Unkillable Postgresql cluster inside Kubernetes cluster
If you have ever thought about trust and hope, then most likely you have not experienced this to anything as much as to database management systems. Well, really, it's the same Database! The title contains the whole meaning - the place where the data is stored, the main task is to STORE. And what is the saddest thing, as always, once, these beliefs are broken against the remains of such a single dead database on the 'Prod'.
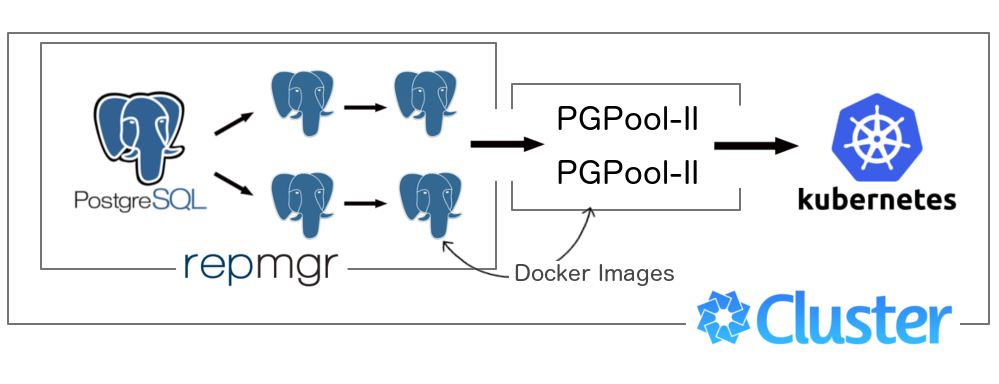
And what to do? - you ask. Do not deploy anything to the servers, we answer. Nothing that does not know how to repair itself, at least temporarily, but safely and quickly!
In this article I will try to talk about my customization experience. nearly Immortal Postgresql Cluster Inside Another Google Failsafe Solution - Kubernetes (aka k8s)
Content
The article was published a little more than expected, and therefore in the code there are many links, mainly to the code in the context in which it is discussed.
I also enclose a table of contents, including for the impatient, in order to go directly to the results:
Task
The need to have data storage for almost any application is a must. And to have this repository resistant to adversity on the network or on physical servers is a good tone for a competent architect. Another aspect is the high availability of the service even with large competing service requests, which means easy scaling if necessary.

Total we get problems to solve:
- Physically distributed service
- Balancing
- Unlimited scaling by adding new nodes
- Automatic recovery for failures, destruction and loss of communication nodes
- No single point of failure
Additional points due to the specifics of the author’s religious beliefs:
- Postgres (the most academic and consistent solution for RDBMS available for free)
- Docker packaging
- Kubernetes infrastructure description
On the diagram, it will look something like this:
master (primary node1) --\ |- slave1 (node2) ---\ / balancer \ | |- slave2 (node3) ----|---| |----client |- slave3 (node4) ---/ \ balancer / |- slave4 (node5) --/ Subject to input:
- More read requests (in relation to the write)
- Linear increase in load at peaks to x2 from the average
Solution by "googling"
Being tempted to solve IT problems, I decided to ask the collective mind: "postgres cluster kubernetes" is a pile of garbage, "postgres cluster docker" is a pile of garbage, "postgres cluster" is a few options from which I had to wallow.

What upset me is the lack of sane Docker builds and a description of any option for clustering. Not to mention the Kubernetes. By the way, there were not many options for Mysql, but there were some. At least I liked the example in the official k8s repository for Galera (Mysql cluster)
Google has made it clear that the problems will have to be solved by myself and in the manual mode ... "but at least with the help of scattered tips and articles," I breathed.
Bad and inevitable solutions
Immediately, I note that all the points in this paragraph may be subjective and, quite even, viable. However, relying on my experience and flair, I had to cut them off.

When someone makes a universal decision (for whatever), it always seems to me that such things are cumbersome, cumbersome and heavy to maintain. It was the same with Pgpool, which can do almost everything:
- Balancing
- Storage of connections for optimization of connection and speed of access to the database
- Support for different replication options (stream, slony)
- Auto detection of Primary server for writing, which is important when reorganizing roles in a cluster
- Failover / failback support
- Own master-master replication
- Coordinated work of several nodes Pgpool-ov to eradicate a single point of failure.
I found the first four points useful, and stopped at that, having understood and considered the problems of the others:
- Recovery with Pgpool2 does not offer any decision system on the next master - all logic must be described in the failover / failback commands
- The recording time, with master-master replication, is reduced to the doubled variant without it, regardless of the number of nodes ... well, at least it does not grow linearly
- How to build a cascade cluster (when one slave reads from the previous slave) is not at all clear
- Of course, it’s good that Pgpool knows about its brothers and can quickly become an active link in case of problems at the neighboring node, but this problem is solved for me by Kubernetes, which guarantees similar behavior for, in general, any service installed in it.
Actually, also reading and comparing what was found with the streaming replication ( Streaming Replication ) that was already familiar and working out of the box, it was easy to not even think about Elephants.
And everything else, on the very first page of the project site, the guys write that, with postgres 9.0+, you do not need Slony, provided there are no specific system requirements:
- partial replication
- integration with other solutions ("Londiste and Bucardo")
- additional replication behavior
In general, I think Slony is not a cake ... at least if you do not have these three specific tasks.
Looking around and understanding the ideal two-way replication approach, it turned out that the victims are not compatible with the life of some applications. Not to mention the speed, there are restrictions in working with transactions, complex queries ( SELECT FOR UPDATE and others).
It is quite likely that I am not so tempted precisely in this matter, but it was enough for me to see what was also left behind. And still brains, it seemed to me that for a system with an enhanced write operation, completely different technologies are needed, rather than relational databases.
Consolidation and build solutions
In the examples I will talk about how the solution should look fundamentally, and in the code how it came out for me. To create a cluster, it is not at all necessary to have Kubernetes (there is an example of docker-compose) or a Docker in principle. Just then, everything described will be useful, not as a solution like CPM (Copy-Paste-Modify), but as a guide for installing with snippets.
Primary and Standby instead of Master and Slave
Why did the colleagues from Postgresql reject the terms "Master" and "Slave"? .. hmm, I could be wrong, but there was a rumor that because of non-polit-correctness, they say that slavery is bad . Well, right.

