Overview and testing of flash storage from IBM FlashSystem 900
Photos, basic principles and some synthetic tests inside ...

Modern information systems and the pace of their development dictate their own rules for the development of IT infrastructure. Storage systems on solid-state media have long been transformed from luxury into a means of achieving the necessary disk guarantor SLA. So, here it is - a system that can issue more than a million IOPS.
')

Basic principles
This storage system is a flash array with increased speed due to the use of MicroLatency modules and optimization of MLC technology.

When we asked our company what technologies are used to ensure fault tolerance and how many gigabytes are actually hidden inside (IBM claims 11.4 TB of clean space), he replied noncommittally.
As it turned out, everything is not so simple. Inside each module, there are memory chips and 4 FPGA controllers, a Raid with a variable stripe (VSR) is built on them.
Each module chip is divided into so-called layers. On each N-layer of all chips inside the module Raid5 of variable length is built.

When a single layer fails on a chip, the stripe length is reduced, and a broken memory cell is no longer used. Due to the excess amount of memory cells, the usable volume is saved. As it turned out, the system is much more than 20 TB raw flush, i.e. almost at the level of Raid10, and due to redundancy we do without restructuring the entire array when a single chip fails.

Having obtained a Raid at the module level, FlashSystem integrates the modules into a standard Raid5.
Thus, to achieve the required level of fault tolerance, from a system with 12 modules of 1.2 TB each (marking on the module) we get a little more than 10 TB.
Testing
After receiving the system from a partner, we install the system into a rack and connect to the current infrastructure.

We connect the storage system according to a pre-agreed scheme, set up a zonning and check availability from the virtualization environment. Next - prepare a laboratory stand. The stand consists of 4 blade servers connected to the tested storage system by two independent 16 Gbit optical factories.
Since “IT Park” leases virtual machines, the test will evaluate the performance of one virtual machine and a whole cluster of virtual loops running vSphere 5.5.
We optimize our hosts a bit: let's configure multithreading (roundrobin and limit the number of requests), also increase the queue depth on the FC HBA driver.
We create one virtual machine per blade server (16 GHz, 8 GB RAM, 50 GB system disk). We will connect 4 hard disks to each machine (each on its own flash moon and on its own Paravirtual controller).
In testing, we consider synthetic testing with a small 4K block (read / write) and a large 256K block (read / write). The storage system consistently gave 750k IOPS, which looked very good for us, despite the space figure stated by the manufacturer at 1.1M IOPS. Do not forget that everything is pumped through the hypervisor and OS drivers.
We also note that, like all known vendors, the declared performance is achieved only in greenhouse laboratory conditions (a huge number of uplink SANs, a specific LUN breakdown, the use of dedicated servers with RISK architecture and specially configured load generating programs).
findings
Pros : great performance, easy setup, friendly interface.
Cons : outside the capacity of one system, scaling is carried out with additional shelves. The advanced functionality (snapshots, replication, compression) is rendered into the storage virtualization layer. IBM has built a clear storage hierarchy, headed by a storage virtualizer (SAN Volume Controller or Storwize v7000), which provides multi-layered, virtualized and centralized management of your storage network.
Bottom line : IBM Flashsystem 900 performs its task of processing hundreds of thousands of IO. In the current test infrastructure, it was possible to get 68% of the performance declared by the manufacturer, which gives an impressive performance density on TB.
Modern information systems and the pace of their development dictate their own rules for the development of IT infrastructure. Storage systems on solid-state media have long been transformed from luxury into a means of achieving the necessary disk guarantor SLA. So, here it is - a system that can issue more than a million IOPS.
')
Specifications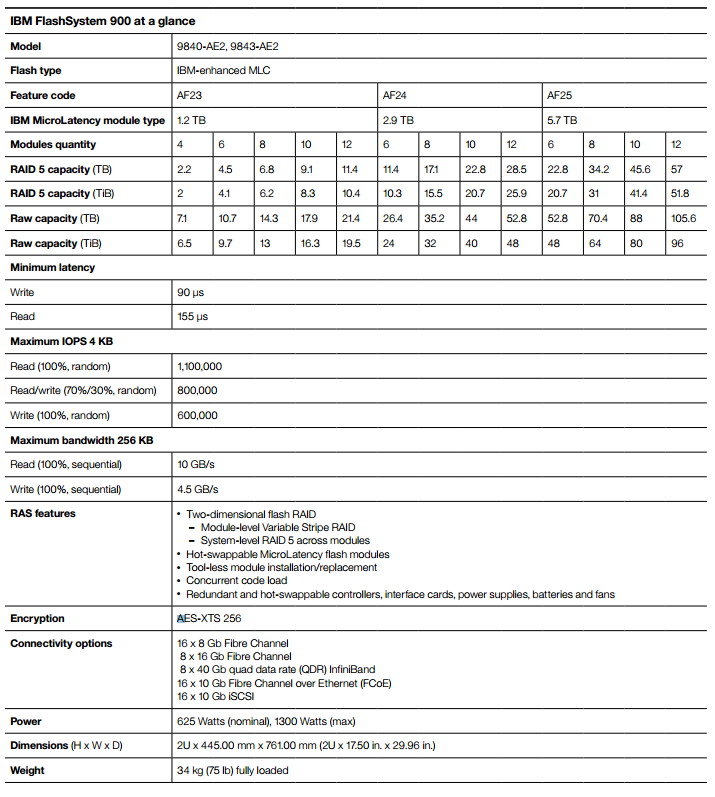
Basic principles
This storage system is a flash array with increased speed due to the use of MicroLatency modules and optimization of MLC technology.
When we asked our company what technologies are used to ensure fault tolerance and how many gigabytes are actually hidden inside (IBM claims 11.4 TB of clean space), he replied noncommittally.
As it turned out, everything is not so simple. Inside each module, there are memory chips and 4 FPGA controllers, a Raid with a variable stripe (VSR) is built on them.
Module internals, two double-sided boards



