As we did the centralized data storage for the retail network and optimized it step by step.
After we talked about transferring the storages of hundreds of branches of a large bank to the central data center, using Riverbed solutions, we decided to dive a bit technically into the “stack” component of the products, and at the same time to think about the option of data consolidation, for example, with a large retailer, to check the effectiveness of the systems SteelFusion Core and Edge, as well as evaluate the engineering efforts and customer benefits.
In our experience, the typical regional branch of the retailer is built on a pair of network switches, a pair of servers, a tape library and a cleaner who changes tapes. Sometimes the library prefer an external drive. Cartridges can simply be stored, and can be exported at regular intervals. The same with the external drive. The width of the WAN channel is limited to a pair of Mbps and rarely reaches high values.
The infrastructure of the retailer’s central office is a bit more complicated: there are a large number of servers, mid-range storage systems, and even backup sites. Therefore, in general, the idea of consolidating the data of regional branches of the retailer is applicable for such a case. We assembled a test stand in our shop in a matter of hours. That's what happened.
')

We took one of the laboratories as an imaginary central office (DPC), where we deployed vCenter and assembled a simple HA cluster ...
In the lab that serves as the branch, we installed a single piece of metal Edge. A narrow channel was imitated by a WANem emulator, obtaining characteristics of a bandwidth of 2048–3072 kbit / s with a delay of 20 ms. Packet losses in testing did not simulate.
Data blocks between sites make movements after compression and deduplication of a stream by iSCSI traffic by the optimizer. Simplified scheme for better understanding - below.

For the projection of disk space in the branch, the SteelFusion Core (SFC) gateway is used. We installed it as a virtual machine in the data center. To optimize traffic in the data center, we also used the virtual SteelHead VCX, which was configured with the appropriate traffic interception rule and redirected through the optimizer.
The branch line is designed in an original way. The Edge server (in our case, 3100) is divided into two nodes:
• RiOS node, responsible for the operation of Riverbed services (traffic optimization, control of blockstore, hypervisor, etc.).
• An ESXi hypervisor node pre-configured on the network.
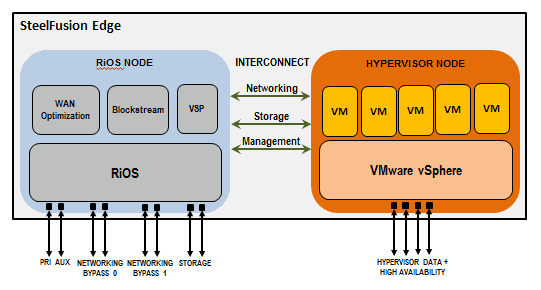
The drives in the server are cache blockstore Edge. It is controlled only by the RiOS node, which, in turn, allocates space equal to the moon in the cache for ESXi. At the same time, access of the ESXi-node to the blockstore (actually to the disks in the same iron box) is carried out via iSCSI protocol at a speed of 1 Gbit / s through an internal interconnect.
In our configuration we had 4 2TB SATA 7.2K disks in RAID10 and 4 SSD 240 GB disks also in RAID10. There are no Hot-spare disks, but you can force the failed disk back to the group from under the CLI. This is useful when you need to recover data if several disks fail at once. Just under the blockstore is available a little more than 3 TB.
It is difficult to make a mistake in setting up routing and optimizing Rdisk traffic if you do everything right. There are clear patterns to follow. Otherwise, as a bonus to the crazy system, there are constant breaks of the direct linking Edge - Core, unstable operation of RiOS connections and a bad mood, which we first got by banal traffic from Edge to the wrong VCX optimizer interface.
When finally Zen was acquired, we began testing typical operations with the Edge repository. Under mixed load, taking into account caching on SSD disks, we obtained a performance corresponding to the interconnect speed, with an acceptable response time.

Then we decided to overload Edge with a virtual machine with Exchange and through LoadGen imitated the active work of about 500 people. In this case, the VM operating system was installed on a vmdk disk, and the Exchange itself was installed on a 150 GB RDM.
