Introduction to Roslyn. Use to develop static analysis tools

Roslyn is a platform that provides the developer with various powerful tools for parsing and analyzing code. But the availability of such funds is not enough, you need to understand what and why you need to use. This article is intended to answer such questions. In addition, the features of the development of static analyzers using the Roslyn API will be discussed.
Introduction
The knowledge presented in this article was obtained during the development of the PVS-Studio static code analyzer, part of which is responsible for checking C # projects and was written using the Roslyn API.
The article can be divided into 2 large logical sections:
- General information about Roslyn. An overview of the tools they provide for parsing and analyzing code. Both a general description of entities and interfaces as well as a look at them from the point of view of a static analyzer developer are given.
- Features that should be considered when developing static analyzers. How to use Roslyn to develop products of this class, what to consider when developing diagnostic rules, how to write them, an example of a diagnosis, etc.
')
If the article is divided into sections in more detail, the following parts can be distinguished:
- Roslyn. What is it and why do we need?
- Preparation for the analysis of projects and file analysis.
- The syntax tree and semantic model as 2 main components necessary for static analysis.
- Syntax Visualizer is an extension of the Visual Studio development environment, as well as our assistant in code parsing.
- Features that need to be taken into account when developing a static code analyzer.
- An example of a diagnostic rule.
Note. Additionally, I offer you a related article " Guidelines for the development of extension modules in C # for Visual Studio 2005-2012 and Atmel Studio ."
Roslyn
Roslyn is an open source platform developed by Microsoft and contains compilers and tools for parsing and analyzing code written in C # and Visual Basic programming languages.
Roslyn is used in the Microsoft Visual Studio 2015 development environment. Various innovations like code fixes are implemented just by using Roslyn.
Using the analysis tools provided by the Roslyn platform, you can make a complete code analysis by analyzing all supported language constructs.
The Visual Studio environment allows you to create, on the basis of Roslyn, both tools embedded in the IDE itself (Visual Studio extensions) and independent applications (standalone tools).
The source code for Roslyn is available in the corresponding repository on GitHub . This allows you to see what and how it works, and in case of detection of any error, inform the developers about it.
The option of creating a static analyzer and diagnostic rules considered below is not the only one. It is possible to create diagnostics based on the use of the standard class DiagnosticAnalyzer . Roslyn's built-in diagnostics use this solution. This will allow, for example, integration with the standard error list of Visual Studio, provides the ability to highlight errors in a text editor, etc. But it is worth remembering that if these diagnostics exist within the 32-bit devenv.exe process, there are serious limitations on the amount of memory used. In some cases, this is critical and will not allow an in-depth analysis of large projects (the same Roslyn). Moreover, in this case, Roslyn leaves the developer with less control over tree traversal and is independently involved in parallelizing this process.
C # PVS-Studio analyzer is a standalone application, which solves the problem with the restriction on the use of memory. In addition, we get more control over tree traversal, we implement parallelization in the way we need, thereby controlling the process of parsing and analyzing the code more. Since there is already experience in creating an analyzer that works on this principle (PVS-Studio C ++), it would be advisable to use it when writing a C # analyzer. Integration with the Visual Studio development environment is carried out in the same way as a C ++ analyzer — via a plug-in that calls this standalone application. Thus, using the existing developments, we managed to create an analyzer for a new language and connect it with the existing solutions, integrating it into a full-fledged product - PVS-Studio.
Preparing for file analysis
Before proceeding with the analysis itself, it is necessary to obtain a list of files whose source code will be checked, as well as to obtain the entities necessary for correct analysis. There are several points that need to be performed to obtain the necessary data for analysis:
- Creating workspace;
- Getting the solution (optional);
- Receiving projects;
- Analysis of the project: getting a compilation, a list of files;
- File parsing: getting the syntax tree and semantic model;

At each point is worth a little more detail.
Creating a workspace
Creating a workspace is necessary to get a solution or projects. To get a workspace, you must call the static Create method of the MSBuildWorkspace class, which returns an object of type MSBuildWorkspace .
