R in Microsoft Azure to win the hackathon. Instructions for use
Standard plan of any hackathon ↓

R, one of the most popular programming languages among data scientists, is getting more and more support both among the opensource community and among private companies that have traditionally been the developers of proprietary products. Among such companies is Microsoft, whose intensively increasing support for the R language in their products / services has attracted my attention.
One of the “locomotives” of integrating R with Microsoft products is the Microsoft Azure cloud platform. In addition, there was an excellent reason to take a closer look at the R + Azure bundle - this is the hackathon of machine learning organized by Microsoft organized this weekend (May 21-22).
Hackathon is an event wherecoffee time is an extremely valuable resource. In the context of this, I previously wrote about the best practices of model learning in Azure Machine Learning. But Azure ML is not a prototyping tool; rather, it is a service for creating a product with an SLA with all the costs of development and the cost of ownership.
R is well suited for prototyping, for data mining, for quickly testing its hypotheses — that is,
all that we need at this type of competition! Below, I'll tell you how to use all the power of R in Azure - from creating a prototype to publishing a finished model in Azure Machine Learning.
')
0. Microsoft love R
We will immediately determine the list of Microsoft products / services that will allow us to work with R:
And (oh joy!) Products 1-3 are available to us in Azure on the model of IaaS / PaaS. Consider them in turn.
1. Microsoft R Server (+ for Azure HDInsight)
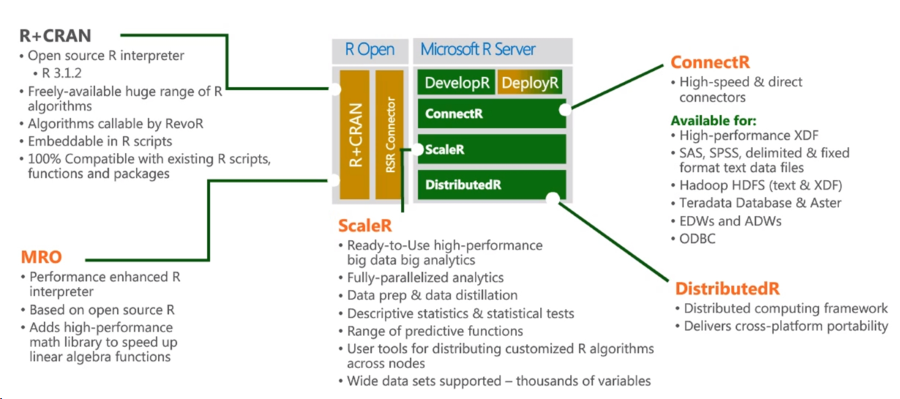
After buying the notorious Revolution Analytics, Revolution R Open (RRO) and Revolution R Enterprise (RRE) last year, they were renamed Microsoft R Open (MRO) and Microsoft R Server, respectively. Now Microsoft R Server is a well-built ecosystem consisting of both opensource products and proprietary modules Revolution Analytics.
A source
The central place is occupied by R + CRAN, guaranteed 100% compatibility with both the R language and compatibility with existing packages. Another central component of the R Server is the Microsoft R Open, which is a runtime environment with improved matrix speeds, mathematical functions, and improved multi-threading support.
The ConnectR module allows you to access data stored in the Hadoop, Teradata Database, etc.
R Server for Azure HDInsight adds to everything the ability to run R-scripts directly on the Spark cluster in the Azure cloud. Thus, the problem of the fact that the data does not fit in the RAM of the machine, locally, with respect to which, the R-script is executed, has been solved. Instructions attached .
Azure HDInsight itself is a cloud service that provides a Hadoop / Spark cluster on demand. Since this is a service, then of the administrative tasks it is worth only to deploy and delete a cluster. Everything! Not a second spent time on cluster configuration, installing updates, setting up accesses, etc.
