Another Big Data slap? Disappointment phase
In previous articles we have already shown on real events that the term Big Data, “greasy and shabby”, goes into the “disappointment” phase:
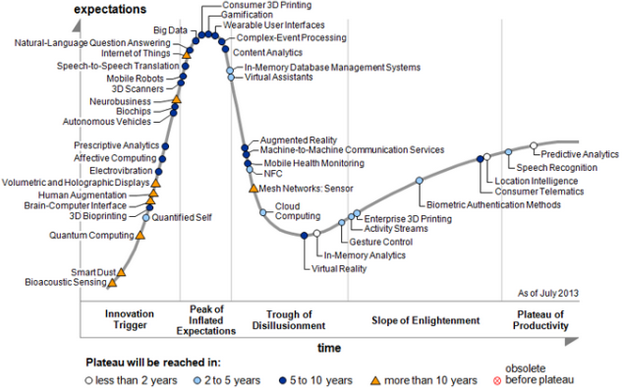
As another clove in the cover, here is a translation of one of a series of articles of yet another disappointment. Is it all bad and what is the Big Error of such an approach to Big Data - after the article. The material is in any case useful for familiarization, since it contains several important references to industrial studies and data sets.
')
Big Data - Awareness: We are in Transition
Recently I read a publication from Ali Syed , entitled "Europeans do not believe in the effectiveness of Big Data . "
This study was commissioned by the Vodafone Institute of Society and Communications by market researchers from TNS Infratest. It was attended by more than 8,000 people from 8 European countries and by his example one can see the attitude of people towards both Big Data and analytics as a whole.
There are still people who do not believe in the fact that we live in the era of Big Data. In other words, they believe that the Big Data question is simply overrated, and all the hype around it will soon subside.
For me, the concept of Big Data is not new. We only gradually gain skills for more and better analysis. And this is only the beginning, and the further this process goes, the more an ordinary person will believe in Big Data.
I remember how at a conference devoted to Big Data in March 2013, a professor of statistics argued with the other participants, saying that such a thing as Big Data simply does not exist, because in order for the data to be analyzed and to extract statistics from them , then they need to be reduced in quantity and divided into small groups.
Meeting Big Data is inevitable for everyone. One of the possible reasons for people's distrust of Big Data may be that they simply do not have access to them. As they say, it's better to see once. Companies working with Big Data are gradually publishing their previously secret tools and massive data sets so that the world community can finally take this step forward and feel Big Data.
In November 2015, Google released TensorFlow , an in-depth analysis algorithm using Big Data, and then, in January 2016, Yahoo released " The Biggest Dataset for Machine Analysis " - as much as 13.5 terabytes of unarchived data.
According to the head of the project from Yahoo Labs: “ Many researchers and data analysts do not have access to really large arrays and data sets, since this is usually a privilege of very large companies. We released our data set because we value open and mutually beneficial cooperation with our colleagues and always strive to promote machine analysis technologies. "
We live in a transitional period of time, and so far there is no what can be called absolute Big Data, and the exact volumes of perception of “big data” differ from person to person. For some people, and gigabytes is already Big Data, and to some it is small and petabyte, and this depends on the storage capacity and computing power.
Data volumes continue to grow, but the obvious question is: Do we ever reach the maximum amount of data that we can store and use? I think that yes, it is possible, because the great scientist Laplace spoke about such a volume of data that we were once told.
In the Demon of Laplace affirms: “We can consider the present state of the Universe as a consequence of its past and the cause of its future. Reason, which at every certain moment in time would know all the forces that set nature in motion, and the position of all the bodies of which it consists, if it were also extensive enough to analyze this data, could embrace the motion of the greatest bodies of the Universe by a single law and the smallest atom; for such a mind, nothing would have been unclear and the future would exist in his eyes just like the past ... ” - Pierre-Simon-Laplace, Philosophical Essay on Probabilities.
The same concept was rephrased by Stephen Hawking: " In essence, he said that if at any particular moment we knew the positions and speeds of all the particles in the universe, then we could calculate their behavior at any time both in the past and in the future . " The big obstacle on the way to the Laplace hypothesis is the Heisenberg uncertainty principle, but still Stephen Hawking wrote that " Still, it would be possible to predict the combination of position and speed ."
If one day we are able to create such a data set, then no one will remain unconvinced;)
Summing up, we can say that we live during the transition period, when people are beginning to understand that the possible volumes of data sets are growing and traditional data processing tools will not cope with this new load.
===========================================
If we apply the laws of dialectics, then the article shows the Big Error, which philosophers and scientists warned about as early as the 19th century: the mechanistic approach does not apply to complex structures. Just as physics cannot explain the laws of molecular chemistry, just as chemistry cannot explain the structure of the thinking of society, so “just data sets” are not Big Data.
