The evolution of neural networks for image recognition in Google: GoogLeNet
I have a VM synchronized here for a long time, so I have time to talk about what I recently read.
For example, about GoogLeNet.
GoogLeNet is the first incarnation of the so-called Inception architecture, which is clear to everyone that:

(By the way, the link to it goes first in the list of references of the article, dude harness)
She won the ImageNet recognition challenge in 2014 with a score of 6.67% top 5 error. Let me remind you, top 5 error is a metric in which the algorithm can produce 5 variants of a picture class and an error is counted if among all these variants there is no correct one. There are a total of 150K pictures and 1000 categories in the test dataset, that is, the task is extremely nontrivial.
To understand why, how and why GoogLeNet is arranged, as usual, a bit of context.
Disclaimer: The post is written on the basis of the edited chat logs closedcircles.com , hence the style of presentation, and clarifying questions.
In 2012, an epoch-making event takes place - ImageNet challenge wins deep convolutional network
And not only wins, but shows an error almost two times less than the second place (15% vs 26% top5 error)
(to show the development of the region, the current top result is 3%)
The grid is called AlexNet by the name of Alex Krizhevsky, a Hinton student. It has only 8 levels (5 convolutional and 3 fully-connected), but in general it is thick and zyrnaya - as much as 60M parameters. Her training does not fit into a single GPU with 3GB of memory and Alex already has to come up with a trick on how to train this on two GPUs.
And now people at Google are working to make it more practical.
For example, in order to be able to use it on smaller devices and in general.
We love GoogLeNet not so much for accuracy as for efficiency in the size of the model and the required number of calculations.
Actually paper - http://arxiv.org/abs/1409.4842 .
Their main ideas are:
- The original AlexNet did large convolutions that require a lot of parameters, we will try to do smaller convolutions with a lot of handlers.
- And then we will aggressively reduce the number of measurements to compensate for thicker layers. It is clever to do this with the help of 1x1 convolutions - in fact, a linear filter used throughout the picture to take the current number of measurements, and mix them linearly into a smaller one. Since he also learns, it turns out very effectively.
- At each level, we will run several convolution kernels of different sizes in order to pull features of different scale. If the scale is too large for the current level, it is recognized at the next.
- We do not make hidden FC layers at all, because they have a lot of parameters. Instead, at the last level we do the global average pool and hook it to the output layer directly.
This is what one "inception" module looks like: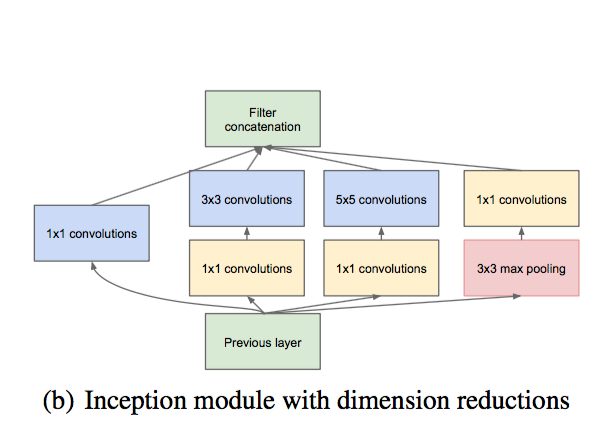
The very same kernels of different sizes are visible, 1x1 convolutions are visible to reduce the dimension.
And here the network consists of 9 such blocks. In this design, there are about 10 times fewer parameters than in AlexNet, and it is also calculated faster, because the dimensionality reduction works well.
And then it turned out that it also actually classifies pictures better - as it was written above, 6.67% top5 error.