Each module chip is divided into so-called layers. On each N-layer of all chips inside the module Raid5 of variable length is built.
When a single layer fails on a chip, the stripe length is reduced, and a broken memory cell is no longer used. Due to the excess amount of memory cells, the usable volume is saved. As it turned out, the system is much more than 20 TB raw flush, i.e. almost at the level of Raid10, and due to redundancy we do without restructuring the entire array when a single chip fails.
Having obtained a Raid at the module level, FlashSystem integrates the modules into a standard Raid5.
Thus, to achieve the required level of fault tolerance, from a system with 12 modules of 1.2 TB each (marking on the module) we get a little more than 10 TB.
Web-based system interface
Yes, it turned out to be an old friend (hello to v7k clusters) with a terrible function of pulling a locale from a browser. In FlashSystem, the management interface is similar to Storwize, but they differ significantly in functionality. In FlashSystem, the software is used for setting up and monitoring, and the software layer (virtualizer) is not available as in the stopup, since the systems are designed for different tasks.

Testing
After receiving the system from a partner, we install the system into a rack and connect to the current infrastructure.
We connect the storage system according to a pre-agreed scheme, set up a zonning and check availability from the virtualization environment. Next - prepare a laboratory stand. The stand consists of 4 blade servers connected to the tested storage system by two independent 16 Gbit optical factories.
Wiring diagram
Since “IT Park” leases virtual machines, the test will evaluate the performance of one virtual machine and a whole cluster of virtual loops running vSphere 5.5.
We optimize our hosts a bit: let's configure multithreading (roundrobin and limit the number of requests), also increase the queue depth on the FC HBA driver.
ESXi Settings
Our settings may differ from yours!


