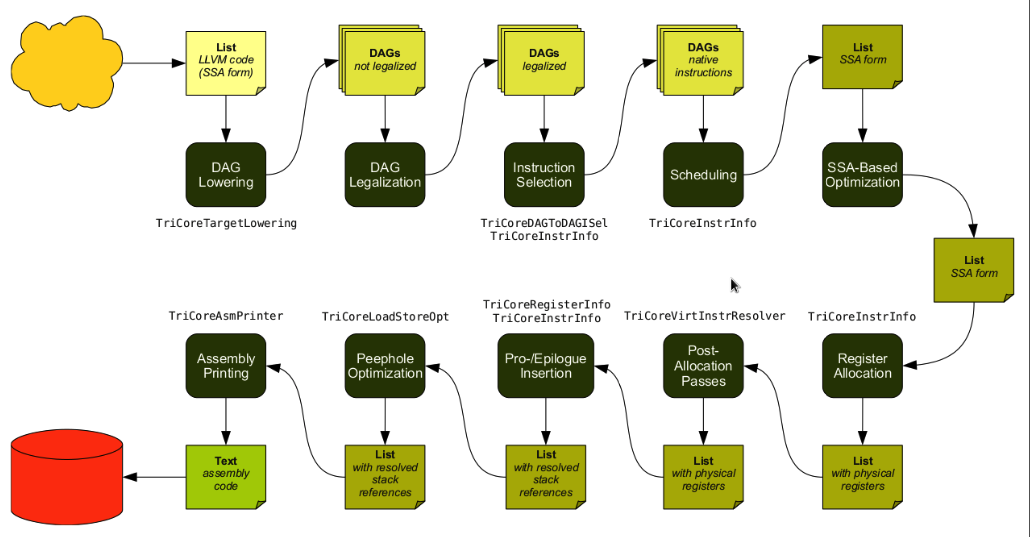
In general terms, the following actions were performed during the development of the backend:
- Description of the target architecture using abstract interfaces, as well as a specialized language TableGen, designed to describe the general information used in LLVM at different stages of compilation (* .td files)
1.1. Description of the characteristics of the target machine (derived class from TargetMachine, DataLayout, Multiclet.td)
1.2. Description of the target machine's register set (derived class from TargetRegisterInfo, MulticletRegisterInfo.td). At this stage, the orientation of the LLVM framework to generate code for register machines, to which, in fact, multicellular processors do not apply, was immediately apparent. There was a question how to describe the switch used to exchange results between instructions. After a brief reflection, it was decided to consider the switch cells as registers with a limited lifetime, i.e. the values of such registers are relevant only within one base unit, which in turn is a paragraph, and, moreover, their relevance within one base unit depends on the scope of the results provided by the switch. Looking ahead, you can immediately say that such a decision leads to the need to write your register allocator.
1.3. Description of the instruction set supported by the target machine (derived class from TargetInstrInfo, MulticletTargetInstrFormats.td, MulticletTargetInstrInfo.td) - Describes the process of sampling and converting the instructions of the LLVM IR intermediate representation, presented as a directed acyclic graph (DAG), into the corresponding instructions explicitly supported by the target machine (derived class from TargetLowering, derived class from SelectionDAGISel). During the implementation of this stage, the need for special processing of instructions, which are displayed in the setXX instruction of the target machine, was revealed. The fact is that the setXX instructions for setting the register value (NOT the switch cells) are actually executed upon completion of the paragraph, i.e., assuming that the paragraph is the base unit, upon completion of the base unit, therefore these instructions should break the base unit. This behavior was implemented using special handlers (Instruction Emitting Hooks), which are called when an instruction is generated, of the TargetLowering class, in particular EmitInstrWithCustomInserter.
- Then, just before the allocation of registers, two passes were added, which reflect the specificity of the multicellular architecture:
3.1. Analysis and modification of control transfer instructions. The fact is that in the multicellular architecture there are actually only instructions for setting the address of the next executable paragraph (although they are named, quite unfortunate, jmp and jXX), and the transfer of control itself is carried out at the end of the current paragraph. Therefore, on this pass, firstly, in the base unit, in which there is no control transfer instruction (in this case, it is assumed that the next base unit located in the memory is being executed), an unconditional control transfer instruction is added to the next base unit, and secondly, in the base unit, in which there is one conditional control transfer instruction, immediately followed by one unconditional control transfer instruction, the unconditional control transfer instruction is replaced with the conditional instruction Transferring control with the opposite condition.
3.2. Analysis of instructions for reading from memory and writing to memory. Since in a multicellular architecture, the execution of instructions is unordered, then in one base unit it is generally unacceptable to execute two instructions to write to the same address, as well as to execute a reading instruction to an address that previously could (and could not have been) executed write instruction. - The LLVM framework provides the following set of register allocators: fast, basic, greedy, pbqp. In view of the features (availability of the switch) of the multicellular architecture of the above allocators, the correct assembler code can be generated only by using the fast allocator, which distributes the registers at the level of the basic blocks, which is necessary in the framework of the accepted concept "basic block". Since fast, the allocator is the default allocator for debugging builds, it does not perform any optimizations. To eliminate this fact, we developed our own multiclet allocator, which also contains some additional architecture-dependent optimizations.
- Implementing the prologue / epilogue function insert (derived from TargetFrameLowering).
- Further, just before the output of the assembler code, two passes were added, which reflect the specifics of the multicellular architecture:
6.1. Optimizing the location of control transfer instructions. Since, in the multicellular architecture, control transfer instructions are in fact instructions for setting the address to which, at the end of the base unit (paragraph), it will be necessary to transfer control, in this passage we move such instructions (if possible) as close as possible to the beginning of the base unit.
6.2. Eliminating references to the results of previously executed instructions that are outside the scope of the results provided by the switch.
To date, this pass performs a very simple processing of such links, which consists in adding the move instruction to the required position of the sequence of instructions. In some cases, such trivial processing may fail, which will lead to a crash of the program (compiler). - The implementation of the pass code emission (output assembler code).
The set of changes made to the frontend was significantly smaller: the multicellular architecture was added as a supported target machine.
As a result of this work, a good foundation was laid for the development of a compiler for multicellular processors based on LLVM. In other words, the development of this compiler is a little further than the initial stage, as evidenced by the following incomplete list of shortcomings of the current version of the compiler:
- There is no full support for 64-bit integer arithmetic.
- There is no support for vector instructions, which in a limited set are supported by the Multiclet R1 processor.
- The architecture-dependent optimizations on the backend side are in their infancy (only obvious optimizations are implemented).
