Experience of moving to a Single Page Application with an emphasis on SEO
Hello to all.
We are a classic web 2.0 site made on Drupal. We can say that we are a media site, because we have a lot of various articles, and new ones are constantly coming out. We pay a lot of attention to SEO. We even have specially trained people who work full time for this.
More than 400k unique users come to us per month. Of these, 90% comes from Google search.
And now, for almost half a year, we have developed the Single Page Application version of our site.
As you probably already know, JS is the eternal pain of SEOs. And you can not just take and make a site on JS.
Before starting the development, we began to explore this question.
And they found out that the generally accepted way is to give the google bot a rendered version of the page.
Making AJAX applications crawlable
It also turned out that this method is no longer recommended by Google and they assure that their bot can open js sites, not worse than modern browsers.
Understand your web pages like modern browsers.
Since at the time of our decision, Google had just abandoned this method, and no one had yet time to check how Google Crawler actually indexes websites made in JS. We decided to take a chance and make a SPA site without additional page rendering for bots.
What for?
Due to the uneven load on the server, and the inability to flexibly optimize pages, it was decided to divide the site into a backend (current version on Drupal) and a frontend (SPA on AngularJS).
Drupal will be used exclusively for moderating content and sending all kinds of mail.
AngularJS will draw everything that should be available to users of the site.
Technical details
As a server for the frontend, it was decided to use Node.js + Express .
REST Server
From Drupal, we made a REST server by simply creating a new prefix / v1 / i. all requests coming to / v1 / were perceived as requests to REST. All other addresses remain unchanged.
Page addresses
It is very important for us that all public pages live at the same addresses as before. Therefore, before developing the SPA version, we structured all the pages so that they have common prefixes. For example:
All forum pages should live at / forum / *, while the forum has categories and the topics themselves. For them, the url will look like this /forum/{category}/{topic} . There should be no random pages at random addresses, everything should be logically structured.
Redirects
The site has been available since 2007, and during that time a lot has changed. Including page addresses. We have saved the whole story, as the pages moved from one address to another. And when you try to request any old address, you will be forwarded to a new one.
In order for the new frontend to also redirect, we before sending the page to the nodejs send the request back to Drupal, and ask what is the status of the requested address. It looks like this:
curl -X GET --header 'Accept: application/json' 'https://api.example.com/v1/path/lookup?url=node/1' To which Drupal replies:
{ "status": 301, "url": "/content/industry/accountancy-professional-services/accountancy-professional-services" } After that, nodeJS decides to remain at the current address, if it is 200, or redirect to another address.
app.get('*', function(req, res) { request.get({url: 'https://api.example.com/v1/path/lookup', qs: {url: req.path}, json: true}, function(error, response, data) { if (!error && data.status) { switch (data.status) { case 301: case 302: res.redirect(data.status, 'https://www.example.com' + data.url); break; case 404: res.status(404); default: res.render('index'); } } else { res.status(503); } }); }); Images
In the content coming from Drupal there may be files that do not exist in the frontend version. That's why we decided to just stream them from Drupal through nodejs.
app.get(['*.png', '*.jpg', '*.gif', '*.pdf'], function(req, res) { request('https://api.example.com' + req.url).pipe(res); }); sitemap.xml
Since Since sitemap.xml is constantly generated in Drupal, and the page addresses match the frontend, it was decided to simply stream sitemap.xml. Absolutely the same as with pictures:
app.get('/sitemap.xml', function(req, res) { request('https://api.example.com/sitemap.xml').pipe(res); }); The only thing you should pay attention to is that Drupal substituted the correct address of the site that is used on the frontend. There is a setting in the admin panel.
robots.txt
- The content available to the google crawler bot should not be duplicated between our two servers.
- All Drupal content requested through the frontend should be available for viewing by the bot.
