Dynamic must be safe
Eugene (Jim) Brickman is the author of the book “Hello, Startup” (“Hello, a startup”) and the founder of the company “Atomic Squirrel”, which specializes in helping start-ups. Prior to that, he worked for more than ten years at such companies as LinkedIn, TripAdvisor, Cisco Systems, Thomson Financial. He also holds bachelor's and master's degrees in computer science from Cornell University.
Imagine your job is to drive all the cars on the freeway faster. What would happen if you just told all the drivers to push the gas pedal all the way?
It is clear that the result would be a disaster. And yet, this is exactly the type of relationship that many developers are trying to implement, trying to create software faster. Here are a few of the reasons why they do this:
')
“We are trying to be really dynamic, so we do not waste time on the development of a structure or documentation.”
“I have to send this to production immediately, so I don’t have time to write tests!”
"We did not have time to automate anything, so we simply deploy our code manually."
For cars on the highway, driving at high speed requires special attention to safety. In order to drive a car quickly, it must have appropriate devices, for example, brakes, belts and airbags, which save the driver if something goes wrong.
For software, agility also requires security. There is a difference between reaching a reasonable compromise and striving forward blindly without thinking about caution. There should be security mechanisms that minimize losses in case of adverse events. The reckless moves, ultimately, slower, not faster:
• One hour, “saved” on not writing tests, will cost you five hours to find an error that causes a failure in production, and another five hours if your “patch” gives rise to a new error.
• Instead of spending thirty minutes writing documentation, you will teach each employee an hour how to use your program and spend hours on the proceedings if employees start to work incorrectly with your product.
• You can save a little time without worrying about automation, but it will take much more time to repeat the manual input of the code and even more time to search for errors if some stage is accidentally skipped.
What are the key security mechanisms in the software world? This article will present three safety mechanisms in the automobile world and similar mechanisms from the software world.
Good brakes stop the car before the problem becomes really serious. In software, continuous integration stops the wrong program before it goes into production. To understand the term “continuous integration”, we first consider its opposite: late integration.
Fig. 1. International Space Station
Imagine that you are responsible for building an international space station (ISS) consisting of many components, as shown in Fig. 1. Teams from different countries must make one or another component, and you decide how to organize everything. There are two options:
• Develop all components in advance, after which each team will leave and work with its component in complete isolation. When all components are ready, you launch them all together into space and try to bring them together.
• Develop an initial reference design for all components, after which each team will begin work. Each team as it develops its component continuously tests each component along with the others and changes the approach, structure, design, if any problems arise. Components for readiness go one by one into space, where they are sequentially assembled.
In option # 1, an attempt to collect the entire ISS at the end would lead to a large number of conflicts and design problems: it turns out that the German team, it turns out, thought that the French should be doing the cabling, while the latter were convinced that this was the task of the English; suddenly it turns out that all the teams used the metric measurement system, but one - the British one; no team found an important toilet installation operation for themselves. Identifying all of this, when everything is already manufactured and flying in space, means that solving problems will be very difficult and expensive.
Unfortunately, this is the way many companies use to create software. Developers operate in complete isolation for weeks or months continuously in their respective directions and then try to bring their developments together into the final product at the very last minute. This process is known as “late integration”, and it often leads to a large loss of time (days, weeks) to eliminate merge conflicts (see Figure 2), finding difficult-to-find errors and attempts to stabilize the output (release) branches of a project.