- The compiler does not take into account all possible hardware errors of the Multiclet R1 processor (in general, one would like to make and avoid such errors on the assembler side, so that the top-level compiler is free from the solution of this problem, and not to repeat the same code in different compilers top level, if there are several (we have a lcc based C89 compiler)).
- There is no standard C language library, math library, etc.
- There is no possibility of generating position-independent code (-fPIC), all generated code is static.
- There is no generation of debug information.
- The reaction of the compiler to the use of attributes ( attribute ) and assembler inserts in the source code is not known, since tests of this code were not carried out (it is possible in some cases that the compiler crashes).
The presented compiler can be downloaded on the official website of the company here .
You can ask all the questions on the forum .
About current results
Using the current version of the compiler, various short C programs were compiled, which were mainly used for testing, A Lightweight TCP / IP stack version 1.4.1 , Coremark test.
The result of the Coremark test for the Multiclet R1 is 0.56 Coremark / MHz, which is almost two times better than the Coremark test, which was compiled using the compiler
C89 based on LCC.
Of course, the result of 0.56 Coremark / MHz is still far from the desired 2-3 units. Firstly, this is due to the lack of good architecture-dependent optimizations in the presented version of the compiler, and, secondly, to the non-optimality of some
hardware blocks of this particular implementation of the processor Multiclet R1, which are poorly adapted to perform sequential (poorly parallelizable) algorithms, which are not so few in Coremark.
CoreMark Comparison Chart
| Multiclet P1 (lcc compiler) | Multiclet R1 (lcc compiler) | Multiclet R1 (llvm compiler) | 985BE91T Milander ARM Cortex-M3 | STM32F4x ARM Cortex-M4 | RX62N Renesas | WIPS proAptive RTL FPGA prototype | Intel Core i7-2760QM CPU@2.40GHz | |
|---|---|---|---|---|---|---|---|---|
| Clock frequency, MHz | 80 | 100 | 100 | 80 | 168 | 100 | 31 | 2400 |
| CoreMark Total | 24.49 | 24.95 | 56.45 | 117.6 | 501.85 | 311.54 | 137.10 | 85151.68 |
| CoreMark / MHz | 0.31 | 0.25 | 0.56 | 1.47 | 2.98 | 3.12 | 4.42 | 35.48 |
For evaluation of architectures of parallel processors, it is more expedient to use assembler programs that take into account all the features of the architecture and implement parallel algorithms. Consider a couple of examples.
An example of an assembler implementation of the calculation of the population of single bits in a 512-bit operand, whose speed on a Multiclet R1 processor is comparable to that on an Intel Core i7 processor.
.data .p2align 3 work_result: .space 8, 0 tmp: .long 0 .text .alias value1 GPR0 .alias value2 GPR1 .alias value3 GPR2 .alias value4 GPR3 .alias value5 GPR4 .alias value6 GPR5 .alias value7 GPR6 .alias value8 GPR7 .alias result IR0 init: jmp init_timer setl #result, 0x0 b1 := getb 0x0 b2 := getb @b1 + 1 b3 := getb @b1 + 2 b4 := getb @b1 + 3 b5 := getb @b1 + 4 b6 := getb @b1 + 5 b7 := getb @b1 + 6 b8 := getb @b1 + 7 s2 := slll @b2, 8 s3 := slll @b3, 16 s4 := slll @b4, 24 s6 := slll @b6, 8 s7 := slll @b7, 16 s8 := slll @b8, 24 v1 := andl @b1, 0x000000FF v2 := andl @s2, 0x0000FF00 v3 := andl @s3, 0x00FF0000 v4 := andl @s4, 0xFF000000 v5 := andl @b5, 0x000000FF v6 := andl @s6, 0x0000FF00 v7 := andl @s7, 0x00FF0000 v8 := andl @s8, 0xFF000000 r1_16 := orl @v1, @v2 r2_16 := orl @v3, @v4 r3_16 := orl @v5, @v6 r4_16 := orl @v7, @v8 r1_32 := orl @r1_16, @r2_16 r2_32 := orl @r3_16, @r4_16 r64 := patch @r1_32, @r2_32 setq #value1, @r64 setq #value2, @r64 setq #value3, @r64 setq #value4, @r64 setq #value5, @r64 setq #value6, @r64 setq #value7, @r64 setq #value8, @r64 complete init_timer: jmp init_timer_2 wrl @0, 0xC0010018; TIM0_CR0 complete init_timer_2: jmp init_timer_3 getl 10 - 1 getl 0xFFFFFFFF wrl @2, 0xC0010004; TIM0_PSCPER wrl @2, 0xC0010014; TIM0_CNTPER0 complete init_timer_3: getl 0x03 wrl @1, 0xC0010018; TIM0_CR0 jmp start_popcnt512 complete start_popcnt512: jmp new_popcnt512_reg