Dynamic non-uniform tightly packed container
Definition 1 . A homogeneous container is such a container in which objects of exactly one type are stored.
Definition 2 . A heterogeneous container is a container in which objects of different types can be stored.
Definition 3 . A static container is a container whose composition is completely determined at the compilation stage.
The composition in this case refers to the number of elements and their types, but not the values of these elements themselves. Indeed, there are containers in which even the values of elements are determined at the compilation stage, but in this model such containers are not considered.
Definition 4 . A dynamic container is a container whose composition is partially or completely determined at the execution stage.
According to this classification, obviously, there are four types of containers:
Static homogeneous
Can you think of an example?A regular array is
int[n].Static heterogeneous
Examples?The most striking example of such a container is a tuple. In C ++, it is implemented by the class
std::tuple<...>.Dynamic homogeneous
Guess?That's right,
std::vector<int>.Dynamic inhomogeneous
That's about this type of container and will be discussed in this article.
Content
- Dynamic inhomogeneous containers
- Dynamic tuple
- Data storage
- Handlers
- Data access
- Exception Life and Safety
- Other problems
- Performance measurements
- Links
Dynamic inhomogeneous containers
There are several techniques for obtaining a dynamic inhomogeneous container. Here are the three, perhaps the most common ones:
Array of pointers to the polymorphic class
Selection
Trusabalbesaexperienced fieldman.struct base { virtual ~base() = default; ... }; struct derived: base { ... }; std::vector<std::unique_ptr<base>> v;Array of associations
The union can be understood as a language possibility of the
union, as well as a library class of typeboost::variant(std::variantwill appear in C ++ 17).Array of arbitrary objects using erase type
For example,
boost::any(std::anywill appear in C ++ 17) into which you can put anything.
Each of these techniques has its advantages and disadvantages, and we will definitely consider them.
And now it's time to highlight the point, which until this moment remained in the shadow, despite the fact that it is part of the title (and essence) of the article.
Definition 5 . A tightly packed container is a container whose elements lie in a continuous area of memory, and there are no gaps between them (with alignment accuracy).
int[n] , std::vector<int> , std::tuple<...> .
Unfortunately, not every tightly packed container is dynamic inhomogeneous. And we need just such.
But back to the advantages and disadvantages of the above techniques for obtaining dynamic inhomogeneous containers.
Array of pointers to the polymorphic class
Benefits:
Relative ease of implementation
Inheritance, polymorphism, everything. Even a beginner knows these things (fortunately or unfortunately?).
Easy to introduce new entities.
No additional actions are required in order to be able to insert a new object into the array. You only need to create a new heir to the base class.
And there is no need to recompile the code depending on the array of pointers.
Disadvantages:
Hierarchy dependency
Only objects inherited from a certain base class can be added to an array.
Code redundancy
For each new element, you need to create a new class in the hierarchy. That is, if I want to put two types of numbers into a container - integers and buoys - then I will have to get the base class "number" and its two corresponding heirs.
Loose packaging
In the array are only pointers, and the objects themselves are scattered in memory. This, in general, will adversely affect the operation of the cache.
Array of associations
Benefits:
Hierarchy independence
In the array, you can put any type specified in the union.
Objects lie in a continuous memory area.
The array does not store the pointer, but the object itself.
Disadvantages:
Dependence on the set of objects included in the union
When adding a new object to the union, you need to recompile all the code, which obviously depends on our array of associations.
Loose packaging
Yes, objects lie in a continuous area of memory. But we would like to get a tight package, and for this it is necessary that there are no voids between the objects. And voids can be.
The point is that the size of the union is equal to the size of the largest type of this union. For example, if the union includes two types -
Xandchar, withsizeof(X) = 32, then eachcharwill occupy 32 bytes, although one would be quite enough.
Array of arbitrary objects using erase type
Benefits:
Complete independence
At any time in such an array, you can put any type, and you do not have to recompile anything that depends on this array.
Disadvantages:
Loose packaging
As in the case of an array of pointers, the objects of such an array are scattered in memory (in general, this is not the case, because optimization of small objects can be used, but for large enough objects this is always true).
Dynamic tuple
So, none of the above approaches implies a tight pack. Therefore, we need to develop another approach to creating a dynamic inhomogeneous container, which, among other things, will provide the coveted tight packaging.
In order to do this, you first need to get a better look at any . Working with him happens like this:
int main () { // . auto a = any(1); assert(any_cast<int>(a) == 1); // . any_cast<int>(a) = 42; assert(any_cast<int>(a) == 42); // . a = std::string(u8"!"); assert(any_cast<std::string>(a) == std::string(u8"!")); } How it works?