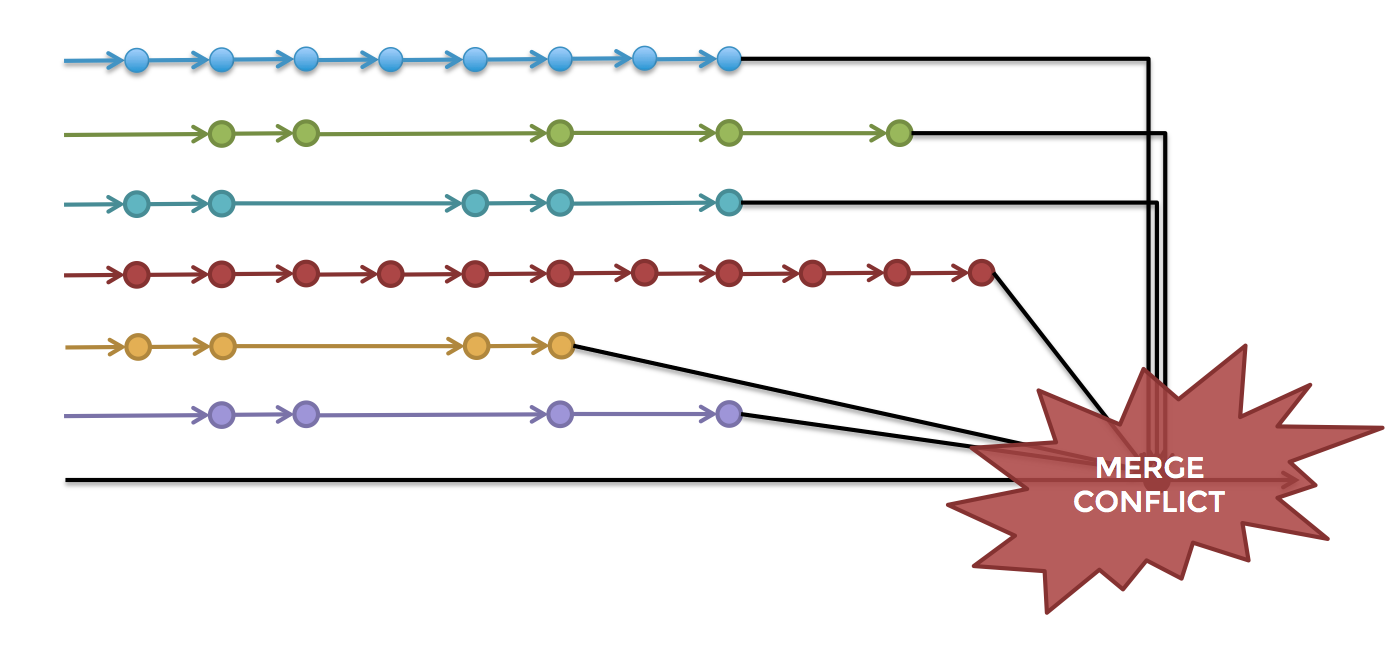
Fig. 2. Bringing together functional branches to the output (release) branch of the project leads to severe merge conflicts
An alternative approach, described as option # 2, is continuous integration, when all developers regularly bring together the results of their work. This reveals problems in the project before the developers have advanced too far in the wrong direction, and allows us to consistently increase development. The most common method of continuous integration is the use of a “stem development” model.
In this model, developers do all their work in the same branch, called the “trunk” or “master” - depending on the version control system (Version Control System = VCS). The idea is that everyone regularly loads their code into this thread, perhaps even several times a day. Can the work of all developers on a single branch really be valuable? Stem development is used by thousands of programmers on LinkedIn, Facebook and Google. Particularly impressive is the stem ("trunk") Google statistics: every day on a single branch, they coordinate more than 2 billion lines of code and more than 45 thousand confirmation operations.

Fig. 3. In stem development, each one loads its code in the same branch.
How can thousands of developers often upload their codes to the same branch without conflicts? It turns out that if you frequently perform small confirmation operations instead of performing huge monolithic mergers, the number of conflicts is quite small, and the conflicts that arise are desirable. This is due to the fact that conflicts will inevitably exist regardless of the integration strategy used, but it is easier to resolve a conflict representing one to two days of work (with continuous integration) than a conflict representing months of work (with late integration).
And what about the stability of the branch? If all developers work in the same branch and a developer loads code that does not compile or causes serious errors, the whole process can be blocked. To prevent this, it is necessary to have a self-testing layout. The self-testing layout is a fully automated process (i.e., it can be run with a single command) containing a sufficient number of automated tests; if they all pass, then you can be sure of the stability of the code. The usual approach is to add a confirmation interceptor to your version control system (VCS), which accepts each such operation, runs it through a build on some kind of continuous integration server (CI), such as, for example, Jenkins or Travis, and rejects if the layout fails. The CI server is the controller, checking each batch of code before allowing it to load into the trunk; it acts as a good brake, stopping a bad code before it goes into production.