rdl 0xC0010010; TIM0_CNTVAL0 wrdl @1, tmp complete new_popcnt512_reg: val1 := getl #value1 val2 := getl #value2 val3 := getl #value3 val4 := getl #value4 val5 := getl #value5 val6 := getl #value6 val7 := getl #value7 val8 := getl #value8 val9 := pack @0, #value1 val10 := pack @0, #value2 val11 := pack @0, #value3 val12 := pack @0, #value4 val13 := pack @0, #value5 val14 := pack @0, #value6 val15 := pack @0, #value7 val16 := pack @0, #value8 s1_1 := slrl @val1, 1 s1_2 := slrl @val2, 1 s1_3 := slrl @val3, 1 s1_4 := slrl @val4, 1 s1_5 := slrl @val5, 1 s1_6 := slrl @val6, 1 s1_7 := slrl @val7, 1 s1_8 := slrl @val8, 1 s1_9 := slrl @val9, 1 s1_10 := slrl @val10, 1 s1_11 := slrl @val11, 1 s1_12 := slrl @val12, 1 s1_13 := slrl @val13, 1 s1_14 := slrl @val14, 1 s1_15 := slrl @val15, 1 s1_16 := slrl @val16, 1 s2_1 := andl @s1_1, 0x55555555 s2_2 := andl @s1_2, 0x55555555 s2_3 := andl @s1_3, 0x55555555 s2_4 := andl @s1_4, 0x55555555 s2_5 := andl @s1_5, 0x55555555 s2_6 := andl @s1_6, 0x55555555 s2_7 := andl @s1_7, 0x55555555 s2_8 := andl @s1_8, 0x55555555 s2_9 := andl @s1_9, 0x55555555 s2_10 := andl @s1_10, 0x55555555 s2_11 := andl @s1_11, 0x55555555 s2_12 := andl @s1_12, 0x55555555 s2_13 := andl @s1_13, 0x55555555 s2_14 := andl @s1_14, 0x55555555 s2_15 := andl @s1_15, 0x55555555 s2_16 := andl @s1_16, 0x55555555 s3_1 := subl @val1, @s2_1 s3_2 := subl @val2, @s2_2 s3_3 := subl @val3, @s2_3 s3_4 := subl @val4, @s2_4 s3_5 := subl @val5, @s2_5 s3_6 := subl @val6, @s2_6 s3_7 := subl @val7, @s2_7 s3_8 := subl @val8, @s2_8 s3_9 := subl @val9, @s2_9 s3_10 := subl @val10, @s2_10 s3_11 := subl @val11, @s2_11 s3_12 := subl @val12, @s2_12 s3_13 := subl @val13, @s2_13 s3_14 := subl @val14, @s2_14 s3_15 := subl @val15, @s2_15 s3_16 := subl @val16, @s2_16 s4_1 := andl @s3_1, 0x33333333 s4_2 := andl @s3_2, 0x33333333 s4_3 := andl @s3_3, 0x33333333 s4_4 := andl @s3_4, 0x33333333 s4_5 := andl @s3_5, 0x33333333 s4_6 := andl @s3_6, 0x33333333 s4_7 := andl @s3_7, 0x33333333 s4_8 := andl @s3_8, 0x33333333 s4_9 := andl @s3_9, 0x33333333 s4_10 := andl @s3_10, 0x33333333 s4_11 := andl @s3_11, 0x33333333 s4_12 := andl @s3_12, 0x33333333 s4_13 := andl @s3_13, 0x33333333 s4_14 := andl @s3_14, 0x33333333 s4_15 := andl @s3_15, 0x33333333 s4_16 := andl @s3_16, 0x33333333 s5_1 := slrl @s3_1, 2 s5_2 := slrl @s3_2, 2 s5_3 := slrl @s3_3, 2 s5_4 := slrl @s3_4, 2 s5_5 := slrl @s3_5, 2 s5_6 := slrl @s3_6, 2 s5_7 := slrl @s3_7, 2 s5_8 := slrl @s3_8, 2 s5_9 := slrl @s3_9, 2 s5_10 := slrl @s3_10, 2 s5_11 := slrl @s3_11, 2 s5_12 := slrl @s3_12, 2 s5_13 := slrl @s3_13, 2 s5_14 := slrl @s3_14, 2 s5_15 := slrl @s3_15, 2 s5_16 := slrl @s3_16, 2 s6_1 := andl @s5_1, 0x33333333 s6_2 := andl @s5_2, 0x33333333 s6_3 := andl @s5_3, 0x33333333 s6_4 := andl @s5_4, 0x33333333 s6_5 := andl @s5_5, 0x33333333 s6_6 := andl @s5_6, 0x33333333 s6_7 := andl @s5_7, 0x33333333 s6_8 := andl @s5_8, 0x33333333 s6_9 := andl @s5_9, 0x33333333 s6_10 := andl @s5_10, 0x33333333 s6_11 := andl @s5_11, 0x33333333 s6_12 := andl @s5_12, 0x33333333 s6_13 := andl @s5_13, 0x33333333 s6_14 := andl @s5_14, 0x33333333 s6_15 := andl @s5_15, 0x33333333 s6_16 := andl @s5_16, 0x33333333 s7_1 := addl @s4_1, @s6_1 s7_2 := addl @s4_2, @s6_2 s7_3 := addl @s4_3, @s6_3 s7_4 := addl @s4_4, @s6_4 s7_5 := addl @s4_5, @s6_5 s7_6 := addl @s4_6, @s6_6 s7_7 := addl @s4_7, @s6_7 s7_8 := addl @s4_8, @s6_8 s7_9 := addl @s4_9, @s6_9 s7_10 := addl @s4_10, @s6_10 s7_11 := addl @s4_11, @s6_11 s7_12 := addl @s4_12, @s6_12 s7_13 := addl @s4_13, @s6_13 s7_14 := addl @s4_14, @s6_14 s7_15 := addl @s4_15, @s6_15 s7_16 := addl @s4_16, @s6_16 s8_1 := slrl @s7_1, 4 s8_2 := slrl @s7_2, 4 s8_3 := slrl @s7_3, 4 s8_4 := slrl @s7_4, 4 s8_5 := slrl @s7_5, 4 s8_6 := slrl @s7_6, 4 s8_7 := slrl @s7_7, 4 s8_8 := slrl @s7_8, 4 s8_9 := slrl @s7_9, 4 s8_10 := slrl @s7_10, 4 s8_11 := slrl @s7_11, 4 s8_12 := slrl @s7_12, 4 s8_13 := slrl @s7_13, 4 s8_14 := slrl @s7_14, 4 s8_15 := slrl @s7_15, 4 s8_16 := slrl @s7_16, 4 s9_1 := addl @s7_1, @s8_1 s9_2 := addl @s7_2, @s8_2 s9_3 := addl @s7_3, @s8_3 s9_4 := addl @s7_4, @s8_4 s9_5 := addl @s7_5, @s8_5 s9_6 := addl @s7_6, @s8_6 s9_7 := addl @s7_7, @s8_7 s9_8 := addl @s7_8, @s8_8 s9_9 := addl @s7_9, @s8_9 s9_10 := addl @s7_10, @s8_10 s9_11 := addl @s7_11, @s8_11 s9_12 := addl @s7_12, @s8_12 s9_13 := addl @s7_13, @s8_13 s9_14 := addl @s7_14, @s8_14 s9_15 := addl @s7_15, @s8_15 s9_16 := addl @s7_16, @s8_16 s10_1 := andl @s9_1, 0xF0F0F0F s10_2 := andl @s9_2, 0xF0F0F0F s10_3 := andl @s9_3, 0xF0F0F0F s10_4 := andl @s9_4, 0xF0F0F0F s10_5 := andl @s9_5, 0xF0F0F0F s10_6 := andl @s9_6, 0xF0F0F0F s10_7 := andl @s9_7, 0xF0F0F0F s10_8 := andl @s9_8, 0xF0F0F0F s10_9 := andl @s9_9, 0xF0F0F0F s10_10 := andl @s9_10, 0xF0F0F0F s10_11 := andl @s9_11, 0xF0F0F0F s10_12 := andl @s9_12, 0xF0F0F0F s10_13 := andl @s9_13, 0xF0F0F0F s10_14 := andl @s9_14, 0xF0F0F0F s10_15 := andl @s9_15, 0xF0F0F0F s10_16 := andl @s9_16, 0xF0F0F0F s11_1 := mull @s10_1, 0x1010101 s11_2 := mull @s10_2, 0x1010101 s11_3 := mull @s10_3, 0x1010101 s11_4 := mull @s10_4, 0x1010101 s11_5 := mull @s10_5, 0x1010101 s11_6 := mull @s10_6, 0x1010101 s11_7 := mull @s10_7, 0x1010101 s11_8 := mull @s10_8, 0x1010101 s11_9 := mull @s10_9, 0x1010101 s11_10 := mull @s10_10, 0x1010101 s11_11 := mull @s10_11, 0x1010101 s11_12 := mull @s10_12, 0x1010101 s11_13 := mull @s10_13, 0x1010101 s11_14 := mull @s10_14, 0x1010101 s11_15 := mull @s10_15, 0x1010101 s11_16 := mull @s10_16, 0x1010101 s12_1 := slrl @s11_1, 24 s12_2 := slrl @s11_2, 24 s12_3 := slrl @s11_3, 24 s12_4 := slrl @s11_4, 24 s12_5 := slrl @s11_5, 24 s12_6 := slrl @s11_6, 24 s12_7 := slrl @s11_7, 24 s12_8 := slrl @s11_8, 24 s12_9 := slrl @s11_9, 24 s12_10 := slrl @s11_10, 24 s12_11 := slrl @s11_11, 24 s12_12 := slrl @s11_12, 24 s12_13 := slrl @s11_13, 24 s12_14 := slrl @s11_14, 24 s12_15 := slrl @s11_15, 24 s12_16 := slrl @s11_16, 24 sum1 := addl @s12_1, @s12_2 sum2 := addl @s12_3, @s12_4 sum3 := addl @s12_5, @s12_6 sum4 := addl @s12_7, @s12_8 sum5 := addl @s12_9, @s12_10 sum6 := addl @s12_11, @s12_12 sum7 := addl @s12_13, @s12_14 sum8 := addl @s12_15, @s12_16 sum9 := addl @sum1, @sum2 sum10 := addl @sum3, @sum4 sum11 := addl @sum5, @sum6 sum12 := addl @sum7, @sum8 sum13 := addl @sum9, @sum10 sum14 := addl @sum11, @sum12 sum15 := addl @sum13, @sum14 setl #result, @sum15 jmp stop_popcnt512 complete stop_popcnt512: jmp save_result rdl 0xC0010010; TIM0_CNTVAL0 rdl tmp subl @1, @2 wrdl @1, work_result complete save_result: jmp uart_init getl #result wrdl @1, work_result + 4 complete uart_init: jmp uart_print altport := getl 0xFFFFFFFF control := getl 0x00000003; rx, tx enable bitrate := getl 0x34; wrdl @control, 0xC0000108 wrdl @altport, 0xC00F0218 wrdl @bitrate, 0xC000010C setl #GPR0, 8 complete uart_print: count := getl #GPR0 je @count, stop jne @count, uart_wait setl #GPR0, #GPR0, -1 complete uart_wait: st := rddl 0xC0000104 andl @st, 2 je @1, uart_wait jne @2, uart_print_data complete uart_print_data: jmp uart_print data := rdq work_result n_data := slrq @data, 8 wrq @n_data, work_result wrdb @data, 0xC0000100 complete stop: getl 0x0 complete This implementation performs the specified algorithm in approximately 90 cycles.
For comparison, consider the equivalent code in C
#include "timer.h" #include "mc-stdio.h" #include "serial.h" #define B1 0 #define B2 1 #define B3 2 #define B4 3 #define B5 4 #define B6 5 #define B7 6 #define B8 7 unsigned int countBits(unsigned int x) { x = x - ((x >> 1) & 0x55555555); x = (x & 0x33333333) + ((x >> 2) & 0x33333333); x = x + (x >> 4); x &= 0xF0F0F0F; return (x * 0x01010101) >> 24; } void init(unsigned int *v, int cnt) { unsigned int v1 = ((B1 & 0xFF) << 0) | ((B2 & 0xFF) << 8) | ((B3 & 0xFF) << 16) | ((B4 & 0xFF) << 24); unsigned int v2 = ((B5 & 0xFF) << 0) | ((B6 & 0xFF) << 8) | ((B7 & 0xFF) << 16) | ((B8 & 0xFF) << 24); for (int i = 0; i < cnt; i += 2) { v[i] = v1; v[i+1] = v2; } } #define SIZE 16 int main(int argc, char *argv[]) { init_system_timer(TIM0, 0x03, 0xffffffff, 10); SER_init(); unsigned int res = 0; unsigned int v[SIZE]; init(v, SIZE); uint32_t start = get_system_ticks(TIM0); for (int i = 0; i < SIZE; ++i) res += countBits(v[i]); uint32_t stop = get_system_ticks(TIM0); mc_uprintf(0, "ticks count = 0x%X\nbits_count = %u", start - stop, res); return res; } To compile, run the following command:
clang -target multiclet -O2 -S test_popcnt.c -o test_popcnt.s -I<PATH_TO_INCL_DIR>
