Test shot: about the role of a / a tests in a / b testing

Today, suddenly there will be no presentation at all. The fact is that in the past I did a bit a / b testing and yesterday, once again I got on an article that says that before starting the experiments you need to do a / a test (that is, one where the control group sees the same version of the site As an experimental one), I decided that I could and should add my two pennies to this question. It turns out non-core for my blog, but once you can, I guess. Otherwise, it will break me, yes.
Some of the most costly errors of a / b testing in the sense of lost lives were made when searching for a cure for scurvy. After it seemed that it turned out that the lemons were helping her, the experiment was re-passed, and there, already in a clinical setting, the patients were treated with lemon juice concentrate. And how in the eighteenth century, did you get the concentrate? Of course, a long boil. Well, you understand: the clinical verification of the previously obtained results is not confirmed. But it was just necessary to be treated, as in the photograph to the post. It is possible to hope that human life does not directly depend on errors in your system a / b testing, but one cannot assume that there are no errors in it. And what is the connection of some of them with a / a tests.
What is bad control experiment?
Terminology digression
I will sometimes call a / a test a control experiment or even just a control . Also, in the case of a present a / b experiment, control is the collection of users who sees the production version (it’s a control group or control sample ), and not an experimental one. I will try to make it clear from the context what exactly it is about, and the concepts of “control” and “control” are not confused.
')
Also, I will not be able to write every time “the experiment revealed a winner with a given statistical significance,” and I will use the words triggered or shot instead. If not revealed, then, therefore, did not work .
Actually, the claim
Control before the start of real experiments is insufficient . Why do people spend it? To verify that none of the two identical system versions wins. We are all sparrows, we know that we need statistical significance (we know, right?), And set its threshold in our tools, depending on the available users, at 0.95 (if we have dense hopeless poverty in terms of users), 0.99 ( this is a plus or minus normal case) or at 0.999 or more (if we are like Google or Yandex or have come up with a very good metric, which can be estimated with a small scatter).
What do these numbers mean? The threshold of statistical significance tells us only what proportion of mistakes we are prepared to make. The number 0.95 means that we are ready to make the wrong decision in 0.05 cases, that is, an average of one time out of twenty, with 0.99 - this is one time out of a hundred, and so on. That is, a certain fixed percentage of controls has the right to show the winner when the system is operating normally. Attention, the rhetorical question: is it possible to check the normal operation of the system with one launch? Of course not. If a problem has crept into the implementation, then it is not at all necessary that all controls will reveal the winner (give the so-called false positive). It is possible that there will simply not be one of the twenty, but two or three. Or even one and a half.
Is it possible to check the regular operation of the system by twenty control experiments for a case with a significance of 0.95? How much do you think false positives out of twenty controls should be if the system is working correctly?
The probabilities of getting a different number of triggers look like this (on the right there are also no zeros, they are simply not visible on this scale):
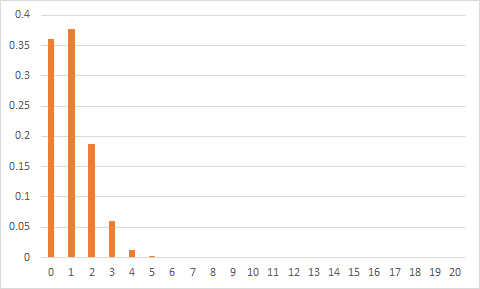
That is, the probability of getting one and not getting one is very close and great, two are also easy, although a little more difficult, three are suspicious, but it is possible, with four you can put money on the fact that the system works incorrectly, with five or more already put not money, but parts of the body on the fact that all the hell raztak and razedak generally broken in the trash .
One should not be overjoyed if we have not received a single response. In this case, it is impossible to exclude breakdowns in the opposite direction: we could have a system that never shows a winner at all. This will have to be checked separately.
Now let's imagine that out of twenty experiments we have five (that is, everything is very bad), and we only had one. The chances that it will work are just 0.25 (5 out of 20). That is, having conducted one control over such an incorrect system, we in three cases out of four will not even suspect anything.
So what to do instead of the control experiment?
Instead of one control experiment at the beginning, it is necessary to conduct such experiments constantly (ideally) or at least regularly and monitor the accumulated statistics. If you make modifications, even the most innocuous ones, into the system of experiments, it makes sense to consider the statistics accumulated in the latest version separately. If control experiments shoot more often than they are supposed to by a given level of significance, this is a strong signal that something is wrong.
How exactly this will help
Of course, constant control experiments are not a panacea, and with their help it is impossible to insure against all possible problems in general. But quite a few things you will notice over time that I will show with examples below.
Breakdown classification
First of all, we note that an error in the system of experiments can hide in one of two places:
- System run experiments. Splitting users, determining what user to show, that's all.
- Calculate the results of experiments. Calculation of metrics, implementation of stattest.
The error may lie in the implementation, and in the algorithm or the very concept of how you make decisions.
Errors in calculating the results are a bit less traumatic: if you have user activity logs saved ( logs? What other logs? ), Then you can correct the error and recalculate all affected experiments with an afterthought to restore the picture. Users, of course, will not understand what you decided to roll out to production on the incorrect results of experiments, but at least you can understand how bad it was. If the launch system of experiments is broken, then everything gets worse. In order to understand that you rolled out all these half a year, while it worked incorrectly, you need to recast all the affected experiments. It is clear that for a dynamically developing website, restoring the version that was six months ago is fantastic, impossible in real life.
