Create a new OS. Really new, really operational, and the truth - the system

On the creation of a new operating system in recent years, they say a lot, especially in Russia. In sum, the size of all publications on this topic probably exceeds the size of the source code of any operating system. So there remains only one problem - no new OS appears from these conversations. Everything that is presented to the public (and what budget money is spent for) turns out to be customized builds of the Linux OS family, which means it does not contain anything fundamentally new . But, if something is not said, it does not mean that it does not exist.
This article is a project of a fundamentally new OS, created during non-working hours by one of the leading employees (Principal Engineer) of the Russian division of Intel.
General system characteristics
Properties of the proposed OS coincide with the goals of its creation. Namely:
- minimum possible consumption of system resources
- scalability in relation to processor power, memory, disk space, the number of simultaneously performed tasks, that is, applicability in powerful servers as well as in mobile devices and even such specific systems as wireless sensor networks
- unified solution for heterogeneous computer systems, including networked ones, that is, support for joint work on CPU and GPU systems of various architectures, with optimal distribution of work between them
- increased reliability and security (compared to existing systems)
- ease of developing, distributing and updating software while maximally preserving the currently existing languages and software development tools.
The basic principles underlying the operation of the OS
First, about what is supposed to be left without (significant) changes compared to existing systems, or simply to move beyond the design of the OS, leaving it to the discretion of the developers of specific implementations.
- User interface. It can be anything from the most complex variants to a simple text console, for example, in the case of a wireless sensor system.
- Memory model. Virtual and physical memory, pages ... or linear address space. The presence or absence of a swap, protection of memory areas ..
- Differentiation of access rights to user and privileged ..
- File system. It can also be any of the existing ones, or to implement modern ideas of abandoning files and presenting everything in the form of objects, or in general, like Goodwin, great and terrible, look different for different applications ...
And now that will be new.
First of all, the name;). The proposed OS does not have a well-established name yet. Although different options are discussed (you can offer your own in the comments), the working title is ROS OS .
▍ Get to know the Resource-Owner-Service (ROS) model
The basic idea of a new OS device, named by the author Resource-Owner-Service (Resource-Owner-Service) and designed to provide the above characteristics of the system, is beautiful, simple and, at first glance, familiar. But only at first glance. So:
- All the “components” of the device on which the OS is operating — both iron (CPU, data storage, etc.) and software (for example, code sections that implement a certain algorithm) —are considered as resources and are shared between the owners - programs / tasks.
- All interactions between tasks are carried out exclusively through requests and the provision of services (services).
Resembles a normal client-server model? Yes, but there is still a third principle, which is the main difference with this model -
- “Materialization” of services. Namely, the service in the ROS model is not just the functionality or interface for data exchange provided by the object, but the new communication and synchronization entity is an object.
')
We call the instances of these objects " channels ". A channel is a shared object that contains both code and data and is used to transfer data and control between tasks. Notice that there is intentionally no distinction between a provider and a service consumer (that is, a server and a client), since each task can both provide and consume a certain set of services. From the exclusivity of the channels as a means of interaction between tasks, there is one more property of the ROS model: communication synchronization. Any transfer of control between tasks, by definition, can be carried out only in conjunction with the receipt / provision of services, that is, channels become synchronization objects that uniquely determine the location and purpose of task synchronization.
The OS has no information and makes no assumptions about the purpose of each channel. So channels must provide identifiers that uniquely identify the type, purpose, or other information necessary for a particular interaction.
To ensure the execution of tasks, the system creates a special system channel for each task.
OS design includes two types of channels: dual and multi. As the name implies, for the first, the number of attached tasks cannot exceed 2, and for the latter, there are no restrictions on the number of connected tasks (they are determined solely by the amount of available memory and the specific OS implementation). Each channel has two "opposite" ends. The tasks attached to them are called channel exporters and importers, respectively. The difference between these two types of tasks is not significant - both must create an instance of the channel, that is, allocate memory and thus place the channel in their address space. The sole purpose of the division into exporters and importers is to support tasks with traditional client-server semantics, i.e. producer and consumer of services.