Getting a solution
Getting a solution is important when it is necessary to analyze, for example, several projects included in a given solution, or all of them. Then, having received a solution, you can easily get a list of all the projects included in it.
To obtain a solution, the OpenSolutionAsync method of the MSBuildWorkspace object is used . As a result, we obtain a collection containing a list of projects (i.e., an IEnumerable <Project> object).
Getting projects
If there is no need to analyze all the projects, you can get a specific project that interests us using the openProjectAsync asynchronous method of the MSBuildWorkspace object. Using this method, we get an object of type Project .
Analysis of the project: getting a compilation and a list of files for analysis
After the list of projects for the analysis is received, it is possible to start their analysis. The result of the project parsing should be a list of files for analysis and compilation.
The list of files is easy to get - this is done using the Documents property of an instance of the Project class.
To compile, use the TryGetCompilation method or GetCompilationAsync method .
Getting a compilation is one of the key points, as it is used to obtain the semantic model (which will be discussed in more detail later), which is necessary for conducting a deep and complex analysis of the source code.
In order to get a correct compilation, the project must be compiled - there should be no compilation errors in it, and all dependencies should be in place.
An example of use. Getting projects
Below is the code demonstrating various options for obtaining project files using the MSBuildWorkspace class:
void GetProjects(String solutionPath, String projectPath) { MSBuildWorkspace workspace = MSBuildWorkspace.Create(); Solution currSolution = workspace.OpenSolutionAsync(solutionPath) .Result; IEnumerable<Project> projects = currSolution.Projects; Project currProject = workspace.OpenProjectAsync(projectPath) .Result; } These actions should not cause any questions, since everything that happens here has been described above.
File parsing: getting the syntax tree and semantic model
The next step is to parse the file. Now it is necessary to get 2 entities on which the full analysis is based - the syntactic tree and the semantic model. The syntax tree is built on the basis of the program source code and is used to analyze various language constructs. The semantic model provides information about objects and their types.
To get the syntax tree (an object of the SyntaxTree type), use the TryGetSyntaxTree or GetSyntaxTreeAsync method of the Document class instance.
The semantic model (an object of the SemanticModel type) is obtained from compilation using the syntactic tree obtained earlier. To do this, use the GetSemanticModel method of an instance of the Compilation class, which takes an object of the SyntaxTree type as a required parameter.
The class, which will bypass the syntax tree and carry out analysis, should be inherited from the CSharpSyntaxWalker class , which will allow redefining the traversal methods of various nodes. By calling the Visit method, which takes the root of a tree as a parameter (the GetRoot method of an object of type SyntaxTree is used to obtain it ), we thereby start a recursive traversal of the syntax tree nodes.
Below is the code that demonstrates the implementation of the steps described above:
void ProjectAnalysis(Project project) { Compilation compilation = project.GetCompilationAsync().Result; foreach (var file in project.Documents) { SyntaxTree tree = file.GetSyntaxTreeAsync().Result; SemanticModel model = compilation.GetSemanticModel(tree); Visit(tree.GetRoot()); } } Overridden Node Traversal Methods
For each language design, nodes of its type are defined. And for each node type, a method is defined that performs a crawl of nodes of this type. Thus, by adding handlers (diagnostic rules) to the bypass methods of various nodes, we can analyze only the constructions of the language that we are interested in.
An example of a redefined traversal method for nodes corresponding to an if statement :
public override void VisitIfStatement(IfStatementSyntax node) { base.VisitIfStatement(node); } Adding the appropriate rules to the method body, we will analyze all if statements that will occur in the program code.
Syntax tree
The syntax tree is the basic element necessary for code analysis. It is on it that the movement occurs during the analysis. The tree is built on the basis of the code in the file, from which it follows that each file has its own syntax tree. In addition, it is worth considering the fact that the syntax tree is immutable. No, you can change it, of course, by calling the appropriate method, but the result of its work will be a new syntax tree, and not a modified old one.
