Stock Market Technologies: 10 Misconceptions About Neural Networks

Neural networks are one of the most popular classes of machine learning algorithms. In financial analysis, they are most often used for forecasting, creating your own indicators, algorithmic trading and risk modeling. Despite all this, the reputation of the neural networks is spoiled, since the results of their use can be called unstable.
NMRQL quantitative hedge fund analyst Stuart Reed in an article on the TuringFinance website tried to explain what this means and prove that all problems lie in an inadequate understanding of how such systems work. We present to your attention an adapted translation of his article .
')
1. The neural network is not a model of the human brain.
The human brain is one of the biggest mysteries, over which scientists have been fighting for more than one century. There is still no common understanding of how all this functions. There are two main theories: the theory of the "grandmother's cell" and the theory of distributional representation. The first states that individual neurons have high information capacity and are capable of forming complex concepts. For example, the image of your grandmother or Jennifer Aniston. The second says that neurons are much simpler in their structure and represent complex objects only in a group. An artificial neural network can be generally presented as the development of ideas of the second model.
The huge difference between the ANNs and the human brain, in addition to the obvious complexity of the neurons themselves, is in size and organization. There are disproportionately more neurons and synapses in the brain; they are self-organized and able to adapt. Ann constructing as architecture. There can be no talk of any self-organization in the usual sense.
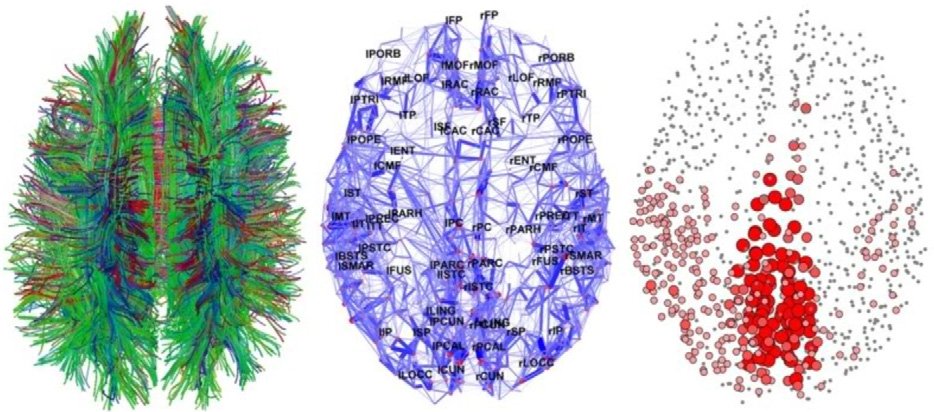
What follows from this? ANNs are created according to the archetype of the human brain in the same sense as the Olympic Stadium in Beijing was assembled according to the bird's nest model. This does not mean that the stadium is a nest. This means that it has some elements of its design. It is better to talk about the similarity, rather than the coincidence of structure and design.
Neural networks, rather, are related to statistical methods - curve matching and regression. In the context of quantitative methods in the financial field, the claim that something works according to the principles of the human brain can be misleading. And in unprepared minds cause fear of the threat of invasion of robots and other fiction.
