Creating a first-level in-memory cache for StackExchange.Redis .NET clients
Jonathan Cardy has written the open source StackRedis.L1 .NET library that allows you to create a first-level cache for Redis. In other words, using the StackExchange.Redis library in a .NET application, you can connect StackRedis.L1 to it to speed up work due to local caching of data in RAM. This avoids unnecessary redis calls in cases where the data has not been altered. The library is available on GitHub and NuGet.
This article describes how and why it was created.

Prehistory
For the past couple of years I have been working on the Repsor custodian application managed by SharePoint. If you are familiar with SharePoint, you know that its model requires running applications on a separate server. This makes it possible to increase the stability and simplify the architecture. However, this model works to the detriment of performance, since you have to go to the SharePoint server for data every time, and network delays in this case do not play in your favor.
')
For this reason, we decided to add Redis caching to the application using StackExchange.Redis as a .NET client. For full caching of all application data models, we use sets, ordered sets, and hash tables.
As expected, this greatly accelerated the work of the application. Now the pages returned in about 500 ms instead of 2 s, as before. But the analysis showed that even from these 500 ms a considerable part of the time was spent on sending or receiving data from Redis. Moreover, the main part of the data received each time on request from the page has not been changed.
Cache cache
Redis is not only an incredibly fast caching tool, but also a set of tools for managing cached data. This system is well developed and very widely supported. StackExchange.Redis is free and open source, and its community is growing rapidly. Stack Exchange aggressively caches all Redis data, even though it is one of the busiest sites on the Internet. But the main advantage is that it performs in-memory caching of all available data on the Redis server and, thus, it usually does not even have to turn to Redis.
The following quote explains to some extent how the caching mechanism works in the Stack Exchange:
http://meta.stackexchange.com/questions/69164/does-stack-exchange-use-caching-and-if-so-how
When you cache data before it enters another cache, you create several cache levels. If you perform in-memory caching of data before caching it in Redis, the in-memory cache is assigned the first L1 level.
Therefore, if Redis is the slowest part of your application, you are on the right track and can definitely speed up this flaw further.
In-memory caching
In the simplest situation when using Redis, your code will look like this:
And if you decide to use in-memory caching (i.e. L1 cache), the code will be a bit more complicated:
And although it is not so difficult to implement, everything becomes much more difficult, you should try to do the same steps for other data models in Redis. In addition, the following problems will arise:
• Redis allows us to manipulate data through functions like StringAppend. In this case, we will have to declare the in-memory element invalid.
• If you delete a key via KeyDelete, it must also be deleted from the in-memory cache.
• If another client changes or deletes a value, it becomes obsolete in our client's in-memory cache.
• When a key expires, it must be removed from the in-memory cache.
Methods for accessing and updating data in the StackExchange.Redis library are defined in the IDatabase interface. It turns out that we can rewrite the implementation of IDatabase to solve all the above problems. Here's how to do it:
• StringAppend - add data to the in-memory string, and then pass the same operation to Redis. For more complex data operations, you will need to remove the in-memory key.
• KeyDelete, KeyExpire, etc. — deletes in-memory data.
• Operations through another client - keyspace notifications in Redis are designed to detect changes to the data and declare them invalid accordingly.
The beauty of this approach is that you continue to use the same interface as before. It turns out that the introduction of L1-cache does not require any changes in the code.
Architecture
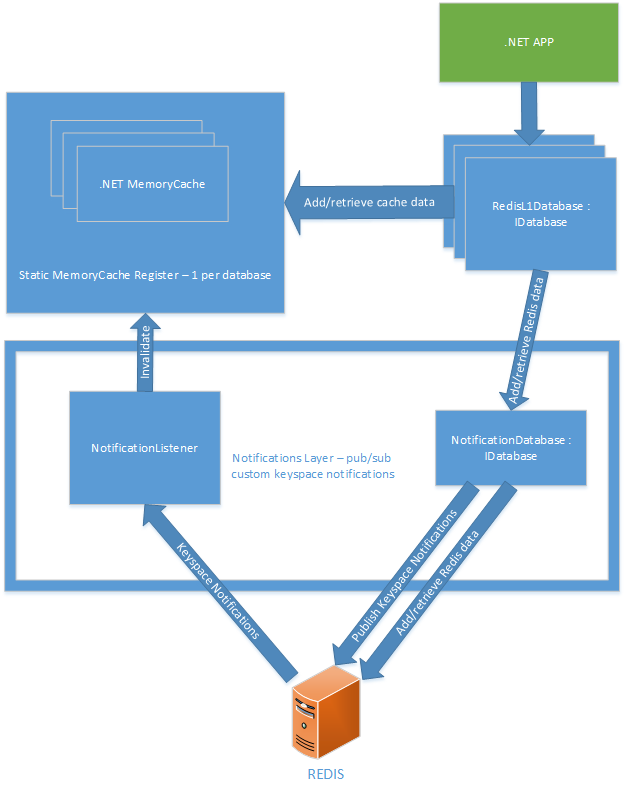
I chose the following solution with these basic elements:
Static MemoryCache Register
You can create new RedisL1Database entities by passing a ready-made entity to Redis IDatabase, and it will continue to use any in-memory cache that it has previously created for this database.