For example, for the following code:
class C { void M() { } } The syntax tree will look like this:

Here the blue are the nodes of the tree ( Syntax nodes ), and the green are the tokens .
In the syntax tree, which Roslyn builds on the basis of the program code, there are 3 elements:
- Syntax nodes;
- Syntax tokens;
- Syntax trivia.
Each of these elements of the tree should be considered in more detail, since all of them are used in one way or another during static analysis. Another thing is that some of them are used regularly, while others are an order of magnitude less frequent.
Syntax nodes
Syntax nodes (hereinafter referred to as nodes) represent syntactic constructions, such as declarations, operators, expressions, etc. The main work that takes place during the analysis of the code is on the processing of nodes. It is on them that the movement takes place, and diagnostic rules are based on the bypass of certain types of nodes.
Consider an example of a tree corresponding to the expression
a *= (b + 4); Unlike the previous figure, here are just the nodes and comments to them, which will make it easier to navigate what node of which structure corresponds.
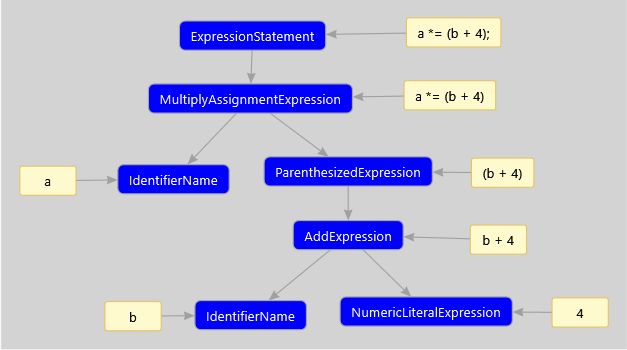
Base type
The basic node type is the abstract class SyntaxNode . This class provides the developer with methods that are common to all nodes. We list some of the most frequently used ones (if some things like what SyntaxKind or the like are incomprehensible to you now - do not worry, this will be discussed below):
- ChildNodes - gets a list of nodes that are children of the current one. Returns an object of type IEnumerable <SyntaxNode> ;
- DescendantNodes - gets a list of all nodes that are in the tree below the current one. Also returns an object of type IEnumerable <SyntaxNode> ;
- Contains - checks if the current node includes another one passed in as an argument;
- GetLeadingTrivia - allows to get syntax trivia elements preceding this node, if any;
- GetTrailingTrivia - allows you to get the elements of syntax trivia, following this node, if any;
- Kind - returns a SyntaxKind enumeration element that specifies this node;
- IsKind - takes a SyntaxKind enumeration member as a parameter, and returns a boolean value that determines whether a particular node type matches the type passed in as an argument.
In addition, the class defines a number of properties. Some of them:
- Parent - returns a link to the parent node. It is an extremely necessary property, since it allows you to move up the tree;
- HasLeadingTrivia - returns a boolean value indicating the presence or absence of syntax trivia elements preceding the given node;
- HasTrailingTrivia — Returns a boolean value, indicating the presence or absence of the syntax trivia elements following the given node.
Derived Types
But back to the types of nodes. Each node representing a particular language construct has its own type, which determines a number of properties that simplify navigation through the tree and obtaining the necessary data. These types are many. Here are some of them and what language constructions they correspond to:
- IfStatementSyntax - if statement ;
- InvocationExpressionSyntax - method call;
- BinaryExpressionSyntax - infix operation;
- ReturnStatementSyntax - expression with the operator return;
- MemberAccessExpressionSyntax - access to a member of the class;
- And many other types.
Example. Parsing the if statement
Consider an example of how to use this knowledge in practice on the example of the if operator .