We create one virtual machine per blade server (16 GHz, 8 GB RAM, 50 GB system disk). We will connect 4 hard disks to each machine (each on its own flash moon and on its own Paravirtual controller).
VM settings
In testing, we consider synthetic testing with a small 4K block (read / write) and a large 256K block (read / write). The storage system consistently gave 750k IOPS, which looked very good for us, despite the space figure stated by the manufacturer at 1.1M IOPS. Do not forget that everything is pumped through the hypervisor and OS drivers.
IOPS charts, delays and, it seems to me notrim
1 VM, Block 4k, 100% reading, 100% random. When providing all the resources from one virtual machine, the performance graph behaved nonlinearly and jumped from 300k to 400k IOPS. On average, we got about 400k IOPS
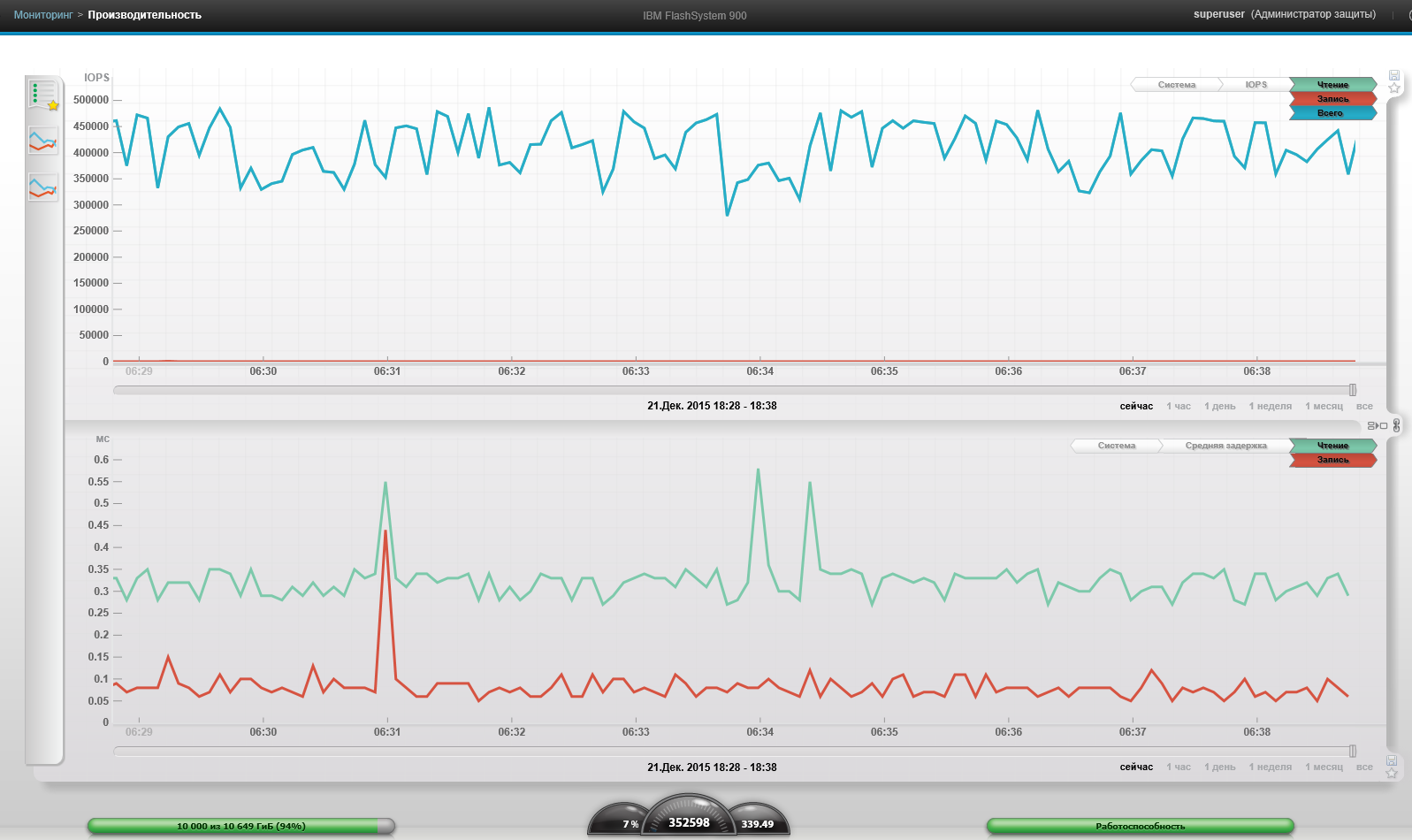
4 VM, Block 4k, 100% reading, 100% random