Do not take this code too close to your heart; this is a schematic implementation. Behind this implementation should refer to a more authoritative source .
#include <cassert> #include <utility> enum struct operation_t { clone, destroy }; using manager_t = void (*) (operation_t, const void *, void *&); // `any` , // . template <typename T> void manage (operation_t todo, const void * source, void *& destination) { switch (todo) { case operation_t::clone: { destination = new T(*static_cast<const T *>(source)); break; } case operation_t::destroy: { assert(source == nullptr); static_cast<T *>(destination)->~T(); break; } } } class any { public: any (): m_data(nullptr), m_manager(nullptr) { } any (const any & that): m_manager(that.m_manager) { m_manager(operation_t::clone, that.m_data, this->m_data); } any & operator = (const any & that) { any(that).swap(*this); return *this; } any (any && that): m_data(that.m_data), m_manager(that.m_manager) { that.m_manager = nullptr; } any & operator = (any && that) { any(std::move(that)).swap(*this); return *this; } ~any () { clear(); } // "" . // "", // . , , // , "" : . template <typename T> any (T object): m_data(new T(std::move(object))), m_manager(&manage<T>) { } template <typename T> any & operator = (T && object) { any(std::forward<T>(object)).swap(*this); return *this; } template <typename T> friend const T & any_cast (const any & a); template <typename T> friend T & any_cast (any & a); void clear () { if (not empty()) { m_manager(operation_t::destroy, nullptr, m_data); m_manager = nullptr; } } void swap (any & that) { std::swap(this->m_data, that.m_data); std::swap(this->m_manager, that.m_manager); } bool empty () const { return m_manager == nullptr; } private: void * m_data; manager_t m_manager; }; // , , . // : // // `any_cast<int>(a) = 4;` // template <typename T> const T & any_cast (const any & a) { return *static_cast<const T *>(a.m_data); } template <typename T> T & any_cast (any & a) { return *static_cast<T *>(a.m_data); } As you already understood, the dynamic tuple (DC) will be the development of an idea with any . Namely:
- As in the case of
any, an erase type technique will be applied: the object types will be "forgotten", and for each object a "manager" will be set up, who will know how to work with this object. - The objects themselves will be stacked one after another (taking into account alignment) into a continuous memory area.
It will work in a manner similar to any :
// . auto t = dynamic_tuple(42, true, 'q'); // . assert(t.size() == 3); // . assert(t.get<int>(0) == 42); ... // . t.push_back(3.14); t.push_back(std::string("qwe")); ... // . t.get<int>(0) = 17; Need more code
Well, let's get down to the most interesting .
Data storage
As follows from the definition of a dense package, all objects are stored in a single continuous piece of memory. This means that for each of them, in addition to the handlers, you need to keep its indent from the beginning of this piece of memory.
Great, let's get a special structure for this:
struct object_info_t { std::size_t offset; manager_t manage; }; Further, it will be necessary to store the piece of memory itself, its size, and also separately it will be necessary to remember the total volume occupied by the objects.
We get:
class dynamic_tuple { private: using object_info_container_type = std::vector<object_info_t>; ... std::size_t m_capacity = 0; std::unique_ptr<std::int8_t[]> m_data; object_info_container_type m_objects; std::size_t m_volume = 0; }; Handlers
So far, the type of the manager_t handler remains undefined.
There are two main options:
Structure with "methods"
As we already know from
any, several operations are needed to control an object. In the case of DC, this is, at a minimum, copying, transfer and destruction. For each of them, you need to create a field in the structure:struct manager_t { using copier_type = void (*) (const void *, void *); using mover_type = void (*) (void *, void *); using destroyer_type = void (*) (void *); copier_type copy; mover_type move; destroyer_type destroy; };Pointer to generic handler
You can store only one pointer to a generic handler. In this case, you need to make an enumeration that is responsible for the selection of the required operation, and also lead to a single type of signature of all possible actions on the object:
enum struct operation_t { copy, move, destroy }; using manager_t = void (*) (operation_t, const void *, void *);
The disadvantage of the first option is that each action requires the introduction of a new field. Accordingly, the memory occupied by handlers will swell if new handlers are added.
The disadvantage of the second option is that the signatures of different handlers are different, so you have to adjust all handlers to a single signature, while depending on the requested operation, some arguments may remain unnecessary, and sometimes - oh gods - even have to call const_cast .
In fact, there is a third option: polymorphic handlers-classes. But this option mercilessly dismisses as the most inhibited.