Let the analyzed code have a fragment of the following form:
if (a == b) c *= d; else c /= d; In the syntax tree, this fragment will be represented by a node of the IfStatementSyntax type . Then you can easily get the information we are interested in by referring to the various properties of this class:
- Condition - returns the condition checked in the statement. The return value is a link of type ExpressionSyntax ;
- Else - returns the else branch of the if statement , if any. The return value is a reference of the ElseClauseSyntax type;
- Statement - returns the body of the if statement . The return value is a reference of type StatementSyntax.
In practice, it looks the same as in theory:
void Foo(IfStatementSyntax node) { ExpressionSyntax condition = node.Condition; // a == b StatementSyntax statement = node.Statement; // c *= d ElseClauseSyntax elseClause = node.Else; /* else c /= d; */ } Thus, knowing the type of node, it is easy to obtain other nodes that are included in its composition. A similar set of properties is also defined for other types of nodes characterizing certain constructions - method declarations, for loops , lambdas, etc.
Concretization of the node type. SyntaxKind Enumeration
Sometimes it is not enough to know the type of node. One of the cases is prefix operations. For example, we need to select the prefix increment and decrement operators. One could check the type of the node.
if (node is PrefixUnaryExpressionSyntax) But such a check will not be enough, since the operators '!', '+', '-', '~' are suitable for this condition, because they are also prefix unary operators. How to be?
The SyntaxKind transfer comes to the rescue . In this enumeration, all possible language constructions are defined, as well as its keywords, modifiers, etc. With the help of the elements of this enumeration, you can set a specific type of node. The following properties and methods are defined for specifying the node type in the SyntaxNode class:
- RawKind is an Int32 property that stores an integer value that specifies this node. In practice, the methods Kind and IsKind are more commonly used;
- Kind - a method that takes no arguments and returns an element of the SyntaxKind enumeration;
- IsKind is a method that takes a SyntaxKind enumeration member as an argument and returns true or false , depending on whether the exact node type matches the type of argument passed.
Using the Kind or IsKind methods , you can easily determine if a node is a prefix increment or decrement operation:
if (node.Kind() == SyntaxKind.PreDecrementExpression || node.IsKind(SyntaxKind.PreIncrementExpression)) Personally, I like the use of the IsKind method more , since the code looks more concise and more readable.
Syntax tokens
Syntax tokens (hereinafter - tokens) are the terminals of the grammar of the language. Tokens are elements that are not subject to further parsing - identifiers, keywords, special characters. In the course of code analysis, you have to work with them less often than with tree nodes. However, if you still have to work with lexemes, as a rule, this is limited to obtaining a textual representation of the lexeme or checking its type.
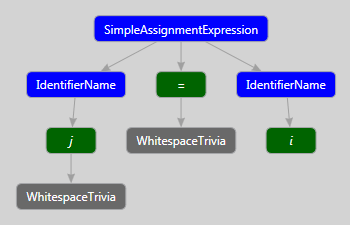
Consider the previously mentioned expression.
a *= (b + 4); The figure below shows the syntax tree derived from this expression. But here, in contrast to the previous figure, lexemes are also depicted. The link between the nodes and the tokens that are part of them is clearly visible.

Use in the analysis
All tokens are represented by the significant type of SyntaxToken. Therefore, in order to find out what exactly the lexeme is, the previously mentioned methods Kind and IsKind and the elements of the SyntaxKind enumeration are used .
If you need to get a textual representation of the lexeme, it suffices to refer to the ValueText property.
You can also get the value of a lexeme (for example, a number if the lexeme is represented by a numeric literal), for which you simply need to refer to the Value property, which returns a reference of type Object . However, to obtain constant values, the semantic model and the more convenient method GetConstantValue are usually used, which will be discussed in the appropriate section.
In addition, syntax trivia (about what it is, is written in the next section) are tied to lexemes (in fact, to them, not to nodes).
The following properties are defined for working with syntax trivia:
- HasLeadingTrivia - a boolean value corresponding to the presence or absence of syntax trivia elements in front of the lexeme;
- HasTrailingTrivia - Boolean value corresponding to the presence or absence of syntax trivia elements after the lexeme;
- LeadingTrivia - elements of the syntax trivia preceding the lexeme;
- TrailingTrivia - elements of syntax trivia following the token.