2. Data Science VM
If you suddenly wanted: 32x CPU, 448Gb RAM, ~ 0.5 TB SSD with pre-configured and configured:
If you are going to write in R, Python, C # and use SQL. And then they decided that xgboost, Vowpal Wabbit, CNTK (Microsoft Research) open source deep learning library will not hurt you. Then the Data Science Virtual Machine is what you need - all of the above products and not only are pre-installed and ready to go. Deployment is simple, but there is an instruction for it.
3. Azure Machine Learning
Azure Machine Learning (Azure ML) is a cloud service for performing tasks related to machine learning. Almost certainly, Azure ML will be the central service that you will use, if you want to train a model, in the Azure cloud.
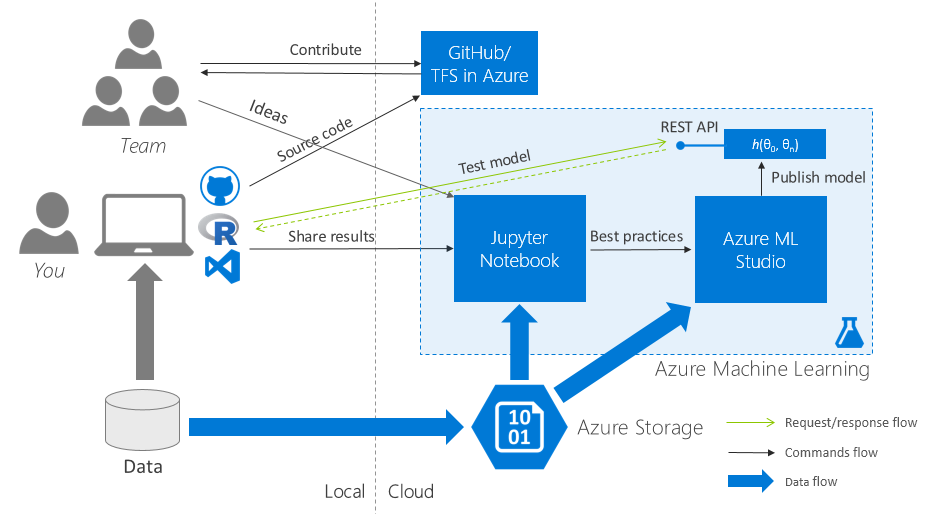
A detailed story about Azure ML is not included in the goals of this post, especially since the service is already written enough: Azure ML for Data Scientists , Best Practices for teaching a model in Azure ML . Let's concentrate on the following task: organization of team work with the most painless transfer of R-scripts from the local computer to Azure ML Studio.
3.1. Initial requirements
For this you need the following free software products:
To work in Azure, you need an active Microsoft Azure subscription.
3.2. Getting Started: collaboration everything
One workspace in Azure ML at all
Create one (!) For the whole workspace team in Azure ML and share it between all team members.
One code repository for all
We create one cloudy Team Project (TFS in Azure) / a repository in GitHub and also we share it for all team.
I think it’s obvious that now the part of the team working on the same task of the hackathon commits to one repository, commits features to brunches, brunches merges to the master - in general, there is a normal team work on the code.
