Is Tesseract recognizes slow?

The work of each program can be accelerated at least ten times.
Smart Engines developer installation
We will talk about several methods of recognition acceleration using OCR Tesseract. Everything told was used in the implementation of the project, the meaning of which was to classify a large number of images of pages of business documents (such as a passport, contract, contract, power of attorney, registration certificate, etc.) and save the results in an electronic archive. Part of the classification algorithms was based on the analysis of the actual images of the pages, and part on the analysis of the texts extracted from the image. To extract texts, OCR was required.
A feature of any project (customized work, designed to create a software or hardware-software complex with pre-installed properties that cannot be obtained by purchasing the finished product) is the existence of time limits and resource restrictions by the contractor. In other words, in the project, the performer does not always have the opportunity to solve problems as he sees fit, and is forced to look for compromise solutions that allow to achieve the necessary functionality while respecting the deadlines and other restrictions. In our project it was necessary to quickly find a way to recognize 60,000 pages in 8 hours. For various reasons, we stopped at free text recognition software and chose OCR Tesseract. The reason for the choice was acceptable text recognition quality, which ensures the quality of the subsequent classification.
After assembling a full-featured system layout (except for full-text OCR, it had barcode recognition functions, image analysis of document pages, and page importing and exporting results), we found that the software created is quite slow even to demonstrate the system functions. For example, it turned out that the processing of a 100-page test packet of documents takes more than 1 hour, that the perfect is not suitable for display to the customer - he simply will not wait until the original 100 pages get into the electronic archive!
The speed analysis has shown that most of the time is spent on Tesseract recognition. The search for information (both on the Internet and specialists' requests) about Tesseract speed showed that many users note insufficient speed of this OCR, and recommendations for Tesseract acceleration are private and should be tested experimentally. We checked several ways to increase the speed of recognition and tell you about those that led to a significant acceleration of the entire system.
Ways to accelerate an arbitrary program can be divided into several groups, such as:
- optimization of the algorithm used;
- selection of the parameters of the algorithms used;
- optimization of compilation using modern processor technologies;
- parallelization of processing algorithms.
Let's start with the possibility of optimizing Tesseract itself. For version 3.04.00, a profiler built for building a single-threaded system using Microsoft Visual Studio 2013 with SSE2 optimization shows that 15-25% of the total Tesseract execution time is enclosed in a single function IntegerMatcher :: UpdateTablesForFeature. Theoretically, this function is a candidate for optimization of algorithms, but it is easy to see that the code of the function IntegerMatcher :: UpdateTablesForFeature has been explicitly optimized many times, at least in terms of data organization and minimizing the number of processing operations. We came to the conclusion that the possibilities of such optimization obviously require the expenditure of time, which we could not allow in our project. Therefore, we have moved to more simple ways to optimize.
We describe the main parameters of the API Tesseract. Initialization was performed in fast mode (tesseract :: OEM_TESSERACT_ONLY in the api.Init () method). The entire page area was recognized, since for some classes of documents it is not enough to analyze the page title and requires the search for words at the bottom of the page. The recognition language "rus + eng" was used, which looks natural for business documents, when printing, the words of both Russian and English were used. Pages were represented by color images, although in reality many of the pages were halftone.
Changing some of these parameters allowed us to significantly speed up recognition.
Tesseract performance evaluation was conducted on an Intel® Core (TM) i7-4790 computer CPU 3.60 GHz, 16.0 GB, Windows 7 prof 64-bit with 4 physical cores and 8 HT cores. For all the experiments described below, we used one data set consisting of 300 images of document pages of different types, different color (grayscale and color), different resolutions (from 150 to 300 dpi), different quality (pure and noisy) and with different the number of letters on the page. Tesseract performance evaluation was carried out using direct measurements of the recognition time of one page.