Usage example
Consider a simple if statement :
if (a == b) ; This operator will be divided into several lexemes:
- Keywords: 'if';
- Identifiers: 'a', 'b';
- Special characters: '(', ')', '==', ';'.
Example of getting token values:
a = 3; Let the literal '3' come as an analyzed node. Then get its text and numerical representation as follows:
void GetTokenValues(LiteralExpressionSyntax node) { String tokenText = node.Token.ValueText; Int32 tokenValue = (Int32)node.Token.Value; } Syntax trivia
Syntax trivia (additional syntax information) are those elements of the tree that will not be compiled into IL code. These elements include formatting elements (spaces, newline characters), comments, preprocessor directives.
Consider a simple expression of the following form:
a = b; // Comment Here you can highlight the following additional syntactic information: spaces, single-line comments, end of line character. The links between additional syntax information and tokens are clearly shown in the figure below.

Use in the analysis
Additional syntax information, as mentioned earlier, is related to lexemes. Share Leading trivia and Trailing trivia. Leading trivia is an additional syntax information preceding a lexeme, trailing trivia is additional syntax information following a lexeme.
All elements of additional syntax information are of type SyntaxTrivia . To determine what exactly the element is (space, single-line comment, multi-line comment, etc.) use the SyntaxKind enumeration and the methods Kind and IsKind already known to you.
As a rule, with static analysis, all work with additional syntactic information is reduced to determining what its elements are, and sometimes to analyzing the text of an element.
Usage example
Suppose we have the following code being analyzed:
// It's a leading trivia for 'a' token a = b; /* It's a trailing trivia for ';' token */ Here, a single-line comment will be tied to the lexeme 'a', and a multi-line comment - to the lexeme ';'.
If as a node we get the expression a = b; , it is easy to get the text of single-line and multi-line comments as follows:
void GetComments(ExpressionSyntax node) { String singleLineComment = node.GetLeadingTrivia() .SingleOrDefault(p => p.IsKind( SyntaxKind.SingleLineCommentTrivia)) .ToString(); String multiLineComment = node.GetTrailingTrivia() .SingleOrDefault(p => p.IsKind( SyntaxKind.MultiLineCommentTrivia)) .ToString(); } Short summary
Briefly summarizing the information in this section, we can single out the following points regarding the syntax tree:
- The syntax tree is the basic element required for static analysis;
- The syntax tree is unchangeable;
- By traversing the syntactic tree, we go around various language constructs, each of which has its own type;
- For each type corresponding to any syntactic construction of the language, there is a workaround method, by redefining which, you can set the processing logic of the node;
- The three main elements of the tree are syntax nodes , syntax tokens , syntax trivia ;
- Syntax nodes are syntactic constructs of a language. This category includes ads, definitions, operators, etc .;
- Syntax tokens - lexemes, the final characters of the grammar of the language. This category includes identifiers, keywords, specials. characters, etc .;
- Syntax trivia - additional syntax information. This category includes comments, preprocessor directives, spaces, etc.
Semantic model
The semantic model provides information about objects and types of objects. This is a very powerful tool that allows for in-depth and complex analysis. That is why it is important to have a correct compilation and a correct semantic model. Let me remind you that for this project must be compiled.
It should be remembered that in the analysis we work with nodes, and not with objects. Therefore, to obtain information, for example, neither the is operator nor the GetType method will work about the type of the object, since they provide information about the node, and not about the object. For example, suppose we analyze the following code:
a = 3; That such a , from this code it is possible to build only assumptions. It is not possible to say whether it is a local variable, or a property, or a field, only approximate type assumptions can be made. But guesses do not interest anyone, we need accurate information.
One could try to walk up the tree to declare a variable, but that would be too wasteful in terms of performance and amount of code. In addition, the ad can easily be somewhere in another file, or even in a third-party library, the source code of which we do not have
Here the semantic model comes to the rescue.