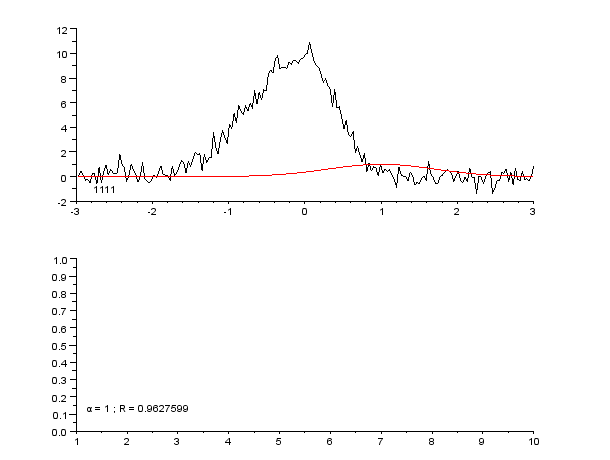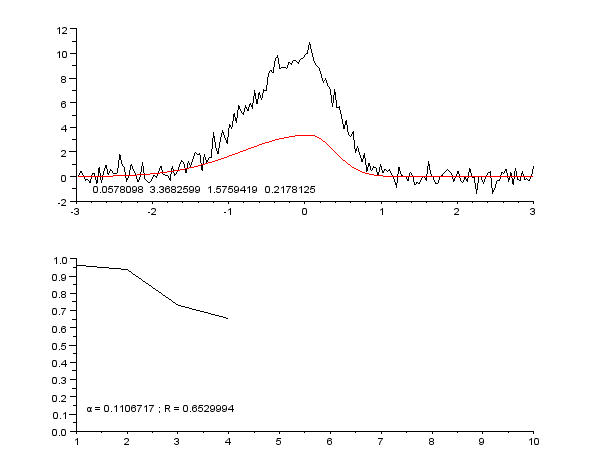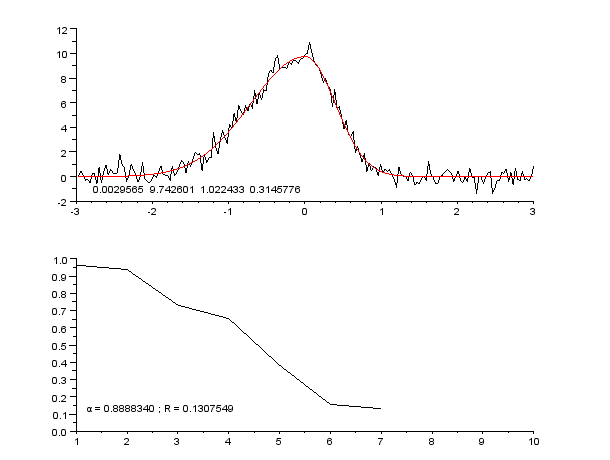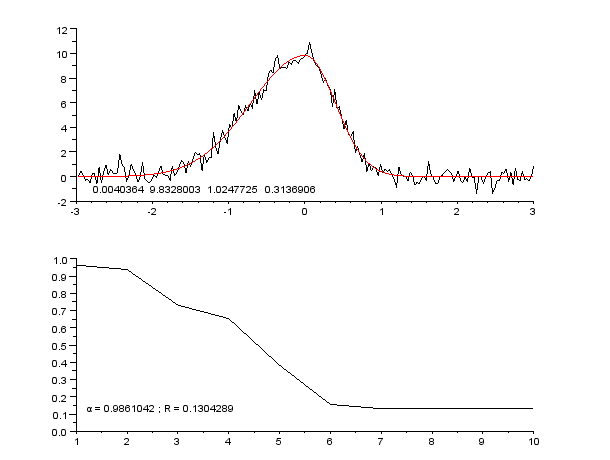
An example of a curve, also known as an approximation function. Neural networks are very often used to approximate complex mathematical functions.
2. Neural network is not a simplified form of statistics
Neural networks consist of layers of interconnected nodes. Individual nodes are called perceptrons and resemble multiple linear regression . The difference is that perceptrons pack a signal produced by multiple linear regression into an activation function, which can be both linear and nonlinear. In a system with multiple perceptron layers (MLP), the perceptrons are organized into layers, which in turn are connected to each other. There are three types of layers: input and output layers, hidden layers. The first layer receives input data patterns, the second can maintain a classification list or output signals in accordance with the scheme. Hidden layers control the weights of the input data until the risks of error are minimized.