The first thing to do is turn on the Primary server, followed by the first Standby layer, and then the second one - all according to the task. From here we get a simple procedure to enable the usual Postgresql server in Primary / Standby mode with the configuration to enable Streaming Replication
wal_level = hot_standby max_wal_senders = 5 wal_keep_segments = 5001 hot_standby = on All the parameters in the comments have a brief description, but if in brief, this configuration makes the server understand that it is now part of a cluster and, in which case, it should be allowed to read the WAL logs to other clients. Plus allow requests during recovery. An excellent description of the detailed configuration of this kind of replication can be found on the Postgresql Wiki .
Once we got the first server in the cluster, we can turn on Stanby, who knows where his Primary is located.
My task here is to build a universal Docker Image image, which is included in the work, depending on the mode, something like this:
- For Primary :
- Configures Repmgr (more on that later)
- Creates a database and user application
- Creates a database and user to monitor and support replication
- Updates the config (
postgresql.conf) and gives access to users from outside (pg_hba.conf) - Launches Postgresql service in background
- Registered as Master in Repmgr
- Runs
repmgrd- arepmgrddaemon to monitor replication (more about it later)
- For Standby :
- Clones the Primary server with Repmgr (by the way with all configs, since it simply copies the
$PGDATAdirectory) - Configures Repmgr
- Starts Postgresql service in the background - after cloning, the service is aware that it is standby and dutifully follows Primary
- Registered as Slave in Repmgr
- Run
repmgrd
- Clones the Primary server with Repmgr (by the way with all configs, since it simply copies the
For all these operations, the sequence is important, and therefore the code crammed in sleep . I know - it’s not good, but it’s so convenient to configure delays through ENV variables, when you need to start all containers at once (for example, via docker-compose up )
All variables to this image are described in the docker-compose file .
The only difference between the first and second layer of Standby services is that for the second master any service from the first layer, and not Primary, is the master. Do not forget that the second echelon should start after the first with a delay in time.
Split-brain and the election of a new leader in the cluster
Split brain is a situation in which different segments of the cluster can create / elect a new Master and think that the problem is solved.

This is one, but far from the only problem that Repmgr helped me to solve.
In essence, this is a manager who can do the following:
- Clone Master (master - in Repmgr terms) and automatically infuse a reborn Slave
- To help reanimate the cluster at the death of the Master.
- In automatic or manual mode, Repmgr can elect a new Master and reconfigure all Slave services to follow the new leader.
- Remove nodes from cluster
- Monitor cluster health
- Execute commands for events within the cluster
In our case, repmgrd comes to the repmgrd and is started by the main process in the container and monitors the integrity of the cluster. In a situation where access to the Master server is lost, Repmgr tries to analyze the current cluster structure and decide on who will be the next Master. Naturally Repmgr is smart enough not to create a Split Brain situation and choose the only right Master.
Pgpool-II - swiming pool of connections
The last part of the system is Pgpool. As I wrote in the bad decisions section, the service still does its job:
- Balances the load between all the nodes of the cluster
- Stores connection descriptors to optimize database access speed
- In our case, Streaming Replication - automatically finds the Master and uses it for write requests.

As an outcome, I got a fairly simple Docker Image , which at startup configures itself to work with a set of nodes and users who will have the opportunity to pass md5 authorization through Pgpool ( with this, too, as it turned out, not everything is simple )
Very often, the problem arises of getting rid of a single point of failure, and in our case, this point is the pgpool service, which proxies all requests and may become the weakest link in the data access path.
Fortunately, in this case, our problem is solved by k8s and allows us to make as many replications of the service as needed.
Unfortunately, this is not the case for Kubernetes , but if you are familiar with how Replication Controller and / or Deployment work , then it’s easy to do the above.
Result
This article is not a retelling of the scripts for solving the problem, but a description of the structure of the solution to this very task. That means - for a deeper understanding and optimization of the solution, you will have to read the code, at least README.md in github , which is step by step and meticulously telling how to start the cluster for docker-compose and Kubernetes. Everything else, for those who like and decide to move on with this, I am ready to lend a virtual helping hand .

- Sources and documentation on GitHub
- Docker Image for cluster-ready Postgresql from example
- Docker Image for Pgpool with setting via ENV variables
Documentation and material used
PS:
I hope that the stated material will be useful and will give a little positive before the beginning of summer! Good luck and good mood, colleagues;)
')
Source: https://habr.com/ru/post/301370/
All Articles