Without continuous integration, your software is considered inoperative until someone shows that it works — this usually happens during the testing or integration phase. With continuous integration, it is believed that your software is working (if, of course, there is a fairly comprehensive set of automated tests) with each new change - and the developer knows the moment when the violation occurs, being able to fix the error immediately.
- Jez Humbley and David Farley, authors of the book “Continuous Delivery” (“Continuous Software Delivery”)
How can you use continuous integration to make big changes? That is, if you are working on a characteristic that takes a week, how can you load into the trunk several times a day? One solution is to use feature toggles.
At the beginning of the 19th century, most people avoided elevators, fearing that if the cable breaks, elevator passengers will die. To solve the problem, Elisha Otis invented a “safe lift” and carried out a bold demonstration of its effectiveness. To do this, Otis built a large open elevator shaft, lifted an open elevator up to several floors, and in front of the crowd ordered the assistant to cut the cable, as shown in fig. 4. The elevator began to fall, but was immediately stopped.

Fig. 4. Elisha Otis demonstrates "safe lift".
How it works? The key element of the safe lift is the safety latch shown in fig. 5. In the initial position, the safety latches are fully extended so that they fit into the latches on the elevator shaft and do not allow the elevator to move. Only when the elevator cable is tight enough will the safety latches come out of the engagement. In other words, the latches are in the retracted state only when the cable is intact.
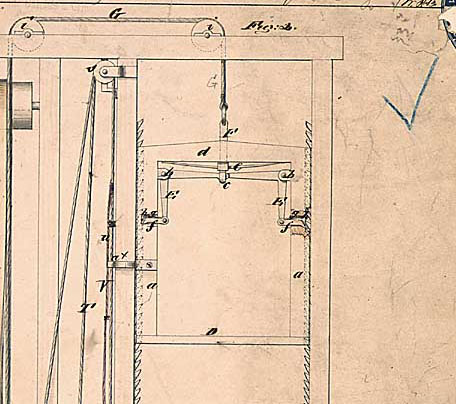
Fig. 5. A drawing of a patent in a safe elevator shows an elevator shaft with an elevator in the middle (D), with safety latches on the sides (f) and a cable at the top (G).
In this gorgeous design, safety latches provide security by default. In software, the same function is performed by the switch characteristics. The way to use the characteristics switches is to enclose all of the new code in the “if” statement that looks for the named characteristic switch (for example, showFeatureXYZ) in the configuration file or database.
if (featureToggleEnabled (“showFeatureXYZ”)) {showFeatureXYZ ()}
The key idea is that, by default, all the on / off switches of the characteristics are in the “off” position. Those. The default position is safe. This means that while the characteristic switch shell is in effect, it is possible to load and even unfold incomplete or erroneous codes, since the “if” operator ensures that the code will not be executed or will not have any visible effect.
After completing the work on the characteristic, the specified characteristic switch can be turned to the “on” position. The easiest way is to save the named characteristics switches and their values in configuration files. Thus, it is possible to allow this characteristic in the configuration of the development environment, but prohibit it from use until it is completed.
A more powerful option is to have a dynamic system in which you can set the value of the characteristic switch for each user, and the presence of a user web interface in which your employees can dynamically change the values of the characteristic switches to allow or deny certain characteristics for certain users, like shown in fig. 6
For example, during development, you can initially allow some characteristic only for your company's employees. When the feature is complete, you can enable it for 1% of all users. If everything is normal, then you can give permission for 10% of users, then for 50%, etc. If a problem occurs at some point, the web user interface allows you to turn off the feature in question. Switches characteristics can be used even for comparative testing.