There are 3 most frequently used functions provided by the semantic model:
- Getting information about the object;
- Getting information about the type of object;
- Getting constant values.
Each of these points should be discussed in more detail, since they are all important and widely used in static code analysis.
Getting information about the object. Symbol
Information about the object is provided by the so-called symbols.
The basic symbol interface, ISymbol , provides methods and properties that are common to all objects, regardless of whether they are a field, a property, or something else.
There are a number of derived types, casting to which you can get more specific information about the object. These interfaces include IFieldSymbol , IPropertySymbol , IMethodSymbol, and others.
For example, using the cast to the IFieldSymbol interface and referring to the IsConst field, you can find out if the node is a constant field. And if you use the IMethodSymbol interface, you can find out if the method returns any value.
For characters, a Kind property is defined that returns the elements of the SymbolKind enumeration. According to its purpose, this listing is similar to the SyntaxKind listing. That is, using the Kind property, you can find out what we are working with now — a local object, a field, a property, an assembly, etc.
An example of use. We find out if a node is a constant field.
Suppose there is a definition of a field of the following form:
private const Int32 a = 10; And somewhere below - the following code:
var b = a; Suppose we need to find out if a is a constant field. From the above expression, you can get the necessary information about the node a , using the semantic model. The code for obtaining the necessary information is as follows:
Boolean? IsConstField(SemanticModel model, IdentifierNameSyntax identifier) { ISymbol smb = model.GetSymbolInfo(identifier).Symbol; if (smb == null) return null; return smb.Kind == SymbolKind.Field && (smb as IFieldSymbol).IsConst; } First we get the symbol for the identifier using the GetSymbolInfo method of an object of the SemanticModel type, and then immediately access the Symbol field (it contains the information we are interested in, so in this case it makes no sense to store the SymbolInfo structure returned by the GetSymbolInfo method).
After checking for null , using the Kind property specifying the character, we see that the identifier is actually a field. If this is indeed the case, we perform a cast to the derived interface IFieldSymbol , which will allow us to access the IsConst property, thereby obtaining information about the constancy of the field.
Getting information about the type of object. ITypeSymbol interface
It is often necessary to know the type of object represented by the node. , is GetType , , .
, , . , ITypeSymbol . GetTypeInfo SemanticModel . TypeInfo , 2 :
- ConvertedType – . , , Type ;
- Type – , . , null. - - , IErrorTypeSymbol .
ITypeSymbol , , . , :
- AllInterfaces – . , ;
- BaseType – ;
- Interfaces – , ;
- IsAnonymousType – , ;
- IsReferenceType – , ;
- IsValueType – , ;
- TypeKind – ( Kind ISymbol ). , – , , ..
, , . , a + b , a b . , .
, ISymbol , , .
.
, , , , :
List<String> GetInterfacesNames(SemanticModel model, IdentifierNameSyntax identifier) { ITypeSymbol nodeType = model.GetTypeInfo(identifier).Type; if (nodeType == null) return null; return nodeType.AllInterfaces .Select(p => p.Name) .ToList(); } , , , , .
. , , . , , . . , , – . , , , .
GetConstantValue , Optional<Object> , , .
.
, :
private const String str = "Some string"; - str , , :
String GetConstStrField(SemanticModel model, IdentifierNameSyntax identifier) { Optional<Object> optObj = model.GetConstantValue(identifier); if (!optObj.HasValue) return null; return optObj.Value as String; } , , :
- ( , .);
- ;
- ;
- ISymbol ;
- ITypeSymbol ;
- .
Syntax visualizer
Syntax visualizer ( – ) – Visual Studio, Roslyn SDK ( Visual Studio). , , .

, , – , – . , Kind , . ISymbol ITypeSymbol .
TDD, -, . , , , ( ) , .
, , . View Directed Syntax Graph . , .