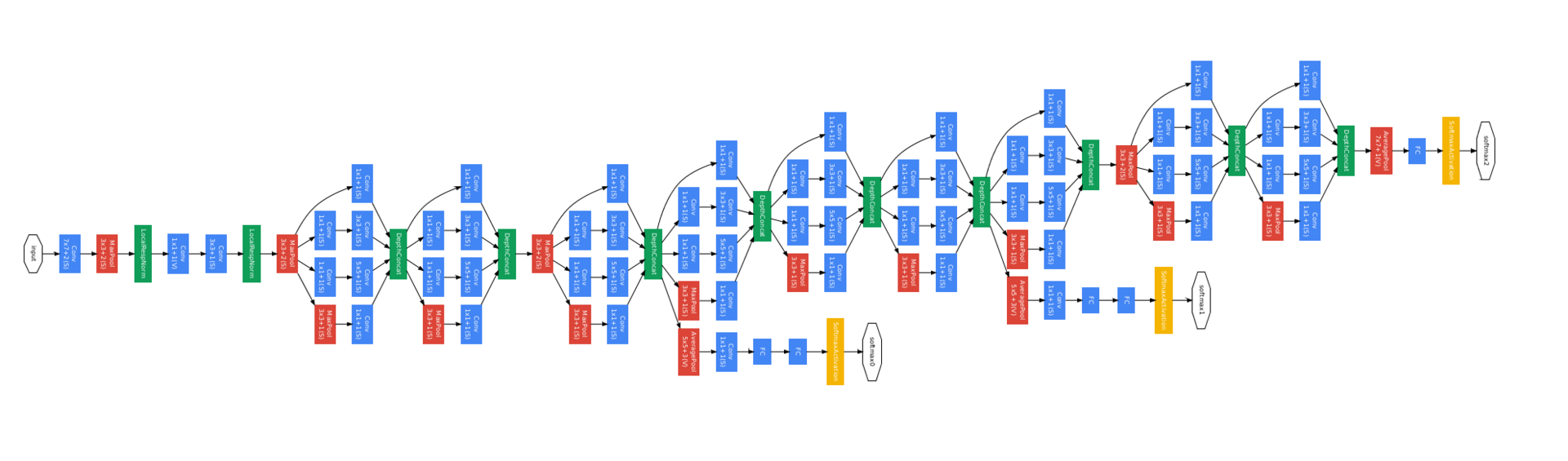
Here is a picture of the full network. It looks scary, but when you realize that these are repetitive blocks, simpler.
What other details to tell ...
She has three training heads (yellow squares) - this was done to make it easier to train such a deep network. In each additional training head there are some FC layers that predict the same class based on low levels, so that the signal reaches the lower levels more quickly (although in the following papers it turned out that they help rather because they are additional regularization).
In the release, everything leading to the auxiliary training heads is discarded. This technique is used elsewhere in the literature, but since then we have learned how to train deepnets better, which is why it is often necessary.
Such an architecture, besides GoogLeNet itself, is called Inception-v1.
Inception-BN is the same mesh, only trained using Batch Normalization (this is a good explanation on the fingers).
And Inception-v2 and further are already more complex architectures, about which I will tell next time, otherwise they can start feeding soon.
"Le" in GoogLeNet is a reference to LeNet 5, the first grid published by LeKun before deep learning was a thing.
About the compression of networks, I also recently read something. They take the net there, cut off the excess weight from it, the net is reduced by a factor of one hundred, and accuracy is almost not affected. That is, it seems, right from gigabytes to megabytes, you can shove it into the memory of a mobile phone. I feel another ten years and each camera will start to see for real.
About compression paper, by the way, if you're interested - http://arxiv.org/abs/1510.00149 .
Yeah. This game is a little different level.
You can optimize at the level of architecture and training, and you can at a low level - working already with learned weights.
Most likely, in practice, you need both.
By the way, the question of space.
Is it possible to draw a global conclusion from this?
Why does this all work? Or at least - how best to design the network with this experience?
Great questions about this will be a lot of meat in the next part of the story. Stay tuned!
')
Source: https://habr.com/ru/post/301084/
All Articles