One set of initial data for all
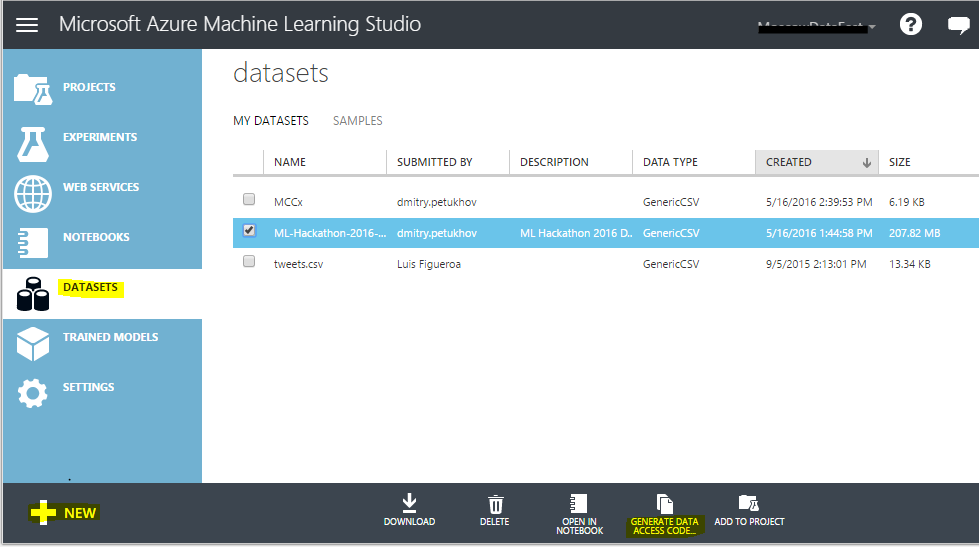
Go to Azure ML Studio (web IDE), go to the “Datasets” tab and upload the initial data set to the cloud. Generate a Data Access Code and distribute it to the team.
This is how the data loading interface in Azure ML Studio looks like:
Listing 1. R script to load data
3.3. Jupyter Notebook: running R-scripts in the cloud and visualizing the results
After the date, code, and project in Azure ML were in common for the entire team access, it's time to learn how to share the visual results of the study.
Traditionally, for this task, the data science community likes to use Jupyter Notebook - a client-server web application that allows a developer to combine within a single document: code (R, Python), the results of its execution (including graphics) and rich-text- explanations to it.
Create Jupyter Notebook documents in Azure ML:
As a result, for each task of the hackathon there should be several Jupyter Notebook documents:
This is how it looks from me:
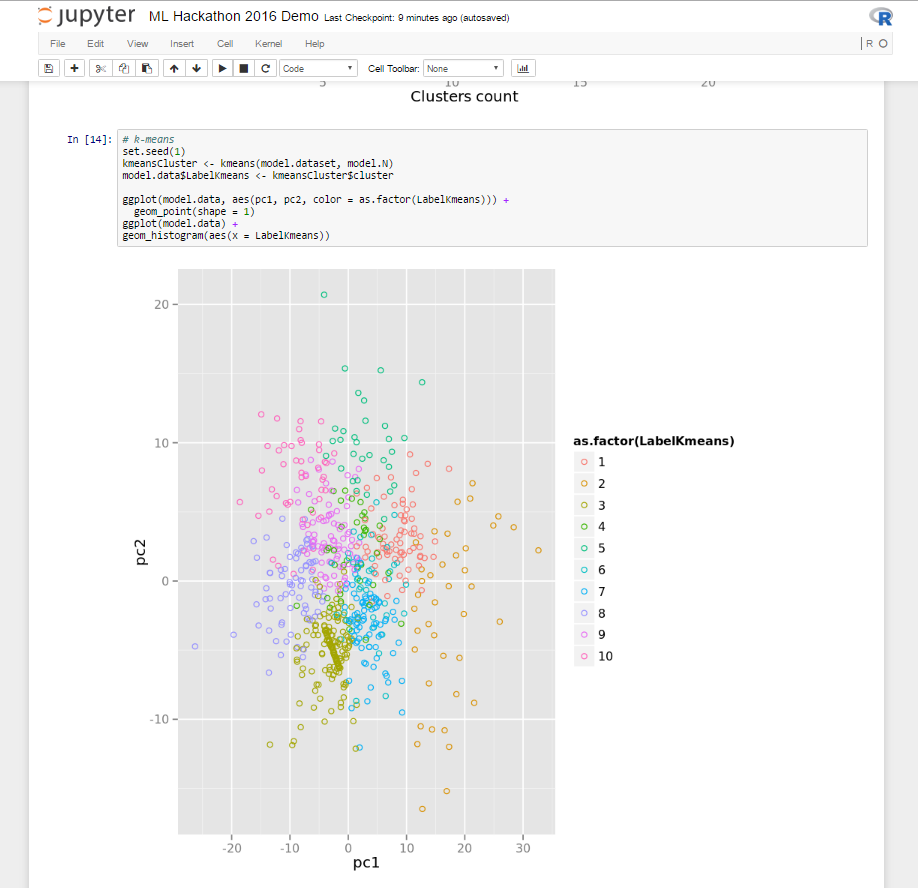
3.4. Prototype to Production
At this stage, we have several studies on which an acceptable result was obtained and corresponding to these studies:
The next step is to create experiments in Azure ML Studio (tab “Experiments”) - then AzureML experiments .