Notification level
• NotificationDatabase - publishes special keyspace events necessary to maintain the in-memory cache. Standard keyspace notifications in Redis do not allow to achieve the same result, since they do not provide enough information to invalidate the necessary part of the cache. For example, if you delete a hash key, you get a HDEL notification with information about which hash it was deleted from. But it does not indicate which element of the hash it was. In turn, special events also contain information about the hash element itself.
• NotificationListener — Subscribes to special keyspace events and accesses static cache to invalidate the required key. It also subscribes to the built-in Redis keyspace event called expire. This allows you to quickly delete from memory all expired Redis keys.
Next we look at how to cache various data models in Redis.
Line
Working with a string is relatively simple. The IDatabase StringSet method looks like this:
• Key and Value - the names speak for themselves.
• Expiry - an arbitrary period of time, and therefore we need to use in-memory cache with a validity period.
• When - allows you to define the conditions for creating a string: set a string only if it already exists or does not exist yet.
• Flags - allows you to specify the details of the Redis cluster (not relevant).
For data storage, we use System.Runtime.Caching.MemoryCache, which allows for the automatic expiration of keys. The StringSet method looks like this:
Then StringGet can read the in-memory cache before attempting to access Redis:
Redis supports many operations for strings. In each case, their use is associated with either updating the in-memory value or declaring it invalid. In general, the second option is better, because otherwise you risk in vain complicate many operations Redis.
• StringAppend is a very simple operation. Data is added to the in-memory line, if one exists and is not declared inactive.
• StringBitCount, StringBitOperation, StringBitPosition - the operation is performed in Redis, in-memory activation is not required.
• StringIncrement, StringDecrement, StringSetBit, StringSetRange - the in-memory string is declared invalid until the operation is redirected to Redis.
• StringLength - returns the length of a string if it is in the in-memory cache. If not, the operation gets it from Redis.
Lots of
The sets are a bit more difficult to handle. The SetAdd method is executed as follows:
1. Check MemoryCache on HashSet with this key
• If one does not exist, create it.
2. Add each Redis value to the set.
Adding and removing values from sets is quite simple. The SetMove method is SetRemove followed by SetAdd.
Most other set requests can be cached. For example:
• SetMembers - returns all elements of a set so that the result is stored in memory.
• SetContains, SetLength - checks in-memory sets before accessing Redis.
• SetPop - pushes a data item from the Redis set and then removes this item from the in-memory set, if there is one.
• SetRandomMember - receives a random set element from Redis, then in-memory caches it and returns it.
• SetCombine, SetCombineAndStore - in-memory activation is not required.
• SetMove — Removes a data item from an in-memory set, adds it to another in-memory set, and redirects it to Redis.
Hash tables
Hash tables are also relatively simple, since their in-memory implementation is just a Dictionary <string, RedisValue>, which, in principle, is very similar to a string.
Basic operation:
1. If the hash table is not available in in-memory, you need to create a Dictionary <string, RedisValue> and save it.
2. Perform operations on the in-memory dictionary, if possible.
3. Redirect the request to Redis, if necessary.
• Cache the result.
The following operations are available for hash tables:
• HashSet — saves values in a dictionary stored in the key, and then redirects the request to Redis.
• HashValues, HashKeys, HashLength - there is no in-memory application.
• HashDecrement, HashIncrement, HashDelete - deletes the value from the dictionary and redirects to Redis.
• HashExists - returns true if the value is in the in-memory cache. Otherwise, it redirects the request to Redis.
• HashGet - requests data from the in-memory cache. Otherwise, it redirects the request to Redis.
• HashScan - get results from Redis and add them to the in-memory cache.