But, in any case, it should be recognized that the term Big Data is going through a recession (with the exception of the drive and hosting industry), and instead the researchers use the terms “smarter big data” - Smart / Clever (Big) Data.
PS While “scientists” count and count atoms in the Universe and terabytes of checks of the same type from stores, the industry is moving at a fast pace — waiting and participating in (pro) movement! :-)
As another clove in the cover, here is a translation of one of a series of articles of yet another disappointment. Is it all bad and what is the Big Error of such an approach to Big Data - after the article. The material is in any case useful for familiarization, since it contains several important references to industrial studies and data sets.
')
Big Data - Awareness: We are in Transition
Recently I read a publication from Ali Syed , entitled "Europeans do not believe in the effectiveness of Big Data . "
This study was commissioned by the Vodafone Institute of Society and Communications by market researchers from TNS Infratest. It was attended by more than 8,000 people from 8 European countries and by his example one can see the attitude of people towards both Big Data and analytics as a whole.
There are still people who do not believe in the fact that we live in the era of Big Data. In other words, they believe that the Big Data question is simply overrated, and all the hype around it will soon subside.
For me, the concept of Big Data is not new. We only gradually gain skills for more and better analysis. And this is only the beginning, and the further this process goes, the more an ordinary person will believe in Big Data.
I remember how at a conference devoted to Big Data in March 2013, a professor of statistics argued with the other participants, saying that such a thing as Big Data simply does not exist, because in order for the data to be analyzed and to extract statistics from them , then they need to be reduced in quantity and divided into small groups.
Meeting Big Data is inevitable for everyone. One of the possible reasons for people's distrust of Big Data may be that they simply do not have access to them. As they say, it's better to see once. Companies working with Big Data are gradually publishing their previously secret tools and massive data sets so that the world community can finally take this step forward and feel Big Data.
In November 2015, Google released TensorFlow , an in-depth analysis algorithm using Big Data, and then, in January 2016, Yahoo released " The Biggest Dataset for Machine Analysis " - as much as 13.5 terabytes of unarchived data.
According to the head of the project from Yahoo Labs: “ Many researchers and data analysts do not have access to really large arrays and data sets, since this is usually a privilege of very large companies. We released our data set because we value open and mutually beneficial cooperation with our colleagues and always strive to promote machine analysis technologies. "
We live in a transitional period of time, and so far there is no what can be called absolute Big Data, and the exact volumes of perception of “big data” differ from person to person. For some people, and gigabytes is already Big Data, and to some it is small and petabyte, and this depends on the storage capacity and computing power.
Data volumes continue to grow, but the obvious question is: Do we ever reach the maximum amount of data that we can store and use? I think that yes, it is possible, because the great scientist Laplace spoke about such a volume of data that we were once told.
In the Demon of Laplace affirms: “We can consider the present state of the Universe as a consequence of its past and the cause of its future. Reason, which at every certain moment in time would know all the forces that set nature in motion, and the position of all the bodies of which it consists, if it were also extensive enough to analyze this data, could embrace the motion of the greatest bodies of the Universe by a single law and the smallest atom; for such a mind, nothing would have been unclear and the future would exist in his eyes just like the past ... ” - Pierre-Simon-Laplace, Philosophical Essay on Probabilities.
The same concept was rephrased by Stephen Hawking: " In essence, he said that if at any particular moment we knew the positions and speeds of all the particles in the universe, then we could calculate their behavior at any time both in the past and in the future . " The big obstacle on the way to the Laplace hypothesis is the Heisenberg uncertainty principle, but still Stephen Hawking wrote that " Still, it would be possible to predict the combination of position and speed ."
If one day we are able to create such a data set, then no one will remain unconvinced;)
Summing up, we can say that we live during the transition period, when people are beginning to understand that the possible volumes of data sets are growing and traditional data processing tools will not cope with this new load.
===========================================
If we apply the laws of dialectics, then the article shows the Big Error, which philosophers and scientists warned about as early as the 19th century: the mechanistic approach does not apply to complex structures. Just as physics cannot explain the laws of molecular chemistry, just as chemistry cannot explain the structure of the thinking of society, so “just data sets” are not Big Data.
But, in any case, it should be recognized that the term Big Data is going through a recession (with the exception of the drive and hosting industry), and instead the researchers use the terms “smarter big data” - Smart / Clever (Big) Data.
PS While “scientists” count and count atoms in the Universe and terabytes of checks of the same type from stores, the industry is moving at a fast pace — waiting and participating in (pro) movement! :-)
Source: https://habr.com/ru/post/298498/
All Articles