4 VM, Block 4k, 0% reading, 100% random
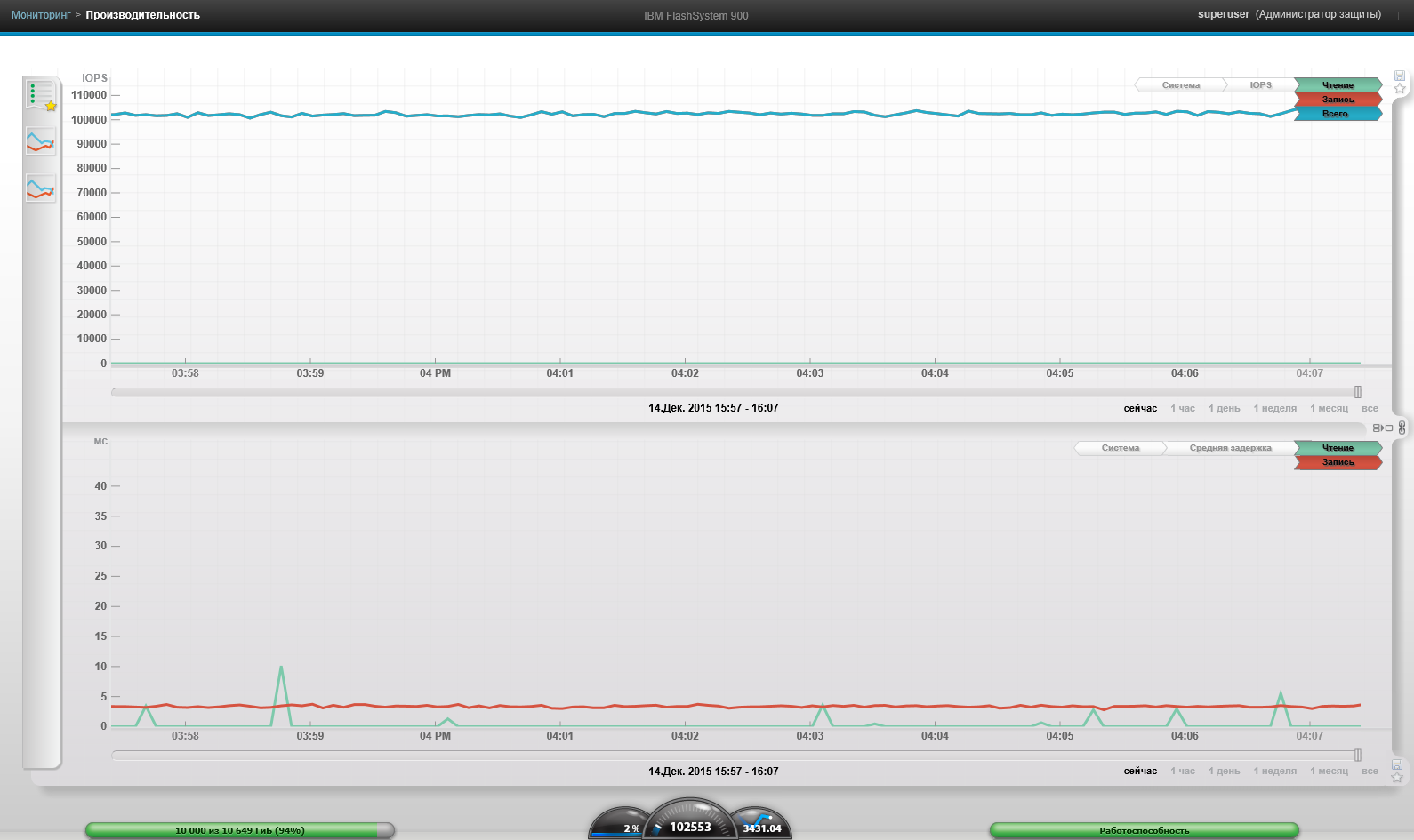
4 VM, Block 4k, 0% reading, 100% random, 12 hours later. We did not see drawdowns in performance.