Accordingly, the disadvantages of one of the options are the advantages of the other.
According to the results of long reflections and weighing the advantages and disadvantages , the disadvantages of the first option outweigh, and the choice falls on the lesser evil - a generic handler.
template <typename T> void copy (const void *, void *); // . " ". template <typename T> void move (void * source, void * destination) { new (destination) T(std::move(*static_cast<T *>(source))); } template <typename T> void destroy (void * object) { static_cast<T *>(object)->~T(); } template <typename T> void manage (operation_t todo, const void * source, void * destination) { switch (todo) { case operation_t::copy: { copy<T>(source, destination); break; } case operation_t::move: { move<T>(const_cast<void *>(source), destination); break; } case operation_t::destroy: { assert(source == nullptr); destroy<T>(destination); break; } } } Data access
The easiest thing to say about DC.
The type of the requested data is known at the compilation stage, the index is known at the execution stage, therefore the object access interface suggests itself:
template <typename T> T & get (size_type index) { return *static_cast<T *>(static_cast<void *>(data() + offset_of(index))); } size_type offset_of (size_type index) const { return m_objects[index].offset; } Also, for greater efficiency (see access performance graphs at the end of the article), you can define access to an object by indent:
template <typename T> const T & get_by_offset (size_type offset) const { return *static_cast<const T *>(static_cast<const void *>(data() + offset)); } Well, indicators, by analogy with standard containers:
size_type size () const { return m_objects.size(); } std::size_t capacity () const { return m_capacity; } bool empty () const { return m_objects.empty(); } The only thing that needs to be said separately is a special indicator indicating the volume of the container.
Under the volume is understood the total amount of memory occupied by objects located in the DC.
std::size_t volume () const { return m_volume; } Exception Life and Safety
The most important tasks are tracking the life of objects and ensuring the safety of exceptions.
Since objects are constructed "manually" with the help of the host new , they, naturally, are destroyed "manually" - by explicitly calling the destructor.
This creates certain difficulties with copying and transferring objects during relocation. Therefore, it is necessary to implement relatively complex structures for copying and transferring:
template <typename ForwardIterator> void move (ForwardIterator first, ForwardIterator last, std::int8_t * source, std::int8_t * destination) { for (auto current = first; current != last; ++current) { try { // . current->manage(operation_t::move, source + current->offset, destination + current->offset); } catch (...) { // , , . destroy(first, current, destination); throw; } } destroy(first, last, source); } template <typename ForwardIterator> void copy (ForwardIterator first, ForwardIterator last, const std::int8_t * source, std::int8_t * destination) { for (auto current = first; current != last; ++current) { try { // . current->manage(operation_t::copy, source + current->offset, destination + current->offset); } catch (...) { // - , , . destroy(first, current, destination); throw; } } } Other problems
One of the biggest problems was copying. And, although I figured it out with her, doubts still arise from time to time.
I will explain.
Suppose we put an uncopyable object (say, std::unique_ptr ) in std::vector . We can do this with the help of the transfer. But if we try to copy a vector, the compiler will swear, because its internal elements are uncopyable.
In the case of DC, everything is somewhat different:
- At the time of laying the item in the DC you need to create a copy handler. If the object is not copied, then the handler cannot be created (compile error). At the same time, it is not yet known whether we are going to ever copy our DC.
- At the time of the actual copying of the DC, the information about the copyability of the type — due to the erasing of the type — is no longer available.
The following solution is currently selected:
- If the object is copied, then a regular copy handler is created for it.
- If the object is not copied, then a special handler is created for it, which throws an exception when trying to copy.
template <typename T> auto copy (const void * source, void * destination) -> std::enable_if_t < std::is_copy_constructible<T>::value > { new (destination) T(*static_cast<const T *>(source)); } template <typename T> auto copy (const void *, void *) -> std::enable_if_t < not std::is_copy_constructible<T>::value > { auto type_name = boost::typeindex::ctti_type_index::type_id<T>().pretty_name(); throw std::runtime_error(u8" " + type_name + u8" "); } An even more difficult problem arises when comparing two DCs for equality. One could do in the same way, but, in addition to the case of a compiler error when trying to compare the incomparable, there are still cases where the compiler generates a warning rather than an error — for example, when invoking the equality operator for floating-point numbers. Here, on the one hand, it is impossible to throw an exception, because the user could be aware of his actions and make a comparison intentionally. On the other hand, I would like to somehow inform the user about the unsafe operation.
This problem is still open.