Recognition of all 300 pages with the original parameters took t = 4928.53 seconds, while the average recognition time of one page t cp was 16.43 seconds, the minimum recognition time of one page t min = 0.99 seconds, and the maximum t max = 143, 21 seconds. Consider time intervals of 10 seconds in the range from 0 to 150. The spread of the recognition time is illustrated by a histogram of the number of pages with the recognition time that fell into one of the intervals:

as well as a graph of the total time spent on the recognition of all pages from the corresponding interval:
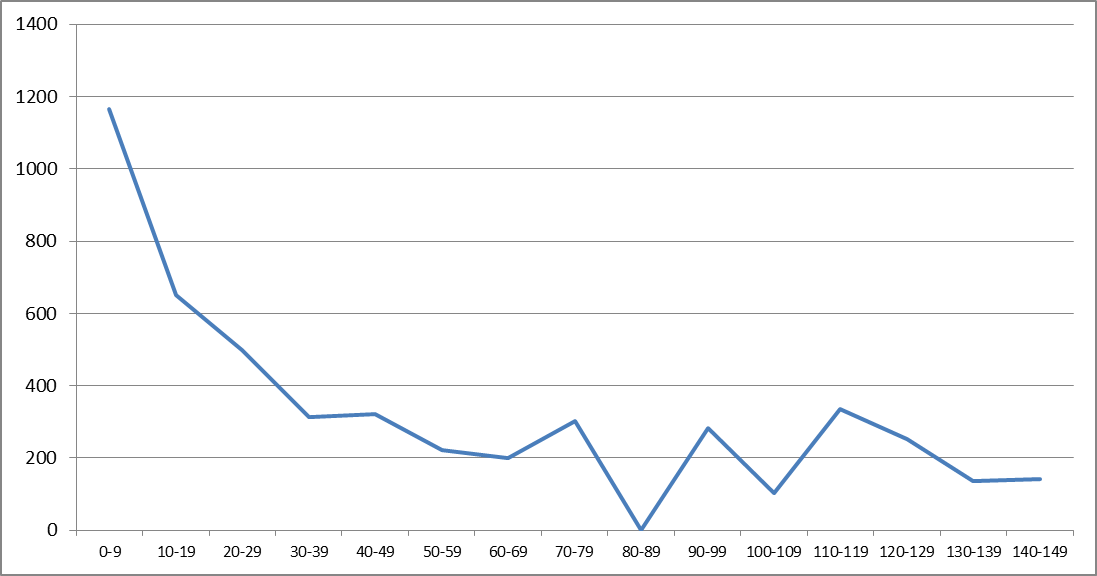
The qualitatively large scatter is due to the variety of images of the pages in the test set. In the considered set of pages most time is spent on pages with a large number of characters or objects similar to characters.
To speed up, we first of all changed the recognition language from "rus + eng" to "rus". This became possible due to changes in the algorithm of further classification, consisting in the analysis of only words printed in Cyrillic. Let's see what the gain in speed was: total time t = 3262.33 seconds, average recognition time of one page t cp = 10.87 seconds, minimum recognition time of one page t min = 0.99 seconds, maximum t max = 83.07 .
The restriction of the recognition zone in each of the pages turned out to be effective. To do this, we chose such a restriction on the training set of approximately 5000 pages, so that this area contained all possible keywords necessary for classification, and with a small margin chose a limit of 70% for page height and 90% for width. Naturally, with this restriction Tesseract began to recognize faster: the total time t = 2649.57 seconds, the average recognition time of one page t cp = 8.83 seconds, the minimum recognition time of one page t min = 0.83 seconds, the maximum t max = 77.64.
Note that both modifications of the parameters became possible only as a result of the specifics of the project, in other conditions it could not work, for example, if there were English-speaking documents in the input stream, the recognition language would have to be left "rus + eng".
However, after such a “luck” we continued to search for algorithms to speed up page processing. The procedure of binarization of images of pages before recognition turned out to be very effective. We considered the initial goal of binarization to improve the accuracy of recognition due to the removal of complex background and morphological operations. But binarization also gave a good acceleration: t = 2293.20 s, t cp = 7.64 s, t min = 0.98 s, t max = 59.83 s. These times were obtained for the case of recognition with a single language "rus", set by a frame of 0.7x0.9 and with preliminary binarization. We emphasize that the above times include the total recognition time of Tesseract and the time for binarization.
We assume that binarization is a universal technique that allows both to speed up recognition and to increase recognition accuracy.
Now we will tell about optimization by means of compilation. All previous experiments were performed using the Visual Studio 13 compiler (version 12.0.40629.00 Update 5). When compiling with Intel C ++ Compiler XE 15.0, we received good acceleration with respect to the previous version with binarization, frame and one language: t = 2156.00 s, t cp = 7.19 s, t min = 0.76 s, t max = 59.66 seconds For the compiler, an optimization option was specified for the AVX2 architecture. For the SSE4.2 architecture, the results are almost the same, although not superior to the AVX2 architecture. Here it is necessary to mention that the Intel compiler allows you to optimize performance not only for Tesseract, but also for all other components used in the system.
Additionally, you could use the timeout setting, which limits the recognition time for one page, for example, for the TessBaseAPI :: ProcessPages method. Then for a timeout value of 30,000 milliseconds, the result would be obtained: t = 2087.10, t cp = 6.96, t min = 0.76 s, t max = 30.00 s. However, we abandoned this method of optimization for two reasons for the observed losses associated with the inability to classify a page that was rejected by timeout.