At this stage, it is necessary to adhere to the following best practices when transferring the R-code to the AzureML experiment:
Modules:
R scripts:
In accordance with the rules above, we will transfer our R-code to the AzureML experiment. For us, we need a zip-archive consisting of 2 files:
Let's load the received archive through Azure ML Studio. And we will carry out the experiment, making sure that the script has worked and we have trained the model.
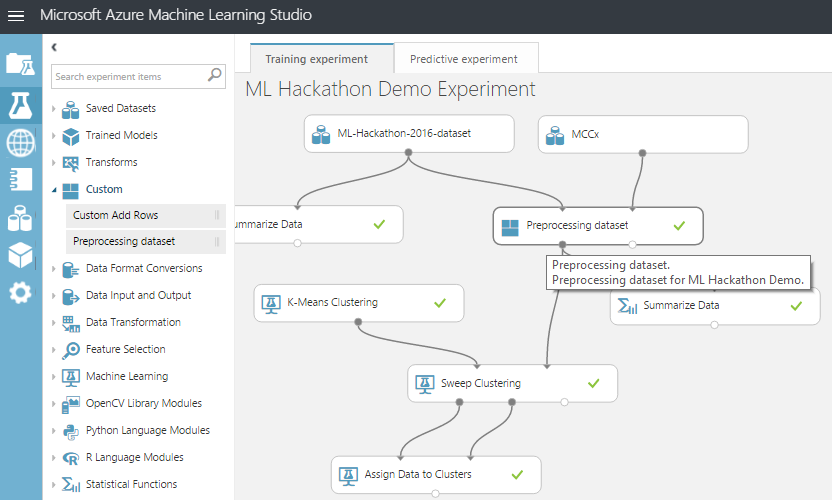
Now it is possible to improve an existing module, load a new one, arrange a competition between them - in general, enjoy the benefits of encapsulation and modular structure.
Conclusion
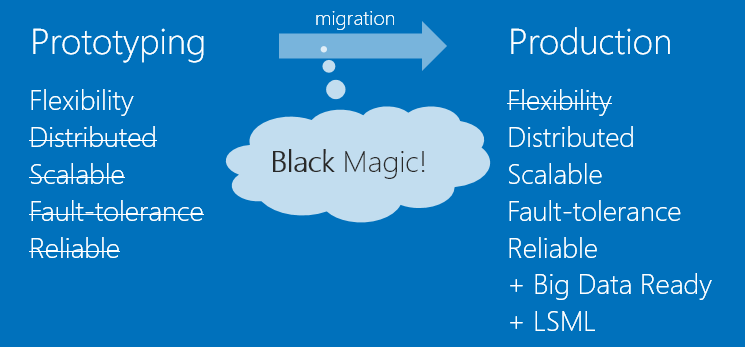
In my opinion, R is extremely effective in prototyping, and as a result, he has proven himself well on various types of data science hackathons. At the same time, between the prototype and the product there is a difficult gap in such things as scalability, accessibility, reliability.
Using the Azure toolkit for R, for a long time we can balance on the edge between R flexibility and reliability + other benefits that Azure ML gives us.