The figure below shows a schematic diagram of ROS OS :
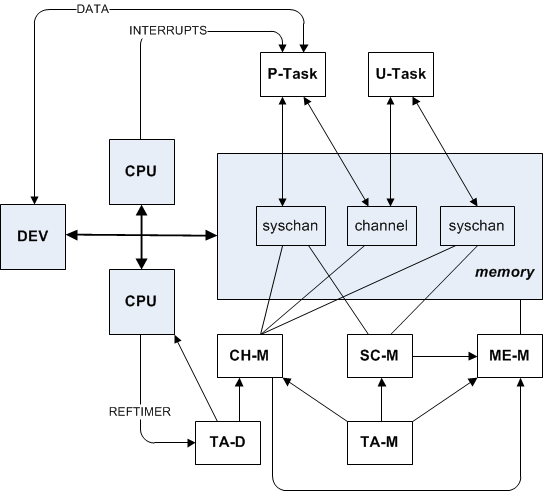
Everything is extremely simple. The gray-blue color marks the physical components of the system - processors (CPU), memory (memory). Dev (Device) is a physical storage device.
The OS kernel owns processor and memory resources. The remaining resources of the system can be owned by privileged tasks (P-tasks), which in turn provide services to user-level tasks (U-tasks) through communication channels (channel).
ROS OS implements: Memory Manager (ME-M), Channel Manager (CH-M), System Channel Manager (SC-M), Task Manager (TA-M), and Task Manager (TA-D). The kernel identifies tasks and service requests through system channels (syschan).
Task Management
▍Coordinated displacement (cooperative preemption)
Unlike Windows and Linux, which preserve the context of tasks when switching them, while consuming a significant amount of memory to allocate the stack, as well as losing performance on register save instructions, the proposed OS allows each task to inform the kernel that it is not necessary to save its context.
Instead, tasks provide an execution environment consisting of four pointers in the form {func (chan, sys, loc)} , so the kernel can clear the task stack and then, just before activating, allocate a new (or present existing) stack to the task. , then call the function func with the given parameters. At the same time, the values of the other registers that are not used in the transmission of this environment remain undefined or zeroed, which is faster than saving / restoring the correct value.
Immediately before the task is activated, the system clears the environment of 4 pointers to eliminate the erroneous premature displacement of the task.
Note that coordinated preemption (assuming that all tasks in the system follow it) means that under ideal execution conditions, only one stack will exist for each CPU core. Additional stacks will be allocated only if the task is preempted prematurely, before it initializes the context from 4 pointers.
Transmission control model for threads (Yield-To)
The OS design does not imply explicit wait functions or mutual exclusions for threads. Instead, inter-stream synchronization is achieved by explicitly passing control to other tasks, identified by a pointer to the channel and the task number in the channel. That is, control is transferred not to a specific task, but to any agent that provides the corresponding service and is indexed in its service channel. In this case, the communication agents themselves are responsible for the specific effective internal implementation of the protocol for synchronization.
The operating system can support multiple task management transfer strategies, such as “give in to any”, “give in to a given one”, and “allow execution of a given one”. The latter strategy implies that the inferior task does not intend to give control to "its" CPU, so the new task must be activated in parallel with the current one on another CPU.
▍Deterministic task planning
Each task is activated by a system timer (as in existing OSs), but, taking into account the applicability of ROS OS to real-time systems, each task must set the requirements for the task scheduler in the form of two parameters: frequency and activation duration. In addition to their primary purpose, these parameters are used to estimate the expected system load, the number of expected task conflicts and the allocation of the necessary resources (the same stacks).
Ideally, the total duration of activation of all tasks should be less than or equal to the minimum specified activation period, and the periods should be a multiple of the minimum. Fulfillment of these conditions will guarantee the absence of planning conflicts.
But in our imperfect world, some tasks can exceed their stated duration, in which case they can be ousted by other tasks ready for execution and placed on the list for future execution in the nearest available slots.
▍Performance
Since there can be several providers of the same service in the ROS model (over the network or even locally), the only criterion for choosing between different providers will be their performance in these specific conditions.
To control program performance, the system channel has active time and wait time counters that provide information on the status of the current task. Since it is usually known to which task (channel) control was transferred, performance can be estimated simply by the value of the corresponding timer upon returning to the calling task.
