Web scraping on Node.js and problem sites
 This is the second article in a series about creating and using scripts for web-scraping on Node.js.
This is the second article in a series about creating and using scripts for web-scraping on Node.js.
- Web scraping with Node.js
- Web scraping on Node.js and problem sites
- Node.js web scraping and bot protection
- Web scraping updated data with Node.js
The first article dealt with the simplest problem from the world of web scraping. In the overwhelming majority of cases, it is these tasks that get to web scraper - retrieving data from unprotected HTML pages of a stable website. Fast site analysis, HTTP requests using a needle (organized with the help of tress ), recursive passage through links, DOM parsing with the help of cheerio - that’s all.
This article deals with a more complicated case. Not one of those when you have to give up an order taken with a fight, but one of those that can be disrupted by a beginner scraper. By the way, this task was contained in a real order on one international freelance exchange, and the first performer failed it.
The purpose of this article (like the previous one) is to show the whole process of creating and using a script from setting the task to obtaining the final result, but the topics already covered in the first article are covered briefly here, so I recommend starting with the first article. Here the focus will be on analyzing the site from the point of view of web scraping, identifying pitfalls and ways to circumvent them.
Formulation of the problem
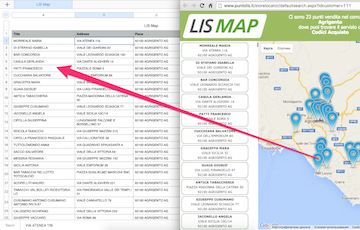 The customer wants a script that will receive data from the markers on the map in one of the sections of a certain site 'LIS Map' (link to the section is attached: ' http://www.puntolis.it/storelocator/defaultsearch.aspx?idcustomer=111 ') . It is not necessary to delve into the meaning of the data (anyway, everything is in Italian). It is enough if the script can take the lines from the markers and save them to a spreadsheet in the columns '
The customer wants a script that will receive data from the markers on the map in one of the sections of a certain site 'LIS Map' (link to the section is attached: ' http://www.puntolis.it/storelocator/defaultsearch.aspx?idcustomer=111 ') . It is not necessary to delve into the meaning of the data (anyway, everything is in Italian). It is enough if the script can take the lines from the markers and save them to a spreadsheet in the columns ' Title ', ' Address ' and ' Place '.
There are a lot of markers on the site, so they are organized in portions by region and are selected from the drop-down lists in two or three levels. Markers need everything. The order is not important.
It seems that the site has no convenient API. At least the customer does not know about it and is not noticeable on the site. So you have to scrap.
Site analysis
The first bad news is that the entire selection and display of data on the site occurs dynamically on the same page. It looks like this: when updating, a drop-down list is shown, after selecting an item, another drop-down list (and sometimes another one after it), and then a map of the selected region appears.
Finding words from markers in the source text of the page gives nothing. Search for words from the drop-down lists - too. Already at this stage it may seem that the site can only be scraped with tools like PhantomJS or Selenium WD , but it’s too early to despair. Most likely, the data is either contained in one of the connected scripts, or loaded dynamically. In any case, they can be found on the Network tab in Chrome DevTools or in a similar tool in another browser.