For more convincing, I will cite one example of conceptual problems in conducting experiments and in the calculation system.
Problem with splitting users
If our project grows, we have more developers and designers, and at some point the throughput of the experiment system becomes a blocker for implementing the entire stream of
This allows you to standardize the volume of the experiment within the company (if the improvement does not win the improvement on this fixed volume in a fixed time, it means that the change is not good enough), and also to avoid user downtime. The benefit is about the same as from container shipping, it becomes very easy to run and track experiments.
So, if we mistakenly show something really awful (idle buttons, broken layout or a very bad content aggregation algorithm) in an experiment to some bakery loser, and we notice this not right away, then users from such a bake will be unhappy for a long time, and their behavior will be different from the behavior of ordinary users who have not been tortured. Comrades from Bing purposefully caught such a situation when, after a bad experiment, the freed bake was made a control group. The number of sessions per user, which is the main metric there (this is really a good measure of user loyalty), was still very long in this unfortunate batch than in the other control:
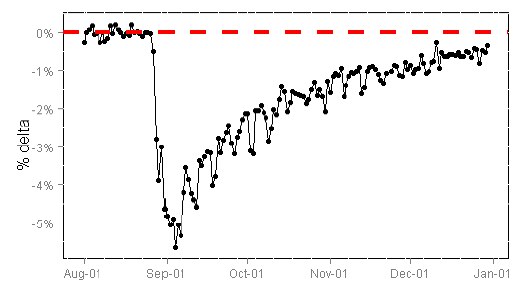
Picture from here: www.exp-platform.com/documents/puzzlingoutcomesincontrolledexperiments.pdf
I want to separately note that the reality is much more dramatic than this picture: people break into buckets by hash code from cookies, and in three months a fairly significant percentage of users have been updated in the bucket, simply because of the swelling of the cookies. That is, by the end of the third month, there are already quite a few
My own experience confirms the existence of post-effects from the experiment.
If you regularly carry out controls, then there is a chance to notice this problem and fix it. No, the chance is not 100%: if some buckets are fixed under control forever, then it will not manifest there. But still. For fixing, for example, you can regularly mix users between bakes, adding to all user cookies (or what you use for hashing instead of cookies) the same modifier.
The problem in the calculation of experiments
In cases where we do not focus directly on the conversion (if we are not an online store, then this is normal), we need some kind of indicator, calculated from user actions. Clicks, visits to the site, whatever. The danger lies in gathering all the actions of all users in one big heap and counting the average value over it.
The calculation of the statistical significance of the difference of the average values obtained for a given metric in the control and experimental samples is based on the Central Limit Theorem (hereinafter referred to as the CLT). She tells us that the average has a normal distribution, which means that we can estimate confidence intervals well and make a verdict on whether the averages are different in the control and experimental groups.
The catch here is that the PTC requires independence of averaged measurements.
On the fingers of the independence of events for those who forgot
Events are considered independent if the known outcome of one does not affect the likelihood of the other. A vivid example of dependent events is the survival by the same person up to 80 and up to 90 years. If we know that a person has lived to 90, then the probability to live to 80 is equal to 1. In the opposite direction, if a person did not live to 80, then he will not exactly live to 90 either. Some outcomes of one event affect the probabilities of outcomes of the second. In contrast, for two unfamiliar, unrelated people living to the same age - independent events. Of course, everything in the world is interconnected, and for some pairs of such people there is still an addiction, but in practice it has to be neglected.
So, the actions of the same user on our service in the general case are not independent events . From examples close to me, suppose that a person consistently asks a search for something like this:
Kalashnikov machine Price
Kalashnikov automatic buy
Kalashnikov automatic buy
Kalashnikov assault rifle is not a layout to buy
hire a hit man
If, say, we consider the fact of a click on each request (abandonment rate, although it’s the day before the search, but let's say it took us for some reason), then even such a user, as in the example above, most likely will not click on the documents that came from the issuance of previous requests. Well, or it will be less likely to click than if I had asked such a request directly. And of course, he would not have asked him directly at all, if not for the previous results. He will be especially upset by the fact that to say “not a mock-up” is a sure guarantee for getting a mock-up, but he does not understand this.
I am sure that everyone who wants to come up with other metrics himself, for which not one, but several digits per average is taken from one user. It is very easy to create a new metric and not to notice that it has a dependency element in it. So, it happens that in such a situation, the controls start to operate much more often than they are supposed to by the chosen threshold of significance. This undoubtedly means that a / b experiments often work randomly, and it is dangerous to make decisions based on their results.
I will sum up
Allocating the same amount of users for a constant a / a experiment (or for a few) as for a / b experiments that you are conducting is a good practice. If you follow the accumulated statistics, it helps to notice some problems that arise in the system of conducting and calculating the results of user experiments. Control experiments should not, on average, reveal a winner more often than they are supposed to by a given level of significance. If you see that instead of one experiment out of twenty, two or three systematically work for you, this is a reason to think. Such monitoring is not a panacea, so not everything that can break there can be seen, but it is definitely useful.
Source: https://habr.com/ru/post/299142/
All Articles