Input / Output Mapping
Perceptors receive input data vectors - z = (z 1 , z 2 , ..., z n ) from n attributes. A vector is called an input pattern. The weight of such an “input” is determined by the weight of the vector belonging to this perceptron — v = (v 1 , v 2 , ..., v n ). In the context of multiple linear regression, this can be represented as a regression coefficient. The perceptron signal in the net, net, usually consists of an input pattern and its weight.
net = ∑ n i z i v i
The signal minus offset θ is then converted into some kind of activation function. This is usually a monotonically increasing function with (0,1) or (-1,1) bounds. Some of the most popular features are shown in the picture:
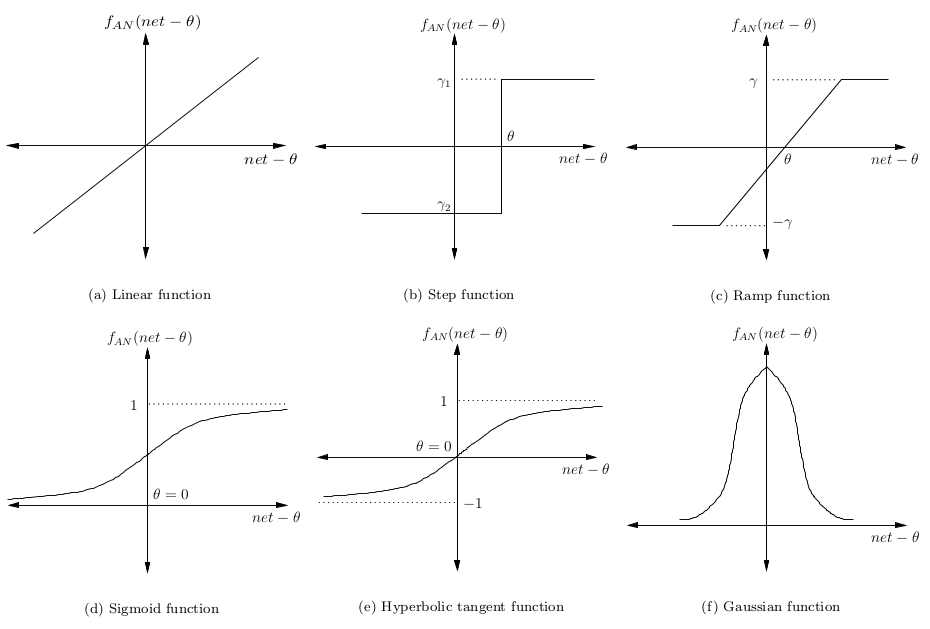
The simplest neural network is one that has only one neuron mapping the input signals to the output.
Creating layers

As can be seen from the figure, perceptrons are organized in layers. The first layer, which will later receive the name of the input layer, receives a pattern p in the learning process - P t . The last layer is tied to the expected output for these patterns. Patterns can be values of various technical indicators, and potential output signals can be categories {BUY, HOLD, SELL} .
The hidden layer is the one that gets the input and output from another layer and forms the output for the next one. According to one of the versions, the hidden layers extract the protruding elements from the incoming data, which are important for predicting the result. In statistics, this technique is called the primary component analysis.
The deep neural network has a large number of hidden layers and is capable of extracting more suitable data elements. Recently, they have been successfully used to solve image recognition problems.
There is one problem in trading problems when using deep networks: the input data are already prepared and there can be several elements that need to be extracted at once.
Learning rules
The task of the neural network to minimize the degree of error ϵ. Usually this indicator is calculated as the sum of squared errors. Although this option may be sensitive to extraneous noise.

For our purposes, we can use an optimization algorithm to adjust the weight indicators to the network. Most often, a gradient descent algorithm is used to train the network. It works through the calculation of partial derivatives of errors, taking into account their weight for each layer, and then moves in the opposite direction on a slope. By minimizing the error, we increase the network performance in the sample.
Mathematically, this update rule can be expressed in the following formula:
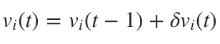 where
where where
where
η is the learning frequency, which is responsible for how quickly or slowly the network converges. The choice of training frequency has serious implications in terms of neural network performance. A small value will lead to a slow convergence, a large one may lead to deviations in learning.
So, the neural network is not a simplified form of statistics for lazy analysts. This is a kind of excerpt serious statistical methods used for hundreds of years.