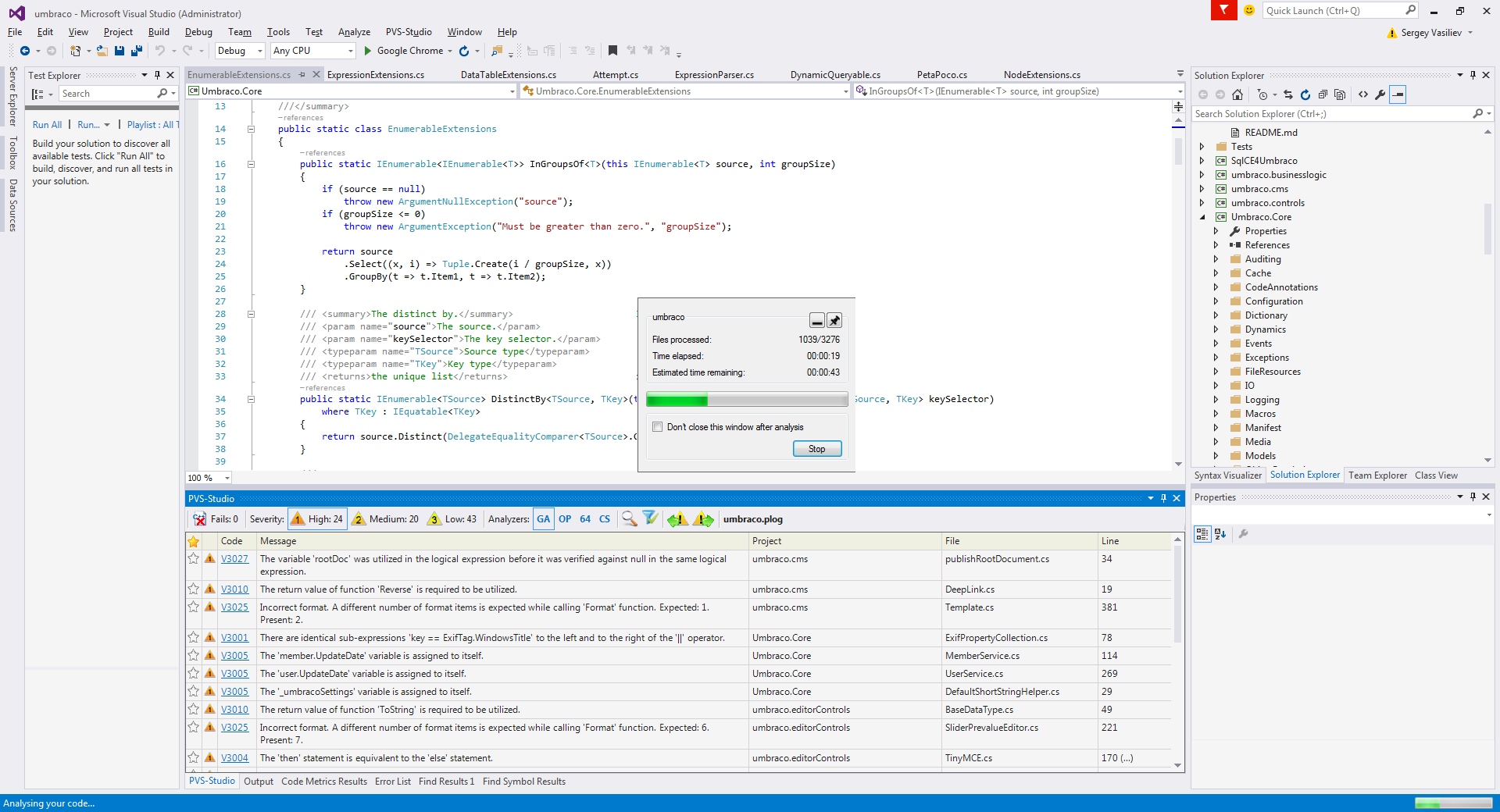
.