As a result, our robots.txt looks like this:
In Drupal, forbid everything except / v1 /:
User-agent: * Disallow: / Allow: /v1/ In the frontend, just allow everything:
User-agent: * Release preparation
Before the release, we placed the frontend version at https://new.example.com address.
And for the Drupal version reserved additional subdomain https://api.example.com/
After that, we linked the frontend so that it works with the https://api.example.com/ address.
Release
The release itself looks like a simple rearrangement of servers in the DNS. We point our current @ address to the frontend server. Then we sit and see how everything works.
It is worth noting that if you use CNAME records, the server will be replaced instantly. Record A will resolve to DNS up to 48 hours.
Performance
After dividing the site into frontend and backend, the server load became measured. It is also worth noting that we didn’t particularly optimize sql queries, all queries pass through without caching. All optimization was planned after the release.
I do not have a metric before the release, but there is a metric after we rolled back :)


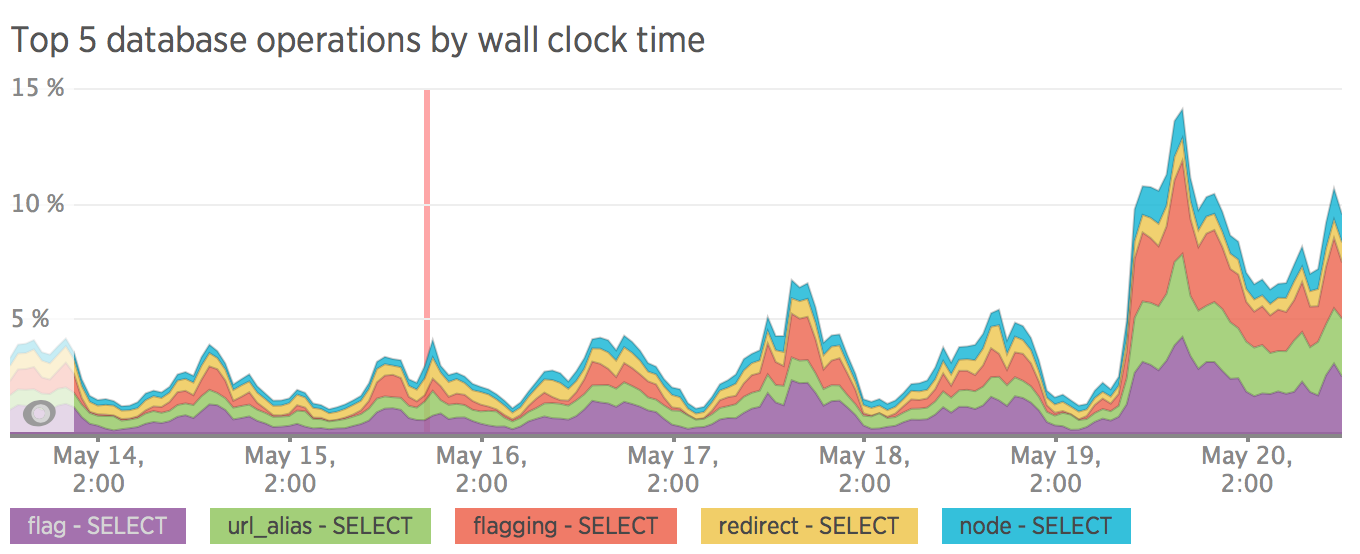
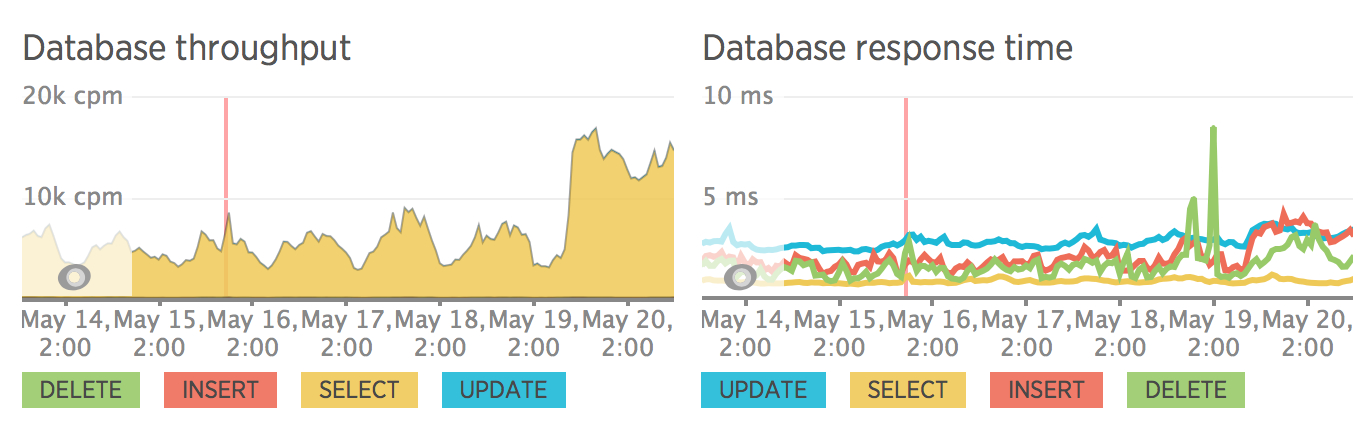
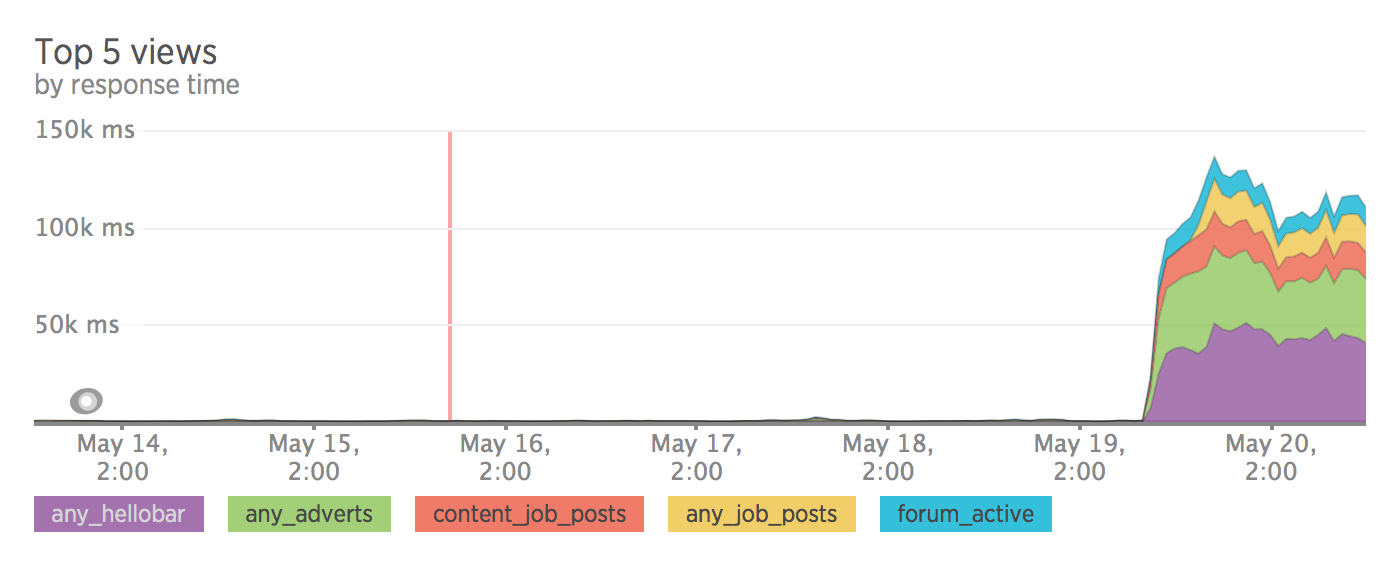
SEO
Here everything was not as good as we would like. After a little more than a week of testing, traffic to the site fell by 30%.