3. The neural network can be executed in a different architecture.
Up to this point we have been discussing the most primitive neural network architecture - the system of multi-level perceptrons. There are many more options on which performance depends. Modern advances in learning machine learning are not only related to how optimization algorithms work, but how they interact with perceptrons. The author proposes to consider the most interesting, from his point of view, models.
A recurrent neural network: some or all of its connections play it back. In essence, this is the principle of the Feed Back Loop technology (notification of the provider to the mailing service when recruiting a critical number of spam complaints). It is believed that such a network works better on serial data. If so, then this option is appropriate for financial markets. For more information, we are offered to read this article.
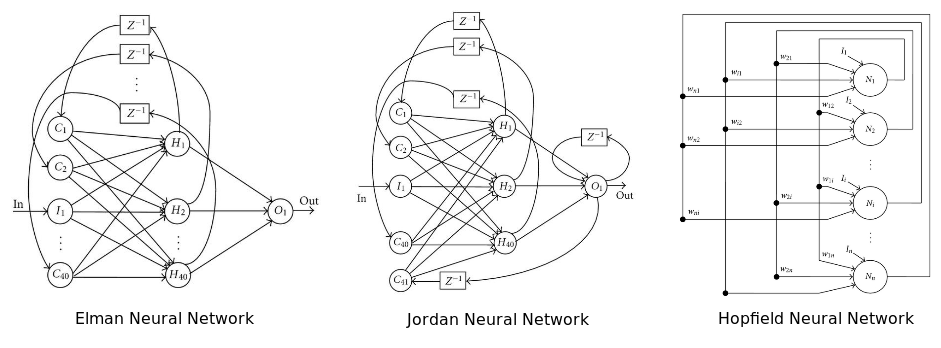
The diagram shows three popular neural network architectures.
The last of the invented variants of the recurrent neural network architecture is the Turing neural machine . It combines a standard network architecture with memory.
The Boltzmann neural network is one of the first fully connected neural networks. She was one of the first to be able to learn internal concepts and solve complex problems in combinatorics. They say it is a Monte Carlo version of the Hopfield recurrent neural network. It is more difficult to train, but if restrictions are set, then it is more effective than a traditional network. The most common restriction on the Boltzmann network is the prohibition of connections between hidden neurons. Actually, another version of the architecture.
The deep neural network is a network with many hidden layers. Such networks have become extremely popular in recent years, due to their ability to brilliantly solve problems in voice and image recognition. The number of architectures in this version is growing at an unprecedented pace. The most popular ones are deep trust networks, convolutional neural networks, stack auto-encoders, and so on. The main problem with deep networks, especially in the case of financial analysis, is retraining.
The adaptive neural network simultaneously adapts and optimizes the architecture in the learning process. It can build up the architecture (add neurons) or compress it, removing unnecessary hidden neurons. According to the author, this network is best suited for working in financial markets, because these markets themselves are not stationary. That is, the network is able to adapt to the dynamics of the market. Everything that was great yesterday is not a fact that it will work optimally tomorrow.
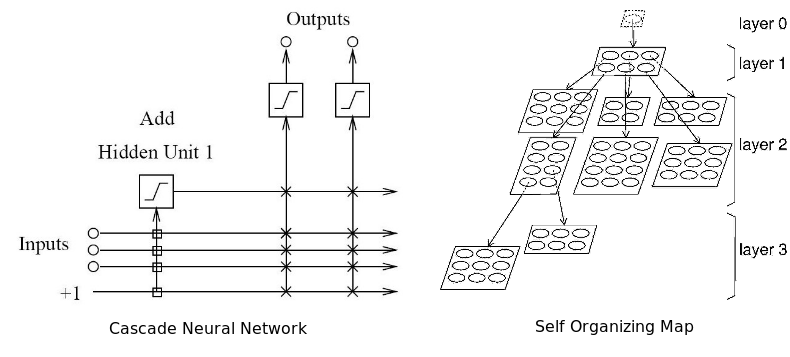
Two types of adaptive neural networks: cascade and self-organizing map
A radial-basic network is not just a separate type of architecture in terms of placing connections and perceptrons. Here, the radial-base function is used as an activating function, whose output points depend on the distance from a specific point. The most common use of this feature is the Gaussian distribution. It is also used as a core in a vector support machine.
