The method of identifying "trolls" in online communities on the example of Q & AC
In connection with the subject matter of “Megamind” in our articles, we have somewhat moved away from hardcore IT subjects, but this does not mean that we are less interested in this. Therefore, I decided to dilute the current atmosphere with a small, near-scientific article. Under the cut there will be several formulas, please do not be afraid.
In general, this is a short translation of an article posted on the website of Cornell University , with some of my inserts.
 The Internet has become more important in the lives of people since the advent of Web 2.0 . The interaction between users gave them the opportunity to freely share information through social networks, forums, blogs, wikis-like sites and other interactive shared media resources.
The Internet has become more important in the lives of people since the advent of Web 2.0 . The interaction between users gave them the opportunity to freely share information through social networks, forums, blogs, wikis-like sites and other interactive shared media resources.
')
On the other hand, there are all the flaws in the concept of the second web. Content orientation has become the most important plus and minus of the network at the same time. Questions of reliability and reliability of information in full growth are facing the owners and users of interactive communities. As in real life, in the process of communication through the network, sometimes there are situations when some users violate the rules of generally accepted “network” etiquette . In fact, in order to preserve the normal atmosphere of the resource, the owners are forced to introduce artificial rules of interaction and to monitor their observance.
One of these obvious violations is trolling.
This article proposes a new approach for calculating intruders. This method is based on a measure of conflict of trust functions between different messages in the discussion thread. To demonstrate the consistency of the approach we will test it on artificial data.
Recently, the ways of obtaining information have shifted significantly towards accelerating, facilitating and reducing labor costs. In fact, thanks to the Internet, research of a particular topic has been reduced to a simple click of the mouse button. Although some issues are difficult to find a satisfactory answer with the help of traditional search engines. Instead, we prefer to get an expert opinion.
As a result, such a tool of information interaction as the question-answer community (hereinafter referred to as Q & AC ) has become widespread. Such systems allow each user to contribute to the development of the community. Unfortunately, not all messages are reliable: some users pretend to be experts, while others publish useless messages. Therefore, a very important process is the work of the moderators of these communities. Most often, the increase in "junk" messages - the result of the "trolls".
Users are the main characters of Q & AC. Conventionally, they can be divided into: "experts", "students" and "trolls".
Experts: users with knowledge or skills in a particular area.
Students: Users trying to gain information or experience.
Trolls: people trying by any means to disturb the peace of the community. Their goal is to create counterproductive discussions.
Many studies have already tried to evaluate the sources of information in the communities.
Some propose user assessment models based on the number of the best user responses. The best answer here is determined by the polling user or the voting method.
In other authors focus on the choice of questions selected by the user to answer. Experts always prefer to answer questions that are more competent.
Some authors propose complex structures based on the cognitive and behavioral criteria of users to evaluate not only the reliability, but also the experience of information providers.
When dealing with the information supplied by people, we are confronted with several levels of uncertainty. There are three levels of uncertainty for Q & AC. The first is associated with the extraction and integration of uncertainty, the second with information sources of uncertainty, the third with the very essence of information. In our case, we are more interested in the assessment of sources and part of the uncertainty associated with this. Indeed, in the network, when we encounter other users (ie, information sources), we almost never possess a priori knowledge of them.
One of the mathematical tools for modeling and processing inaccurate (interval) expert assessments, measurements or observations is the theory of trust functions .
The approach proposed in the article assumes the use of this theory in conjunction with the introduction of a quantity that determines the conflict between two combined trust functions.
Let us proceed to the description of the method.
One of the important assumptions suggests that "trolls" are integrated only into popular branches of the discussion. We divide the further description of the method into three steps.
Researchers offer the main characteristics of "trolls": aggression, deception, breaking the rules, success. Also indicate such behavioral characteristics as, disregard for moral norms, obvious sadistic and psychopathic inclinations. In the context of this work, the researchers distinguished between trolls and other users manually from messages. Based on this, messages can be: relevant, offtopic, nonsense or swearing. We define the framework characterizing the message:
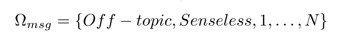 [one]
[one]
The nature of the message is determined by the published question or topic. At this stage, we assume that the method uniquely determines the nature of each message.
Detection of irrelevant messages still does not give a definite answer to the question of the user's belonging to the trolls cohort. A user can only get caught up with and responding to podchevki. In addition, the subject matter may gradually change. In fact, in order to distinguish a “troll” from other users, we need to quantify how much this user conflicts with others. The proposed approach and involves measuring the magnitude of the conflict between the messages of each user.