It is clear that SFED is not designed for such loads, but what the hell is not joking ... Additionally, we decided to play around with the breaking of the Core-Edge bundle to ensure the correct behavior and stability of the system.
With working optimization and reducing the amount of transmitted data up to 90%, the blockstore cache was filled so rapidly that it not only did not have time to replicate, but also hung up the system. When the SFED with enviable appetite swallowed 3 TB of space in the blockstore, the host began to receive write errors.

As it turned out, our configuration was not correct in terms of demonstrating how to optimize traffic. The reasons are as follows:
And from this moment more in detail.
Different types of formatting of VMDK disks are cached differently in blockstore.
Example: VMDK-disk with a capacity of 100 GB with used 20 GB
So, the blockstore is most efficiently utilized when using thin volumes. A double increase in the number of cached and replicated data is observed when using Lazy Zeroed disks due to the vanishing of VMFS Datastore blocks during the first recording. The most “voracious” is the Eager Zeroed method, since zero blocks for the entire volume and blocks of recorded data are cached. Further testing of caching disks of various types led to the expected results - the cache was filled only as much as it should.
Our next step was to test the efficiency of using the system when deploying a new infrastructure. We reset the cache blockstore for the purity of the experiment, prepared in the data center VMFS-storage with a virtual machine and started.
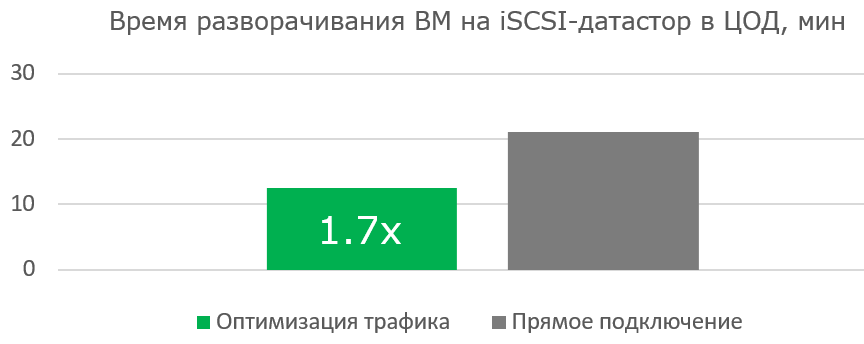

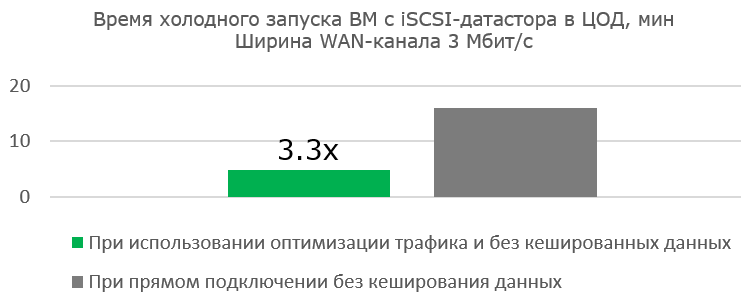
Working with a wide channel is not as effective when you first boot the finished virtual machine. But the work of the VM itself is noticeably faster, since less and less useful blocks are transferred, and the Read Hit in the blockstore cache becomes more and more.
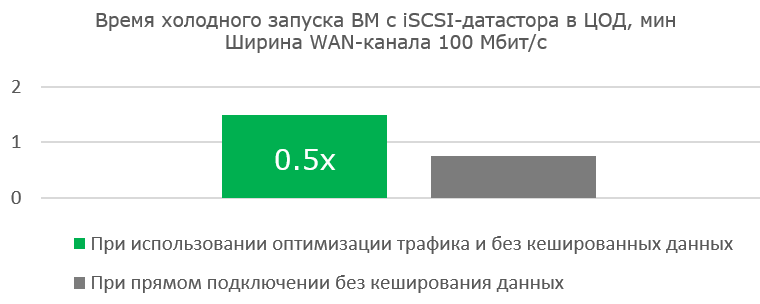
The advantages of optimization are obvious where there is practically no channel.