The easiest way is to try several options in practice and choose the most suitable one for specific tasks.
4. Size matters, but bigger is not always better
After choosing the architecture, the question arises: how big or how small should a neural network be? How many should be "input"? How many need to use hidden neurons? Hidden layers (in the case of a deep network)? How many "output" do neurons need? If we miss size, the network may suffer from retraining or under-training. That is, it will not be able to competently generalize.
How many and which inputs should I use?
The number of input signals depends on the problem being solved, the quantity and quality of the information available and, possibly, a certain amount of creativity. Output signals are simple variables to which we assign certain predictive abilities. If the input to the problem is not clear, you can define variables for inclusion through a systematic search for correlations and cross-correlations between potential independent variables and dependent variables. This approach is discussed in detail in this article.
There are two main problems with using correlations. First, if you use the linear correlation metric, you can inadvertently exclude the variables you need. Second, two relatively uncorrelated variables can potentially be combined to produce one well-correlated variable. When you look at variables in isolation, you may miss this opportunity. Here you can use basic component analysis to extract useful vectors as input signals.
Another problem with variable selection is multicollinearity. This is when two or more variables loaded in the model have a high correlation. In the context of regression models, this can cause chaotic changes in the regressive coefficient in response to minor changes in the model or in the data. Given that the neural networks and regression models are similar, it can be assumed that the same problem applies to neural networks.
Another point is related to the fact that the selected variables accept the missing deviations in the variables. They appear when the model is already formed, and a couple of important causal variables are left behind. Deviations manifest themselves when the model receives an incorrect compensation for missing variables through overestimating or underestimating other variables.
How many hidden neurons are needed?
The optimal number of hidden items is a specific problem that is solved empirically. But the general rule: the more hidden neurons - the higher the risk of retraining. In this case, the system does not study the possibilities of the data, but, as it were, remembers the patterns themselves and any noise they contain. Such a network works fine on the sample and is poorly outside the sample. How can you avoid retraining? There are two popular methods: early stop and regularization. The author prefers his own, associated with the global search.
An early stop involves the division of the learning process into the stages of learning and validation of results. Instead of training the network on a limited number of iterations, you train it until the network performance at the confirmation stage begins to fall. Essentially, it does not allow the network to use all available parameters and limits the ability to simply memorize patterns. Below are two possible stopping points:
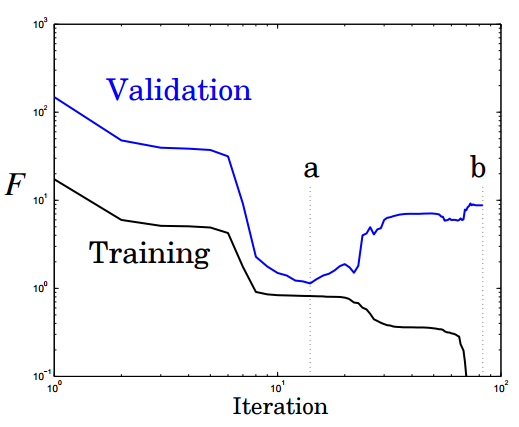
Another picture shows the performance and degree of network re-training when a and b are stopped at these points:
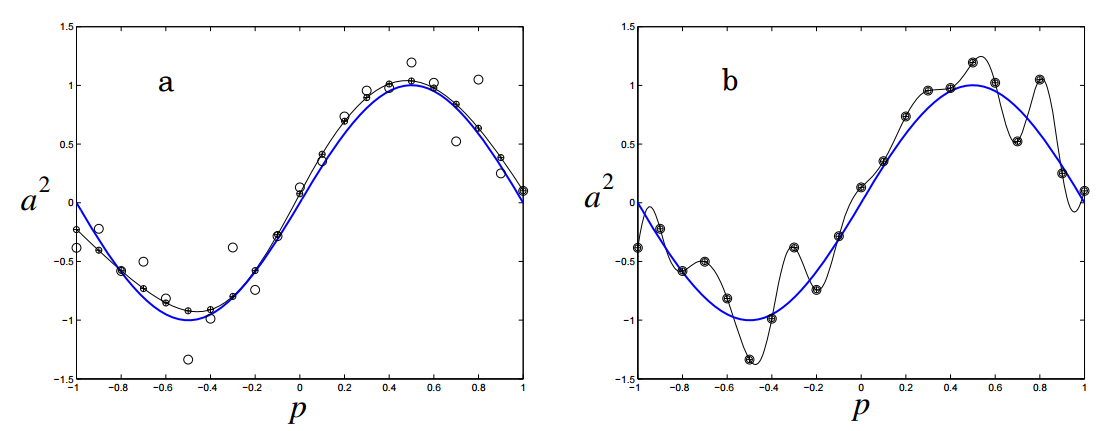
Regularization penalizes the neural network for using sophisticated architecture. The complexity in this case is measured by the size and weight of the network. It is established by adding an interval to the error function, which is tied to weight and size. This is the same as adding priority, which makes the neural network believe that the function is homogeneous.