By comparing the performance of several channels, the task can switch to using the faster ones, which can be especially useful in the conditions of dynamic adaptation to changing conditions (extensive networks, physically unstable environments, etc.).
▍ Simplifying the code structure
Since channels are dynamic data structures that are shared between task address spaces and are subject to possible movements in memory by the OS kernel, the channel code, and of tasks in general, should be written so as not to depend on the static position of the data in memory (or position them relative to calling code) and the position of the code itself. The absence of static structures, position independence and the context of 4 pointers make it possible to do without complex program headers and defines the following simplest program structure:
Each program is represented in memory as two parts: a code and data (with an optional distinction between them to ensure access protection). The beginning of a piece of code is the starting function of the task, which accepts three pointers to the input, as described above.
▍Creation and structure of tasks
A task can be created from any code fragment. The address of the beginning of the code will be the address of the start function of the task — the same one with the prototype of four pointers — func (chan, sys, loc) , where chan and loc are optional (for example, loc may indicate local data), and sys indicates created for the task system channel. Note that the task code is copied to a new place in memory to simplify further operations with the channels - for example, if part of the code is exported as a channel.
The internal structure of the tasks is as follows:

Each task contains a descriptor describing its type (type) - user or privileged, as well as pointers to: page tables of the address space (address space), local memory (heap), stack (stack) and exception handler (exception handler).
In addition, the task descriptor includes a list of displayed channels - (task2chan), i.e. the list of pairs: “channel index-descriptor, pointer to the code of the given channel”.
In the case where tasks share a common address space, channel handles can be skipped to optimize memory usage.
The first item in the list of displayed channels is always the system channel of the task. It stores the execution context and other properties, as described later.
▍Dispatching tasks
The OS design provides two types of task activation: (a) according to the system timer according to the requested schedule and (b) explicitly transferring control from another task.
The activation schedule may be requested in the form of a period and duration of activation. These two parameters define the following task state diagram.
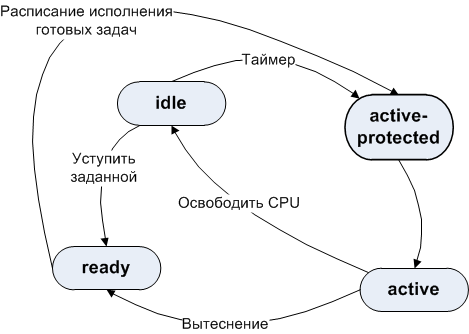
Task Status Change Graph.
Initially, when a task is activated, it enters a protected (active-protected) state, that is, it is not subject to repression. After the task exceeds the stated duration, protection against crowding is removed. In the case when there is another task in the list of ready-to-run tasks (ready list), the system can displace the first task, place its handle in the ready list and activate another task. The newly activated task resumes execution either in the active state (if it was preempted before) or in the protected state (in the case of scheduled execution or in general for all tasks, depending on the specific implementation)
An important point: setting the execution schedule based on a period allows the core of the system to guarantee real-time tasks a certain activation frequency, and not the deadline for its start. Thus, the system can shift tasks in time, if it does not violate the activation frequency. Setting the duration allows you to avoid problems associated with the priority of tasks by defining for them the previously planned (requested) activity / waiting relationship. Specific implementations of the OS can limit the duration to a maximum length of a quantum of time so that the “greedy” tasks do not take up the processor indefinitely. All of the above simplifies the scheduler's scheme and ensures its fast operation.
Planning based on the specified period and duration of activation allows the planner to identify unavoidable conflicts (see figure below) and either reject the activation request or mitigate the requirements of real-time planning.

In addition to preemptive multitasking, the system supports and cooperative. Explicit transfer of control can be accomplished using the special system yield () method. Calling this method will lead to the transfer of control to the task, identified by a pointer to the channel and the task numbers in it, and the execution of this task on a given processor. Also, as mentioned above, it is possible to transfer control not to a specific task, but to any agent that provides the corresponding service and is indexed in its service channel.