.text .file "test_popcnt.c" .globl countBits .type countBits,@function countBits: SR2 := rdl #IR7, 4 SR3 := rdl #IR7 jmp @SR3 SR4 := slrl @SR2, 1 SR5 := andl @SR4, 1431655765 SR4 := subsl @SR2, @SR5 SR2 := andl @SR4, 858993459 SR5 := slrl @SR4, 2 SR4 := andl @SR5, 858993459 SR5 := addsl @SR4, @SR2 SR2 := slrl @SR5, 4 SR4 := addsl @SR2, @SR5 SR2 := andl @SR4, 252645135 SR4 := mulsl @SR2, 16843009 SR2 := slrl @SR4, 24 setq #GPR7, @SR2 complete .Lfunc_end0: .size countBits, .Lfunc_end0-countBits .globl init .type init,@function init: jmp LBB1_1 setl #IR7, #IR7, -16 complete LBB1_1: SR2 := rdl #IR7, 24 SR3 := ltsl @SR2, 1 je @SR3, LBB1_2 jne @SR3, LBB1_3 complete LBB1_2: jmp LBB1_4 SR2 := rdl #IR7, 20 SR3 := addsl @SR2, 4 wrq @SR3, #IR7, 8 wrq @0, #IR7 complete LBB1_4: SR2 := getl 50462976 SR3 := getl 117835012 SR4 := rdl #IR7, 24 SR5 := rdq #IR7 SR6 := rdq #IR7, 8 SR7 := addsl @SR6, -4 wrl @SR3, @SR6 SR3 := addsl @SR6, 8 SR6 := addsl @SR5, 2 wrl @SR2, @SR7 SR2 := ltsl @SR6, @SR4 je @SR2, LBB1_3 jne @SR2, LBB1_4 wrq @SR3, #IR7, 8 wrq @SR6, #IR7 complete LBB1_3: SR2 := rdl #IR7, 16 jmp @SR2 setl #IR7, #IR7, 16 complete .Lfunc_end1: .size init, .Lfunc_end1-init .globl main .type main,@function main: jmp LBB2_1 setl #IR7, #IR7, -128 complete LBB2_1: jmp init_system_timer SR2 := getl 10 SR3 := getl -1 SR4 := getl 3 SR5 := getl -1073676288 SR6 := getl LBB2_2 wrl @SR2, #IR7, 16 wrl @SR3, #IR7, 12 wrl @SR4, #IR7, 8 wrl @SR5, #IR7, 4 wrl @SR6, #IR7 complete LBB2_2: jmp SER_init SR2 := getl LBB2_3 wrl @SR2, #IR7 complete LBB2_3: jmp get_system_ticks SR2 := getl -1073676288 SR3 := getl 50462976 SR4 := getl 117835012 SR5 := getl LBB2_4 wrl @SR3, #IR7, 64 wrl @SR4, #IR7, 68 wrl @SR3, #IR7, 72 wrl @SR4, #IR7, 76 wrl @SR3, #IR7, 80 wrl @SR4, #IR7, 84 wrl @SR3, #IR7, 88 wrl @SR4, #IR7, 92 wrl @SR3, #IR7, 96 wrl @SR4, #IR7, 100 wrl @SR3, #IR7, 104 wrl @SR4, #IR7, 108 wrl @SR3, #IR7, 112 wrl @SR4, #IR7, 116 wrl @SR3, #IR7, 120 wrl @SR4, #IR7, 124 wrl @SR2, #IR7, 4 wrl @SR5, #IR7 complete LBB2_4: jmp LBB2_8 SR2 := getl 4 SR3 := getq #GPR7 SR4 := exal #IR7, 64 wrq @SR2, #IR7, 56 wrq @SR2, #IR7, 48 wrq @SR3, #IR7, 40 wrq @SR4, #IR7, 24 complete LBB2_8: SR2 := rdq #IR7, 24 SR3 := rdq #IR7, 48 SR4 := rdq #IR7, 56 SR5 := addsl @SR2, @SR4 SR2 := addsl @SR4, 4 SR4 := rdl @SR5 SR5 := xorl @SR2, 64 jne @SR5, LBB2_8 je @SR5, LBB2_5 wrq @SR2, #IR7, 56 SR2 := slrl @SR4, 1 SR6 := andl @SR2, 1431655765 SR2 := subsl @SR4, @SR6 SR4 := andl @SR2, 858993459 SR6 := slrl @SR2, 2 SR2 := andl @SR6, 858993459 SR6 := addsl @SR2, @SR4 SR2 := slrl @SR6, 4 SR4 := addsl @SR2, @SR6 SR2 := andl @SR4, 252645135 SR4 := mulsl @SR2, 16843009 SR2 := slrl @SR4, 24 SR4 := addsl @SR2, @SR3 wrq @SR4, #IR7, 48 wrq @SR4, #IR7, 32 complete LBB2_5: jmp get_system_ticks SR2 := getl -1073676288 SR3 := getl LBB2_6 wrl @SR2, #IR7, 4 wrl @SR3, #IR7 complete LBB2_6: jmp mc_uprintf SR2 := rdq #IR7, 40 SR3 := rdq #IR7, 32 SR4 := getq #GPR7 SR5 := getl .L.str wrl @0, #IR7, 4 SR6 := getl LBB2_7 SR7 := subsl @SR2, @SR4 wrl @SR5, #IR7, 8 wrl @SR3, #IR7, 16 wrl @SR6, #IR7 wrl @SR7, #IR7, 12 complete LBB2_7: SR2 := rdq #IR7, 32 setq #GPR7, @SR2 SR2 := rdl #IR7, 128 jmp @SR2 setl #IR7, #IR7, 128 complete .Lfunc_end2: .size main, .Lfunc_end2-main .type .L.str,@object .section .rodata.str1.1,"aMS",@progbits,1 .L.str: .asciz "ticks count = 0x%X\nbits_count = %u" .size .L.str, 35 This implementation performs the specified algorithm in approximately 950 cycles, which is more than 10 times worse than the assembler version.
We present a summary table of results (the number of cycles for one cycle of calculating 32 bits)
| Algorithm | Multiclet R1 © | Multiclet R1 (ASM) | Pentium Dual Core 5700 3.0GHz | Intel Core i7-4700HQ @ 2400 |
|---|---|---|---|---|
| Bithacks | 59.4 | 5.0 | 9.5 | 4.7 |
One of the most presentational algorithms is the FFT. At the same time, in order to exclude technological factors, the assessment should be carried out in cycles spent on solving this problem, it is also necessary to consider the number of operations performed per cycle and their features (the amount of data generated by SIMD operation can be two or more).