When we installed the VM on the Edge, we, of course, placed the boot image on the projected datastore, thereby preventing it from being cached in the blockstore in advance.
The process of installing the VM and the results of the optimization of the transmitted data:

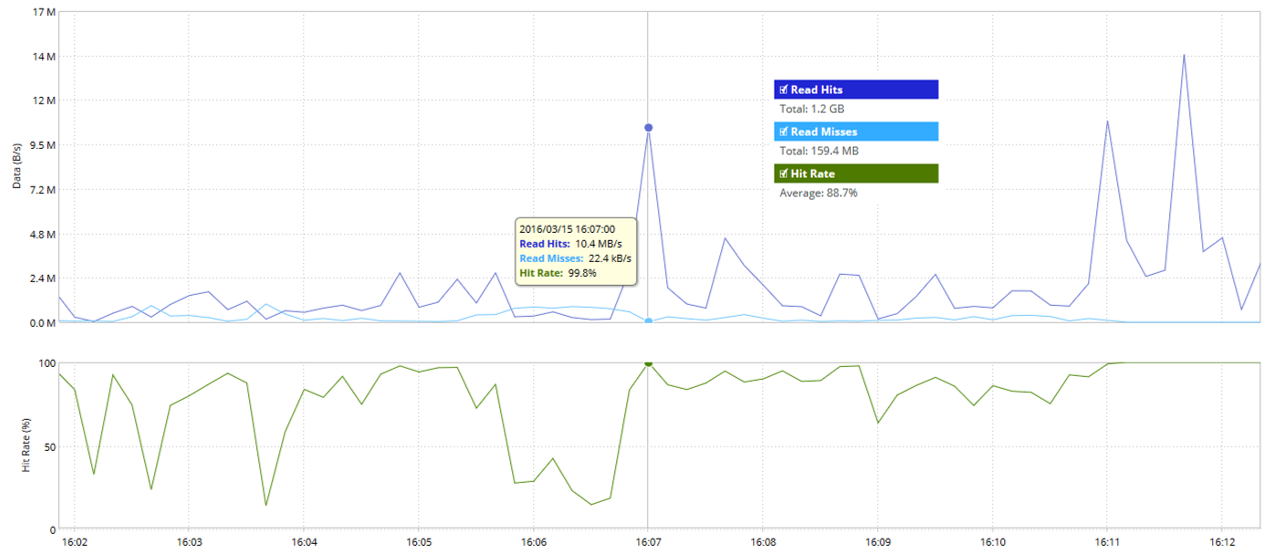
Statistics blockstore on Read Hit and Read Miss:
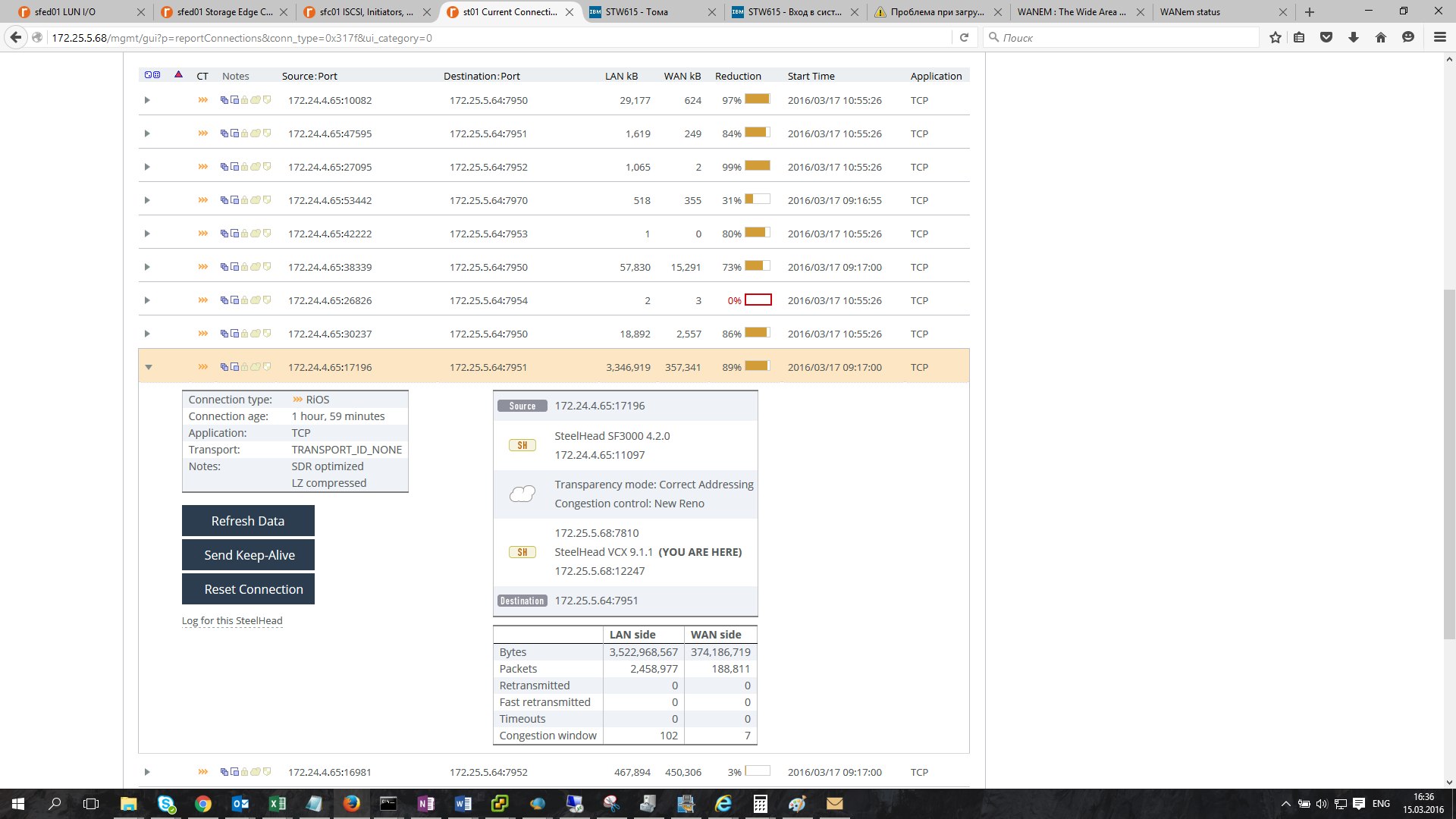
TCP connection optimization statistics:
Load WAN-and LAN-channels:

Here we can see how, in fact, the WAN channel is utilized and what actual data transfer rate is provided by traffic optimization.
An hour later, our newly installed VM completely moved to the data center. On the graph we see how the volume of replicated data decreases.

The main question remained: how to back up the whole thing, and preferably with a greater degree of automation? Answer: use the built-in Edge-Core snapshots functionality.
Snapshots can be of two types - Application Consistent (the application writes data buffers to disk, after which a volume is taken) and Crash Consistent (a snapshot of the volume without recorded data from the buffers is equivalent to running the application after an abnormal termination).
Application Consistent snapshots work with virtual machines through VMWare Tools when using VMDK, as well as through VSS in the case of NTFS.