Each scheduling conflict (including dynamic, when a task is crowded out by exceeding the execution time) in general leads to the release of additional resources by the OS kernel - a new stack for the activated task. Therefore, for optimal use of system resources, each task can inform the OS kernel that it does not need to save registers and stack data. In this case, the OS when calling yield () can free the task stack and reset the contents of the registers. When activating such a task, the system will call the {func (chan, sys, loc)} prototype} on the empty stack and the undefined contents of the registers.
To ensure scheduled or preemptive activation of a task, Task Manager maintains a list of ready-to-run tasks. This is a ring buffer containing task indexes (or pointers) of tasks and a scheduled activation time, as shown in the figure below. For repressed tasks, this time will, of course, be zero.

Time can be expressed in absolute or relative units (relative to the maximum period), and updated in accordance with the requested activation periods. When a task is preempted or inferior control, its descriptor is placed in the first free slot of the ring buffer. Note that since the list is ordered by time, a task can be inserted in the list before others if the deadline for its activation comes earlier.
Tasks that are ready for execution can be selected from a sheet, starting at the end (tail) or from pointers to task lists (task list pointers) contained in the Processor Control Units described below.
The overhead of planning tasks are divided into static and dynamic. The first is the constant time of initialization of the processor context of the task (recall that this time reduces cooperative multitasking), and the second - the overhead of the task manager itself, proportional to the number of search operations in the task readiness list (both for searching the current task ready for execution and to insert a new one). At the same time, there is no need to search for a task to activate, since it will always be in the “tail” of the list.
The overhead of inserting tasks will be minimal if all tasks requested activation periods of the same duration. If the periods are different, then the search will take a logarithmic number of operations, since the readiness list includes a set of consecutive, at most, sorted data, and unsorted items can be found along a chain of links.
Channel Management
Each channel in the system is assigned a descriptor that stores information about the channel topology (type), its identifier (guid), and also pointers: to the body of the channel (body pointer) in the common address space where all the channels are located; and task handles (chan2task) that are attached to this channel. That is, the system stores the channel descriptor table shown in the figure below:
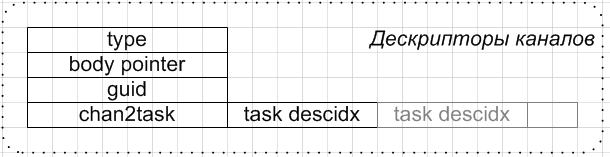
Reverse links of channels to tasks are necessary for identifying tasks by means of a pointer to the channel and an intra-channel index (for transferring control between tasks). In this scheme, the intracanal index is the position of the task descriptor (task descidx) in the corresponding chan2task sheet.
▍System calls and context management
System channels are a set of tools for identifying tasks, preserving their context, obtaining system information, generating system calls and transferring control to other tasks.
The figure below shows the structure of the system channel.

As you can see, the arguments of the system calls are not passed through the stack or registers, but are copied into the corresponding system channel structures.
The system channel contains information about the properties and capabilities of the computer platform, allowing its use without additional overhead of the system call.
A combination of the four-pointer execution environment and the execution context in one channel can be convenient for the purposes of remote debugging / monitoring.
Information about the timing of each task is updated by the OS kernel in real time. The presence of fields belonging to each processor of the system allows parallel activation of tasks (the identification of tasks occurs on the basis of the channel descriptor table).
Specific system implementations can allocate one register (readable to unprivileged tasks — for example, if there is support in hardware, a segment register) for storing a permanent pointer to the current system channel of the task. In this case, tasks do not need to save a pointer to the system channel; instead, they can refer to it through the corresponding macro.
The system channel must support the following functions, which, in fact, will be the system API:
//(1) func , ; {ok, err}; int exec(func, size, type, arg0, arg1); //(2) p , subidx; . ( ); {ok, err}; int yield(chan, subidx, strategy); int yield(); //(3) ; void exit(); //(4) . void* malloc(size, type); //(5) , -; {ok, err}; int free(pointer); //(6) ID (guid) (type) . . void* export(pointer, guid, type); //(7) ID (guid) (type) . . void* import(pointer, guid, type); //(8) ; {ok, err, channel_destroyed}; int disconnect(pointer); //(9) ; – . int self(pointer); That is, the entire system API consists of less than 10 functions !!