.alias IRBASE 8 .alias IR0 8 .alias IR1 9 .alias IR2 10 .alias IR3 11 .alias IR4 12 .alias IRMASK01234 ((1 << (IR0 - IRBASE)) | (1 << (IR1 - IRBASE)) \ | (1 << (IR2 - IRBASE)) | (1 << (IR3 - IRBASE)) \ | (1 << (IR4 - IRBASE))) .alias IRMASK04 ((1 << (IR0 - IRBASE)) | (1 << (IR4 - IRBASE))) .syntax V1 .data ticks: .long 0 .align 8 W: ; Re(z), Im(z) .float\ 0f1.000000000000000000000000, 0f-0.000000000000000000000000,\ 0f0.999698817729949951171875, 0f-0.024541229009628295898438,\ 0f0.998795449733734130859375, 0f-0.049067676067352294921875,\ 0f0.997290432453155517578125, 0f-0.073564566671848297119141,\ 0f0.995184719562530517578125, 0f-0.098017141222953796386719,\ 0f0.992479562759399414062500, 0f-0.122410677373409271240234,\ 0f0.989176511764526367187500, 0f-0.146730467677116394042969,\ 0f0.985277652740478515625000, 0f-0.170961901545524597167969,\ 0f0.980785250663757324218750, 0f-0.195090323686599731445312,\ 0f0.975702106952667236328125, 0f-0.219101235270500183105469,\ 0f0.970031261444091796875000, 0f-0.242980197072029113769531,\ 0f0.963776051998138427734375, 0f-0.266712784767150878906250,\ 0f0.956940352916717529296875, 0f-0.290284663438796997070312,\ 0f0.949528157711029052734375, 0f-0.313681751489639282226562,\ 0f0.941544055938720703125000, 0f-0.336889863014221191406250,\ 0f0.932992815971374511718750, 0f-0.359895050525665283203125,\ 0f0.923879504203796386718750, 0f-0.382683455944061279296875,\ 0f0.914209723472595214843750, 0f-0.405241340398788452148438,\ 0f0.903989315032958984375000, 0f-0.427555084228515625000000,\ 0f0.893224298954010009765625, 0f-0.449611335992813110351562,\ 0f0.881921231746673583984375, 0f-0.471396744251251220703125,\ 0f0.870086967945098876953125, 0f-0.492898225784301757812500,\ 0f0.857728600502014160156250, 0f-0.514102756977081298828125,\ 0f0.844853579998016357421875, 0f-0.534997642040252685546875,\ 0f0.831469595432281494140625, 0f-0.555570244789123535156250,\ 0f0.817584812641143798828125, 0f-0.575808227062225341796875,\ 0f0.803207516670227050781250, 0f-0.595699310302734375000000,\ 0f0.788346409797668457031250, 0f-0.615231633186340332031250,\ 0f0.773010432720184326171875, 0f-0.634393334388732910156250,\ 0f0.757208824157714843750000, 0f-0.653172850608825683593750,\ 0f0.740951120853424072265625, 0f-0.671558976173400878906250,\ 0f0.724247097969055175781250, 0f-0.689540565013885498046875,\ 0f0.707106769084930419921875, 0f-0.707106769084930419921875,\ 0f0.689540505409240722656250, 0f-0.724247097969055175781250,\ 0f0.671558916568756103515625, 0f-0.740951180458068847656250,\ 0f0.653172791004180908203125, 0f-0.757208883762359619140625,\ 0f0.634393274784088134765625, 0f-0.773010432720184326171875,\ 0f0.615231573581695556640625, 0f-0.788346409797668457031250,\ 0f0.595699310302734375000000, 0f-0.803207516670227050781250,\ 0f0.575808167457580566406250, 0f-0.817584812641143798828125,\ 0f0.555570185184478759765625, 0f-0.831469655036926269531250,\ 0f0.534997642040252685546875, 0f-0.844853579998016357421875,\ 0f0.514102697372436523437500, 0f-0.857728660106658935546875,\ 0f0.492898195981979370117188, 0f-0.870086967945098876953125,\ 0f0.471396654844284057617188, 0f-0.881921291351318359375000,\ 0f0.449611306190490722656250, 0f-0.893224298954010009765625,\ 0f0.427555114030838012695312, 0f-0.903989315032958984375000,\ 0f0.405241280794143676757812, 0f-0.914209783077239990234375,\ 0f0.382683426141738891601562, 0f-0.923879504203796386718750,\ 0f0.359894961118698120117188, 0f-0.932992815971374511718750,\ 0f0.336889833211898803710938, 0f-0.941544055938720703125000,\ 0f0.313681662082672119140625, 0f-0.949528217315673828125000,\ 0f0.290284633636474609375000, 0f-0.956940352916717529296875,\ 0f0.266712754964828491210938, 0f-0.963776051998138427734375,\ 0f0.242980122566223144531250, 0f-0.970031261444091796875000,\ 0f0.219101220369338989257812, 0f-0.975702106952667236328125,\ 0f0.195090234279632568359375, 0f-0.980785310268402099609375,\ 0f0.170961856842041015625000, 0f-0.985277652740478515625000,\ 0f0.146730497479438781738281, 0f-0.989176511764526367187500,\ 0f0.122410625219345092773438, 0f-0.992479562759399414062500,\ 0f0.098017133772373199462891, 0f-0.995184719562530517578125,\ 0f0.073564492166042327880859, 0f-0.997290432453155517578125,\ 0f0.049067649990320205688477, 0f-0.998795449733734130859375,\ 0f0.024541135877370834350586, 0f-0.999698817729949951171875,\ 0f-0.000000043711388286737929, 0f-1.000000000000000000000000,\ 0f-0.024541223421692848205566, 0f-0.999698817729949951171875,\ 0f-0.049067739397287368774414, 0f-0.998795449733734130859375,\ 0f-0.073564574122428894042969, 0f-0.997290432453155517578125,\ 0f-0.098017223179340362548828, 0f-0.995184719562530517578125,\ 0f-0.122410707175731658935547, 0f-0.992479503154754638671875,\ 0f-0.146730571985244750976562, 0f-0.989176511764526367187500,\ 0f-0.170961946249008178710938, 0f-0.985277652740478515625000,\ 0f-0.195090323686599731445312, 0f-0.980785250663757324218750,\ 0f-0.219101309776306152343750, 0f-0.975702106952667236328125,\ 0f-0.242980197072029113769531, 0f-0.970031261444091796875000,\ 