From the very beginning, along with the HTML of our landing page, static is loaded (images, CSS, a couple of scripts), and several requests are executed via XMLHttpRequest. Almost all requests load additional scripts and only one - something else. His address is:
http://www.puntolis.it/storelocator/buildMenuProv.ashx?CodSer=111 This is how it looks in the browser (screenshot is clickable):

We look at it and see the data for the first drop-down list as a fragment of HTML. Each item in the list (apparently it is called ' Provincia ') is represented by a fragment of this type:
<option value='AG' id='Agrigento'>Agrigento</option> Clear the Network tab and select one of the list items. Another XHR request is sent to the following address:
http://www.puntolis.it/storelocator/buildMenuLoc.ashx?CodSer=111&ProvSel=AG This is how it looks in the browser (screenshot is clickable):

The letters AG at the end of the address are the Agrigento province code from the previous list. Just in case, you can try with other provinces and make sure that this is how it works. In response to the request comes a fragment of HTML with the contents of the second drop-down list (it looks like this is called ' Comune '). Each item is represented here by this fragment:
<option value='X084001Agrigento' id='084001'>Agrigento</option> Select an item from the second list and a map appears on the page with markers whose data come in the form of XML in response to another XHR request here at this address:
http://www.puntolis.it/storelocator/Result.aspx?provincia=AG&localita=084001&cap=XXXXX&Servizio=111 This is how it looks in the browser (screenshot is clickable):
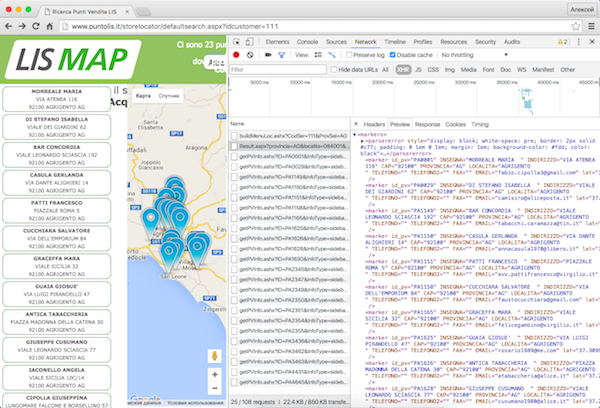
Looking at this address, it is easy to notice in it the letter code of the province of Agrigento (AG) and the numerical identifier of the commune of Agrigento (084001). Now we have all the address patterns to get a list of markers, each of which will be represented by this fragment:
<marker id_pv="PA1150" INSEGNA="CASULA GERLANDA " INDIRIZZO="VIA DANTE ALIGHIERI 14" CAP="92100" PROVINCIA="AG" LOCALITA="AGRIGENTO " TELEFONO="" TELEFONO2="" FAX="" EMAIL="annacasula1970@libero.it" lat="37.3088220" lon="13.5788890" CODSER="101,102,103,104,105,106,107,109,110,111,112,113,114,201,202,203,204,210,220,240,250,260,261,270,290,301,302,303,306,401,402" /> The fields we need are in the marker data, albeit in pieces.
( It is worth mentioning that on some sites the data can be encrypted, and then it is almost impossible to find them by simply searching for characteristic words. Fortunately, this happens very rarely. Everything is simpler on our site. )
Now we recall that for some provinces, the site does not give out two, but three levels of drop-down lists. In the data request after the second list, not the digital identifier of the commune is substituted, but its name, address is slightly different, and the answer is not a list of markers, but items of the third list.
This is how it looks in the browser (screenshot is clickable):
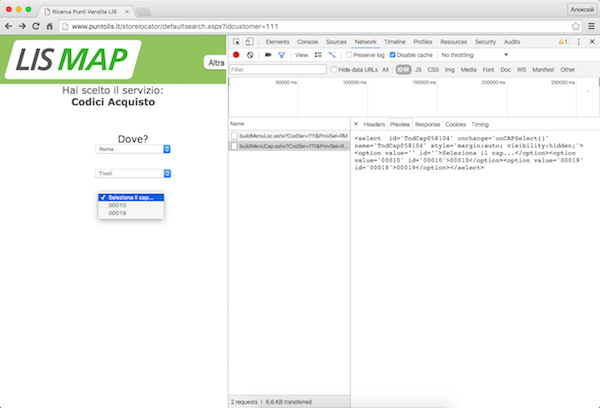
It may seem that we will have to handle different provinces in different ways, but before you get upset you should check everything out. If we manually substitute the necessary data into the template, we get a list of all the markers, for example, for the Tivoli commune in the province of Roma:
http://www.puntolis.it/storelocator/Result.aspx?provincia=RM&localita=058104&cap=XXXXX&Servizio=111 So you can forget about the third level. Apparently, the webmaster of our site was also too lazy to process requests for different provinces in different ways and just screwed the third level over the original two-level interface. Such crutches are often encountered, and if you check them, you can save time and cool the script.