PVS-Studio , . , , — ILSpy — Parser.cs , - if . , . , , , , Visual Studio, «» .
. , «» if (, 3218).
,
, , . .
- , . , . , . , , . , , , ;
- . . , , . , , ;
- , , . , . , , , . , , . , – , – 0;
- , , , . -, – , , – , ;
- TDD. -, . , . ;
- . , - , . , , , -.
, , . , , .

- . , , – ;
- , , -, – . . , . . , - . , ;
- , -, . – ;
- , , - , – . ( ) , -. , , ;
- , . , , ! ;
- , . .
. throw

PVS-Studio V3006 , throw . – , ( , ..). , , , throw . , .
, -.
:
if (cond) new ArgumentOutOfRangeException(); :
if (cond) throw new FieldAccessException(); :
- ObjectCreationExpressionSyntax . new – , ;
- , System.Exception (.. , ). , , . (, );
- , ( );
- – .
. , . .
throw :
readonly String ExceptionTypeName = typeof(Exception).FullName; Boolean IsMissingThrowOperator(SemanticModelAdapter model, ObjectCreationExpressionSyntax node) { if (!IsExceptionType(model, node)) return false; if (IsReferenceUsed(model, node.Parent)) return false; return true; } , , , . , – . , .
- SemanticModelAdapter . , . , ( SemanticModel ).
, :
Boolean IsExceptionType(SemanticModelAdapter model, SyntaxNode node) { ITypeSymbol nodeType = model.GetTypeInfo(node).Type; while (nodeType != null && !(Equals(nodeType.FullName(), ExceptionTypeName))) nodeType = nodeType.BaseType; return Equals(nodeType?.FullName(), ExceptionTypeName); } – , . , – System.Exception , , – .
, :
Boolean IsReferenceUsed(SemanticModelAdapter model, SyntaxNode parentNode) { if (parentNode.IsKind(SyntaxKind.ExpressionStatement)) return false; if (parentNode is LambdaExpressionSyntax) return (model.GetSymbol(parentNode) as IMethodSymbol) ?.ReturnsVoid == false; return true; } , , : , , .. , . .
, , – , – . . – -, , .
Roslyn. Advantages and disadvantages
Roslyn – . , , , . . , .
Virtues
- . , . , , . , , ;
- . . , , ;
- . , , , ;
- . , , . , – .
disadvantages
- . Roslyn ( - , ..), - , – . , . (, MSBuild) /;
- , , . – . Equals , . .
- , Roslyn, (). 64- , . , .
PVS-Studio – , Roslyn API
PVS-Studio – , , C, C++, C#.
, C# , Roslyn API. , , – .
PVS-Studio , , Roslyn. 80 . PVS-Studio . Some of them:
- Roslyn;
- MSBuild;
- CoreFX;
- SharpDevelop;
- MonoDevelop;
- Microsoft Code Contracts;
- NHibernate;
- Space engineers;
- And many others.
, , – . – , .
: « ?». ! - , , , open source . .
Results
General
- Roslyn . , ;
- , ;
- 2 , – . , ;
- – ;
- Syntax visualizer – , .
- .
- 3- – syntax nodes, syntax tokens, syntax trivia;
- – , ;
- , , ;
- – , , , .;
- – , , .;
- IsKind SyntaxKind .
- ;
- ;
- GetSymbolInfo , ISymbol ;
- GetTypeInfo , ITypeSymbol ;
- GetConstantValue .
- , , . ;
- , ;
- ;
- -, ;
- .
Conclusion

, , Roslyn — , – , . Microsoft Roslyn, .
– , . . Roslyn API, .

If you want to share this article with an English-speaking audience, then please use the link to the translation: Sergey Vasiliev. Introduction to Roslyn and its use in program development .
Read the article and have a question?
Often our articles are asked the same questions. We collected answers to them here: Answers to questions from readers of articles about PVS-Studio, version 2015 . Please review the list.
Source: https://habr.com/ru/post/301204/
All Articles