Processor Management
Each processor in the system is assigned a Process Control Unit, which contains some properties of the currently running task, as shown in the figure below.
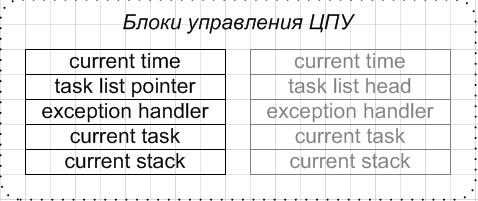
Also, some other control tables — interrupts (including interprocessor ones) and the system descriptor table — are assigned to the processor.
System complexity levels
The complexity of a particular system implementation may depend on the available memory, processor capabilities and performance of a particular platform. The following are possibilities for adjusting the complexity of the OS kernel.
Channel Management Implementation
Channels, as the basis of the design of the OS, allow significant variation. For example, OS developers can choose to support exclusively dual channels, thus eliminating the need to dynamically allocate channel member lists. In addition, the system may not support channels with code (or, at least, mixed channels for code and data), as a result, the use of traditional compilers and development environments is simplified, since the need to aggregate code and data is eliminated.
Channels can be identified by unique 128-bit identifiers or by certain indices, the validity of which can be controlled by a local (system or network scale) or global service.
Another possibility is to assign channels to names formed in hierarchical paths, similar to the system file paths of existing operating systems.
▍ Implementation of task management
Just as in modern OS, the proposed design of the operating system implies the possibility of implementing tasks both in the form of processes and in the form of threads, that is, tasks can be isolated (logically and physically, if the capabilities of the processor system allow it), and share a single address space, and therefore transfer data through shared variables.
Another possible, but very important, implementation feature is the level of privileges of tasks, that is, the availability of certain system and processor resources to tasks (for example, interprocessor interrupts, processor descriptor tables, input-output ports).
A possible solution is to support exclusively privileged tasks, which will lead to savings in efforts to implement task isolation, protect memory and processor resources.
If both privileged and unprivileged tasks are supported, the OS design provides two possibilities for implementing privileged operations.
In the first case, all privileged operations can be executed only by the kernel, that is, all privileged programs become part of the OS kernel and are executed in its context (or the context of the requesting party). Let's call this the "general scheme." The advantages of this approach are: the maintenance of privileged operations may not require switching the context of tasks (operations are performed in the context of the requesting party) in the case when the address space of the OS kernel is mapped to the address space of each task. In addition, since the system core is always parallelized by the number of processors of the system, parallel tasks requesting privileged operations will not be idle even in the absence of the possibility of executing their context. The disadvantage is that the requesting task cannot continue execution until the request is processed.
In the second case, all privileged tasks can be separated from the kernel (“split scheme”).
This solves the problem of parallel execution of requesting and querying tasks, but introduces additional context switching for each request and receipt of an interrupt (since interrupts belonging to privileged tasks can occur during the execution of any other task).
Therefore, combining common and separate schemes can be a useful solution. By default, all privileged operations can be performed on behalf of the tasks requesting them (as part of the kernel), but, as necessary, they can create other privileged tasks that are executed separately and transfer control and data to them using channels.
To implement the combined approach, an additional extension to the kernel functionality described above may be needed - a system call connecting the interrupt vector and its handler - a service function called by the system core when transferring control to a privileged channel whose owner is part of the kernel, and not a separate task.
//(10) ., {ok, err} int connect(int vector, void* handler); When calling this function, the system checks the privileges of the requester and the current index of the task. The OS kernel guarantees upon receiving each interrupt from the specified vector a context switch to a privileged task - the initiator of the request. The zero parameter handler removes the preset interrupt handler.
In this case, the channel descriptor will contain an interrupt handler function.
Examples of communication through channels
▍ Dual channels
The simplest model of task communication is dual channels. They guarantee the maintenance of only two communicating agents, although each of them can connect to more than one channel of the same ID. That is, one service provider may provide it to several clients (each in a separate channel), and one consumer receive the same service from different suppliers.
Dual channels are an effective means of transferring data in the case when agents attached to them copy their data into shared intra-channel storage and notify each other about the completion of the copying / processing operation (so that waiting agents do not waste computational resources).