n is the number of loads (weights) in the neural network. The α and β parameters control the level after which the network is under-trained or re-trained. Suitable values for them can be found through Bayesian analysis and optimization.

Another technique that is quite expensive in terms of computing is a global search. Here the search algorithm is used to differentiate the network architecture and find its optimal variant. Usually, a generation algorithm is used for this, which will be discussed below.
What is an "outpoint"?
The neural network can be used for regression or classification. In the first model, we work with a single value on the output. That is, you need only one output neuron. In the second model, an output neuron is needed for each class to which the pattern may belong, separately. If classes are not known, self-organizing maps are used.
Let's summarize this part of the story. The best approach to determine the size of the network is to follow the principle of Occam. That is, for two models with the same performance, a model with a smaller number of parameters will generalize more successfully. This does not mean that it is necessary to choose a simple model in order to improve performance. The converse is true: many hidden neurons and layers do not guarantee superiority. Too much attention today is paid to large networks, and too little to the very principles of their development. More is not always better.
5. A multitude of training algorithms are applicable to the neural network.
The learning algorithm is designed to optimize the weight of the neural network, until it stumbles upon some kind of stopping condition. This may be due to the appearance of an error in the training set at an acceptable level of accuracy (for example, when the network at the validation stage begins to deteriorate). This may be the point when some computational budget of the network has been spent. The most popular variant of the algorithm is the backpropagation method using a gradient stochastic descent. Reverse distribution consists of two steps:
- Direct transmission: the training data passes through the network, the output signal is recorded and errors are counted.
- Back propagation: the error signal is pulled back through the network, the weight of the network is optimized using a gradient descent.
There are several problems with this approach. Adjustment of all weights at the same time can lead to excessive movement of the net in the weight space. The gradient descent algorithm is rather slow and susceptible to a local minimum. Local minimum is a specific problem for certain neural networks. The first problem is solved through the use of different gradient descent options: (QuickProp), Nesterov's Accelerated Momentum (NAG), Adaptive Gradient Algorithm (AdaGrad), Resilient Propagation (RProp) or Root Mean Squared Propagation (RMSProp).

But all these algorithms cannot overcome the local minimum, and are less useful when they are trying to simultaneously optimize the architecture and network load. Need a global optimization algorithm. This may be Particle Swarm Optimization or a genetic algorithm. This is how it works.
The vector representation of a neural network encodes a neural network according to the load vector, each of the vectors represents the weight of the connection in the network. We can train the network using a meta-heuristic search algorithm. On too large networks, the method works poorly because the vectors themselves become too large.

The diagram shows how a neural network can be represented in vector notation.
The particle swarm method teaches the network through building a population / swarm. Each neural network here is represented as a load vector and corrected for the position of the global best particle and its own best position.