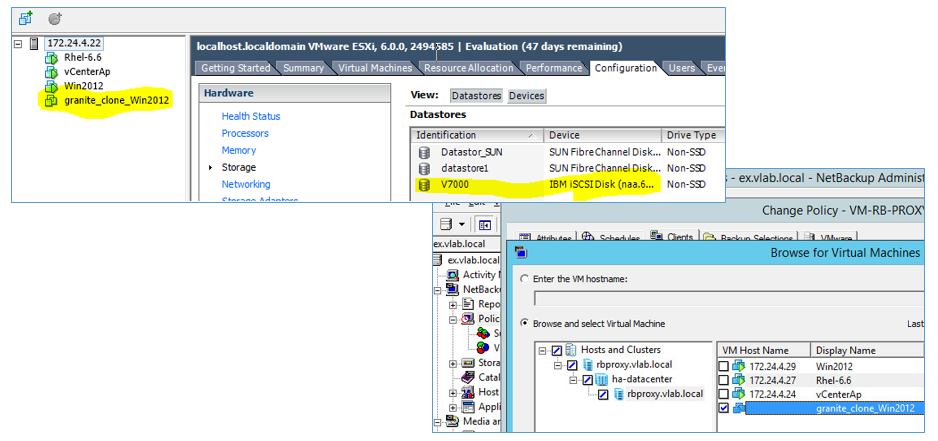
We tested this functionality in conjunction with ESXi and IBM Storwize V7000 storage systems.
How it works:
Mechanism:
And that's all. Virtual machines are available for backup by any vSphere compatible software. We took Netbackup and successfully backed up the test machine.
As a result, what we get: using separate servers and local disks in servers is cheap and fast, but there are issues with long-term data storage and a lot of overhead. In this case, backup, of course, can be done both on a tape in a branch office, and using various software, for example, CommVault with its own deduplication and traffic compression mechanisms.
In the case of data consolidation in the data center using SteelFusion, you must initially have the appropriate amount of resources for storing regional data and their backup. Additional savings on backup are possible if Proxy Backup servers are licensed in the data center by the number of sockets depending on the planned load of the branches.
If we consider the classical layout of the branch and its approximate cost for key positions, we get the following picture:
Using SteelFusion branch configurations, we get:
In the data center we put two virtual machines SteeFusion Core and two iron Steelheads.
Considering TCO for 5 years, we get savings of at least $ 300,000 using the SteelFusion solution. And this is without additional overhead in the classic version. And taking into account the possibility of compressing not only block replication stream, but also various application protocols, it is possible to further reduce the cost of communication channels.
In our experience, the typical regional branch of the retailer is built on a pair of network switches, a pair of servers, a tape library and a cleaner who changes tapes. Sometimes the library prefer an external drive. Cartridges can simply be stored, and can be exported at regular intervals. The same with the external drive. The width of the WAN channel is limited to a pair of Mbps and rarely reaches high values.
The infrastructure of the retailer’s central office is a bit more complicated: there are a large number of servers, mid-range storage systems, and even backup sites. Therefore, in general, the idea of consolidating the data of regional branches of the retailer is applicable for such a case. We assembled a test stand in our shop in a matter of hours. That's what happened.
')
We took one of the laboratories as an imaginary central office (DPC), where we deployed vCenter and assembled a simple HA cluster ...
In the lab that serves as the branch, we installed a single piece of metal Edge. A narrow channel was imitated by a WANem emulator, obtaining characteristics of a bandwidth of 2048–3072 kbit / s with a delay of 20 ms. Packet losses in testing did not simulate.
Data blocks between sites make movements after compression and deduplication of a stream by iSCSI traffic by the optimizer. Simplified scheme for better understanding - below.
For the projection of disk space in the branch, the SteelFusion Core (SFC) gateway is used. We installed it as a virtual machine in the data center. To optimize traffic in the data center, we also used the virtual SteelHead VCX, which was configured with the appropriate traffic interception rule and redirected through the optimizer.
The branch line is designed in an original way. The Edge server (in our case, 3100) is divided into two nodes:
• RiOS node, responsible for the operation of Riverbed services (traffic optimization, control of blockstore, hypervisor, etc.).
• An ESXi hypervisor node pre-configured on the network.
The drives in the server are cache blockstore Edge. It is controlled only by the RiOS node, which, in turn, allocates space equal to the moon in the cache for ESXi. At the same time, access of the ESXi-node to the blockstore (actually to the disks in the same iron box) is carried out via iSCSI protocol at a speed of 1 Gbit / s through an internal interconnect.
In our configuration we had 4 2TB SATA 7.2K disks in RAID10 and 4 SSD 240 GB disks also in RAID10. There are no Hot-spare disks, but you can force the failed disk back to the group from under the CLI. This is useful when you need to recover data if several disks fail at once. Just under the blockstore is available a little more than 3 TB.