Ordered set
Ordered sets are undoubtedly the most complex data model in terms of creating an in-memory cache. In this case, the in-memory caching process involves the use of so-called "disjoint ordered sets." That is, each time the local cache sees a small fragment of an ordered Redis set, this fragment is added to the “disjoint” ordered set. If a subsection of an ordered set is later requested, the non-intersecting ordered set will be checked first. If it contains the entire section, it can be returned with full confidence that there are no missing components.
Ordered in-memory sets are sorted not by value, but by a special parameter score. Theoretically, it would be possible to expand the implementation of disjoint ordered sets so that it is possible to sort them by value, but at the moment this is not yet implemented.
Operations use disjoint sets as follows:
• SortedSetAdd - values are added to the in-memory set discretely, which means we do not know whether they are related in terms of score.
• SortedSetRemove - the value is deleted both from memory and from Redis.
• SortedSetRemoveRangeByRank - all in-memory sets are declared invalid.
• SortedSetCombineAndStore, SortedSetLength, SortedSetLengthByValue, SortedSetRangeByRank, SortedSetRangeByValue, SortedSetRank - the request is sent directly to Redis.
• SortedSetRangeByRankWithScores, SortedSetScan - data is requested from Redis and then discretely cached.
• SortedSetRangeByScoreWithScores is the most cached feature, as scores are returned in order. The cache is checked, and if it can process the request, it is returned. Otherwise, a request is sent to Redis, after which scores are cached in memory as a continuous data set.
• SortedSetRangeByScore - data is taken from the cache, if possible. Otherwise, they are taken from Redis and are not cached, since scores are not returned.
• SortedSetIncrement, SortedSetDecrement - in-memory data is updated, and the request is redirected to Redis.
• SortedSetScore - the value is taken from memory, if possible. Otherwise, a request is sent to Redis.
The complexity of working with ordered sets is due to two reasons: first, the characteristic difficulty of constructing in-memory implementations for existing subsets of ordered sets (that is, building discontinuous sets). And secondly, due to the number of operations available in Redis that require execution. To some extent, complexity is reduced by the ability to implement targeted caching of queries, including Score. Either way, you need serious unit testing of all components.
List
Lists are not so easy to cache in RAM. The reason is that operations with them, as a rule, imply work either with the head or with the tail of the list. And this is not as easy as it may seem at first glance, because we do not have one hundred percent opportunity to make sure that the in-memory list has the same data at the beginning and at the end as the list in Redis. Partially this difficulty could be solved with the help of key space notifications, but so far this possibility has not been realized.
Updates from other customers
Up to this point, we proceeded from the consideration that we have only one Redis database client. In fact, customers can be many. Under such conditions, it is quite possible that one client has data in the in-memory cache, and another one updates it, which makes the data of the first client invalid. There is only one way to solve this problem - to set up communication between all clients. Fortunately, Redis provides a publisher-subscriber messaging mechanism. This template has 2 types of notifications.
Key Space Notifications
These notifications are published to Redis automatically when the key changes.
Specially published notices
They are published at the notification level, implemented as part of the caching mechanism for the client. Their goal is to reinforce the key space notifications with additional information necessary to invalidate certain small parts of the cache.
Working with multiple clients is a major cause of caching problems.
Risks and problems
Lost Notifications
Redis does not guarantee delivery of key space notifications. Accordingly, notifications can be lost, and invalid data will remain in the cache. This is one of the most basic risks, but, fortunately, such situations rarely occur. However, when working with two or more clients, this danger must be taken into account.
Solution: use a reliable messaging mechanism between customers with guaranteed delivery. Unfortunately, this is not yet, so see the alternative solution.
Alternative solution: perform in-memory caching only for a short time, say, for one hour. In this case, all data that we access within an hour will load faster. And if any notification is lost, this omission will soon be filled. Call the Dispose method on the database, and then instantiate it again to clear it.
Uses one - use all
If one client uses this caching level (L1), all other clients must use it to notify each other when data changes.
No limit for in-memory data
At the moment, everything that can be cached will be sent to the cache. In such a situation, you can quickly run out of memory. In my case, this is not a problem, but just keep this in mind.
Conclusion
They say there are only 10 complex problems in programming: cache invalidation, naming and the binary system ... I am sure this project can be useful in many situations. The source code for the library is available on GitHub . Follow the project and take part in it!
This article describes how and why it was created.