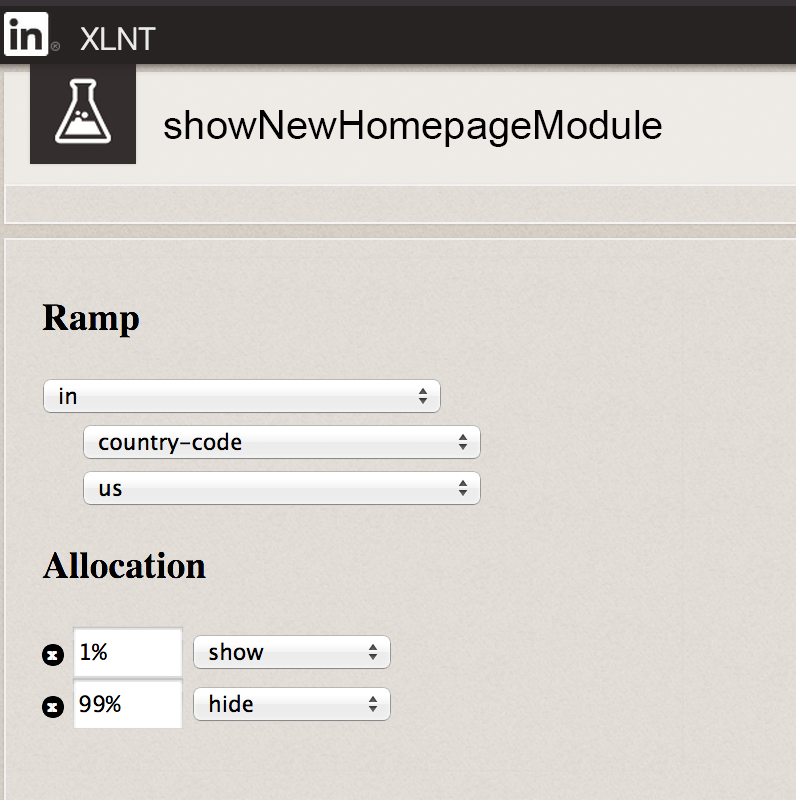
Fig. 6. Use the XLNT performance shutdown tool on LinkedIn to enable some feature for 1% of US users.
On ships, use bulkheads to create insulated watertight compartments. Due to this, the destruction of the hull causes the flooding of only one single compartment.
Similarly, in the software, you can divide the base of the source code into isolated components, so that the problem, if it occurs, will act only within this component.
The separation of the source code base is important because the worst property for the source code base is oversize. The larger the size of the program, the slower its development. For example, consider the tablet from Steve McConnell's “Perfect Code” (Steve McConnell “Code Complete”, 2004), showing the relationship of project size (in lines of code) to the error density (the number of errors per thousand lines of code):

Here you can see that as the code base increases, the error density increases. If the base of the source code is increased by 2 times, then the number of errors increases by 4-8 times. And when you have to work with more than half a million code lines, the error density can reach one error for every 10 lines!
The reason for this is - if you use a quote from the book of Venkat Subramaniam, Andy Hunt "Sketches on the subject of rapid software development. Work in the real world. "- that" software development does not occur on any scheme, not in any integrated development environment or in some design tool; it happens in your head. ” The base of the source code, containing hundreds of thousands of code strings, far exceeds what a person can hold in his head. It is impossible to consider all the interactions and dead ends in such a huge program. Therefore, a strategy is needed to separate the program so that it is possible at this point in time to focus on one part of it and safely set aside everything else.
There are two main strategies for the separation of the code base: one is the introduction of dependencies on artificial features, and the other is the introduction of microservice architecture.
The idea of dependencies on artificial features is to change your modules so that instead of depending on the source code of other modules (dependence on source), they obey to versioned artificial features issued by other modules (dependence on artificial features). You may already be doing this with libraries of open source. To use jQuery in your JavaScript program or Apache Kafka in your Java code, you do not rely on the source code of the respective open source libraries, but on the versioned artificial feature that these libraries provide, for example, jquery-1.11-min.js or kafka -clients-0.8.1.jar. If you use a fixed version of each module, the changes made by the developers on such modules will not affect you until you explicitly select the update. This approach - like bulkheads on a ship - isolates you from problems in other components.