It is difficult to make a mistake in setting up routing and optimizing Rdisk traffic if you do everything right. There are clear patterns to follow. Otherwise, as a bonus to the crazy system, there are constant breaks of the direct linking Edge - Core, unstable operation of RiOS connections and a bad mood, which we first got by banal traffic from Edge to the wrong VCX optimizer interface.
When finally Zen was acquired, we began testing typical operations with the Edge repository. Under mixed load, taking into account caching on SSD disks, we obtained a performance corresponding to the interconnect speed, with an acceptable response time.
Then we decided to overload Edge with a virtual machine with Exchange and through LoadGen imitated the active work of about 500 people. In this case, the VM operating system was installed on a vmdk disk, and the Exchange itself was installed on a 150 GB RDM.
It is clear that SFED is not designed for such loads, but what the hell is not joking ... Additionally, we decided to play around with the breaking of the Core-Edge bundle to ensure the correct behavior and stability of the system.
What is interesting noticed
With working optimization and reducing the amount of transmitted data up to 90%, the blockstore cache was filled so rapidly that it not only did not have time to replicate, but also hung up the system. When the SFED with enviable appetite swallowed 3 TB of space in the blockstore, the host began to receive write errors.
As it turned out, our configuration was not correct in terms of demonstrating how to optimize traffic. The reasons are as follows:
- The RDM disk is cached in the blockstore, but during replication the stream is not deduplicated. Optimization only works with VMFS storage and VMDK disks inside them. Hence the extremely slow replication of the volume with Exchange.
- Exchange file in our virtual machine was actively involved in the paging file that lay on the OS system disk inside the datastor. Accordingly, it was he and his dynamic changes that fell under optimization. Hence a large percentage of the reduction in the amount of data on the graphs and hasty triumph.
- The disproportionate filling of the cache is due to the type of disk Thick, Lazy Zeroed used for the system.
And from this moment more in detail.
Different types of formatting of VMDK disks are cached differently in blockstore.
Example: VMDK-disk with a capacity of 100 GB with used 20 GB
Vmdk type | WAN traffic usage | Space utilized array thick luns | Space utilized on array thin luns | Vmdk fragmentation |
Thin | 20 GB | 20 GB | 20 GB | High |
Thick eager Zero | 100 GB + 20 GB = 120 GB | 100 GB | 100 GB | None (flat) |
Thick lazy zero (default) | 20 GB + 20 GB = 40 GB | 100 GB | 20 GB | None (flat) |
So, the blockstore is most efficiently utilized when using thin volumes. A double increase in the number of cached and replicated data is observed when using Lazy Zeroed disks due to the vanishing of VMFS Datastore blocks during the first recording. The most “voracious” is the Eager Zeroed method, since zero blocks for the entire volume and blocks of recorded data are cached. Further testing of caching disks of various types led to the expected results - the cache was filled only as much as it should.
Our next step was to test the efficiency of using the system when deploying a new infrastructure. We reset the cache blockstore for the purity of the experiment, prepared in the data center VMFS-storage with a virtual machine and started.
Virtual machine OS | Ubuntu | Ubuntu |
Virtual machine storage | Data Center via Core | Data center |
VM disk space | 16 GB | 16 GB |
Volume of boot data | ~ 370 MB | |
WAN channel width | 100 Mbps | |
Working with a wide channel is not as effective when you first boot the finished virtual machine. But the work of the VM itself is noticeably faster, since less and less useful blocks are transferred, and the Read Hit in the blockstore cache becomes more and more.
The advantages of optimization are obvious where there is practically no channel.
When we installed the VM on the Edge, we, of course, placed the boot image on the projected datastore, thereby preventing it from being cached in the blockstore in advance.
The process of installing the VM and the results of the optimization of the transmitted data:
Statistics blockstore on Read Hit and Read Miss:
TCP connection optimization statistics:
Load WAN-and LAN-channels:
Here we can see how, in fact, the WAN channel is utilized and what actual data transfer rate is provided by traffic optimization.