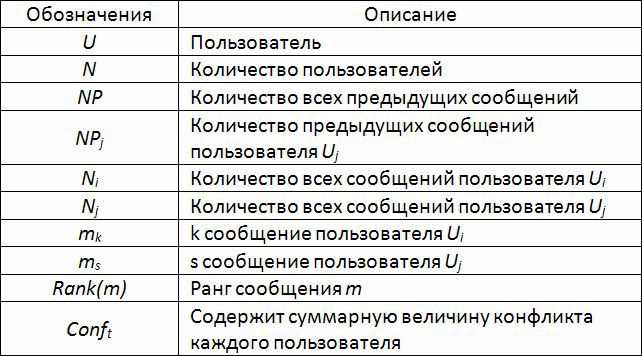
- Conf msg / U : a measure of the conflict between the k th message of the user U i and the messages written by each other user U j .
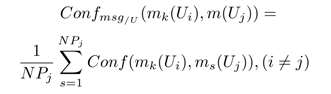 [2]
[2]
- Conf msg : a measure of the conflict between the k th message of user U i and all messages written by all other users of U based on a weighted average. This value takes into account the number of messages written by each user in order to determine the level of conflict, especially between the "trolls" and experts.
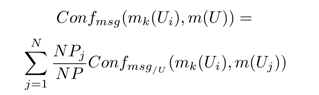 [3]
[3]
- Conf user : a general measure of user conflict U i
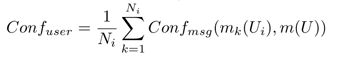 [four]
[four]
The magnitude of the cumulative conflict of the user may increase when he embarks on an endless debate with the "troll." In this case, the user becomes a victim, and the moderators have to control the behavior of users in many threads.
The last step is to classify users according to their conflict measures into two groups. The authors have provided for the partitioning of users into groups using the algorithm K-means .
The k-means algorithm is a simple repetitive clustering algorithm that divides a specific data set into a user-defined number of clusters, k . The algorithm is simple to implement and run, relatively fast, easily adaptable and common. This is historically one of the most important data mining algorithms.
In our case, the number of clusters: k = 2 .
As a result of the algorithm, all users will be divided into two clusters. "Trolls" will fall into the group with the greatest measure of conflict, and good users - with the least measure of conflict.
Consider the following example:
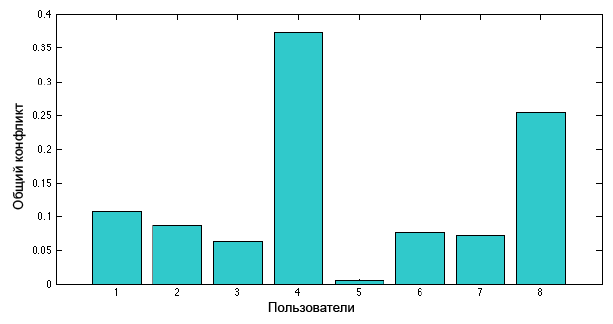
Take one of the discussion threads, containing thirty-one messages written by eight users. The overall measure of each user's conflict, expressed through equation [4], is shown in the figure below.
User U 1 sent three relevant and two disputed messages in response to a message from user U 4 .
User U 2 sent seven relevant messages and two controversial messages in response to a message from user U 4 .
User U 3 sent four relevant messages and one message with offtopic user U 8 .
User U 4 posted two controversial posts.
User U 5 posted one relevant message.
User U 6 has posted three relevant messages.
User U 7 has posted two relevant messages.
User U 8 has posted three messages: the first two offtopic, one controversial.
The overall measure of user conflict U 4 is larger than U 8 because the second one published its posts after a large number of relevant messages from other users. Thus, this situation showed a higher measure of conflict.
Let's apply the k-means algorithm, which will split users into two groups:

U users 1 ; U 2 ; U 3 ; are not classified as "trolls", despite some of their posts, since they also published relevant posts.
“Trolling” in the network is unambiguously defined as a negative and in some way even destructive phenomenon, leading to the complication of receiving information by users. In many modern online communities there are rating systems of self-regulation, but none of them still do without moderation. That in itself leads to increased costs for community owners. Small resources are mostly managed on their own, large ones are required to maintain specialists.
This article proposes a new synthesized approach to determining the quality of the user according to the nature of the messages published by him. At the moment, the authors have developed a method of searching for unscrupulous users of one branch of discussion (thread), but they are planning to expand its work within the whole community.
When writing a topic, I was forced to miss part of the description of the heavyweight device, to make the article not only useful, but also readable. Since no one has yet canceled the links, those interested in the topic can fill this simplification by themselves.