And further…
Come to the hackathon on Azure Machine Learning (I wrote about it at the beginning) and try it all yourself, talk to experts and associateskill yourself the weekend . I can also be found there (on the jury).
In addition, for those who will have little offline communication, I invite you to a warm tube slack chat , where the hackathon participants can ask questions, share their experiences with each other, and after the hackathon tell about their ML decision and continue to maintain professional contacts.
Knock me out for an invite to slack through personal messages in Habré or on any of the contacts that you find in my blog (I’ll not put the link - I’ll find it through the Habré profile).
R, one of the most popular programming languages among data scientists, is getting more and more support both among the opensource community and among private companies that have traditionally been the developers of proprietary products. Among such companies is Microsoft, whose intensively increasing support for the R language in their products / services has attracted my attention.
One of the “locomotives” of integrating R with Microsoft products is the Microsoft Azure cloud platform. In addition, there was an excellent reason to take a closer look at the R + Azure bundle - this is the hackathon of machine learning organized by Microsoft organized this weekend (May 21-22).
Hackathon is an event where
R is well suited for prototyping, for data mining, for quickly testing its hypotheses — that is,
all that we need at this type of competition! Below, I'll tell you how to use all the power of R in Azure - from creating a prototype to publishing a finished model in Azure Machine Learning.
')
Off-topic motivating
As in the past hackathon (yes, this is not the first ML hackathon from Microsoft), you will have the opportunity to program enough on your favorite Python / R / C #, twist the knobs in Azure Machine Learning, talk to like-minded people and experts, do not sleep well, get drunk free coffee and eat tasty cookies. And the most cunning ones will make the world a better place and will get well-deserved prizes!
0. Microsoft love R
We will immediately determine the list of Microsoft products / services that will allow us to work with R:
- Microsoft R Server / R Server for Azure HDInsight
- Data Science VM
- Azure Machine Learning
- SQL Server R Services
- Power BI
- R Tools for Visual Studio
And (oh joy!) Products 1-3 are available to us in Azure on the model of IaaS / PaaS. Consider them in turn.
1. Microsoft R Server (+ for Azure HDInsight)
After buying the notorious Revolution Analytics, Revolution R Open (RRO) and Revolution R Enterprise (RRE) last year, they were renamed Microsoft R Open (MRO) and Microsoft R Server, respectively. Now Microsoft R Server is a well-built ecosystem consisting of both opensource products and proprietary modules Revolution Analytics.
A source
The central place is occupied by R + CRAN, guaranteed 100% compatibility with both the R language and compatibility with existing packages. Another central component of the R Server is the Microsoft R Open, which is a runtime environment with improved matrix speeds, mathematical functions, and improved multi-threading support.
The ConnectR module allows you to access data stored in the Hadoop, Teradata Database, etc.
R Server for Azure HDInsight adds to everything the ability to run R-scripts directly on the Spark cluster in the Azure cloud. Thus, the problem of the fact that the data does not fit in the RAM of the machine, locally, with respect to which, the R-script is executed, has been solved. Instructions attached .
Azure HDInsight itself is a cloud service that provides a Hadoop / Spark cluster on demand. Since this is a service, then of the administrative tasks it is worth only to deploy and delete a cluster. Everything! Not a second spent time on cluster configuration, installing updates, setting up accesses, etc.