An hour later, our newly installed VM completely moved to the data center. On the graph we see how the volume of replicated data decreases.
The main question remained: how to back up the whole thing, and preferably with a greater degree of automation? Answer: use the built-in Edge-Core snapshots functionality.
Snapshots can be of two types - Application Consistent (the application writes data buffers to disk, after which a volume is taken) and Crash Consistent (a snapshot of the volume without recorded data from the buffers is equivalent to running the application after an abnormal termination).
Application Consistent snapshots work with virtual machines through VMWare Tools when using VMDK, as well as through VSS in the case of NTFS.
We tested this functionality in conjunction with ESXi and IBM Storwize V7000 storage systems.
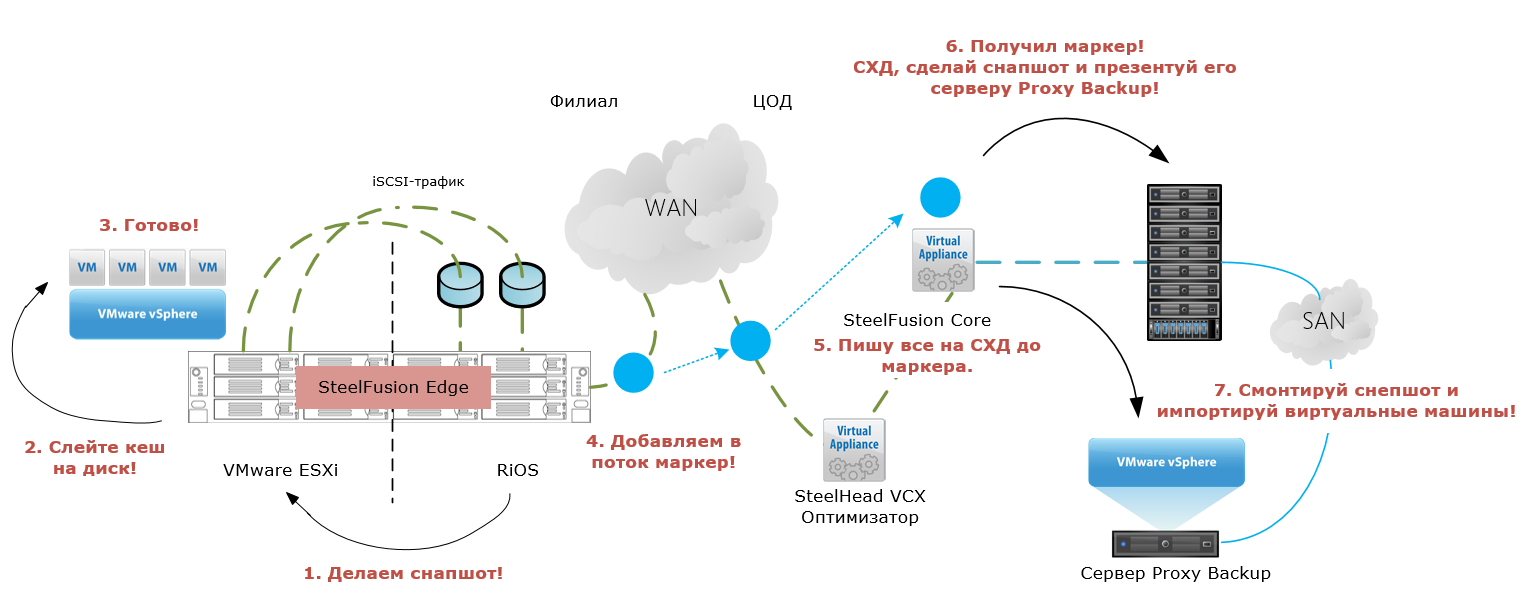
How it works:
Mechanism:
- Edge sends an ESXi-host command to create Application Consistent snapshots according to the specified schedule.
- When receiving a command, the ESXi host sends a command to the guest VM via VMware Tools to write data from its buffers.