Retrieving Pages
Using the http-client in the script in some detail versed in the first article. Here it is worth staying at only one moment.
The addresses we found can be opened in the browser and see their contents (HTML or XML, respectively), but only if the browser already has cookies installed from the main page of the section (link from the task). In the case of curl and with the http-client in the script, the situation is the same. This is the most primitive protection against bots, but it will have to take into account. This is the second bad news. At the very beginning, you must execute a request to the main page, save the received cookies and pass them along with each subsequent request.
Crawling
We have four types of URLs with which we will work:
- Main page (only needed to get cookies)
- List of provinces (we will begin with it)
- Community List Template
- Marker list template
Addresses based on lists will be added to the queue, and the data from the markers will be stored in an array. The whole crawling will look something like this:
var tress = require('tress'); var needle = require('needle'); var fs = require('fs'); // ( ): var sCookie = 'http://www.puntolis.it/storelocator/defaultsearch.aspx?idcustomer=111'; // URL. : var sProv = 'http://www.puntolis.it/storelocator/buildMenuProv.ashx?CodSer=111'; // ( %s): var sLoc = 'http://www.puntolis.it/storelocator/buildMenuLoc.ashx?CodSer=111&ProvSel=%s'; // ( %s): var sMarker = 'http://www.puntolis.it/storelocator/Result.aspx?provincia=%s&localita=%s&cap=XXXXX&Servizio=111'; var httpOptions = {}; var results = []; // var q = tress(crawl); q.drain = function(){ fs.writeFileSync('./data.json', JSON.stringify(results, null, 4)); } // needle.get(sCookie, function(err, res){ if (err || res.statusCode !== 200) throw err || res.statusCode; // httpOptions.cookies = res.cookies; // q.push(sProv); }); function crawl(url, callback){ needle.get(url, httpOptions, function(err, res){ if (err || res.statusCode !== 200) throw err || res.statusCode; // callback(); }); } In fact, everything looks like crawling from the previous article, only the installation of cookies is added by a separate request, the task handler is moved to a separate function, and the response code is checked in error handling.
Usually, if a customer asks to save data in Excel, CSV will be enough for him. Sometimes you can even agree on JSON (the benefit of free online converters is enough). But if the customer basically needs the xlsx file, you can use, for example, the excelize module or another similar wrapper. For example:
q.drain = function(){ require('excelize')(results, './', 'ADDR.xlsx', 'sheet', function(err){ if (err) throw err; console.log(results.length + ' adresses saved.'); }); } Parsing
Parsing well-organized HTML / XML chunks is much easier than cluttered pages, so everyone who figured out the parsing in the previous article should have this obvious without explanation. The block of parsing code will look like this:
var $ = cheerio.load(res.body); $('#TendinaProv option').slice(1).each(function() { q.push(sLoc.replace('%s', $(this).attr('value'))); }); $('select[onchange="onLocSelect()"] option').slice(1).each(function() { q.push(sMarker.replace('%s', url.slice(-2)).replace('%s', $(this).attr('id'))); }); $('marker').each(function() { results.push({ Title: $(this).attr('insegna').trim(), Address: $(this).attr('indirizzo').trim(), Place: [ $(this).attr('cap').trim(), $(this).attr('localita').trim(), $(this).attr('provincia').trim() ].join(' ') }); }); Especially it is worth paying attention to the slice method from cheerio . It works in exactly the same way as the same-name method for arrays. Specifically, here it is used before each to remove from the selections of the list items the first item that does not carry any useful information. But this is not something that makes the slice method worth knowing to every scraper using cheerio . The main thing is that when testing the scraping of sites with large samples, you can call slice(0,5) (well, or slice(1,5) in our case) before calling the each method to reduce the sample to acceptable sizes. Scrapping will work completely in combat mode, but not for so long.