Some pages fell out of the google index, some became very oddly indexed, without meta description.
An example of how Google has indexed this page.
We also noticed that after the release of the new site, Google noticed this, and began to pande the entire site. Thereby updating all your cache.
After that, Crawler found a huge number of old pages, which should not have been in the index long ago.
The graph below shows the graph found 404 pages. It can be seen that before the release, we did a sweep of the content, and Google slowly deleted the old pages. But after the release, he began to do it much more actively.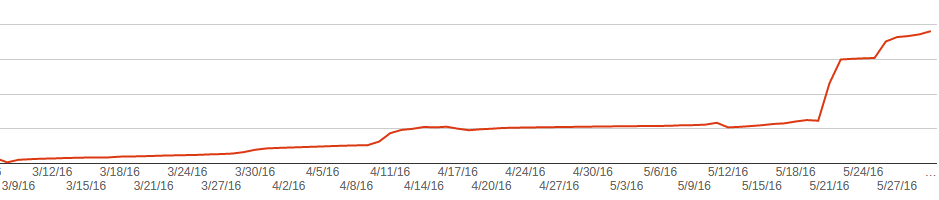
Result / Conclusions
Due to problems with indexing, it was decided to roll back to Drupal, and to think that we did wrong.
Everything is complicated by the fact that google is a kind of black box, which, if something goes wrong, doesn't just remove the pages from the index. And any of our experiments require a couple of days for this to be reflected in the search results.
One of the more likely versions is that Google Crawler has certain limitations. This can be a memory or a page rendering time.
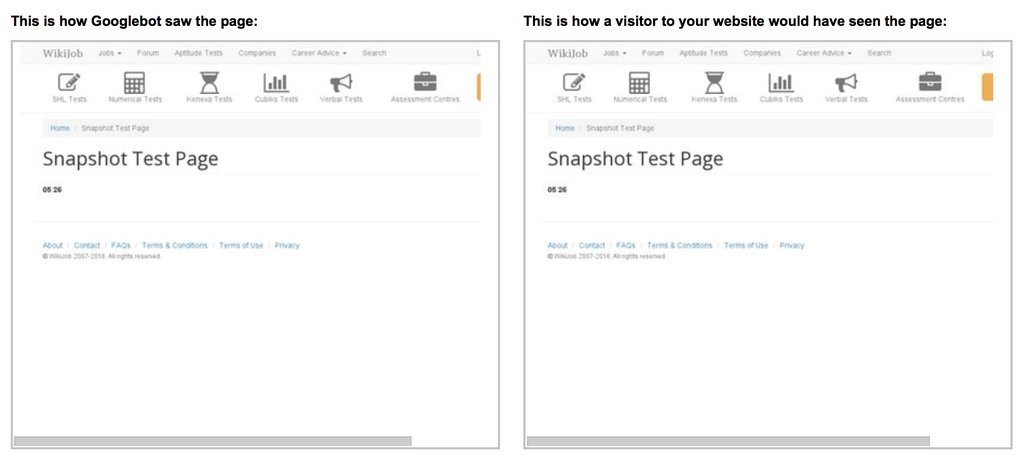
I made a small test by creating a page with a stopwatch, and tried to draw it as a crawler in the Google Search Console. In the screenshot, the stopwatch stopped at 5.26 seconds. I think the crawler waits for the page for about 5 seconds, and then it takes a snapshot, and everything loaded after - the index does not fit.
useful links
Update
- Added a chart from google analytics showing how traffic sank.
- I found out that Google Crawler has about 5 seconds to render the page.
- I found out that Google Crawler understands when the site is updated, and re-indexes it.
')
Source: https://habr.com/ru/post/301288/
All Articles