1 VM, Block 256k, 0% reading, 0% random

4 VM, Block 256k, 100% reading, 0% random
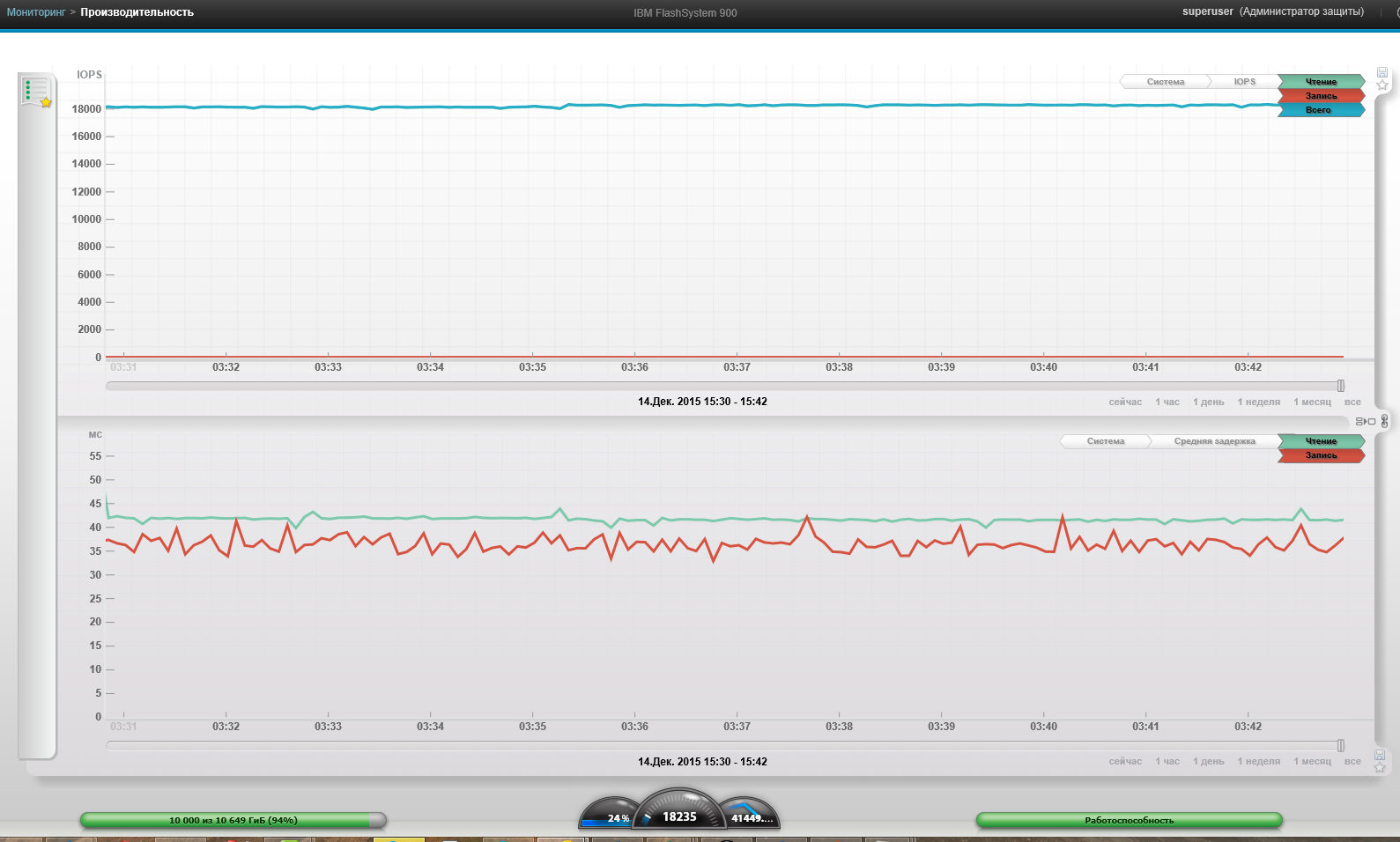
4 VM, Block 256k, 0% reading, 0% random
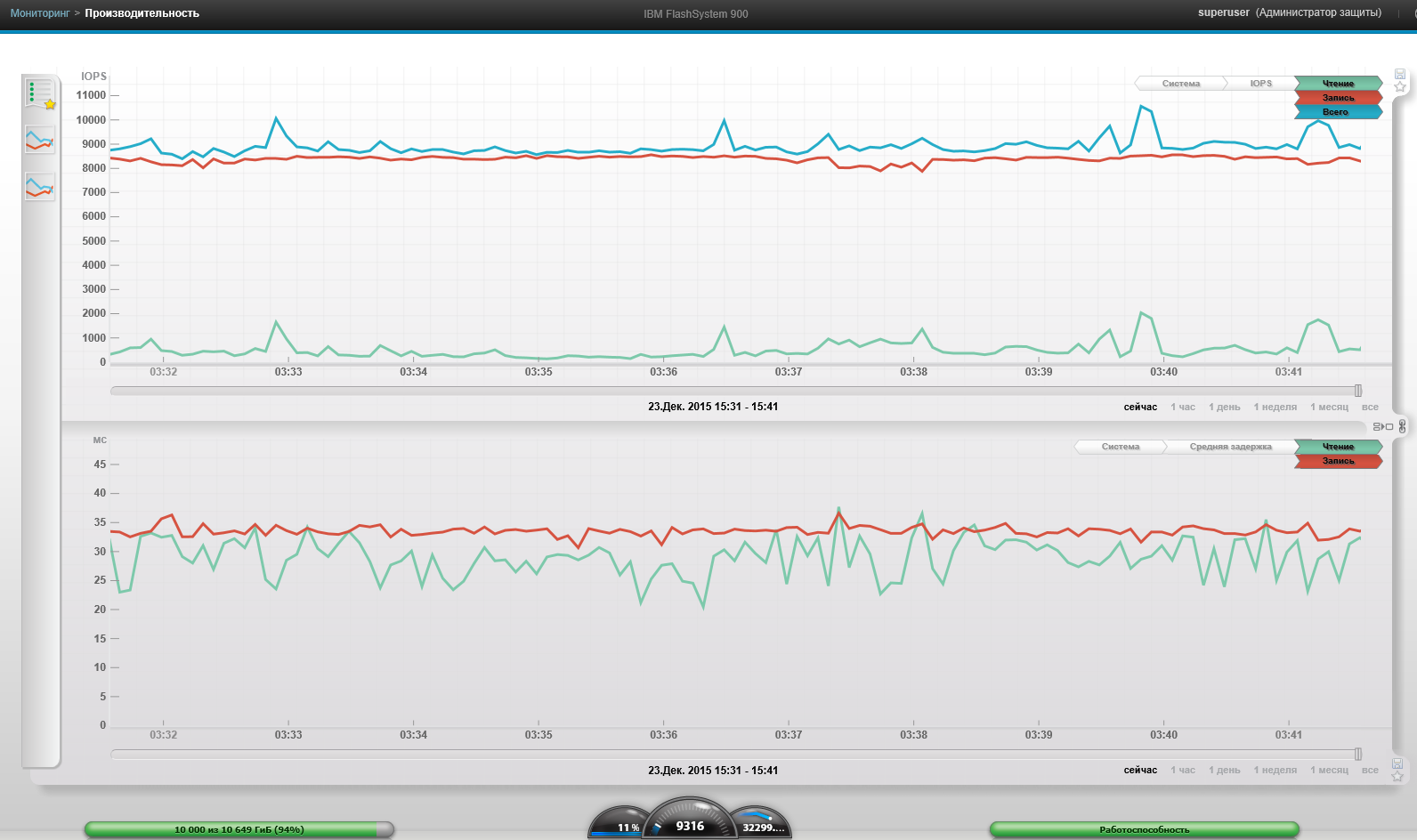
Maximum system capacity (4 VM, Block 256k, 100% read, 0% random)