- After flushing buffers are completed, Edge places a special token in the data stream replicated to the data center (commit string).
- Edge connects to the previous ESXi host and removes the previously taken snapshot.
- The marker in the WAN channel reaches the Core, all data before the marker is written to the moon on the disk array.
- After writing data to the Core marker, the disk array is invoked with the command to initialize the moon snapshot.
- After the disk array has created a snapshot, Core connects to the Proxy-Backup server also on ESXi, deregisters past VMs and disables the datastore.
- Then Core connects to the disk array again, creates a snapshot clone and presents it from the array to the proxy server.
- After this, Core instructs the proxy server to mount the snapshot and import the virtual machines.
And that's all. Virtual machines are available for backup by any vSphere compatible software. We took Netbackup and successfully backed up the test machine.
As a result, what we get: using separate servers and local disks in servers is cheap and fast, but there are issues with long-term data storage and a lot of overhead. In this case, backup, of course, can be done both on a tape in a branch office, and using various software, for example, CommVault with its own deduplication and traffic compression mechanisms.
In the case of data consolidation in the data center using SteelFusion, you must initially have the appropriate amount of resources for storing regional data and their backup. Additional savings on backup are possible if Proxy Backup servers are licensed in the data center by the number of sockets depending on the planned load of the branches.
If we consider the classical layout of the branch and its approximate cost for key positions, we get the following picture:
Classic layout (branch) | Estimated cost, $ |
2 x Server (1 CPU, 32GB RAM, 5 × 600GB HDD) | 20,000 |
Tape library (1 drive) | 10,000 |
Extended support (24/7 / 6h), 1 year | 7,000 |
VMware vSphere Std .: license for 2 sockets | 4,000 |
Subscription for 2 sockets, 1 year | 1,500 |
Backup: license for 2 sockets | 2,000 |
Support, 1 year | 5,000 |
CAPEX (first year) | 49 500 |
OPEX (next 4 years) | 54,000 |
TCO (5 years) | 103 500 |
TCO for 30 branches (5 years) | 3,105,000 |
Using SteelFusion branch configurations, we get:
Layout SteelFusion (branch) | Estimated cost, $ |
Equipment: | |
2 x SteelFusion Edge 2100 | 31,000 |
Hardware and software support: | |
SteelFusion Edge Appliance 2100 Gold Support, 1 year | 9 500 |
Software licenses: | |
VSP, BlockStream, WAN Opt (1500 Connections, 20 Mbps) | 7 800 |
CAPEX (first year) | 48 300 |
OPEX (next 4 years) | 38,000 |
TCO (5 years) | 86 300 |
TCO (30 branches, 5 years) | 2,589,000 |
In the data center we put two virtual machines SteeFusion Core and two iron Steelheads.
Layout SteelFusion (DPC) | Estimated cost, $ |
Equipment: | |
2 x SteelFusion Core VGC-1500 | 46,800 |
2 x SteelHead CX 770 | 30,400 |
Equipment support, 1 year: | |
SteelFusion Core Virtual Appliance 1500 Gold Support, 1 year | 9,400 |
SteelHead CX Appliance 770 Gold Support, 1 year | 5,400 |
Software licenses: | |
License SteelHead CX | 21,600 |
CAPEX (first year) | 113,600 |
OPEX (next 4 years) | 59 200.00 |
TCO (data center, 5 years) | 172 800 |
Considering TCO for 5 years, we get savings of at least $ 300,000 using the SteelFusion solution. And this is without additional overhead in the classic version. And taking into account the possibility of compressing not only block replication stream, but also various application protocols, it is possible to further reduce the cost of communication channels.
Links
- The said transfer of hundreds of branches to the center without loss of speed in the bank
- Likbez about traffic optimization
- Network detective example
- History channel optimization for mineral deposits in the terrible cold
- Brain-blowing educational campaign about distributed and storage systems
- Bikes of our unit to relax
- Well, my mail is Smesilov@croc.ru
Source: https://habr.com/ru/post/302760/
All Articles