Working with data: How do large companies

/ photo by Jason Tester Guerrilla Futures CC
IDC reports that in 2011, humankind generated 1.8 zettabyte information. In 2012, this figure was already 2.8 zettabytes, and by 2020 it will increase to 40 zettabytes.
')
A significant part of this data is generated by large global companies, such as Google, Facebook, Apple. They need not only to store data, but also to perform backups, monitor their relevance, process, and do it with minimal cost. Therefore, IT departments of large organizations are developing their own systems to solve these problems.
According to Sean Gallagher, editor of Ars Technica, Google has become one of the first web players to encounter the problem of scaling stores. The company found the answer to the question back in 2003 by developing a Google File System (GFS) distributed file system.
According to researcher Sanjay Ghemawat and senior engineers Howard Gobioff and Shun-Tak Leung from Google, GFS is designed with a certain specificity. Its goal is to turn a huge number of cheap servers and hard drives into a reliable storage for hundreds of terabytes of data, which can be accessed by many applications simultaneously.
GSF is the foundation of virtually all Google cloud services. Google stores application data in huge files, in which hundreds of machines append information simultaneously. Moreover, writing to the file can be done right while working with it.
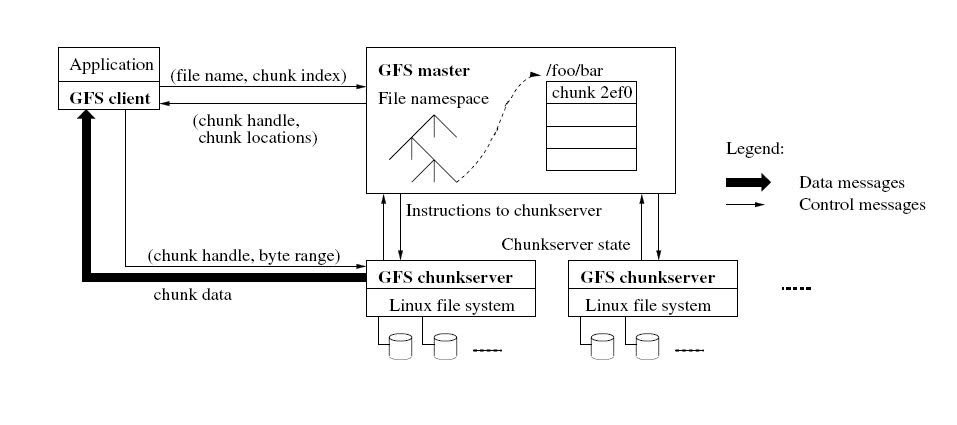
/ The Google File System
The system contains master and fragment servers (chunkservers) that store data. Typically, a GFS cluster consists of one master master machine and multiple fragment servers. Files in GFS are broken into pieces with a fixed but adjustable size, which the fragment servers store as Linux files on the local hard disk (however, to increase reliability, each fragment is replicated to other servers).
As for the master, he is responsible for working with metadata and controls all the global system activities: managing fragments, garbage collection, moving fragments between servers, etc.
One of the main problems of such a system are frequent failures in the operation of its components, since it is built on the basis of a large number of cheap equipment. Failure can be caused both by the inaccessibility of the system element, and the presence of corrupted data. But Google was ready for this, so GFS constantly monitors the components and in case of failure of any of them takes the necessary measures to maintain the system’s performance.
Damaged fragments are determined by calculating checksums. Each piece is divided into blocks of 64 KB with a 32-bit checksum. Like other metadata, these amounts are stored in memory and are regularly written to logs separately from user data.
Over the entire existence of GFS, the Google platform has evolved and adapted to new requirements, the search engine has new services. It turned out that cluster sizes in GFS are no longer suitable for efficient storage of all types of data. By 2010, the company's researchers studied the advantages and disadvantages of GFS and applied the acquired knowledge to create new software systems.
Thus , the distributed file system Colossus (GFS2), Spanner (BigTable development) - scalable geo-distributed storage with data versioning support, scalable Dremel query processing system, Caffeine - Google search service infrastructure using GFS2, iterative MapReduce and next-generation BigTable, et al. Today they solve more complex problems and process more information, opening up new opportunities.

/ photo Atomic Taco CC
However, not only Google is “fighting” with large amounts of data. Uber found an unusual approach to data storage and replication. Instead of constantly synchronizing the database between the data centers, the car service specialists decided to organize an external distributed system from the drivers' phones.
The company notes that the main goal of this solution is to increase resiliency. This approach reliably protects data from failures in data centers. When using the classic replication strategy, it was difficult to guarantee the preservation of trip information due to the nature of network management systems.
The usual solution for failures in the data center is to transfer data from the active data center to the backup, but if there are more than two data centers, the complexity of the infrastructure increases dramatically, a replication delay occurs between the data centers and a high connection speed is required.
In the case of Uber, if any error occurs in the data center, information about the trip will always remain on the driver’s mobile device. Since the smartphone has the most relevant data, it is from it that the actual information goes to the data center, and not vice versa.
Drivers mobile phones send data every 4 seconds. “For this reason, Uber was faced with the task of processing millions of write operations per second,” said Matt Ranney, chief developer of the Uber system architecture, during a presentation on scaling the platform.
The whole process is as follows. The driver updates his status, for example, at the moment when he takes the passenger, and sends a request to the dispatch service. The latter updates the trip model and notifies the replication service. When replication is complete, the dispatcher updates the data store and informs the mobile client that the operation has completed successfully.
At the same time, the replication service encodes the information and sends it to the messaging service that supports bidirectional communication with drivers. This channel has nothing to do with the original request channel; therefore, data recovery processes do not affect business processes. Next, the messaging service sends a backup to the phone.
“The Uber digital platform aggregates an amazing amount of data,” said Tyler James Johnson at Convergent Technology Advisors. - Maps, routes, information about customer preferences, communications - this is only a small part of the contents of the Uber repositories. The company invests heavily in the development of digital technology. Data is the basis of everything. ”
This data is important to keep, as they will be useful to companies in the future. The appearance of autopilot cars is not far off. Gartner predicts that one out of five cars in the world will have wireless connectivity by 2020, which is, for a moment, 250 million connected vehicles.
So far, Google remains the leader in this market, but in parallel with the technology giant, Tesla, Ford, Apple are working on such systems. Uber is not far behind. The company has an Advanced Technology Development Center that works in partnership with Carnegie Mellon University in Pittsburgh. It develops smart cars and other technologies that can help the company improve the quality of the services provided and reduce their cost.
"Increasing the amount of digital content being created and consumed will lead to the need to create new, more complex information systems," said James Hines, head of research at Gartner. “At the same time, the application of these technologies in the autosphere will lead to the emergence of new business models and approaches to car ownership in the urban environment.”
PS We try to share not only our own experience on the service of providing virtual infrastructure 1cloud , but also to talk about related areas of knowledge in our blog on Habré. Do not forget to subscribe to updates, friends!
Source: https://habr.com/ru/post/302124/
All Articles