This adaptation function is calculated as the sum of the squares of the errors of the reconstructed neural network after the completion of one straight pass. Benefit is obtained by optimizing the update speed of link weights. If the scales are adjusted too quickly, the sum of squared errors stagnates, learning does not occur.
A genetic algorithm builds a population of a vector representing a neural network. Next, three successive operations are carried out with it to improve network performance:
- Sample: after each direct passage, the sum of squares of errors is calculated, the population of the neural network is ranked. The top percentage of the population is selected for survival and is used for the crossover.
- Crossover: the top x% of the population's genes compete with each other, we get some new progeny, each progeny represents, in fact, a new neural network.
- Mutation: this operator requires the support of genetic diversity in the population, a small percentage of it is selected for the passage of the mutation, that is, some of the weights of the network will be regulated randomly.
6. Neural networks do not always need a large amount of data.
Neural networks can use three basic learning strategies: supervised learning, unsupervised and enhanced learning. For the first, you need at least two training data sets. One of them will consist of input with expected output signals, the second with input without expected output. Both should include tagged data, that is, patterns with a previously unknown purpose.
Uncontrolled strategy is commonly used to identify hidden structures in unmarked data (for example, hidden Markov chains). The principle of operation is the same as that of cluster algorithms. Enhanced learning is based on the simple assumption of winning networks and placing them in poor conditions. The last two options do not imply the use of tagged data, so the correct output signal is unknown here.
Unsupervised learning
One of the most popular architectures for this type of network is a self-organizing map. In fact, this is a scaling technique in several dimensions, which constructs an approximation of the probability density function of some basic data cycle. Z - saves the topological structure of the data set by mapping the input signal vectors - zi. It weighs the vectors - vj, in the future map V. Preserving the topological structure means that if two vectors are close to each other in Z, the neurons to which they belong will also be located in V. You can read more here .
Enhanced training
This strategy consists of three components: attitudes on how the neural network will make decisions using technical and fundamental indicators, the functions of achieving the goal that separates the wheat from the chaff, and the function of value aimed at the future.
7. The neural network cannot be trained on any data.
One of the main problems, why the neural network may not work, is that the data are often poorly prepared before being loaded into the system. Normalization, removal of redundant information, sharply deviating values should be carried out before starting work with the network in order to improve its production capabilities.
We know that we have layers of perceptrons connected by weight. Each perceptron contains an activation function, which, in turn, is divided by rank. Input signals must be scaled based on this rank, so that the network can distinguish between input patterns. These are prerequisites for data normalization.
Highlighted values are either much more or much less than most other values in the data set for a set. Such things can cause problems in the application of statistical methods - regression and curve fitting. Because the system will try to adjust these values, the performance will deteriorate. Identifying such values yourself can be problematic. Here you can see instructions on techniques for working with sharply deviating values.
The introduction of two or more independent variables that closely correlate with each other can also cause a decrease in learning ability. Removing redundant variables, among other things, speeds up learning time. Adaptive neural networks can be used to remove redundant connections and perceptrons.
8. Neural networks sometimes need to be re-trained.
Even if you set up a neural network properly, and it trades successfully in the sample and outside, it does not mean that it will not stop working after some time. It's not about her, it's about how the financial market behaves. Financial markets are complex adaptive systems. What works today may not work tomorrow. This characteristic of theirs is called nonstationarity or dynamic optimization. Neural networks do not know how to deal with it.
The dynamic environment of financial markets is a very difficult thing to model with a neural network. There are two ways out of this situation: from time to time to retrain the network or use a dynamic neural network. It is designed to track changes in the environment over time and adapt them to the architecture and system load. To solve dynamic problems, you can use multilateral meta-heuristic optimization algorithms. They will track changes to local experience over time. One option is to optimize the multiple swarm, a derivative of the particle swarm method. Genetic algorithms with improved diversification and memory can also be useful in a dynamic environment.