Dual code channels are practically equivalent to data channels, the only difference is that they provide a shared interface that encapsulates data processing and transmission operations, which can be more convenient in some cases of object-oriented design. In this case, control transfer operations can be performed by an intra-channel code on behalf of the current task.
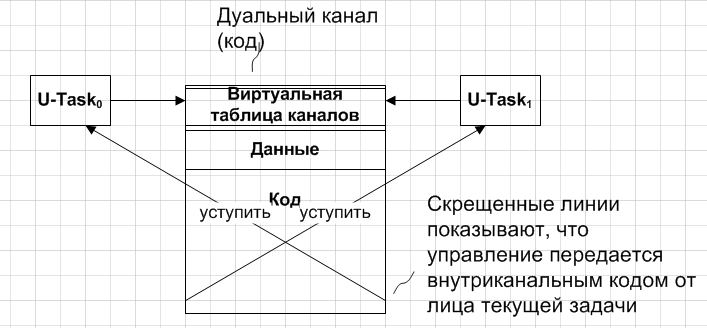
Here and in the subsequent figures, U-Task means a user task .
▍Multi Channels
Multi-channels can be used to provide a computational service — that is, to divide code between several tasks (like dynamic libraries in many traditional OSs).
At the same time, the shared code does not have to be supported by its export task.
The task can initially export the channel and end, and the intra-channel code during import will place local data in the address space of the importing task and, thus, will be both fully integrated with the importer and isolated from other importers (for cases when a specific OS implementation supports isolation address spaces).

The more complex cases of multi-channel configurations are discussed below.
Task pools
Task pools are designed to support synchronization models traditionally used in symmetric multiprocessing (SMP). Data channels to which several tasks are attached can be both a container for shared (processed in parallel) data and serve as a synchronization tool, that is, include a counter for the number of channel user tasks and, optionally, their indices in the channel.
Task pools can use the OS task scheduling capabilities and provide efficient synchronization of parallel tasks - as opposed to the most primitive schemes for polling channels for synchronization.
The channel exporter can assume the responsibilities of work distribution and, since the number of processors and tasks distributed is known, the exporter can transfer control to certain tasks on certain CPUs. When executing tasks complete data processing, they can regain control of the task distributing work.
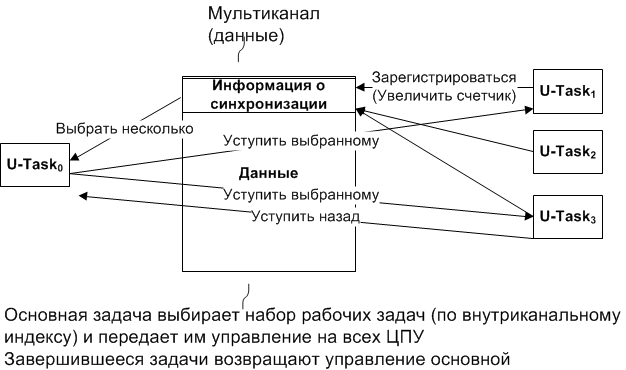
Pools of requests
Request pools can be effective in conditions where creating a separate channel for each client would require a significant amount of memory — when splitting large memory buffers and / or servicing a large number of clients.
These pools provide interfaces that can be called arbitrage. The winner of the arbitration can place a request (transfer data), while other requesters can be switched to the inactive state (in a transparent manner - using an intra channel code). When the arbitration winner’s service is completed, the winner is informed about it, copies its output, and the arbitration process resumes — the winner is selected from the rest of the arbitration participants, awakened by the yield operation, and the process is completely repeated.