Unfortunately, within the framework of one article it is impossible to grasp the immensity, since this topic is very extensive and, if elaborated in detail, draws at least a candidate one. If this method manages to be screwed to the karmaformula of any community, there are prospects for getting rid of the tedious duty of wool comments,because the UFO will arrive and publish this post here .
In this paper, the differences between the "trolls" and other users were highlighted manually, for practical use this option is not suitable. It is clear that the process can be automated, at least according to the estimated comments. An attempt to implement the algorithm on the example of Habr was not crowned with success, mainly due to the fact that jammed comments overwhelms UFOs.
Work in this direction will continue.
Additional information on clustering on Habré: "Clustering: k-means and c-means algorithms" .
In general, this is a short translation of an article posted on the website of Cornell University , with some of my inserts.
annotation
The Internet has become more important in the lives of people since the advent of Web 2.0 . The interaction between users gave them the opportunity to freely share information through social networks, forums, blogs, wikis-like sites and other interactive shared media resources.')
On the other hand, there are all the flaws in the concept of the second web. Content orientation has become the most important plus and minus of the network at the same time. Questions of reliability and reliability of information in full growth are facing the owners and users of interactive communities. As in real life, in the process of communication through the network, sometimes there are situations when some users violate the rules of generally accepted “network” etiquette . In fact, in order to preserve the normal atmosphere of the resource, the owners are forced to introduce artificial rules of interaction and to monitor their observance.
One of these obvious violations is trolling.
“Trolling” is an injection by a participant of communication (“troll”) of anger, conflict by implicitly or openly tearing, belittling, insulting another participant or participants, often with violation of the site’s rules and, sometimes unconsciously, for the “troll” itself, of network ethics. It is expressed in the form of aggressive, mocking and offensive behavior. It is used as personalized participants interested in greater recognition, publicity, shocking, and anonymous users without the possibility of their identification. In the particular case of "trolling" - provocation of the "victim" in order to draw attention to themselves.
This article proposes a new approach for calculating intruders. This method is based on a measure of conflict of trust functions between different messages in the discussion thread. To demonstrate the consistency of the approach we will test it on artificial data.
Recently, the ways of obtaining information have shifted significantly towards accelerating, facilitating and reducing labor costs. In fact, thanks to the Internet, research of a particular topic has been reduced to a simple click of the mouse button. Although some issues are difficult to find a satisfactory answer with the help of traditional search engines. Instead, we prefer to get an expert opinion.
As a result, such a tool of information interaction as the question-answer community (hereinafter referred to as Q & AC ) has become widespread. Such systems allow each user to contribute to the development of the community. Unfortunately, not all messages are reliable: some users pretend to be experts, while others publish useless messages. Therefore, a very important process is the work of the moderators of these communities. Most often, the increase in "junk" messages - the result of the "trolls".
- Q & AC: a quick overview
A. Q & AC Users
Users are the main characters of Q & AC. Conventionally, they can be divided into: "experts", "students" and "trolls".
Experts: users with knowledge or skills in a particular area.
Students: Users trying to gain information or experience.
Trolls: people trying by any means to disturb the peace of the community. Their goal is to create counterproductive discussions.
B. Identifying sources in Q & AC
Many studies have already tried to evaluate the sources of information in the communities.
Some propose user assessment models based on the number of the best user responses. The best answer here is determined by the polling user or the voting method.
In other authors focus on the choice of questions selected by the user to answer. Experts always prefer to answer questions that are more competent.
Some authors propose complex structures based on the cognitive and behavioral criteria of users to evaluate not only the reliability, but also the experience of information providers.
B. Uncertainty in Q & AC
When dealing with the information supplied by people, we are confronted with several levels of uncertainty. There are three levels of uncertainty for Q & AC. The first is associated with the extraction and integration of uncertainty, the second with information sources of uncertainty, the third with the very essence of information. In our case, we are more interested in the assessment of sources and part of the uncertainty associated with this. Indeed, in the network, when we encounter other users (ie, information sources), we almost never possess a priori knowledge of them.
- Mathematical apparatus
One of the mathematical tools for modeling and processing inaccurate (interval) expert assessments, measurements or observations is the theory of trust functions .
The theory of trust functions or the Dempster – Schaefer theory uses mathematical objects called “trust functions”. Usually their main goal is to model the degree of trust of a certain subject to something. At the same time, the literature contains a large number of interpretations of “trust functions” that can be used in various applied tasks.
The approach proposed in the article assumes the use of this theory in conjunction with the introduction of a quantity that determines the conflict between two combined trust functions.
