The evolution of neural networks for image recognition in Google: Inception-v3
I continue to talk about the life of Inception architecture - Google's archneetkury for convnets.
(the first part is right here )
So, a year passes, men publish development successes since GoogLeNet.
Here is a scary picture of what the final network looks like: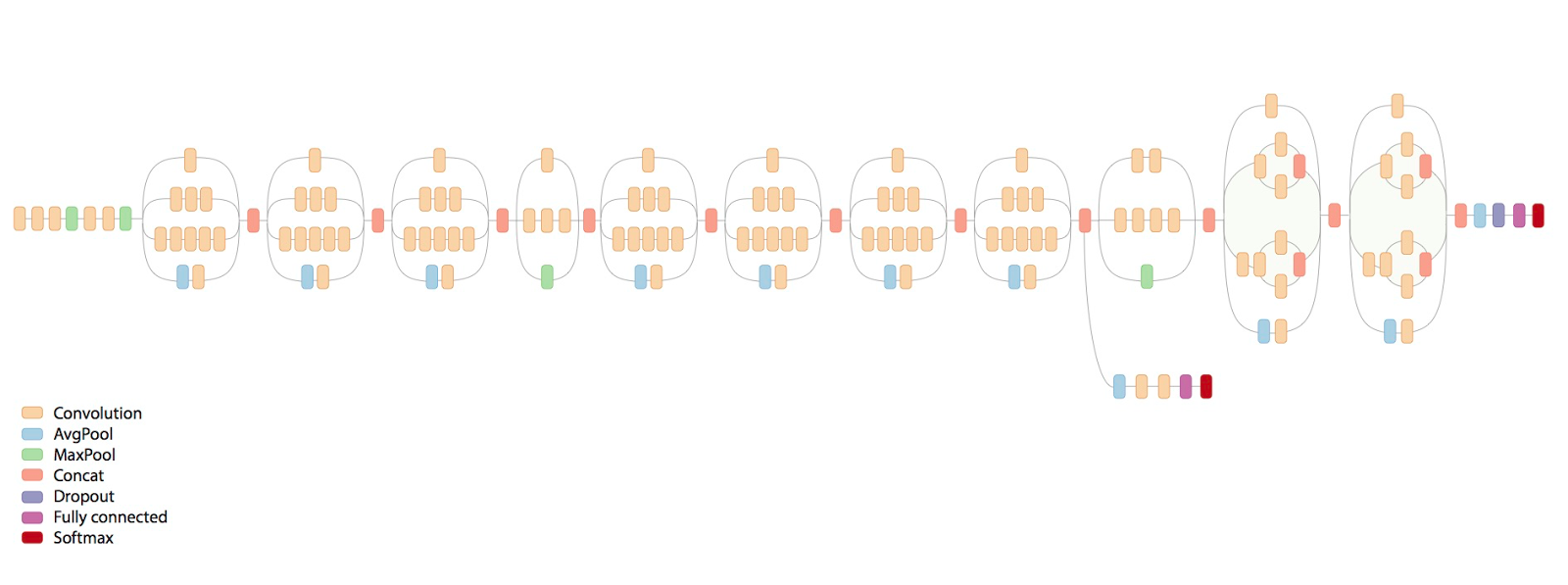
What kind of horror is happening there?
Disclaimer: The post is written on the basis of the edited chat logs closedcircles.com , hence the style of presentation, and clarifying questions.
This time, the authors are trying to formulate some basic principles for building an effective network architecture (the article itself is http://arxiv.org/abs/1512.00567 ).
(remember, the purpose of the Inception architecture is to be primarily efficient in computing and the number of parameters for real applications, for which we love)
The principles they formulate are as follows:
- A lot of signals are close to each other in space (i.e., in the neighboring "pixels"), and this can be used to make a smaller convolution.
They say that since the neighboring signals are often correlated, it is possible to reduce the dimension before convolution without losing information. - For efficient use of resources, you need to increase the width and depth of the network. Those. if for example resources become twice as large, the most effective is to make the layers wider and the network deeper. If you do only deeper, it will be ineffective.
- It is bad to have sharp bottlenecks, that is, a rail with a sharp decrease in parameters, especially at the beginning.