Performance measurements
Since the main goal was to create a precisely packed container in order to have an optimal access time to its elements, in the performance measurements the access speed to the DC was compared with the access speed to the array of pointers to the “scattered” objects in memory.
Two scattered patterns were used:
Sparseness
Let
Nbe the size of the array to be measured,Sbe the spreading index.
Then an array of pointers of sizeN * Sgenerated, and then it is thinned out so that only elements with numbersN * i,i = 0, 1, 2, ...remain.Stirring
Let
Nbe the size of the array to be measured,Sbe the spreading index.
Then an array of the sizeN * Sgenerated, mixed randomly, and then the firstNelements are selected from it, and the rest are discarded.
And std::vector was taken as a reference point for access time.

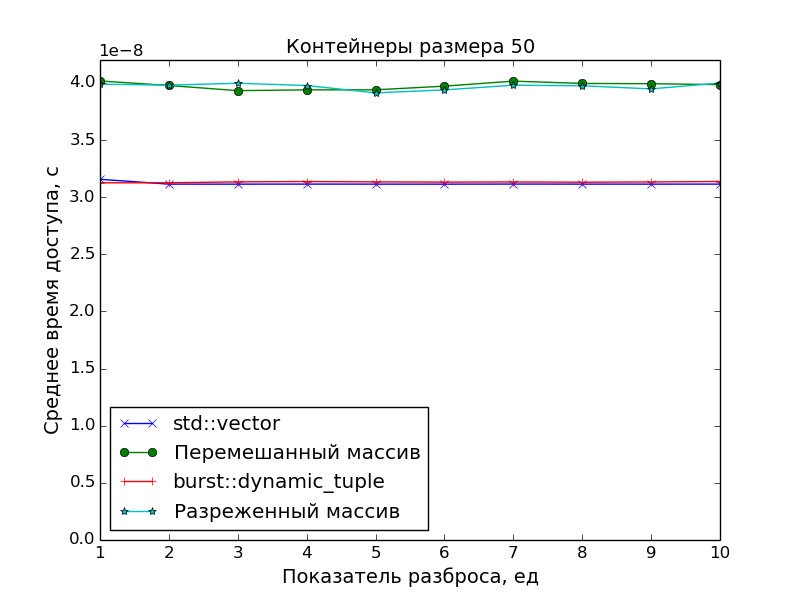
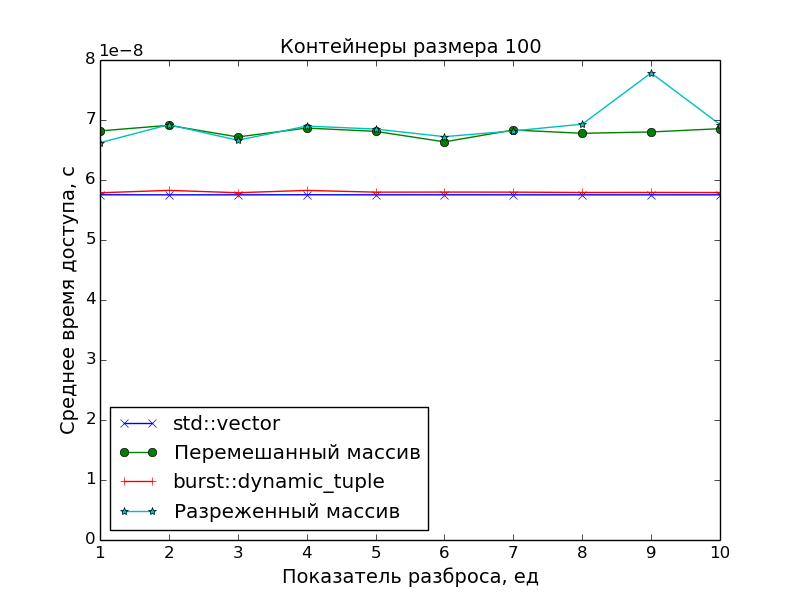
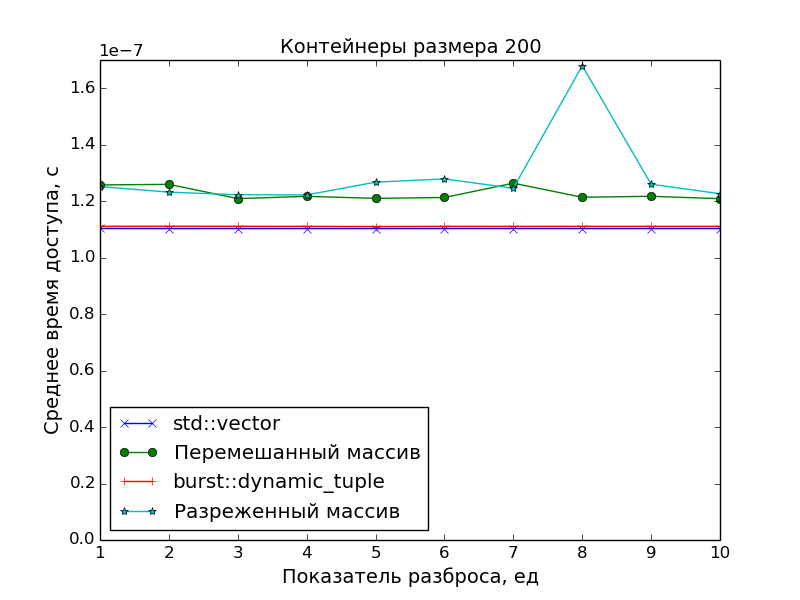
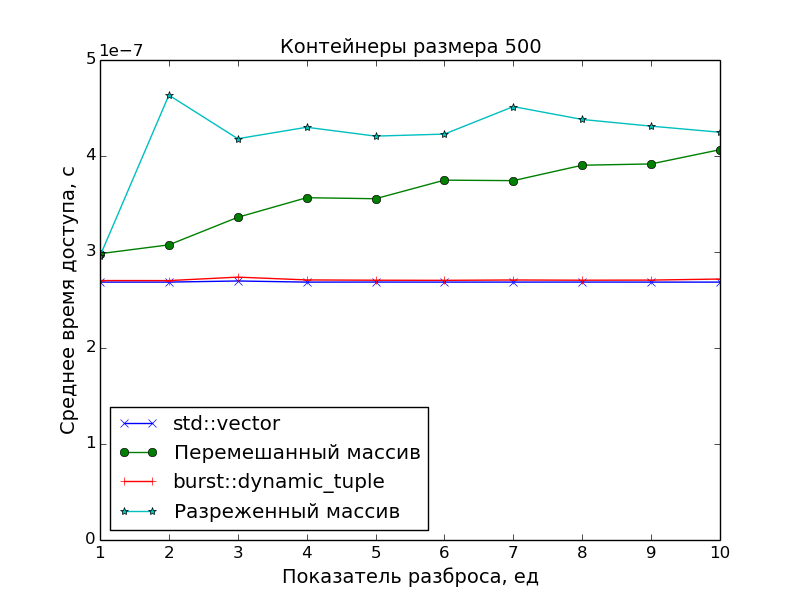
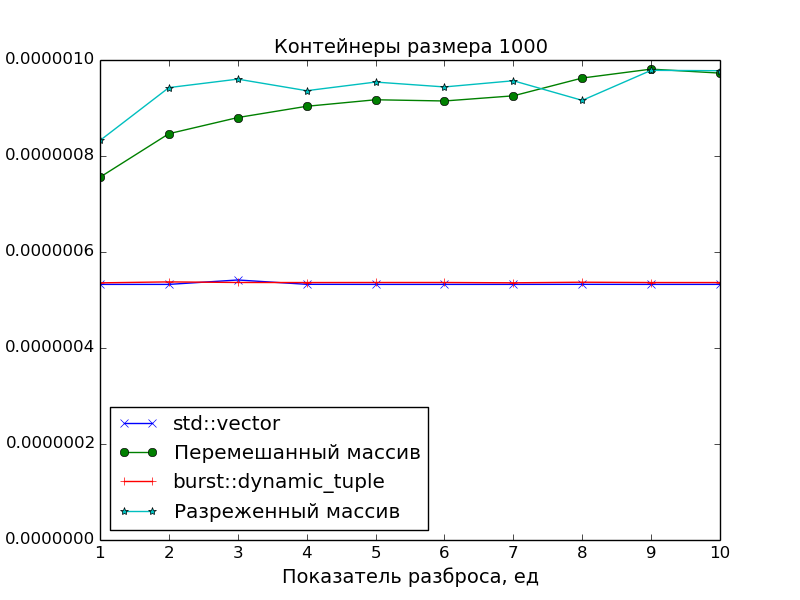
The graphs confirm the obvious:
- The speed of access to the elements of the DC is identical to the speed of access to the elements of the class
std::vector(one addition of pointers and one dereference). - Access to array elements is slower. This is especially evident on large arrays with a scatter of
S > 1, when the data no longer fit into the cache.
All source codes are available on my github .
')
Source: https://habr.com/ru/post/302372/
All Articles