The idea of microservices is to move from a single monolithic application, in which all your modules work in the same process and communicate through functional calls, to isolated services, where each module works in a separate process — usually on a separate server — and where the modules communicate through messages. Service boundaries act as software ownership boundaries, so microservices can be a great way to let teams work independently of each other. Microservices also make it possible to use many different technologies to create your products (for example, one microservice can be built in Python, another in Java, and the third in Ruby) and an independent assessment of each service.
Although dependencies on artificial features and microservices have many advantages, they also contain quite a few significant drawbacks, not the least of which for both methods is functioning contrary to the ideas of continuous integration described earlier. For a full discussion of the tradeoffs, see the article " Splitting Up a Codebase into Microservices and Artifacts " ("Dividing the source code base in microservice approaches and artificial features").
The safety mechanisms allow you to move faster, but you have to pay for everything: they require a preliminary investment of time when development, in fact, slows down. How to decide how much time it makes sense to spend on the security mechanism for the current product? To make a decision, you need to put three questions in front of you:
• What is the price of the problem being addressed by the mechanism in question?
• What is the price of the security mechanism itself?
• How likely are such problems to occur?
To finish this article, let's consider how the above three questions work for a common solution: do or not automated testing.
Although some die-hard testing enthusiasts argue that you should write tests for everything and strive for 100% coverage of the code, it is extremely rare to see anything close to this in the real world. When I wrote my book Hello, Startup, I interviewed developers from some of the most successful startups of the last decade, including Google, Facebook, LinkedIn, Twitter, Instagram, Stripe and GitHub. It turned out that all of them were making thoroughly thought out compromises on what to check and what not to check, especially in their early years.
Consider these three questions.
Preparation of unit tests is currently inexpensive. There are high-quality testing platforms for almost all programming languages; Most building systems have built-in support for unit testing and, as a rule, work quickly. On the other hand, integration tests (especially user interface tests) require the use of large parts of your system, which means they are more expensive to configure, slower and harder to maintain.
Of course, integration tests can catch a lot of mistakes that unit tests will miss. But since their setup and implementation are quite expensive, it turned out that most start-ups direct the main assets into a large complex of unit tests, investing only a little in a small set of extremely valuable and critical integration tests.
If you make a prototype, which you will most likely throw away in a week, then the cost of errors is low, so investing in tests probably will not pay off. On the other hand, if you create a payment processing system, the cost of errors is very high: you, of course, do not want to debit the client’s credit card twice or operate with the wrong amount.
Although the start-up companies in which I communicated with the developers differed in their testing practice, almost everybody identified several parts of their codes for themselves - usually payments, security and data storage - the violation of which is simply unacceptable and therefore a serious check literally from day one.
As was shown above, as the code base grows, the error density increases. The same is true for increasing team size and project complexity.
For a team of two programmers, with a code of 10,000 lines, it will be enough to spend only 10% of their time writing tests; with twenty programmers and a code of 100,000 lines, it will take 20% of their time, and for a team of two hundred code developers from 1 million lines it will take 50%!
As the size of the program and the number of developers grow, it is necessary to spend relatively more time on testing.
Imagine your job is to drive all the cars on the freeway faster. What would happen if you just told all the drivers to push the gas pedal all the way?
It is clear that the result would be a disaster. And yet, this is exactly the type of relationship that many developers are trying to implement, trying to create software faster. Here are a few of the reasons why they do this:
')
“We are trying to be really dynamic, so we do not waste time on the development of a structure or documentation.”
“I have to send this to production immediately, so I don’t have time to write tests!”
"We did not have time to automate anything, so we simply deploy our code manually."
For cars on the highway, driving at high speed requires special attention to safety. In order to drive a car quickly, it must have appropriate devices, for example, brakes, belts and airbags, which save the driver if something goes wrong.
For software, agility also requires security. There is a difference between reaching a reasonable compromise and striving forward blindly without thinking about caution. There should be security mechanisms that minimize losses in case of adverse events. The reckless moves, ultimately, slower, not faster:
• One hour, “saved” on not writing tests, will cost you five hours to find an error that causes a failure in production, and another five hours if your “patch” gives rise to a new error.
• Instead of spending thirty minutes writing documentation, you will teach each employee an hour how to use your program and spend hours on the proceedings if employees start to work incorrectly with your product.