( Important note : if you try to scrap the LIS Map, be sure to use slice . Habraeffect kills. )
Indication
There are at least two reasons not to neglect the indication here, as it was done last time.
Firstly, the LIS Map site is much less stable than Ferra.ru, so at the stage of the script’s launch launches it will be great to see what is happening.
Secondly, this time the customer does not want ready data, but a workable script that he can manually launch as needed. It is unlikely that the customer will like to be bored over and over again, looking at the frozen cursor in the terminal window and trying to guess how much time has passed, how much work has been completed during this time and is everything normal with this work. But he doesn't want to dig into long log files either, so heaped-up loggers like bunyan or winston will be a redundant solution here. He will need something simpler and more visual: a console indicator of progress, combined with an extremely laconic console logger reporting the most basic events.
Since the final amount of work is almost never known when web-scrapping (for recursive passage through links and so on), the standard progress indicator in the form of a filling bar will not work here. It is better to make a counter of completed tasks (a line with “running” numbers). You will also need to output various types of messages to the terminal, which will not overwrite the counter. Messages would be well accompanied by automatic time stamps.
It is for such tasks that the cllc module (Command line logger and counter) is created. With it, you can display a line with counters, and display messages.
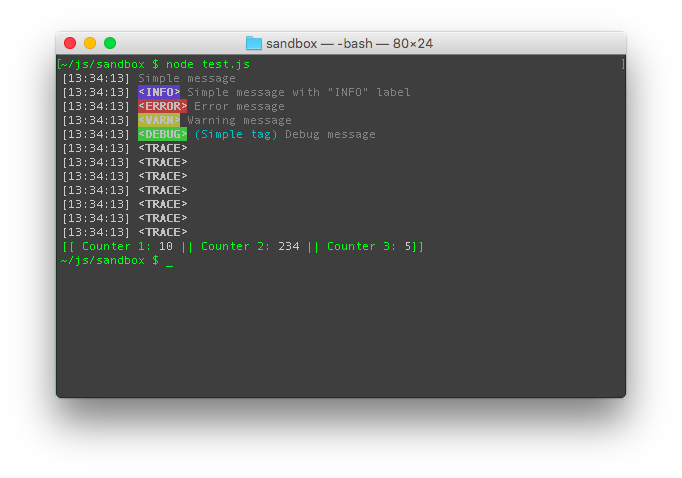
We need the following features of the cllc module:
var log = require('cllc')(); log('Message'); // log.e('Error message'); // <ERROR> // : log.start(' %s, %s, %s.'); log.step(); // 1. ( , log.step(1)) log.step(0, 1); // 1. log.step(0, 0, 1); // 1. log.finish(); // . Between calls to log.start and log.finish all messages will be displayed above the indicator without overwriting anything. All messages are accompanied by timestamps.
var log = require('cllc')(); var tress = require('tress'); var needle = require('needle'); var cheerio = require('cheerio'); var fs = require('fs'); var sCookie = 'http://www.puntolis.it/storelocator/defaultsearch.aspx?idcustomer=111'; var sProv = 'http://www.puntolis.it/storelocator/buildMenuProv.ashx?CodSer=111'; var sLoc = 'http://www.puntolis.it/storelocator/buildMenuLoc.ashx?CodSer=111&ProvSel=%s'; var sMarker = 'http://www.puntolis.it/storelocator/Result.aspx?provincia=%s&localita=%s&cap=XXXXX&Servizio=111'; var httpOptions = {}; var results = []; var q = tress(crawl); q.drain = function(){ fs.writeFileSync('./data.json', JSON.stringify(results, null, 4)); log.finish(); log(' '); } needle.get(sCookie, function(err, res){ if (err || res.statusCode !== 200) throw err || res.statusCode; httpOptions.cookies = res.cookies; log(' '); log.start(' %s, %s, %s.'); q.push(sProv); }); function crawl(url, callback){ needle.get(url, httpOptions, function(err, res){ if (err || res.statusCode !== 200) { log.e((err || res.statusCode) + ' - ' + url); log.finish(); process.exit(); } var $ = cheerio.load(res.body); $('#TendinaProv option').slice(1).each(function() { q.push(sLoc.replace('%s', $(this).attr('value'))); log.step(); }); $('select[onchange="onLocSelect()"] option').slice(1).each(function() { q.push(sMarker.replace('%s', url.slice(-2)).replace('%s', $(this).attr('id'))); log.step(0, 1); }); $('marker').each(function() { results.push({ Title: $(this).attr('insegna').trim(), Address: $(this).attr('indirizzo').trim(), Place: [ $(this).attr('cap').trim(), $(this).attr('localita').trim(), $(this).attr('provincia').trim() ].join(' ') }); log.step(0, 0, 1); }); callback(); }); } Run the script and see on the indicator that everything works. The script finds 110 provinces and 5116 communes, and then begins to collect markers. But it quickly crashes with a socket hang up error. When restarting, the error comes out immediately, even at the initialization stage. In the browser at this time, an error page is displayed with the code 500.