Prehistory
For the past couple of years I have been working on the Repsor custodian application managed by SharePoint. If you are familiar with SharePoint, you know that its model requires running applications on a separate server. This makes it possible to increase the stability and simplify the architecture. However, this model works to the detriment of performance, since you have to go to the SharePoint server for data every time, and network delays in this case do not play in your favor.
')
For this reason, we decided to add Redis caching to the application using StackExchange.Redis as a .NET client. For full caching of all application data models, we use sets, ordered sets, and hash tables.
As expected, this greatly accelerated the work of the application. Now the pages returned in about 500 ms instead of 2 s, as before. But the analysis showed that even from these 500 ms a considerable part of the time was spent on sending or receiving data from Redis. Moreover, the main part of the data received each time on request from the page has not been changed.
Cache cache
Redis is not only an incredibly fast caching tool, but also a set of tools for managing cached data. This system is well developed and very widely supported. StackExchange.Redis is free and open source, and its community is growing rapidly. Stack Exchange aggressively caches all Redis data, even though it is one of the busiest sites on the Internet. But the main advantage is that it performs in-memory caching of all available data on the Redis server and, thus, it usually does not even have to turn to Redis.
The following quote explains to some extent how the caching mechanism works in the Stack Exchange:
http://meta.stackexchange.com/questions/69164/does-stack-exchange-use-caching-and-if-so-how
“Undoubtedly, the most optimal amount of data that can be sent most quickly over the network is 0 bytes.”
When you cache data before it enters another cache, you create several cache levels. If you perform in-memory caching of data before caching it in Redis, the in-memory cache is assigned the first L1 level.
Therefore, if Redis is the slowest part of your application, you are on the right track and can definitely speed up this flaw further.
In-memory caching
In the simplest situation when using Redis, your code will look like this:
//Try and retrieve from Redis RedisValue redisValue = _cacheDatabase.StringGet(key); if(redisValue.HasValue) { return redisValue; //It's in Redis - return it } else { string strValue = GetValueFromDataSource(); //Get the value from eg. SharePoint or Database etc _cacheDatabase.StringSet(key, strValue); //Add to Redis return strValue; } And if you decide to use in-memory caching (i.e. L1 cache), the code will be a bit more complicated:
//Try and retrieve from memory if (_memoryCache.ContainsKey(key)) { return key; } else { //It isn't in memory. Try and retrieve from Redis RedisValue redisValue = _cacheDatabase.StringGet(key); if (redisValue.HasValue) { //Add to memory cache _memoryCache.Add(key, redisValue); return redisValue; //It's in redis - return it } else { string strValue = GetValueFromDataSource(); //Get the value from eg. SharePoint or Database etc _cacheDatabase.StringSet(key, strValue); //Add to Redis _memoryCache.Add(key, strValue); //Add to memory return strValue; } } And although it is not so difficult to implement, everything becomes much more difficult, you should try to do the same steps for other data models in Redis. In addition, the following problems will arise:
• Redis allows us to manipulate data through functions like StringAppend. In this case, we will have to declare the in-memory element invalid.
• If you delete a key via KeyDelete, it must also be deleted from the in-memory cache.
• If another client changes or deletes a value, it becomes obsolete in our client's in-memory cache.
• When a key expires, it must be removed from the in-memory cache.
Methods for accessing and updating data in the StackExchange.Redis library are defined in the IDatabase interface. It turns out that we can rewrite the implementation of IDatabase to solve all the above problems. Here's how to do it:
• StringAppend - add data to the in-memory string, and then pass the same operation to Redis. For more complex data operations, you will need to remove the in-memory key.
• KeyDelete, KeyExpire, etc. — deletes in-memory data.
• Operations through another client - keyspace notifications in Redis are designed to detect changes to the data and declare them invalid accordingly.
The beauty of this approach is that you continue to use the same interface as before. It turns out that the introduction of L1-cache does not require any changes in the code.
Architecture
I chose the following solution with these basic elements:
Static MemoryCache Register
You can create new RedisL1Database entities by passing a ready-made entity to Redis IDatabase, and it will continue to use any in-memory cache that it has previously created for this database.
Notification level
• NotificationDatabase - publishes special keyspace events necessary to maintain the in-memory cache. Standard keyspace notifications in Redis do not allow to achieve the same result, since they do not provide enough information to invalidate the necessary part of the cache. For example, if you delete a hash key, you get a HDEL notification with information about which hash it was deleted from. But it does not indicate which element of the hash it was. In turn, special events also contain information about the hash element itself.