Creating / deleting a Hadoop cluster (HDI 3.3) from 8 nodes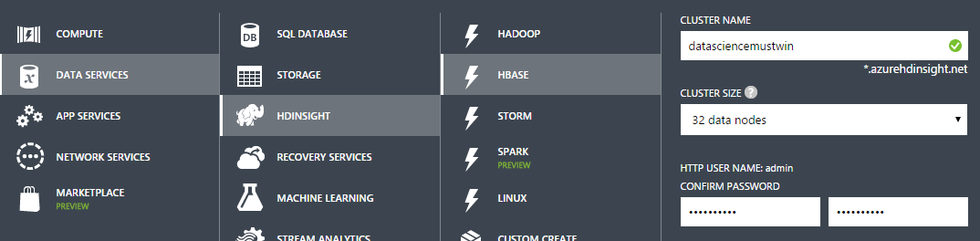
To create a Spark cluster, we have to choose either 3 buttons (image above), or run the following simple PowerShell script [ source ]:
To create a Spark cluster, we have to choose either 3 buttons (image above), or run the following simple PowerShell script [ source ]:
Login-AzureRmAccount # Set these variables $clusterName = $containerName # As a best practice, have the same name for the cluster and container $clusterNodes = 8 # The number of nodes in the HDInsight cluster $credentials = Get-Credential -Message "Enter Cluster user credentials" -UserName "admin" $sshCredentials = Get-Credential -Message "Enter SSH user credentials" # The location of the HDInsight cluster. It must be in the same data center as the Storage account. $location = Get-AzureRmStorageAccount -ResourceGroupName $resourceGroupName ` -StorageAccountName $storageAccountName | %{$_.Location} # Create a new HDInsight cluster New-AzureRmHDInsightCluster -ClusterName $clusterName ` -ResourceGroupName $resourceGroupName -HttpCredential $credentials ` -Location $location -DefaultStorageAccountName "$storageAccountName.blob.core.windows.net" ` -DefaultStorageAccountKey $storageAccountKey -DefaultStorageContainer $containerName ` -ClusterSizeInNodes $clusterNodes -ClusterType Hadoop ` -OSType Linux -Version "3.3" -SshCredential $sshCredentials To remove a cluster to choose from, either press one button and one confirmation, or execute the following line of PowerShell script:Remove-AzureRmHDInsightCluster -ClusterName <Cluster Name>
2. Data Science VM
If you suddenly wanted: 32x CPU, 448Gb RAM, ~ 0.5 TB SSD with pre-configured and configured:
- Microsoft R Server Developer Edition,
- Anaconda Python distribution,
- Jupyter Notebooks for Python and R,
- Visual Studio Community Edition with Python and R Tools,
- Power BI desktop,
- SQL Server Express edition.
If you are going to write in R, Python, C # and use SQL. And then they decided that xgboost, Vowpal Wabbit, CNTK (Microsoft Research) open source deep learning library will not hurt you. Then the Data Science Virtual Machine is what you need - all of the above products and not only are pre-installed and ready to go. Deployment is simple, but there is an instruction for it.
3. Azure Machine Learning
Azure Machine Learning (Azure ML) is a cloud service for performing tasks related to machine learning. Almost certainly, Azure ML will be the central service that you will use, if you want to train a model, in the Azure cloud.
A detailed story about Azure ML is not included in the goals of this post, especially since the service is already written enough: Azure ML for Data Scientists , Best Practices for teaching a model in Azure ML . Let's concentrate on the following task: organization of team work with the most painless transfer of R-scripts from the local computer to Azure ML Studio.
3.1. Initial requirements
For this you need the following free software products:
- For conservatives: R (runtime), R Studio (IDE).
- For Democrats: R (runtime), Microsoft R Open (runtime), Visual Studio Community 2015 (IDE), R Tools for Visual Studio (IDE extension).
To work in Azure, you need an active Microsoft Azure subscription.
3.2. Getting Started: collaboration everything
One workspace in Azure ML at all
Create one (!) For the whole workspace team in Azure ML and share it between all team members.
One code repository for all
We create one cloudy Team Project (TFS in Azure) / a repository in GitHub and also we share it for all team.
I think it’s obvious that now the part of the team working on the same task of the hackathon commits to one repository, commits features to brunches, brunches merges to the master - in general, there is a normal team work on the code.
One set of initial data for all
Go to Azure ML Studio (web IDE), go to the “Datasets” tab and upload the initial data set to the cloud. Generate a Data Access Code and distribute it to the team.