• You can save a little time without worrying about automation, but it will take much more time to repeat the manual input of the code and even more time to search for errors if some stage is accidentally skipped.
What are the key security mechanisms in the software world? This article will present three safety mechanisms in the automobile world and similar mechanisms from the software world.
Brakes / Continuous Integration
Good brakes stop the car before the problem becomes really serious. In software, continuous integration stops the wrong program before it goes into production. To understand the term “continuous integration”, we first consider its opposite: late integration.
Fig. 1. International Space Station
Imagine that you are responsible for building an international space station (ISS) consisting of many components, as shown in Fig. 1. Teams from different countries must make one or another component, and you decide how to organize everything. There are two options:
• Develop all components in advance, after which each team will leave and work with its component in complete isolation. When all components are ready, you launch them all together into space and try to bring them together.
• Develop an initial reference design for all components, after which each team will begin work. Each team as it develops its component continuously tests each component along with the others and changes the approach, structure, design, if any problems arise. Components for readiness go one by one into space, where they are sequentially assembled.
In option # 1, an attempt to collect the entire ISS at the end would lead to a large number of conflicts and design problems: it turns out that the German team, it turns out, thought that the French should be doing the cabling, while the latter were convinced that this was the task of the English; suddenly it turns out that all the teams used the metric measurement system, but one - the British one; no team found an important toilet installation operation for themselves. Identifying all of this, when everything is already manufactured and flying in space, means that solving problems will be very difficult and expensive.
Unfortunately, this is the way many companies use to create software. Developers operate in complete isolation for weeks or months continuously in their respective directions and then try to bring their developments together into the final product at the very last minute. This process is known as “late integration”, and it often leads to a large loss of time (days, weeks) to eliminate merge conflicts (see Figure 2), finding difficult-to-find errors and attempts to stabilize the output (release) branches of a project.
Fig. 2. Bringing together functional branches to the output (release) branch of the project leads to severe merge conflicts
An alternative approach, described as option # 2, is continuous integration, when all developers regularly bring together the results of their work. This reveals problems in the project before the developers have advanced too far in the wrong direction, and allows us to consistently increase development. The most common method of continuous integration is the use of a “stem development” model.
In this model, developers do all their work in the same branch, called the “trunk” or “master” - depending on the version control system (Version Control System = VCS). The idea is that everyone regularly loads their code into this thread, perhaps even several times a day. Can the work of all developers on a single branch really be valuable? Stem development is used by thousands of programmers on LinkedIn, Facebook and Google. Particularly impressive is the stem ("trunk") Google statistics: every day on a single branch, they coordinate more than 2 billion lines of code and more than 45 thousand confirmation operations.
Fig. 3. In stem development, each one loads its code in the same branch.
How can thousands of developers often upload their codes to the same branch without conflicts? It turns out that if you frequently perform small confirmation operations instead of performing huge monolithic mergers, the number of conflicts is quite small, and the conflicts that arise are desirable. This is due to the fact that conflicts will inevitably exist regardless of the integration strategy used, but it is easier to resolve a conflict representing one to two days of work (with continuous integration) than a conflict representing months of work (with late integration).
And what about the stability of the branch? If all developers work in the same branch and a developer loads code that does not compile or causes serious errors, the whole process can be blocked. To prevent this, it is necessary to have a self-testing layout. The self-testing layout is a fully automated process (i.e., it can be run with a single command) containing a sufficient number of automated tests; if they all pass, then you can be sure of the stability of the code. The usual approach is to add a confirmation interceptor to your version control system (VCS), which accepts each such operation, runs it through a build on some kind of continuous integration server (CI), such as, for example, Jenkins or Travis, and rejects if the layout fails. The CI server is the controller, checking each batch of code before allowing it to load into the trunk; it acts as a good brake, stopping a bad code before it goes into production.
Without continuous integration, your software is considered inoperative until someone shows that it works — this usually happens during the testing or integration phase. With continuous integration, it is believed that your software is working (if, of course, there is a fairly comprehensive set of automated tests) with each new change - and the developer knows the moment when the violation occurs, being able to fix the error immediately.