For clarity, we saved the results of the experiments described in the table:
| No | Optimization method | Total time t (sec) | Average time t cp (s) | Minimum time t min (sec) | Maximum time t max (s) |
|---|---|---|---|---|---|
| one | Original version | 4928.53 | 16.43 | 0.99 | 143.21 |
| 2 | Language "rus" instead of "rus + eng" | 3262.33 | 10.87 | 0.99 | 83.07 |
| 3 | Option 2 with limiting the recognition zone | 2649.57 | 8.83 | 0.82 | 78.38 |
| four | Option 3 with preliminary binarization | 2293.20 | 7.64 | 0.98 | 59,83 |
| five | Option 4 with optimization for AVX2 compiler | 2156.00 | 7.19 | 0.76 | 59.66 |
It follows from the table that as a result of the adopted optimization methods (option 5), the total recognition time of all pages decreased by more than two times compared to the total time for the original version. At the same time, due to the chosen binarization algorithms, we improved the quality of recognition and subsequent analysis of the content of the pages. With such processing, the following number of pages will be recognized within 8 hours: 8 60 60 / 7.19 ≈ 4005.
The following figures for all the considered optimization options are histograms of the number of pages with the recognition time that fell into one of the 10-second intervals and graphs of the total time taken to recognize all pages from the same intervals:
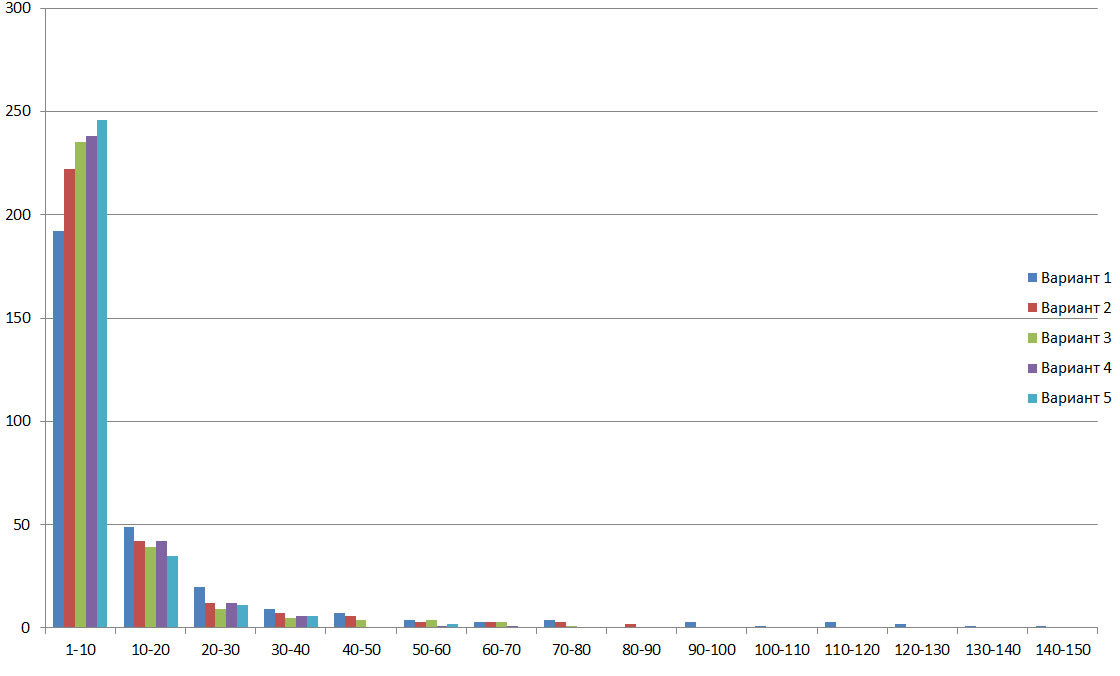
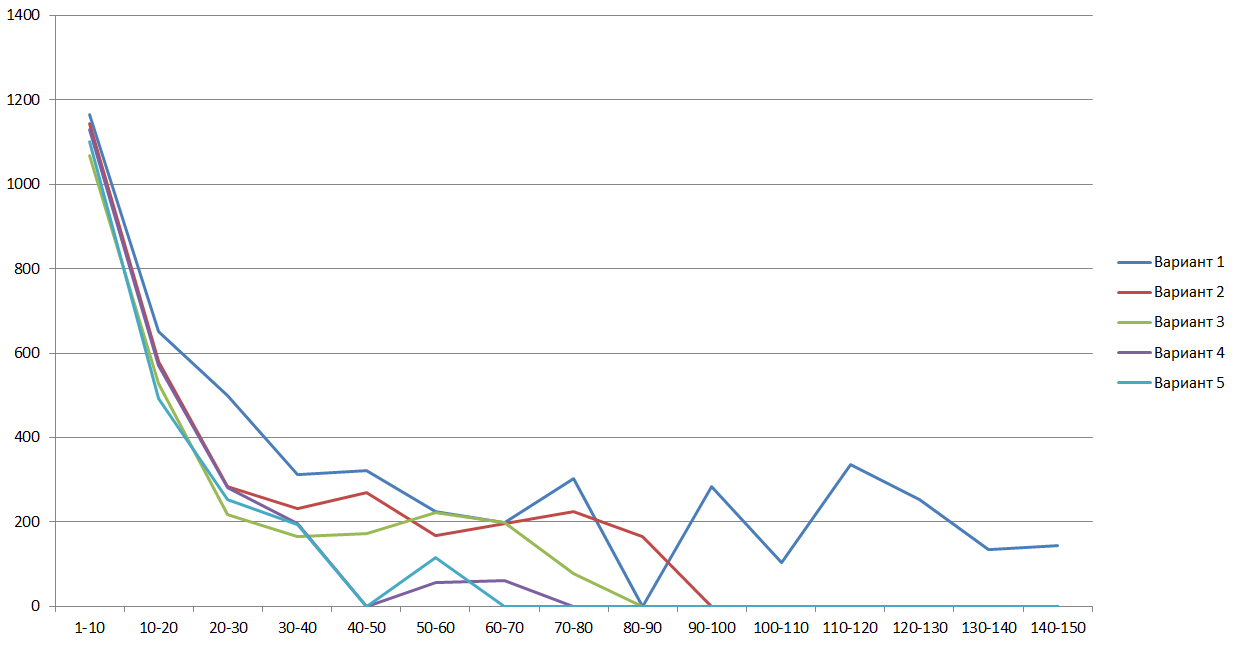
Consider the graph for options 4 and 5 of the frequency of the incident times that fall in one-second intervals. The graph shows that the optimization for the AVX2 architecture reduces page recognition time for all intervals.
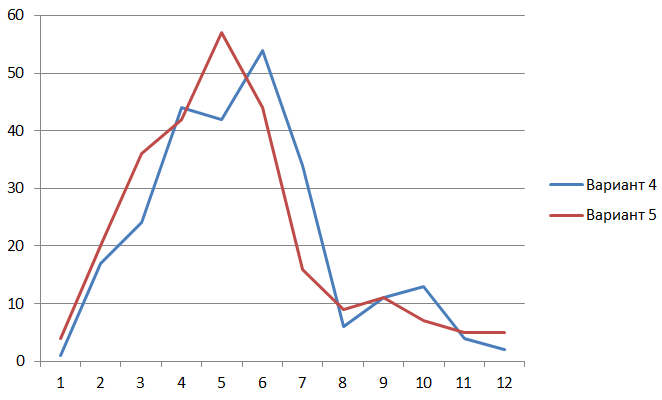
For options 4 and 5, the total Tessract operation time (previously, the table gave the total recognition and binarization time values) is 2091.86 and 1993.27 seconds, that is, optimization for the AVX2 architecture allows Tesseract itself to be accelerated by about 5%.