- "Wide" layers learn faster, which is especially important at high levels (but locally, that is, it is quite possible to reduce the dimension after them)
Let me remind you, the previous version of the network building block looked like this:
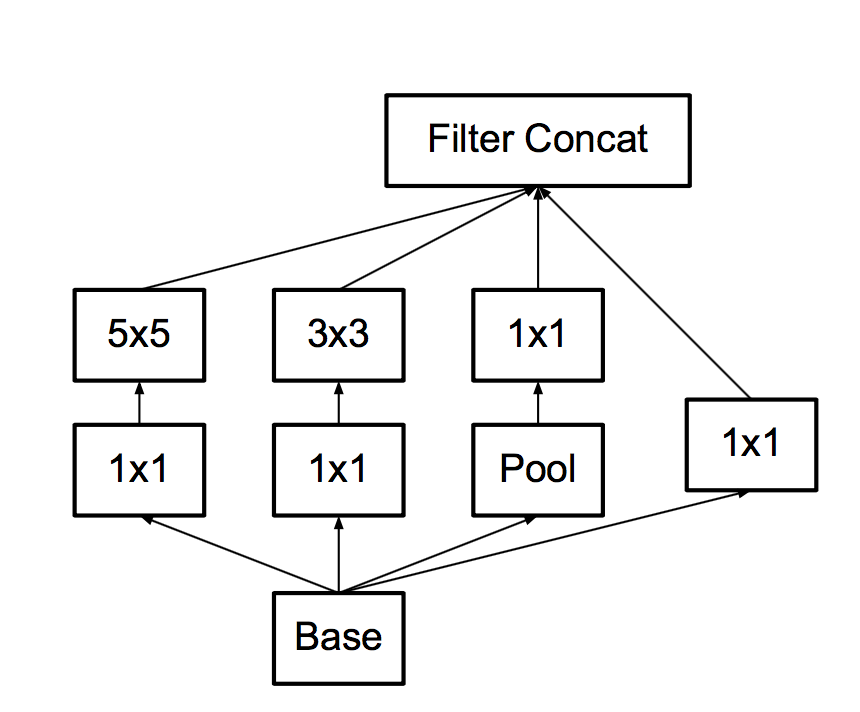
What modifications do they make in it
First , we note that it is possible to replace the big and bold 5x5 convolution by two consecutive 3x3 each, and they say, since the signals are correlated, we lose a little. It turns out experimentally what to do between these 3x3 nonlinearity is better than not to do.
- Secondly , since it's such a booze, let's replace 3x3 with 3x1 + 1x3.
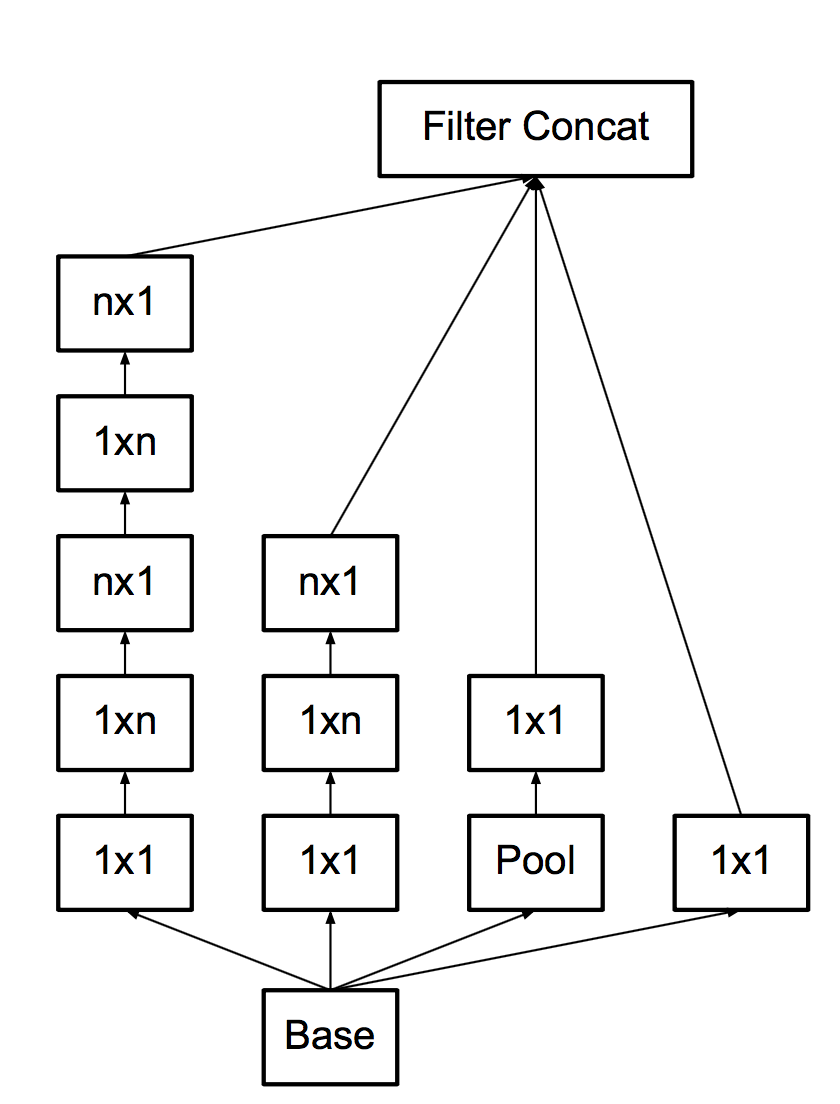
Here we find that doing something convolving becomes cheap, and then why not do 3x1 + 1x3 at all, but nx1 + 1xn right away!