- Jez Humbley and David Farley, authors of the book “Continuous Delivery” (“Continuous Software Delivery”)
How can you use continuous integration to make big changes? That is, if you are working on a characteristic that takes a week, how can you load into the trunk several times a day? One solution is to use feature toggles.
Safety Latches / Feature Switches
At the beginning of the 19th century, most people avoided elevators, fearing that if the cable breaks, elevator passengers will die. To solve the problem, Elisha Otis invented a “safe lift” and carried out a bold demonstration of its effectiveness. To do this, Otis built a large open elevator shaft, lifted an open elevator up to several floors, and in front of the crowd ordered the assistant to cut the cable, as shown in fig. 4. The elevator began to fall, but was immediately stopped.
Fig. 4. Elisha Otis demonstrates "safe lift".
How it works? The key element of the safe lift is the safety latch shown in fig. 5. In the initial position, the safety latches are fully extended so that they fit into the latches on the elevator shaft and do not allow the elevator to move. Only when the elevator cable is tight enough will the safety latches come out of the engagement. In other words, the latches are in the retracted state only when the cable is intact.
Fig. 5. A drawing of a patent in a safe elevator shows an elevator shaft with an elevator in the middle (D), with safety latches on the sides (f) and a cable at the top (G).
In this gorgeous design, safety latches provide security by default. In software, the same function is performed by the switch characteristics. The way to use the characteristics switches is to enclose all of the new code in the “if” statement that looks for the named characteristic switch (for example, showFeatureXYZ) in the configuration file or database.
if (featureToggleEnabled (“showFeatureXYZ”)) {showFeatureXYZ ()}
The key idea is that, by default, all the on / off switches of the characteristics are in the “off” position. Those. The default position is safe. This means that while the characteristic switch shell is in effect, it is possible to load and even unfold incomplete or erroneous codes, since the “if” operator ensures that the code will not be executed or will not have any visible effect.
After completing the work on the characteristic, the specified characteristic switch can be turned to the “on” position. The easiest way is to save the named characteristics switches and their values in configuration files. Thus, it is possible to allow this characteristic in the configuration of the development environment, but prohibit it from use until it is completed.
# config.yml
dev:
showFeatureXYZ: true
prod:
showFeatureXYZ: false
A more powerful option is to have a dynamic system in which you can set the value of the characteristic switch for each user, and the presence of a user web interface in which your employees can dynamically change the values of the characteristic switches to allow or deny certain characteristics for certain users, like shown in fig. 6
For example, during development, you can initially allow some characteristic only for your company's employees. When the feature is complete, you can enable it for 1% of all users. If everything is normal, then you can give permission for 10% of users, then for 50%, etc. If a problem occurs at some point, the web user interface allows you to turn off the feature in question. Switches characteristics can be used even for comparative testing.
Fig. 6. Use the XLNT performance shutdown tool on LinkedIn to enable some feature for 1% of US users.
Bulkheads / Source Code Base Separation
On ships, use bulkheads to create insulated watertight compartments. Due to this, the destruction of the hull causes the flooding of only one single compartment.
Similarly, in the software, you can divide the base of the source code into isolated components, so that the problem, if it occurs, will act only within this component.
The separation of the source code base is important because the worst property for the source code base is oversize. The larger the size of the program, the slower its development. For example, consider the tablet from Steve McConnell's “Perfect Code” (Steve McConnell “Code Complete”, 2004), showing the relationship of project size (in lines of code) to the error density (the number of errors per thousand lines of code):
Here you can see that as the code base increases, the error density increases. If the base of the source code is increased by 2 times, then the number of errors increases by 4-8 times. And when you have to work with more than half a million code lines, the error density can reach one error for every 10 lines!
The reason for this is - if you use a quote from the book of Venkat Subramaniam, Andy Hunt "Sketches on the subject of rapid software development. Work in the real world. "- that" software development does not occur on any scheme, not in any integrated development environment or in some design tool; it happens in your head. ” The base of the source code, containing hundreds of thousands of code strings, far exceeds what a person can hold in his head. It is impossible to consider all the interactions and dead ends in such a huge program. Therefore, a strategy is needed to separate the program so that it is possible at this point in time to focus on one part of it and safely set aside everything else.