It is clear that the recognition of a large amount of pages can not be organized without scaling. When scaling, we used both multithreading and multiprocessing. At the same time, important attention was paid to the load balancing algorithm for the computational modules. This system was implemented independently without the use of MPI. Let's carry out processing experiments (not only Tesseract recognition, but also all other types of processing) of all 300 test pages on one site, which coincides with the previously used computer, we will estimate the time t of processing all 300 pages. The results are tabulated:
| Number of processes | The number of threads in the process | Total time t (sec) | Average time t cp (s) |
|---|---|---|---|
| one | one | 2361 | 7.87 |
| one | 2 | 1318 | 4.39 |
| one | 3 | 829 | 2.76 |
| one | four | 649 | 2.16 |
| 2 | one | 1298 | 4.33 |
| 2 | 2 | 789 | 2.63 |
| 2 | four | 485 | 1.62 |
| 2 | eight | 500 | 1.67 |
It follows from the table that the best result (1.62 seconds to process one page) is achieved when running 2 applications, each of which has 4 threads for processing pages. This time corresponds to the case when approximately the following number of pages will be recognized within 8 hours: 8 60 60 / 1.62 = 17778. In other words, we have increased the speed of page processing by about 10 times. And for processing the declared volume of 60,000 pages in 8 hours, 4 similar nodes will be required.
Of course, it can be argued that in similar projects paralleling is the most effective tool for increasing processing speed, however, the described optimization work allowed us to speed up processing by another 2 times, or, equivalently, to reduce the number of nodes by 2 times.
In conclusion, we will list experiments and studies that we would be interested in doing “in-principle” if we had enough free time and sufficient resources:
- explore whether you can manually optimize Tesseract performance by modifying IntegerMatcher :: UpdateTablesForFeature,
- test the AVX512 architecture on Xeon Phi processors,
- explore the optimization capabilities of Tesseract for the GPU.
')
Source: https://habr.com/ru/post/300990/
All Articles