4 VM, Block 4k, 100% reading, 100% random
4 VM, Block 4k, 0% reading, 100% random
4 VM, Block 4k, 0% reading, 100% random, 12 hours later. We did not see drawdowns in performance.
1 VM, Block 256k, 0% reading, 0% random
4 VM, Block 256k, 100% reading, 0% random
4 VM, Block 256k, 0% reading, 0% random
Maximum system capacity (4 VM, Block 256k, 100% read, 0% random)
We also note that, like all known vendors, the declared performance is achieved only in greenhouse laboratory conditions (a huge number of uplink SANs, a specific LUN breakdown, the use of dedicated servers with RISK architecture and specially configured load generating programs).
findings
Pros : great performance, easy setup, friendly interface.
Cons : outside the capacity of one system, scaling is carried out with additional shelves. The advanced functionality (snapshots, replication, compression) is rendered into the storage virtualization layer. IBM has built a clear storage hierarchy, headed by a storage virtualizer (SAN Volume Controller or Storwize v7000), which provides multi-layered, virtualized and centralized management of your storage network.
Bottom line : IBM Flashsystem 900 performs its task of processing hundreds of thousands of IO. In the current test infrastructure, it was possible to get 68% of the performance declared by the manufacturer, which gives an impressive performance density on TB.
Source: https://habr.com/ru/post/297656/
All Articles