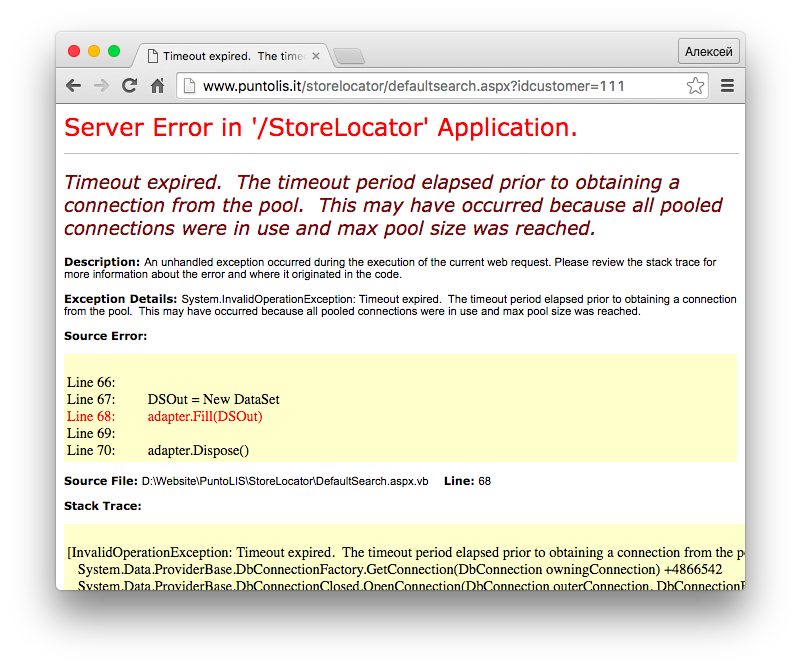
The error page states that a possible reason is that the allowed number of connections is exceeded. This refers to connections to the database, and not via http. Simply put, setting the connection: 'Keep-Alive' in the needle does not help us. The same page is issued in a different browser and on a different IP (that is, it is not a lock and the proxy will not help). Thus, the site is within about 20-30 minutes, as lucky. Then the situation repeats. As you probably guessed, this is the third bad news.
Error processing
The worst thing with such sites is that their scrapping is difficult to test. It is necessary to run the script with the wrong parameter - and you will have to wait more than 20 minutes to try again. Without indication, it would be quite sad, and in just a few launches we can determine that the site drops every time after three with a few saved markers. After playing a little with the counters, it can be established that we are talking about about a hundred and fifty communes. This means that if our script does not terminate after an error, but waits until the site rises and continues, it will stop more than 30 times. That is, the work of the script will take 10-15 hours.
Not the fact that this option will suit the customer. Perhaps he would prefer to close the order by paying for the time already spent. However, before you grieve the customer is to check another option.
