How we made a system for separating information from the text in natural language for Bank Bank CenterCredit JSC (Kazakhstan)
Some time ago, we were approached by a representative of Bank CenterCredit JSC (Kazakhstan) with an interesting task. It was necessary to integrate into the data processing pipeline, which is a natural language text, an additional processing tool. We cannot disclose all the details of the project, as it is in the field of bank security and is being developed by its security service. In covering the technological aspects of the task and how to implement them, the customer was not opposed to what we actually want to do in this article.
In general, the task was to extract some entities from a large array of texts. Not very different problem from the classical task of extracting named entities, on the one hand. But the definitions of entities differed from the usual ones and the texts were quite specific, and the time for solving the problem was two weeks.
Input data
At that time, there were no marked and accessible packages of named entities in Russian at all. And if they were, they would have turned out to be not quite those entities. Or at all those entities. There were similar solutions, but they turned out to be either bad (they found, for example, organizations such as the “Back Cover” in the sentence “after a year of operation the Back Cover broke”) or very good, but they do not highlight what is needed (there were requirements concerning exactly which entities need to be allocated with respect to the boundaries of these entities).
Beginning of work
The data had to mark themselves. From the specific texts provided, a training set was created. During the week, with the efforts of one and a half diggers, we managed to mark out a sample of 112,000 words containing about 9,000 references to the necessary entities. After training several classifiers on a validation sample, we obtained the following:
For entities that are simple in content, this is not very good; on comparable tasks, specialized systems often give out F1 around 90-94 (according to published works). But then on samples of more than a million word forms and subject to a careful selection of characters.
')
In the preliminary results, the LSTM model showed itself best of all, with a large margin. But I didn’t really want to use it, because it is relatively slow, it is expensive to process large arrays of text in real time. By the time of receipt of the marked sample, and preliminary results, a week remained before the deadline.
Day 1. Regularization
The main problem of neural networks in small samples is retraining. Classically, this can be fought by selecting the correct size of the net, or using special regularization methods.
We tried sizing, max-norm regularization on different layers, with selection of values of constants and dropout. Got red eyes, a headache and a couple of percent winnings.
Dropout didn’t help us much, the network is learning slower, and the result is not particularly good. The best was Max-norm and network resizing. But the increase is small, to the desired values as to the moon, and all that can be kind of done.
Day # 2. Rectified LinearPain Unit
Articles recommend using the RelU activation function. Written to improve results. RelU is a simple function if x> 0 then x else 0.
Nothing has improved. Optimization with them does not converge at all or the result is terrible. I spent the day trying to understand why. Not understood.
Day # 3. LSTM-like monsters
Is it possible to make it so that it is like LSTM, but on ordinary layers? After some reflection, the imagination prompted the construction (Fig. 1). Before the recurrent layer, one feed-forward layer has been added (it should of course control what information goes to the network), and on top there is a design for controlling the output:
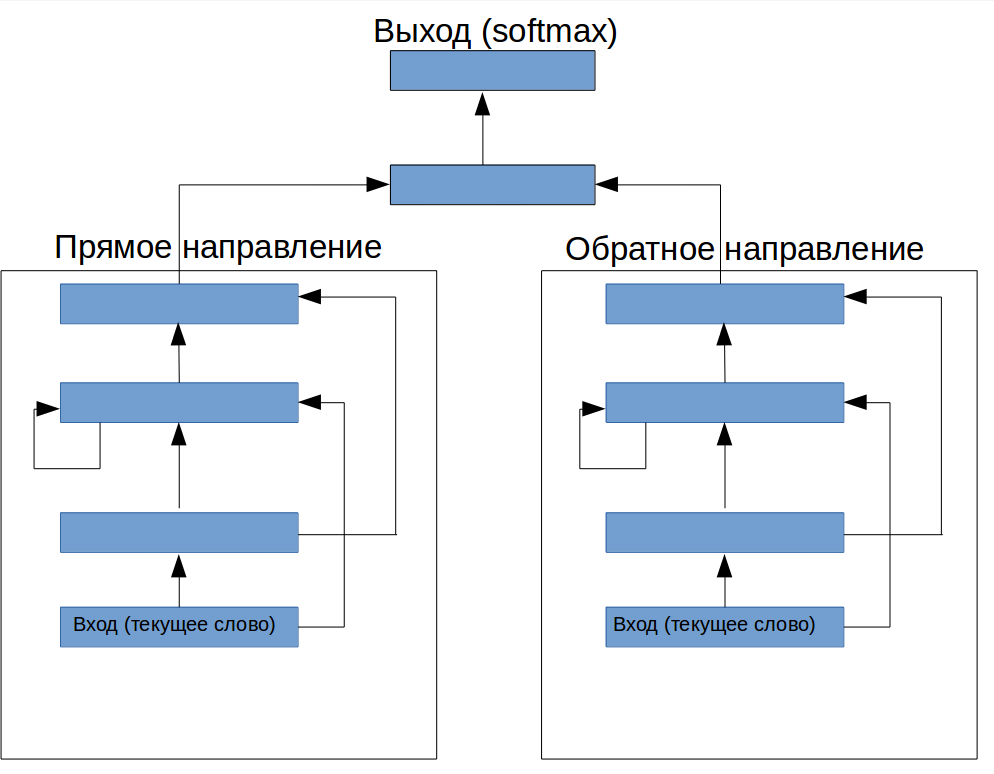
figure 1. The architecture of a special neural network to highlight terms from the text
Oddly enough, with the right choice of parameters, this design gave an increase of F1 to 72.2, which is not bad for a completely invented architecture.