There are two main strategies for the separation of the code base: one is the introduction of dependencies on artificial features, and the other is the introduction of microservice architecture.
The idea of dependencies on artificial features is to change your modules so that instead of depending on the source code of other modules (dependence on source), they obey to versioned artificial features issued by other modules (dependence on artificial features). You may already be doing this with libraries of open source. To use jQuery in your JavaScript program or Apache Kafka in your Java code, you do not rely on the source code of the respective open source libraries, but on the versioned artificial feature that these libraries provide, for example, jquery-1.11-min.js or kafka -clients-0.8.1.jar. If you use a fixed version of each module, the changes made by the developers on such modules will not affect you until you explicitly select the update. This approach - like bulkheads on a ship - isolates you from problems in other components.
The idea of microservices is to move from a single monolithic application, in which all your modules work in the same process and communicate through functional calls, to isolated services, where each module works in a separate process — usually on a separate server — and where the modules communicate through messages. Service boundaries act as software ownership boundaries, so microservices can be a great way to let teams work independently of each other. Microservices also make it possible to use many different technologies to create your products (for example, one microservice can be built in Python, another in Java, and the third in Ruby) and an independent assessment of each service.
Although dependencies on artificial features and microservices have many advantages, they also contain quite a few significant drawbacks, not the least of which for both methods is functioning contrary to the ideas of continuous integration described earlier. For a full discussion of the tradeoffs, see the article " Splitting Up a Codebase into Microservices and Artifacts " ("Dividing the source code base in microservice approaches and artificial features").
Three questions
The safety mechanisms allow you to move faster, but you have to pay for everything: they require a preliminary investment of time when development, in fact, slows down. How to decide how much time it makes sense to spend on the security mechanism for the current product? To make a decision, you need to put three questions in front of you:
• What is the price of the problem being addressed by the mechanism in question?
• What is the price of the security mechanism itself?
• How likely are such problems to occur?
To finish this article, let's consider how the above three questions work for a common solution: do or not automated testing.
Although some die-hard testing enthusiasts argue that you should write tests for everything and strive for 100% coverage of the code, it is extremely rare to see anything close to this in the real world. When I wrote my book Hello, Startup, I interviewed developers from some of the most successful startups of the last decade, including Google, Facebook, LinkedIn, Twitter, Instagram, Stripe and GitHub. It turned out that all of them were making thoroughly thought out compromises on what to check and what not to check, especially in their early years.
Consider these three questions.
What is the cost of writing and maintaining automated tests?
Preparation of unit tests is currently inexpensive. There are high-quality testing platforms for almost all programming languages; Most building systems have built-in support for unit testing and, as a rule, work quickly. On the other hand, integration tests (especially user interface tests) require the use of large parts of your system, which means they are more expensive to configure, slower and harder to maintain.
Of course, integration tests can catch a lot of mistakes that unit tests will miss. But since their setup and implementation are quite expensive, it turned out that most start-ups direct the main assets into a large complex of unit tests, investing only a little in a small set of extremely valuable and critical integration tests.
What is the cost of errors that can pass if there are no automated tests?
If you make a prototype, which you will most likely throw away in a week, then the cost of errors is low, so investing in tests probably will not pay off. On the other hand, if you create a payment processing system, the cost of errors is very high: you, of course, do not want to debit the client’s credit card twice or operate with the wrong amount.
Although the start-up companies in which I communicated with the developers differed in their testing practice, almost everybody identified several parts of their codes for themselves - usually payments, security and data storage - the violation of which is simply unacceptable and therefore a serious check literally from day one.
What is the probability of getting errors without automated tests?
As was shown above, as the code base grows, the error density increases. The same is true for increasing team size and project complexity.
For a team of two programmers, with a code of 10,000 lines, it will be enough to spend only 10% of their time writing tests; with twenty programmers and a code of 100,000 lines, it will take 20% of their time, and for a team of two hundred code developers from 1 million lines it will take 50%!
As the size of the program and the number of developers grow, it is necessary to spend relatively more time on testing.
Source: https://habr.com/ru/post/300002/
All Articles