It is possible that we too often bomb the site with queries. It is worth trying to establish a delay between requests and see what happens. Technically, this is very easy to do, we don’t even have to write anything. The tress module has a concurrency property, familiar to async.queue users. This property is set when creating the queue with the second parameter (by default, concurrency is 1) and indicates how many parallel threads the tasks will be processed. Only tress concurrency can have negative values, meaning that there should be a delay between tasks in a single thread. For example, if you set concurrency to -1000, this would mean a delay of 1000 milliseconds. The async.queue interface is sacrificed for compatibility with async.queue , but if you know, everything is simple.
It remains to decide what should be the delay. Simple calculations show that with a delay of 10 seconds, our 5227 queries (1 list of provinces, 110 lists of communes and 5116 lists of markers) will take more than 14 hours. That is, even if during this time the site does not fall - in time we won’t win anything. On the other hand, even 100 milliseconds in the http world is quite a noticeable delay. First, let's try to set a delay of 1 second.
var q = tress(crawl, -1000); Nothing has changed, the site is still falling after three with a little found markers. To clear your conscience, try a delay of 3 seconds.
var q = tress(crawl, -3000); The site falls after the first seven hundred markers. It would be possible to continue experimenting with more delays, but firstly there won't be any cardinal winnings anymore, and secondly, we cannot guarantee that the site will not fall down. Thus, we have only one working option left - in case of an error, return the task to the queue, put the entire queue on pause, and then resume scrapping until the next error, and so - 10-20 hours.
Here at this stage, you can ask the customer whether such a slow script will suit him, given that no one will do it much faster. Here we will proceed from the assumption that the customer has agreed.
So, we need to make sure that if the http request fails, the corresponding address is returned to the queue, and the queue itself is paused for the specified time. All this is perfectly implemented by the standard features of the tress module, which distinguishes it from async.queue .
In the tress queue, any task is in one of four states:
- Awaiting execution
- Performed
- Successfully completed
- Recognized impracticable
All these tasks are presented to the developer in the form of four arrays that are accessible by the q.waiting, q.active, q.finished and q.failed properties. During any debugging experiments, the contents of these arrays can even be changed live, but you shouldn’t do this in working scripts. And there is no need for such hacking, because everything happens automatically. When the task is passed to the handler, it is transferred from the waiting array to the active array, where it remains until the callback is called. After calling the callback, the task is transferred from active to one of the three remaining arrays. Which one depends on the parameters of the callback:
- If the callback is called without parameters or if the first parameter is null, the task is considered completed and placed in the finished array.
- If the first callback parameter is of type boolean, then the task is returned for reprocessing and placed at the beginning of the queue (beginning of the waiting array), if the parameter is true, or at the end of the queue (end of the waiting array), if the parameter is false.
- If the first callback parameter is an error object (instanceof Error), then the task is moved to the failed array.
- For any other values of the first callback parameter, the behavior of the module is undefined and may change in subsequent versions (so it is better not necessary).
After moving the task from active to another array, tress calls one of the three handlers: q.success, q.retry or q.error, respectively. It is important that in single-threaded mode (concurrency <= 1) the execution of the handler is completed before the next task starts. This allows us to do the following:
Handling an error request will do so:
function crawl(url, callback){ needle.get(url, httpOptions, function(err, res){ if (err || res.statusCode !== 200) { log.e((err || res.statusCode) + ' - ' + url); return callback(true); // url } // callback(); }); } And add, for example, such a q.retry handler:
var q = tress(crawl); q.retry = function(){ q.pause(); // this . log.i('Paused on:', this); setTimeout(function(){ q.resume(); log.i('Resumed'); }, 300000); // 5 } This script successfully completes the scrapping in 14 hours, as expected.
I put the delay on 5 minutes. If the site has not yet woken up, the error just fell out again, and if you woke up, you will not have to wait in vain. , , .
– ( concurrency). :
var q = tress(crawl); q.success = function(){ q.concurrency = 1; } q.retry = function(){ q.concurrency = -300000; // 5 } Conclusion
( gist ). , node- Windows, .
, , (. ) . , . - , http- - .
, (, Ctrl-C, ), . - , , 14 – , – . – , . .
')
Source: https://habr.com/ru/post/302766/
All Articles