And they do, as much as 7, though not at the beginning of the grid. With all these upgrades, the main brick becomes:
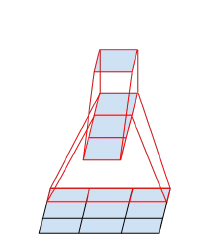
- Thirdly , following the covenant "do not create bottlenecks", they think about pooling.
What is the problem with pooling? Here let the pool reduce the picture twice, and the number of features after the pool is twice as large.
You can make a pool, and then convolution in a lower resolution, but you can first convolution, and then pool.
Here are the options in the picture:

The problem is that the first option - just dramatically reduce the number of activations, and the second - is ineffective in terms of calculations, because you need to carry out convolution at full resolution.
Therefore, they offer a hybrid scheme - let's make half a pool of features, and half a convolution.
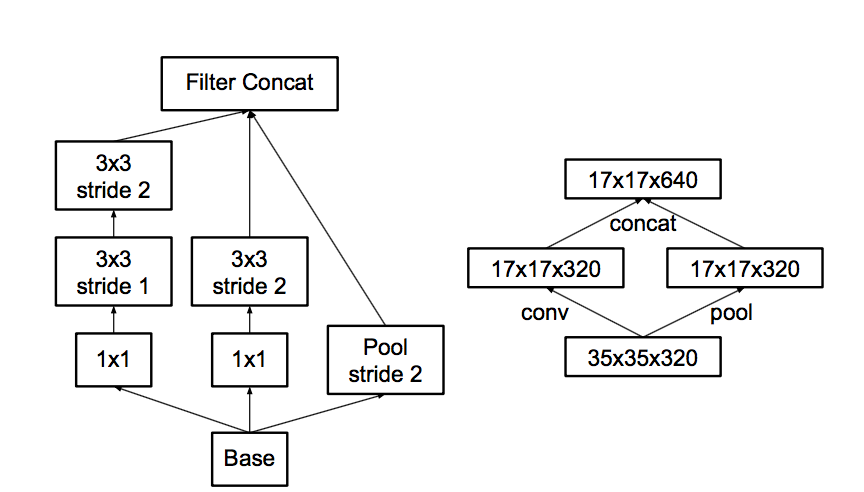
And since after the pool the number of features typically doubles, there will not be a bottleneck. The pool will compress the previous one without reducing the number of features, some convolutions will be driven out in full resolution, but with fewer features. The network learns how to divide, which requires full resolution, and why a pool is enough.
- Finally , they slightly modify the brick for the last leierra to be wider, albeit less deep. To make the mole learn better, at the end of the network this is most important.
And here is the network - these are a few early convolutions, and then these are the bricks interspersed with a pool. There are 11 inception layers in total.
Hence the horror in the first figure.
They also found that the additional classifiers on the sides do not speed up the training much, but rather they help because they work as regularizers - when they connected Batch Normalization to them, the network began to predict better.
What else...
They offer another trick for additional regularization - the so-called label smoothing .
The idea in brief is this: usually the target label for a particular sample is 1 where the class is correct, and 0 where the class is wrong.
This means that if the network is already very confident in the correctness of the class, the gradient will still push to increase and increase this confidence, because 1 occurs only at infinity due to softmax, which leads to overfitting.
They propose to mix one-off target with a distribution proportional to the stupid distribution of classes on a dataset, so that in other classes there are not zeros, but some small values. This gives even more percentages to win, that is a lot.
Total
And all this machinery eats 2.5 times more computing resources than Inception-v1 and achieves significantly better results.
They call the main architecture Inception-v2, and the version where the additional classifiers work with BN is Inception-v3.
This Inception-v3 achieves 4.2% top5 classification error for Imagenet, and an ensemble of four models - 3.58%.
And with this good guys from Google gathered to win Imagenet in 2015.
However, ResNets happened and won Kaiming He associates from Microsoft Research Asia with the result ... 3.57% !!!
(it should be noted that in object localization the result is fundamentally better for them)
But about ResNets, I probably tell you another time.
Interestingly, the average homo sapiens will show what error in these pictures.
The only widely discussed experiment was conducted by Andrey "our all" Karpathy.
http://karpathy.imtqy.com/2014/09/02/what-i-learned-from-competing-against-a-convnet-on-imagenet/
He tested himself on some part of dataset and he got 5.1%.
This is also top5, but it may be more difficult for a person to choose top5.
By the way, you can check yourself - http://cs.stanford.edu/people/karpathy/ilsvrc/
And it is really difficult. They will show you some subspecies of the Mediterranean finch and guessing.
')
Source: https://habr.com/ru/post/302242/
All Articles