• NotificationListener — Subscribes to special keyspace events and accesses static cache to invalidate the required key. It also subscribes to the built-in Redis keyspace event called expire. This allows you to quickly delete from memory all expired Redis keys.
Next we look at how to cache various data models in Redis.
Line
Working with a string is relatively simple. The IDatabase StringSet method looks like this:
public bool StringSet(RedisKey key, RedisValue value, TimeSpan? expiry = default(TimeSpan?), When when = When.Always, CommandFlags flags = CommandFlags.None) • Key and Value - the names speak for themselves.
• Expiry - an arbitrary period of time, and therefore we need to use in-memory cache with a validity period.
• When - allows you to define the conditions for creating a string: set a string only if it already exists or does not exist yet.
• Flags - allows you to specify the details of the Redis cluster (not relevant).
For data storage, we use System.Runtime.Caching.MemoryCache, which allows for the automatic expiration of keys. The StringSet method looks like this:
public bool StringSet(RedisKey key, RedisValue value, TimeSpan? expiry = default(TimeSpan?), When when = When.Always, CommandFlags flags = CommandFlags.None) { if (when == When.Exists && !_cache.Contains(key)) { //We're only supposed to cache when the key already exists. return; } if (when == When.NotExists && _cache.Contains(key)) { //We're only supposed to cache when the key doesn't already exist. return; } //Remove it from the memorycache before re-adding it (the expiry may have changed) _memCache.Remove(key); CacheItemPolicy policy = new CacheItemPolicy() { AbsoluteExpiration = DateTime.UtcNow.Add(expiry.Value) }; _memCache.Add(key, o, policy); //Forward the request on to set the string in Redis return _redisDb.StringSet(key, value, expiry, when, flags); Then StringGet can read the in-memory cache before attempting to access Redis:
public RedisValue StringGet(RedisKey key, CommandFlags flags = CommandFlags.None) { var cachedItem = _memCache.Get<redisvalue>(key); if (cachedItem.HasValue) { return cachedItem; } else { var redisResult = _redisDb.StringGet(key, flags); //Cache this key for next time _memCache.Add(key, redisResult); return redisResult; } } </redisvalue> Redis supports many operations for strings. In each case, their use is associated with either updating the in-memory value or declaring it invalid. In general, the second option is better, because otherwise you risk in vain complicate many operations Redis.
• StringAppend is a very simple operation. Data is added to the in-memory line, if one exists and is not declared inactive.
• StringBitCount, StringBitOperation, StringBitPosition - the operation is performed in Redis, in-memory activation is not required.
• StringIncrement, StringDecrement, StringSetBit, StringSetRange - the in-memory string is declared invalid until the operation is redirected to Redis.
• StringLength - returns the length of a string if it is in the in-memory cache. If not, the operation gets it from Redis.
Lots of
The sets are a bit more difficult to handle. The SetAdd method is executed as follows:
1. Check MemoryCache on HashSet with this key
• If one does not exist, create it.
2. Add each Redis value to the set.
Adding and removing values from sets is quite simple. The SetMove method is SetRemove followed by SetAdd.
Most other set requests can be cached. For example:
• SetMembers - returns all elements of a set so that the result is stored in memory.
• SetContains, SetLength - checks in-memory sets before accessing Redis.
• SetPop - pushes a data item from the Redis set and then removes this item from the in-memory set, if there is one.
• SetRandomMember - receives a random set element from Redis, then in-memory caches it and returns it.
• SetCombine, SetCombineAndStore - in-memory activation is not required.
• SetMove — Removes a data item from an in-memory set, adds it to another in-memory set, and redirects it to Redis.
Hash tables
Hash tables are also relatively simple, since their in-memory implementation is just a Dictionary <string, RedisValue>, which, in principle, is very similar to a string.
Basic operation:
1. If the hash table is not available in in-memory, you need to create a Dictionary <string, RedisValue> and save it.
2. Perform operations on the in-memory dictionary, if possible.
3. Redirect the request to Redis, if necessary.
• Cache the result.
The following operations are available for hash tables:
• HashSet — saves values in a dictionary stored in the key, and then redirects the request to Redis.
• HashValues, HashKeys, HashLength - there is no in-memory application.
• HashDecrement, HashIncrement, HashDelete - deletes the value from the dictionary and redirects to Redis.
• HashExists - returns true if the value is in the in-memory cache. Otherwise, it redirects the request to Redis.
• HashGet - requests data from the in-memory cache. Otherwise, it redirects the request to Redis.