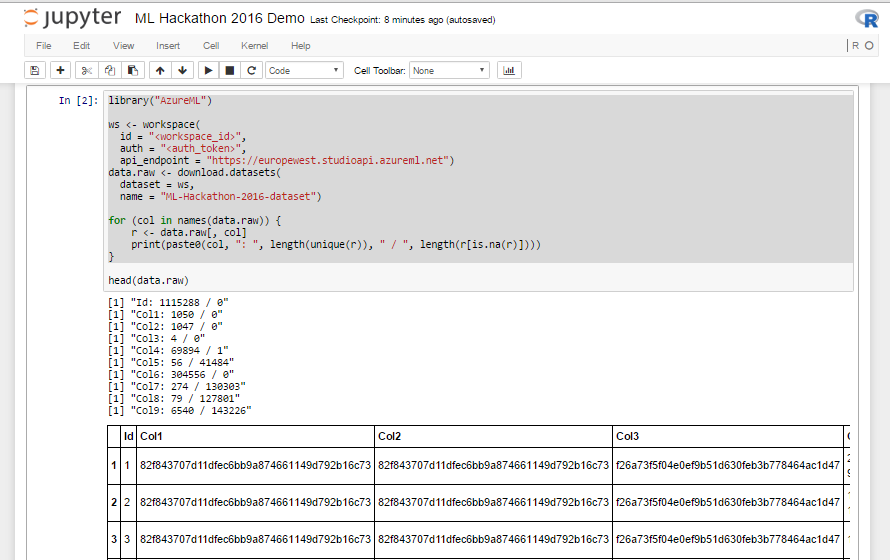
This is how the data loading interface in Azure ML Studio looks like:
Listing 1. R script to load data
library("AzureML")
ws <- workspace(
id = "<workspace_id>",
auth = "<auth_token>",
api_endpoint = "https://europewest.studioapi.azureml.net")
data.raw <- download.datasets(
dataset = ws,
name = "ML-Hackathon-2016-dataset")
3.3. Jupyter Notebook: running R-scripts in the cloud and visualizing the results
After the date, code, and project in Azure ML were in common for the entire team access, it's time to learn how to share the visual results of the study.
Traditionally, for this task, the data science community likes to use Jupyter Notebook - a client-server web application that allows a developer to combine within a single document: code (R, Python), the results of its execution (including graphics) and rich-text- explanations to it.
Create Jupyter Notebook documents in Azure ML:
- Create a separate Jupyter Notebook document per participant.
- We fill in the uniform shared initial data set from Azure ML (the code from listing 1). The code also works when started from the local R Studio, so nothing new is needed for Jupyter Notebook - just take and copy the code from R Studio.
- Share a link to a Jupyter Notebook document with the command
we throw kadiscuss, supplement directly in Jupyter Notebook.
As a result, for each task of the hackathon there should be several Jupyter Notebook documents:
- containing R-scripts and the results of their execution;
- over which the whole team has fantasized and thought;
- with full flow: from data loading to the result of the machine learning algorithm.
This is how it looks from me:
3.4. Prototype to Production
At this stage, we have several studies on which an acceptable result was obtained and corresponding to these studies:
- in GitHub / Team Project: Branch with R-scripts;
- in Jupyter Notebook: several documents with the results of what happened in the team.
The next step is to create experiments in Azure ML Studio (tab “Experiments”) - then AzureML experiments .
At this stage, it is necessary to adhere to the following best practices when transferring the R-code to the AzureML experiment:
Modules:
- If possible, do not use the built-in module “Execute R script” as a container for executing R code: it does not support versioning (changes made inside the code cannot be rolled back), the module together with the R code cannot be reused as part of another experiment.
- Use the ability to upload custom R-packages (Custom R Module) to Azure ML (about the download process below). Custom R Module have a unique name, a description of the module, the module can be reused in various AzureML experiments.
R scripts:
- Organize R-scripts inside R-modules as a set of functions with one entry point.