Day # 4. RelU Returns
Out of stubbornness tried RelU on the “monster”. It turned out that if RelU was installed only on a recurrent layer, then the optimization not only converges, but it turns out F1 73.8! Where does this miracle come from?
Let's see. Why does LSTM work well? This is usually explained by the fact that he can memorize information for a longer time, and thus “see” more of the context. In principle, a regular RNN can also be trained to remember a long context if one uses the appropriate learning algorithm. But, as applied to our problem of marking up a sequence with input vector words, a regular RNN first looks for dependencies in the current time interval and in the near context, and manages to retrain them before the training reaches the possibility of a meaningful analysis of this context. In the usual RNN Ellman, we cannot increase the “memory size” without significantly increasing the network's ability to retrain.
If we look at the picture of the new architecture, we will see that here we have smashed the module that stores information and the “crucial” module. At the same time, the memory module itself is unable to build complex hypotheses, so it can be increased without the fear that it will make a significant contribution to retraining. By this we were able to control the degree of relative importance of memory and information in the current window for a specific task.
Day # 5. Diagonal elements
Following the idea described in [1], we excluded from the recurrent layer all recurrent connections except from other neurons, leaving only its own previous state to the input of each neuron. In addition, we added made the top layer also recurrent (Fig. 2). This gave us F1 74.8, which, on this task, was a better result than we were able to first get with the help of LSTM.
Day # 6. Sample size
Since we continued to mark the data throughout the week, on this day we proceeded to use a double sample of double size, which allowed (after a new round of selection of hyperparameters) to get F1 83.7. There is nothing better than a larger sample when it is easy to get it. True to double the amount of marked data is usually not easy at all. This is what we end up with:
Conclusions and comparison with analogues
It is impossible to adequately compare our system of recognition with similar implementations of the above-mentioned web-API, since the definitions of the entities and boundaries differ. We did some very rough analysis, on a small test sample, trying to put all systems in equal conditions. We had to manually analyze the result according to special rules, using the binary overlap metric (the definition of an entity counts if the system selects at least part of it, which removes the problem of boundary mismatch) and eliminates cases from the analysis when the entities did not need to be identified due to mismatched definitions. This is what happened:
Analog # 2 has only a slight advantage in this metric, and Analog # 1 has shown itself even worse. Both solutions will produce lower quality results if we test them on our task with the specifications specified by the customer.
From all of the above, we made two conclusions:
1. Even well-defined and solved problems of extracting named entities have sub-options that can make the use of ready-made systems impossible.
2. The use of neural networks allows you to quickly create specialized solutions that are approximately in the same range of quality as the more complex developments.
Literature
1. T. Mikolov, A. Joulin, S. Chopra, M. Mathieu, and M. Ranzato. Learning longer memory in
recurrent neural networks
In general, the task was to extract some entities from a large array of texts. Not very different problem from the classical task of extracting named entities, on the one hand. But the definitions of entities differed from the usual ones and the texts were quite specific, and the time for solving the problem was two weeks.
Input data
At that time, there were no marked and accessible packages of named entities in Russian at all. And if they were, they would have turned out to be not quite those entities. Or at all those entities. There were similar solutions, but they turned out to be either bad (they found, for example, organizations such as the “Back Cover” in the sentence “after a year of operation the Back Cover broke”) or very good, but they do not highlight what is needed (there were requirements concerning exactly which entities need to be allocated with respect to the boundaries of these entities).
Beginning of work
The data had to mark themselves. From the specific texts provided, a training set was created. During the week, with the efforts of one and a half diggers, we managed to mark out a sample of 112,000 words containing about 9,000 references to the necessary entities. After training several classifiers on a validation sample, we obtained the following:
| Method | F1 |
| CRF (basic feature set) | 67.5 |
| Elman's Bidirectional Multilayer Network | 68.5 |
| Bidirectional LSTM | 74.5 |
For entities that are simple in content, this is not very good; on comparable tasks, specialized systems often give out F1 around 90-94 (according to published works). But then on samples of more than a million word forms and subject to a careful selection of characters.