Let us proceed to the description of the method.
One of the important assumptions suggests that "trolls" are integrated only into popular branches of the discussion. We divide the further description of the method into three steps.
1. Custom messages
Researchers offer the main characteristics of "trolls": aggression, deception, breaking the rules, success. Also indicate such behavioral characteristics as, disregard for moral norms, obvious sadistic and psychopathic inclinations. In the context of this work, the researchers distinguished between trolls and other users manually from messages. Based on this, messages can be: relevant, offtopic, nonsense or swearing. We define the framework characterizing the message:
The nature of the message is determined by the published question or topic. At this stage, we assume that the method uniquely determines the nature of each message.
2. User conflict
Detection of irrelevant messages still does not give a definite answer to the question of the user's belonging to the trolls cohort. A user can only get caught up with and responding to podchevki. In addition, the subject matter may gradually change. In fact, in order to distinguish a “troll” from other users, we need to quantify how much this user conflicts with others. The proposed approach and involves measuring the magnitude of the conflict between the messages of each user.
- Conf msg / U : a measure of the conflict between the k th message of the user U i and the messages written by each other user U j .
- Conf msg : a measure of the conflict between the k th message of user U i and all messages written by all other users of U based on a weighted average. This value takes into account the number of messages written by each user in order to determine the level of conflict, especially between the "trolls" and experts.
- Conf user : a general measure of user conflict U i
The magnitude of the cumulative conflict of the user may increase when he embarks on an endless debate with the "troll." In this case, the user becomes a victim, and the moderators have to control the behavior of users in many threads.
3. Clustering users
The last step is to classify users according to their conflict measures into two groups. The authors have provided for the partitioning of users into groups using the algorithm K-means .
The k-means algorithm is a simple repetitive clustering algorithm that divides a specific data set into a user-defined number of clusters, k . The algorithm is simple to implement and run, relatively fast, easily adaptable and common. This is historically one of the most important data mining algorithms.
In our case, the number of clusters: k = 2 .
As a result of the algorithm, all users will be divided into two clusters. "Trolls" will fall into the group with the greatest measure of conflict, and good users - with the least measure of conflict.
- Example
Consider the following example:
Take one of the discussion threads, containing thirty-one messages written by eight users. The overall measure of each user's conflict, expressed through equation [4], is shown in the figure below.
User U 1 sent three relevant and two disputed messages in response to a message from user U 4 .
User U 2 sent seven relevant messages and two controversial messages in response to a message from user U 4 .
User U 3 sent four relevant messages and one message with offtopic user U 8 .
User U 4 posted two controversial posts.
User U 5 posted one relevant message.
User U 6 has posted three relevant messages.
User U 7 has posted two relevant messages.
User U 8 has posted three messages: the first two offtopic, one controversial.
The overall measure of user conflict U 4 is larger than U 8 because the second one published its posts after a large number of relevant messages from other users. Thus, this situation showed a higher measure of conflict.
Let's apply the k-means algorithm, which will split users into two groups:
U users 1 ; U 2 ; U 3 ; are not classified as "trolls", despite some of their posts, since they also published relevant posts.
- Findings
“Trolling” in the network is unambiguously defined as a negative and in some way even destructive phenomenon, leading to the complication of receiving information by users. In many modern online communities there are rating systems of self-regulation, but none of them still do without moderation. That in itself leads to increased costs for community owners. Small resources are mostly managed on their own, large ones are required to maintain specialists.
This article proposes a new synthesized approach to determining the quality of the user according to the nature of the messages published by him. At the moment, the authors have developed a method of searching for unscrupulous users of one branch of discussion (thread), but they are planning to expand its work within the whole community.
When writing a topic, I was forced to miss part of the description of the heavyweight device, to make the article not only useful, but also readable. Since no one has yet canceled the links, those interested in the topic can fill this simplification by themselves.
Unfortunately, within the framework of one article it is impossible to grasp the immensity, since this topic is very extensive and, if elaborated in detail, draws at least a candidate one. If this method manages to be screwed to the karmaformula of any community, there are prospects for getting rid of the tedious duty of wool comments,
Not performed:
In this paper, the differences between the "trolls" and other users were highlighted manually, for practical use this option is not suitable. It is clear that the process can be automated, at least according to the estimated comments. An attempt to implement the algorithm on the example of Habr was not crowned with success, mainly due to the fact that jammed comments overwhelms UFOs.
Work in this direction will continue.
Additional information on clustering on Habré: "Clustering: k-means and c-means algorithms" .
Source: https://habr.com/ru/post/284052/
All Articles