- Transfer to Azure ML as an R-code only the functionality that is impossible / difficult to reproduce using the built-in modules of Azure ML Studio.
- The R-code in the modules is executed with the following restrictions: there is no access to persistence storage and a network connection.
In accordance with the rules above, we will transfer our R-code to the AzureML experiment. For us, we need a zip-archive consisting of 2 files:
- A .R file containing the code that we are going to transfer to the cloud.Example of searching / filtering outliers for data
PreprocessingData <- function(dataset1, dataset2, swap = F, color = "red") {
# do something
# ...
# detecting outliners
range <- GetOutlinersRange(dataset1$TransAmount)
ds <- dataset1[dataset1$TransAmount >= range[["Lower"]] &
dataset1$TransAmount < range[["Upper"]], ]
return(ds)
}
# outlines detection for normal distributed values
GetOutlinersRange <- function(values, na.rm = F) {
# interquartile range: IQ = Q3 - Q1
Q1 = quantile(values, probs = c(0.25), na.rm = na.rm)
Q3 = quantile(values, probs = c(0.75), na.rm = na.rm)
IQ = Q3 - Q1
# outliners interval: [Q1 - 1.5IQR, Q3 + 1.5IQR]
range <- c(Q1 - 1.5*IQ, Q3 + 1.5*IQ)
names(range) <- c("Lower", "Upper")
return(range)
} - An xml file containing the definition / metadata of our R-function.Example (section Arguments is just for the “breadth” of the example)
<Module name="Preprocessing dataset">
<Owner>Dmitry Petukhov</Owner>
<Description>Preprocessing dataset for ML Hackathon Demo.</Description>
<!-- Specify the base language, script file and R function to use for this module. -->
<Language name="R" entryPoint="PreprocessingData " sourceFile="PreprocessingData.R" />
<!-- Define module input and output ports -->
<Ports>
<Input id="dataset1" name="Dataset 1" type="DataTable">
<Description>Transactions Log</Description>
</Input>
<Input id="dataset2" name="Dataset 2" type="DataTable">
<Description>MCC List</Description>
</Input>
<Output id="dataset" name="Dataset" type="DataTable">
<Description>Processed dataset</Description>
</Output>
<Output id="deviceOutput" name="View Port" type="Visualization">
<Description>View the R console graphics device output.</Description>
</Output>
</Ports>
<!-- Define module parameters -->
<Arguments>
<Arg id="swap" name="Swap" type="bool" >
<Description>Swap input datasets.</Description>
</Arg>
<Arg id="color" name="Color" type="DropDown">
<Properties default="red">
<Item id="red" name="Red Value"/>
<Item id="green" name="Green Value"/>
<Item id="blue" name="Blue Value"/>
</Properties>
<Description>Select a color.</Description>
</Arg>
</Arguments>
</Module>
Let's load the received archive through Azure ML Studio. And we will carry out the experiment, making sure that the script has worked and we have trained the model.
Now it is possible to improve an existing module, load a new one, arrange a competition between them - in general, enjoy the benefits of encapsulation and modular structure.
Conclusion
In my opinion, R is extremely effective in prototyping, and as a result, he has proven himself well on various types of data science hackathons. At the same time, between the prototype and the product there is a difficult gap in such things as scalability, accessibility, reliability.
Using the Azure toolkit for R, for a long time we can balance on the edge between R flexibility and reliability + other benefits that Azure ML gives us.
And further…
Come to the hackathon on Azure Machine Learning (I wrote about it at the beginning) and try it all yourself, talk to experts and associates
In addition, for those who will have little offline communication, I invite you to a warm tube slack chat , where the hackathon participants can ask questions, share their experiences with each other, and after the hackathon tell about their ML decision and continue to maintain professional contacts.
Knock me out for an invite to slack through personal messages in Habré or on any of the contacts that you find in my blog (I’ll not put the link - I’ll find it through the Habré profile).
Source: https://habr.com/ru/post/301176/
All Articles