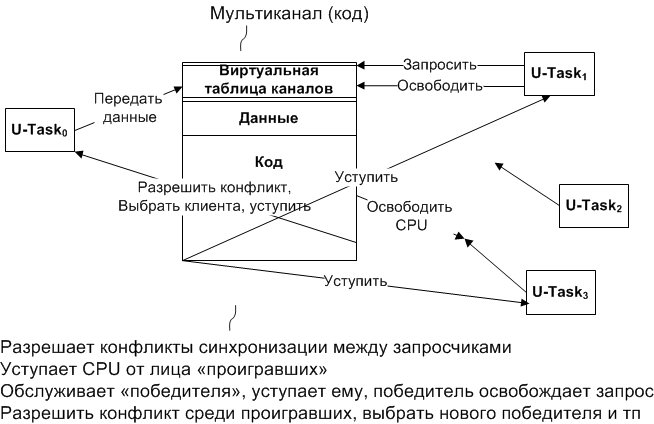
Access Markers
Access tokens allow you to implement a data sharing model (and / or getting the same service) between several tasks without setting up data transfer channels. Instead, a single service provider manages all the resources or provides services to all active agents in the system. Each agent can request from him an access token, which will be the key to the shared data. Agents can then “share” the token with other trusted agents (through a special exchange channel), with the result that trusted agents can receive the same type of service or data access.
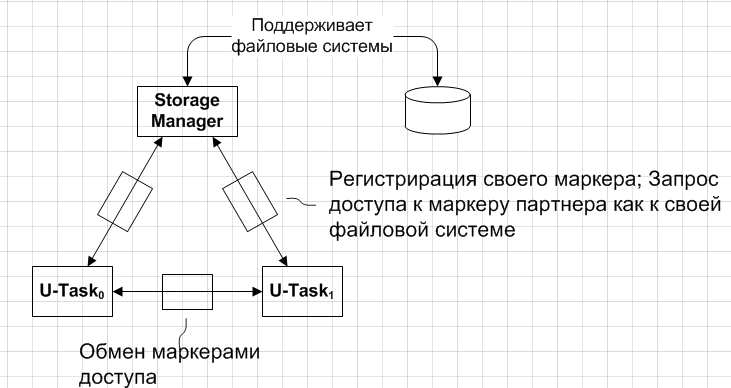
▍ Parallel access to devices
Before we talk about working with physical devices, we note that drivers in ROS OS are not special dedicated entities, but ordinary privileged tasks that provide their services through channels.
In many cases, it is necessary to provide multiple tasks with simultaneous access to data streams produced or consumed by a physical device. The figure below shows 2 typical examples of parallel communication with the device.
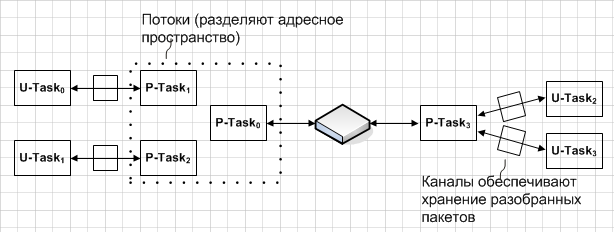
The first will be effective if the OS kernel distinguishes between processes and threads. In this case, a special task can handle all operations with the device and buffer incoming / outgoing data streams, while the actual maintenance of data consumer tasks will be performed by streams that have full access to internal buffers and, accordingly, the ability to check for data and avoid unnecessary delays. In the figure, this diagram is shown on the left.
The second embodiment can be used in the case of batch processing. In this case, the maintenance task that directly interacts with the device can allocate the necessary buffers in the channels it exports (since the packet size is known and limited — just like the size of the buffers). Both sides connected to the channels will report that the data is ready for each other, so that the serving task will be able to receive all the channels upon receipt of one request, regardless of where it came from, thus facilitating the implementation of parallelism in the system. This diagram is illustrated by the right side of the picture.
▍ Remote use of channels
In accordance with the design of the OS - the independence of working with components on their location, each agent in the local system can connect to a channel exported remotely. To support this mechanism, so-called channel replicators are introduced into the system, which, in addition to supporting the usual export / import functionality of the channels, interrogate their local systems for available channels, check for network requests for these channels, and, if present, support pairs (sets) remotely synchronized channels in the most transparent way for remote clients of these channels. An illustration of the described mechanism is below.