9. The neural network is not a black box
The neural network itself is a “black box”. This creates certain problems for people who work or plan to work with it. For example, fund managers do not understand how the system makes decisions on financial transactions. From this it turns out that it is impossible to calculate the risk of the trading strategy that the network has learned. Again, banks using a neural network for credit risk miscalculations cannot verify its position in a credit rating for certain customers. For these purposes, algorithms for extracting network rules were invented. Knowledge can be pulled out of the network in the form of mathematical formulas, symbolic logic, fuzzy logic, decision tree.

: . , « ».
: , . A B «» — «», – «, «», «».
: OR, AND XOR. , . . (P), (SMA), (EMA) , , :
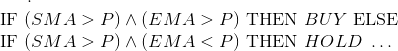
(fuzzy logic) – , . – «», «», «», «», 0 1. . , , , . , (GOOG) 0,7 BUY 0,3 SELL. - .
, . , , .
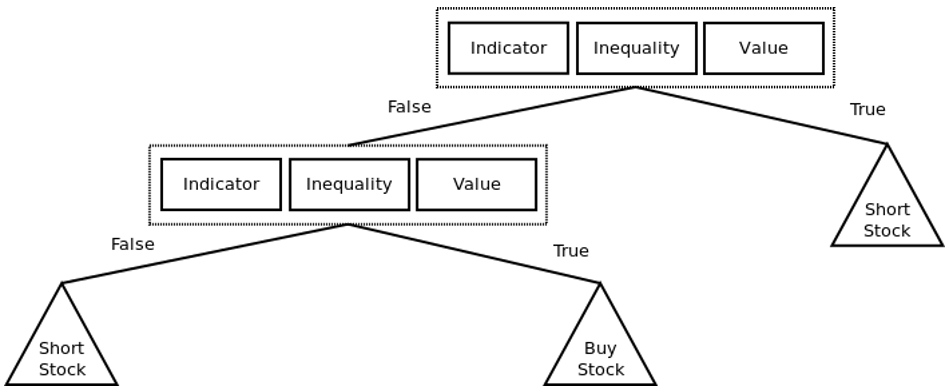
-, . (, BUY, HOLD SELL , ).
<indicator, inequality,="" value="">. , <sma,>, 25> or <ema, <="," 30="">.
10.
, . , , . , . , .
Caffe
- http://caffe.berkeleyvision.org/
GitHub - https://github.com/BVLC/caffe
Encog
- http://www.heatonresearch.com/encog/
GitHub - https://github.com/encog
H2O
- http://h2o.ai/
GitHub - https://github.com/h2oai
Google TensorFlow
- http://www.tensorflow.org/
GitHub - https://github.com/tensorflow/tensorflow
Microsoft Distributed Machine Learning Tookit
- http://www.dmtk.io/
GitHub - https://github.com/Microsoft/DMTK
Microsoft Azure Machine Learning
- https://azure.microsoft.com/en-us/services/machine-learning
GitHub — github.com/Azure?utf8=%E2%9C%93&query=MachineLearning
MXNet
- http://mxnet.readthedocs.org/en/latest/
GitHub - https://github.com/dmlc/mxnet
Neon
- http://neon.nervanasys.com/docs/latest/index.html
GitHub - https://github.com/nervanasystems/neon
Theano
- http://deeplearning.net/software/theano/
GitHub - https://github.com/Theano/Theano
Torch
- http://torch.ch/
GitHub - https://github.com/torch/torch7
SciKit Learn
- http://scikit-learn.org/stable/
GitHub - https://github.com/scikit-learn/scikit-learn
Conclusion
– . . . , , . , . , - .
Other materials on the topic from ITinvest :
- Analytical materials on the situation in the financial markets from ITinvest experts
- Is it possible to create an algorithm for trading on the exchange by analyzing the tonality of messages on the Internet
- How to determine the best time for a transaction in the stock market: Trend following algorithms
- IB start-up Palantir helps Credit Suisse investment bank create a system for identifying unscrupulous traders
- Experiment: Using Google Trends to predict stock market crashes
- Experiment: the creation of an algorithm for predicting the behavior of stock indices
Source: https://habr.com/ru/post/302120/
All Articles