')
In the preliminary results, the LSTM model showed itself best of all, with a large margin. But I didn’t really want to use it, because it is relatively slow, it is expensive to process large arrays of text in real time. By the time of receipt of the marked sample, and preliminary results, a week remained before the deadline.
Day 1. Regularization
The main problem of neural networks in small samples is retraining. Classically, this can be fought by selecting the correct size of the net, or using special regularization methods.
We tried sizing, max-norm regularization on different layers, with selection of values of constants and dropout. Got red eyes, a headache and a couple of percent winnings.
| Method | F1 |
| Reduce network size to optimal | 69.3 |
| Max-norm | 71.1 |
| Dropout | 69.0 |
Dropout didn’t help us much, the network is learning slower, and the result is not particularly good. The best was Max-norm and network resizing. But the increase is small, to the desired values as to the moon, and all that can be kind of done.
Day # 2. Rectified Linear
Articles recommend using the RelU activation function. Written to improve results. RelU is a simple function if x> 0 then x else 0.
Nothing has improved. Optimization with them does not converge at all or the result is terrible. I spent the day trying to understand why. Not understood.
Day # 3. LSTM-like monsters
Is it possible to make it so that it is like LSTM, but on ordinary layers? After some reflection, the imagination prompted the construction (Fig. 1). Before the recurrent layer, one feed-forward layer has been added (it should of course control what information goes to the network), and on top there is a design for controlling the output:
figure 1. The architecture of a special neural network to highlight terms from the text
Oddly enough, with the right choice of parameters, this design gave an increase of F1 to 72.2, which is not bad for a completely invented architecture.
Day # 4. RelU Returns
Out of stubbornness tried RelU on the “monster”. It turned out that if RelU was installed only on a recurrent layer, then the optimization not only converges, but it turns out F1 73.8! Where does this miracle come from?
Let's see. Why does LSTM work well? This is usually explained by the fact that he can memorize information for a longer time, and thus “see” more of the context. In principle, a regular RNN can also be trained to remember a long context if one uses the appropriate learning algorithm. But, as applied to our problem of marking up a sequence with input vector words, a regular RNN first looks for dependencies in the current time interval and in the near context, and manages to retrain them before the training reaches the possibility of a meaningful analysis of this context. In the usual RNN Ellman, we cannot increase the “memory size” without significantly increasing the network's ability to retrain.
If we look at the picture of the new architecture, we will see that here we have smashed the module that stores information and the “crucial” module. At the same time, the memory module itself is unable to build complex hypotheses, so it can be increased without the fear that it will make a significant contribution to retraining. By this we were able to control the degree of relative importance of memory and information in the current window for a specific task.
Day # 5. Diagonal elements
Following the idea described in [1], we excluded from the recurrent layer all recurrent connections except from other neurons, leaving only its own previous state to the input of each neuron. In addition, we added made the top layer also recurrent (Fig. 2). This gave us F1 74.8, which, on this task, was a better result than we were able to first get with the help of LSTM.
Day # 6. Sample size
Since we continued to mark the data throughout the week, on this day we proceeded to use a double sample of double size, which allowed (after a new round of selection of hyperparameters) to get F1 83.7. There is nothing better than a larger sample when it is easy to get it. True to double the amount of marked data is usually not easy at all. This is what we end up with:
| Method | F1 |
| CRF (basic feature set) | 76.1 |
| Elman's Bidirectional Multilayer Network | 77.8 |
| Bidirectional LSTM | 83.2 |
| Our architecture | 83.7 |
Conclusions and comparison with analogues
It is impossible to adequately compare our system of recognition with similar implementations of the above-mentioned web-API, since the definitions of the entities and boundaries differ. We did some very rough analysis, on a small test sample, trying to put all systems in equal conditions. We had to manually analyze the result according to special rules, using the binary overlap metric (the definition of an entity counts if the system selects at least part of it, which removes the problem of boundary mismatch) and eliminates cases from the analysis when the entities did not need to be identified due to mismatched definitions. This is what happened:
| Method | F1 |
| Our system | 76.1 |
| Analog # 1 | 77.8 |
| Analog # 2 | 83.2 |
Analog # 2 has only a slight advantage in this metric, and Analog # 1 has shown itself even worse. Both solutions will produce lower quality results if we test them on our task with the specifications specified by the customer.
From all of the above, we made two conclusions:
1. Even well-defined and solved problems of extracting named entities have sub-options that can make the use of ready-made systems impossible.
2. The use of neural networks allows you to quickly create specialized solutions that are approximately in the same range of quality as the more complex developments.
Literature
1. T. Mikolov, A. Joulin, S. Chopra, M. Mathieu, and M. Ranzato. Learning longer memory in
recurrent neural networks
Source: https://habr.com/ru/post/302308/
All Articles