0f-0.266712844371795654296875, 0f-0.963776051998138427734375,\ 0f-0.290284723043441772460938, 0f-0.956940293312072753906250,\ 0f-0.313681721687316894531250, 0f-0.949528157711029052734375,\ 0f-0.336889922618865966796875, 0f-0.941544055938720703125000,\ 0f-0.359895050525665283203125, 0f-0.932992815971374511718750,\ 0f-0.382683515548706054687500, 0f-0.923879504203796386718750,\ 0f-0.405241340398788452148438, 0f-0.914209723472595214843750,\ 0f-0.427555084228515625000000, 0f-0.903989315032958984375000,\ 0f-0.449611365795135498046875, 0f-0.893224298954010009765625,\ 0f-0.471396833658218383789062, 0f-0.881921231746673583984375,\ 0f-0.492898166179656982421875, 0f-0.870087027549743652343750,\ 0f-0.514102756977081298828125, 0f-0.857728600502014160156250,\ 0f-0.534997701644897460937500, 0f-0.844853520393371582031250,\ 0f-0.555570363998413085937500, 0f-0.831469535827636718750000,\ 0f-0.575808167457580566406250, 0f-0.817584812641143798828125,\ 0f-0.595699369907379150390625, 0f-0.803207516670227050781250,\ 0f-0.615231692790985107421875, 0f-0.788346350193023681640625,\ 0f-0.634393274784088134765625, 0f-0.773010492324829101562500,\ 0f-0.653172850608825683593750, 0f-0.757208824157714843750000,\ 0f-0.671559035778045654296875, 0f-0.740951061248779296875000,\ 0f-0.689540684223175048828125, 0f-0.724246978759765625000000,\ 0f-0.707106769084930419921875, 0f-0.707106769084930419921875,\ 0f-0.724247157573699951171875, 0f-0.689540505409240722656250,\ 0f-0.740951240062713623046875, 0f-0.671558856964111328125000,\ 0f-0.757208824157714843750000, 0f-0.653172850608825683593750,\ 0f-0.773010492324829101562500, 0f-0.634393274784088134765625,\ 0f-0.788346469402313232421875, 0f-0.615231513977050781250000,\ 0f-0.803207635879516601562500, 0f-0.595699131488800048828125,\ 0f-0.817584812641143798828125, 0f-0.575808167457580566406250,\ 0f-0.831469655036926269531250, 0f-0.555570185184478759765625,\ 0f-0.844853639602661132812500, 0f-0.534997463226318359375000,\ 0f-0.857728600502014160156250, 0f-0.514102756977081298828125,\ 0f-0.870087027549743652343750, 0f-0.492898136377334594726562,\ 0f-0.881921350955963134765625, 0f-0.471396625041961669921875,\ 0f-0.893224298954010009765625, 0f-0.449611365795135498046875,\ 0f-0.903989315032958984375000, 0f-0.427555054426193237304688,\ 0f-0.914209783077239990234375, 0f-0.405241221189498901367188,\ 0f-0.923879623413085937500000, 0f-0.382683277130126953125000,\ 0f-0.932992815971374511718750, 0f-0.359895050525665283203125,\ 0f-0.941544115543365478515625, 0f-0.336889803409576416015625,\ 0f-0.949528217315673828125000, 0f-0.313681602478027343750000,\ 0f-0.956940352916717529296875, 0f-0.290284723043441772460938,\ 0f-0.963776051998138427734375, 0f-0.266712725162506103515625,\ 0f-0.970031261444091796875000, 0f-0.242980077862739562988281,\ 0f-0.975702166557312011718750, 0f-0.219101071357727050781250,\ 0f-0.980785310268402099609375, 0f-0.195090308785438537597656,\ 0f-0.985277652740478515625000, 0f-0.170961812138557434082031,\ 0f-0.989176511764526367187500, 0f-0.146730333566665649414062,\ 0f-0.992479503154754638671875, 0f-0.122410699725151062011719,\ 0f-0.995184719562530517578125, 0f-0.098017096519470214843750,\ 0f-0.997290492057800292968750, 0f-0.073564447462558746337891,\ 0f-0.998795449733734130859375, 0f-0.049067486077547073364258,\ 0f-0.999698817729949951171875, 0f-0.024541210383176803588867 .text // init_timer: setl #ST0PRDR, 0xFFFFFFFF setl #ST0CR, 0x1 jmp start complete start: jmp L1; setl #PSW, 0x00000040; getl 0x000007C0; patch @1, 0x00000000; setq #IR0, @1; getl 0x0001001F; patch @1, 0x00000000; setq #IR4, @1; complete; L1: irm IRMASK04 exa #IR4; je @1, L2; jne @2, L1; rdc #IR0, x + 0 * 8; x0 rdc #IR0, x + 2 * 8; x2 rdc #IR0, x + 4 * 8; x4 rdc #IR0, x + 6 * 8; x6 rdc #IR0, x + 1 * 8; x1 rdc #IR0, x + 3 * 8; x3 rdc #IR0, x + 5 * 8; x5 rdc #IR0, x + 7 * 8; x7 rdc W + 64 * 8; W4_1 addc @9, @5; x0=x0+x1 subc @10, @6; x1=x0-x1 addc @10, @6; x2=x2+x3 subc @11, @7; x3=x2-x3 addc @11, @7; x4=x4+x5 subc @12, @8; x5=x4-x5 addc @12, @8; x6=x6+x7 subc @13, @9; x7=x6-x7 mulc @9, @5; W4_1*x3 mulc @10, @2; W4_1*x7 addc @10, @8; x0=x0+x2 addc @10, @3; x1=x1+W4_1*x3 subc @12, @10; x2=x0-x2 subc @12, @5; x3=x1-W4_1*x3 addc @10, @8; x4=x4+x6 addc @10, @6; x5=x5+W4_1*x7 subc @12, @10; x6=x4-x6 subc @12, @8; x7=x5-W4_1*x7 wrc @8, #IR0, x + 0 * 8; wrc @8, #IR0, x + 1 * 8; wrc @8, #IR0, x + 2 * 8; wrc @8, #IR0, x + 3 * 8; wrc @8, #IR0, x + 4 * 8; wrc @8, #IR0, x + 5 * 8; wrc @8, #IR0, x + 6 * 8; wrc @8, #IR0, x + 7 * 8; complete L2: jmp L3; getl 0x00000718; patch @1, 0x00000000; setq #IR0, @1; getl 0x00000300; patch @1, W; setq #IR1, @1; getl 0x00000180; patch @1, W; setq #IR2, @1; getl 0x000000C0; patch @1, W; setq #IR3, @1; getl 0x0001001F; patch @1, 0x00000000; setq #IR4, @1; complete; L3: irm IRMASK01234 exa #IR4; je @1, L4; jne @2, L3; rdc #IR1; W8_i rdc #IR0, x + 4 * 8; x1 rdc #IR0, x + 12 * 8; x3 rdc #IR0, x + 20 * 8; x5 rdc #IR0, x + 28 * 8; x7 mulc @5, @4; W8_i*x1 mulc @6, @4; W8_i*x3 mulc @7, @4; W8_i*x5 mulc @8, @4; W8_i*x7 rdc #IR0, x + 0 * 8; x0 rdc #IR0, x + 8 * 8; x2 rdc #IR0, x + 16 * 8; x4 rdc #IR0, x + 24 * 8; x6 addc @3, @7; x2=x2+W8_i*x3 subc @4, @8; x3=x2-W8_i*x3 addc @3, @7; x6=x6+W8_i*x7 subc @4, @8; x7=x6-W8_i*x7 addc @8, @12; x0=x0+W8_i*x1 subc @9, @13; x1=x0-W8_i*x1 addc @8, @12; x4=x4+W8_i*x5 subc @9, @13; x5=x4-W8_i*x5 rdc #IR2; W16_i rdc #IR2, 0x0200; W16_j mulc @2, @10; W16_i*x2 mulc @2, @10; W16_j*x3 mulc @4, @10; W16_i*x6 mulc @4, @10; W16_j*x7 addc @8, @2; x4=x4+W16_i*x6 addc @8, @2; x5=x5+W16_j*x7 subc @10, @4; x6=x4-W16_i*x6 subc @10, @4; x7=x5-W16_j*x7 addc @14, @8; x0=x0+W16_i*x2 addc @14, @8; x1=x1+W16_j*x3 subc @16, @10; x2=x0-W16_i*x2 subc @16, @10; x3=x1-W16_j*x3 mulc @8, #IR3; W32*x4 mulc @8, #IR3, 0x0100; W32*x5 mulc @8, #IR3, 0x0200; W32*x6 mulc @8, #IR3, 0x0300; W32*x7 addc @8, @4; x0=x0+W*x4 addc @8, @4; x1=x1+W*x5 addc @8, @4; x2=x2+W*x6 addc @8, @4; x3=x3+W*x7 subc @12, @8; x4=x0-W*x4 subc @12, @8; x5=x1-W*x5 subc @12, @8; x6=x2-W*x6 subc @12, @8; x7=x3-W*x7 wrc @8, #IR0, x + 0 * 8; wrc @8, #IR0, x + 4 * 8; wrc @8, #IR0, x + 8 * 8; wrc @8, #IR0, x + 12 * 8; wrc @8, #IR0, x + 16 * 8; wrc @8, #IR0, x + 20 * 8; wrc @8, #IR0, x + 24 * 8; wrc @8, #IR0, x + 28 * 8; complete L4: jmp L5; getl 0x000000F8; patch @1, 0x00000000; setq #IR0, @1; getl 0x000003E0; patch @1, W; setq #IR1, @1; getl 0x000001F0; patch @1, W; setq #IR2, @1; getl 0x000000F8; patch @1, W; setq #IR3, @1; getl 0x0001001F; patch @1, 0x00000000; setq #IR4, @1; complete; L5: irm IRMASK01234 exa #IR4; je @1, stop; jne @2, L5; rdc #IR1; W32_i rdc #IR0, x + 32 * 8; x1 rdc #IR0, x + 96 * 8; x3 rdc #IR0, x + 160 * 8; x5 rdc #IR0, x + 224 * 8; x7 mulc @5, @4; W32_i*x1 mulc @6, @4; W32_i*x3 mulc @7, @4; W32_i*x5 mulc @8, @4; W32_i*x7 rdc #IR0, x + 0 * 8; x0 rdc #IR0, x + 64 * 8; x2 rdc #IR0, x + 128 * 8; x4 rdc #IR0, x + 192 * 8; x6 addc @3, @7; x2=x2+W32_i*x3 subc @4, @8; x3=x2-W32_i*x3 addc @3, @7; x6=x6+W32_i*x7 subc @4, @8; x7=x6-W32_i*x7 addc @8, @12; x0=x0+W32_i*x1 subc @9, @13; x1=x0-W32_i*x1 addc @8, @12; x4=x4+W32_i*x5 subc @9, @13; x5=x4-W32_i*x5 rdc #IR2; W64_i rdc #IR2, 0x0200; W64_j mulc @2, @10; W64_i*x2 mulc @2, @10; W64_j*x3 mulc @4, @10; W64_i*x6 mulc @4, @10; W64_j*x7 addc @8, @2; x4=x4+W64_i*x6 addc @8, @2; x5=x5+W64_j*x7 subc @10, @4; x6=x4-W64_i*x6 subc @10, @4; x7=x5-W64_j*x7 addc @14, @8; x0=x0+W64_i*x2 addc @14, @8; x1=x1+W64_j*x3 subc @16, @10; x2=x0-W64_i*x2 subc @16, @10; x3=x1-W64_j*x3 mulc @8, #IR3; W128_i*x4 mulc @8, #IR3, 0x0100; W128_j*x5 mulc @8, #IR3, 0x0200; W128_k*x6 mulc @8, #IR3, 0x0300; W128_l*x7 addc @8, @4; x0=x0+W128_i*x4 addc @8, @4; x1=x1+W128_j*x5 addc @8, @4; x2=x2+W128_k*x6 addc @8, @4; x3=x3+W128_l*x7 subc @12, @8; x4=x0-W128_i*x4 subc @12, @8; x5=x1-W128_j*x5 subc @12, @8; x6=x2-W128_k*x6 subc @12, @8; x7=x3-W128_l*x7 wrc @8, #IR0, x + 0 * 8; wrc @8, #IR0, x + 32 * 8; wrc @8, #IR0, x + 64 * 8; wrc @8, #IR0, x + 96 * 8; wrc @8, #IR0, x + 128 * 8; wrc @8, #IR0, x + 160 * 8; wrc @8, #IR0, x + 192 * 8; wrc @8, #IR0, x + 224 * 8; complete stop: jmp uart_init getl #ST0VAL wrdl @1, ticks complete .syntax V2 uart_init: jmp uart_print altport := getl 0xFFFFFFFF control := getl 0x00000003; rx, tx enable bitrate := getl 0x34; wrdl @control, 0xC0000108 wrdl @altport, 0xC00F0218 wrdl @bitrate, 0xC000010C setl #GPR0, 32 complete uart_print: count := getl #GPR0 je @count, finish jne @count, uart_wait setl #GPR0, #GPR0, -8 complete uart_wait: st := rddl 0xC0000104 andl @st, 2 je @1, uart_wait jne @2, uart_print_data complete uart_print_data: jmp uart_print data := rdl ticks slrl @data, #GPR0 wrdb @1, 0xC0000100 complete finish: getl 0; complete Comparison of the results of the implementation of integrated floating-point single-precision FFT by 256 points:
| Number of operations | Number of cycles | Number of operations per cycle | Availability of complex / SIMD operations | |
|---|---|---|---|---|
| Multiclet R1, Multiclet | 9400 | 2350 | four | complex |
| 1967BH034, Milandr | 10872 | 1812 | 6 | SIMD |
| Processors family C66x, TI | 14256 | 1782 | eight | complex |
| ADSP-TS201S, Analog Devices | 22272 | 1928 | 24 | SIMD |
The results show that the multicellular architecture implements parallelism more efficiently. This is most clearly seen when comparing with processors of the C66x family, which, like the multicellular processor, have commands of complex arithmetic that are executed in a stream per clock cycle.
From the presented examples in assembler, it is clear that the multicellular architecture allows to achieve much better results, so we believe that there is a prospect of improving the compiler.
At present, the compiler is successfully used to port software that has been developed to multicellular processors under contracts with Russian and foreign customer companies.
We invite everyone, enthusiasts of multicellular architecture to take part in testing the compiler on the forum .
UPD: Fixed a typo in the FFT results table: ADSP-TS201S returned a thousand clock cycles to the number of ticks.
')
Source: https://habr.com/ru/post/302776/
All Articles