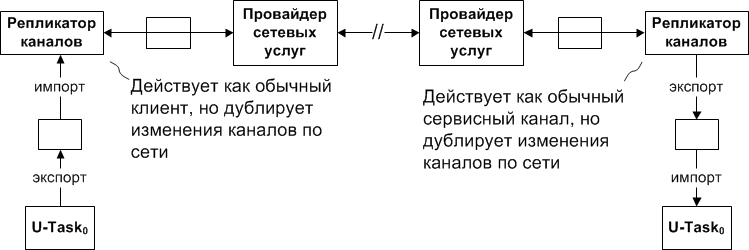
Here and in the subsequent figures, P-Task means a user task .
Note that to effectively support remote channel replicators, an additional system call is required.
//(11) ; . int query(guid[], size[], type[]); Here, guid [] is an array of channel indexes, size [] provides channel sizes, and type [] contains the types / topology of the channel request (imported, exported, or multi).
Support from programming languages
Existing programming languages will require a small extension to support the ROS model and facilitate development for the proposed OS. In the case of C ++, an extension affecting the semantics of a language is a type modifier - “channel”, indicating the type of content that should be combined into a form suitable for interprocess communication. The remaining problems associated with channel communication are solved using the functions of the ROS OS API, as shown below.
// channel class A // { int x; virtual void f(); void g(); } *a, *b, *c, *d; // syschan_t* sys; bool multi = false; // true // a = new A; // x, f, g vft b = new A; // // c = export(a, sys, multi); // A if(c != a){ delete a; a = c; } // d = import(b, sys, multi); // A if(d != b){ delete b; b = d; } // int i = self(a, sys); // disconnect(a, sys); // disconnect(b, sys); // //OS That is, you first need to declare the type of your channel (using a channel type modifier), and also allocate memory areas for the exporter and importer of the channel in a standard way. After that, the channel must obviously be connected by exporting from one side and import from the other. Special functions export () and import () are used for this, into which pointers to your channel, system channel are transmitted and the type of channel (multi or dual) is indicated.
Pointers listed after calls to these functions are shown here for environments with shared address space, where it is possible that the OS kernel will move the channel body in memory from the previously allocated space.
Each agent connected to the channel has its own channel index, obtained by the self () function, which remains unchanged until the agent disconnects from the channel (by calling disconnect ()) and joining it again (via import () and export ()) The rest of the channel-related functions in accordance with the OS design are recommended to be determined so that they take a pointer to your channel, the current system channel, as well as a pointer to the local data storage or an optional parameter.
Below is a prototype of the chanfunc function, which can be either a function launching the task with semantics (arg0, sys, arg1), or a channel initialization function (which allocates the local data storage and returns its loc pointer), or in general any utility intra-channel function
/// sys – /// chan – /// loc – void* chanfunc(chan, sys, loc); ▍ Code Generation
When writing programs for ROS OS using existing compilers designed for other OS, care must be taken. So, the developer should take care of not using static variables and work only with automatic (stack) and dynamically allocated data and / or use the capabilities of some compilers to generate code that does not depend on the download address. Ideally, a special compiler for this OS should be able to detect references to static data and generate a calculation of the corresponding address in memory relative to the address using the function data.
Another problem that cannot be solved by traditional compilers (other than assembler) is the maintenance of combined code and data channels. The specialized compiler of this OS should be able to combine the bodies of channel functions and data into a single monolithic object that can be displayed, moved and processed by the OS.
For processor architectures that support the protection of data execution, the aggregation of code and data should take place on the basis of separate pages in order not to compromise the security of the system.
findings
The basis of the proposed OS model is a service-oriented approach to parallel execution of programs that implements new principles of control transfer, task scheduling and resource management, as well as new logical topologies of program communication and synchronization that meet the needs of modern parallel and distributed computer systems, including as powerful servers, and wireless sensor networks.
At the same time, the system is thought out from the point of view of binding together the hardware and software components of a computer system, and is as simple as possible to implement.
Many of the described principles of OS design were originally embodied by its author in the last century (1999) as part of a lightweight OS that served as a predictable and fully controlled testing environment for Windows NT executable files.And, of course, since then much has been added and improved.
As you can see, it is possible to create your own OS based on the described principles. There would be a desire.If you have it, then the author of the idea , who is undoubtedly interested in its implementation, will be happy to help you - advise and support.
Source: https://habr.com/ru/post/300884/
All Articles