• HashScan - get results from Redis and add them to the in-memory cache.
Ordered set
Ordered sets are undoubtedly the most complex data model in terms of creating an in-memory cache. In this case, the in-memory caching process involves the use of so-called "disjoint ordered sets." That is, each time the local cache sees a small fragment of an ordered Redis set, this fragment is added to the “disjoint” ordered set. If a subsection of an ordered set is later requested, the non-intersecting ordered set will be checked first. If it contains the entire section, it can be returned with full confidence that there are no missing components.
Ordered in-memory sets are sorted not by value, but by a special parameter score. Theoretically, it would be possible to expand the implementation of disjoint ordered sets so that it is possible to sort them by value, but at the moment this is not yet implemented.
Operations use disjoint sets as follows:
• SortedSetAdd - values are added to the in-memory set discretely, which means we do not know whether they are related in terms of score.
• SortedSetRemove - the value is deleted both from memory and from Redis.
• SortedSetRemoveRangeByRank - all in-memory sets are declared invalid.
• SortedSetCombineAndStore, SortedSetLength, SortedSetLengthByValue, SortedSetRangeByRank, SortedSetRangeByValue, SortedSetRank - the request is sent directly to Redis.
• SortedSetRangeByRankWithScores, SortedSetScan - data is requested from Redis and then discretely cached.
• SortedSetRangeByScoreWithScores is the most cached feature, as scores are returned in order. The cache is checked, and if it can process the request, it is returned. Otherwise, a request is sent to Redis, after which scores are cached in memory as a continuous data set.
• SortedSetRangeByScore - data is taken from the cache, if possible. Otherwise, they are taken from Redis and are not cached, since scores are not returned.
• SortedSetIncrement, SortedSetDecrement - in-memory data is updated, and the request is redirected to Redis.
• SortedSetScore - the value is taken from memory, if possible. Otherwise, a request is sent to Redis.
The complexity of working with ordered sets is due to two reasons: first, the characteristic difficulty of constructing in-memory implementations for existing subsets of ordered sets (that is, building discontinuous sets). And secondly, due to the number of operations available in Redis that require execution. To some extent, complexity is reduced by the ability to implement targeted caching of queries, including Score. Either way, you need serious unit testing of all components.
List
Lists are not so easy to cache in RAM. The reason is that operations with them, as a rule, imply work either with the head or with the tail of the list. And this is not as easy as it may seem at first glance, because we do not have one hundred percent opportunity to make sure that the in-memory list has the same data at the beginning and at the end as the list in Redis. Partially this difficulty could be solved with the help of key space notifications, but so far this possibility has not been realized.
Updates from other customers
Up to this point, we proceeded from the consideration that we have only one Redis database client. In fact, customers can be many. Under such conditions, it is quite possible that one client has data in the in-memory cache, and another one updates it, which makes the data of the first client invalid. There is only one way to solve this problem - to set up communication between all clients. Fortunately, Redis provides a publisher-subscriber messaging mechanism. This template has 2 types of notifications.
Key Space Notifications
These notifications are published to Redis automatically when the key changes.
Specially published notices
They are published at the notification level, implemented as part of the caching mechanism for the client. Their goal is to reinforce the key space notifications with additional information necessary to invalidate certain small parts of the cache.
Working with multiple clients is a major cause of caching problems.
Risks and problems
Lost Notifications
Redis does not guarantee delivery of key space notifications. Accordingly, notifications can be lost, and invalid data will remain in the cache. This is one of the most basic risks, but, fortunately, such situations rarely occur. However, when working with two or more clients, this danger must be taken into account.
Solution: use a reliable messaging mechanism between customers with guaranteed delivery. Unfortunately, this is not yet, so see the alternative solution.
Alternative solution: perform in-memory caching only for a short time, say, for one hour. In this case, all data that we access within an hour will load faster. And if any notification is lost, this omission will soon be filled. Call the Dispose method on the database, and then instantiate it again to clear it.
Uses one - use all
If one client uses this caching level (L1), all other clients must use it to notify each other when data changes.
No limit for in-memory data
At the moment, everything that can be cached will be sent to the cache. In such a situation, you can quickly run out of memory. In my case, this is not a problem, but just keep this in mind.
Conclusion
They say there are only 10 complex problems in programming: cache invalidation, naming and the binary system ... I am sure this project can be useful in many situations. The source code for the library is available on GitHub . Follow the project and take part in it!
Source: https://habr.com/ru/post/301222/
All Articles