We compile an audiobook base for easy filtering.
Hello! Surely many of you are familiar with the problem of tired eyes due to long work at the computer. Unfortunately, because of this, you have to limit yourself to other activities. One of them is reading books. In this regard, I have been listening to audiobooks for almost 5 years now almost every day. During this time, I learned in parallel to do something and delve into the essence of voice acting. Now I even listen to books in the gym! Imagine how convenient it is: an hour's journey on foot to and from + a half hour of exercise. The average book in the area of 10-15 hours of recording.
Over time, more and more often there was a problem of choosing the material. After all, the reader plays a rather big role. Often there is a situation when someone advises a book (or in the same article on the habre in the reading room), but the audio version is not corny. I tried to solve all these problems with a separate site. Now there are a couple of quite large and well-known audiobooks where you can listen to them directly online. Such sites have a rather weak book filter. And, in fact, are purely a directory.

')
For all the time, I noticed that the root tracker is one of the largest repositories of audio books. If a book exists in this format, then it is almost certainly in handouts. Many readers even manually make releases of torrents. The first task was the complete synchronization of all available audiobooks from the roottracker.
The next goal was to create a broad filter for the selection of the book. Convenient filters will help change the approach to the choice of books. If earlier you simply found an option for yourself, and then searched for its audiobook (which could not be), then now you exclude the first item and search in the database for as much as possible all existing books. Specifically, now I managed to make the following set of filters:
So, the first point is the analysis of rutraker publications and the formation of the base. For storage I chose MongoDB. First, ideally for a heap of not particularly related data, and second, ideally proved to be in terms of performance. In general, it’s very simple to develop a website with a simple “forwarding” json from UI to the base and takes minimal time. By the way, in MongoDB 3.2 added the left outer join.
The main difficulty was the unification of information. Rutreker, though, forces him to arrange distributions (for which he thanks), but all the same for 10 years (exactly so much time has passed since the publication of the first audiobook), the format is different. I had to open different sections at random and collect possible options.
The parser script is written in Python, the mechanize library is used to emulate the browser, and the BeautifulSoup is used to work with the DOM.
A method that returns an object that maximizes the behavior of a regular browser. The second method receives the browser object, authorizes on the root-tracker and returns this very object, within which the authorization cookies are already stored.
By itself, data collection looks like a set of regular expressions in different variations:
It is very important to use BULK queries in mongo, so that the parser does not load the base inserts with single inserts. Fortunately, all this is done very simply:
The slug field is generated by the slugify package (pip install slugify).
Here is a list of all the fields for each of the books, which I eventually collected:
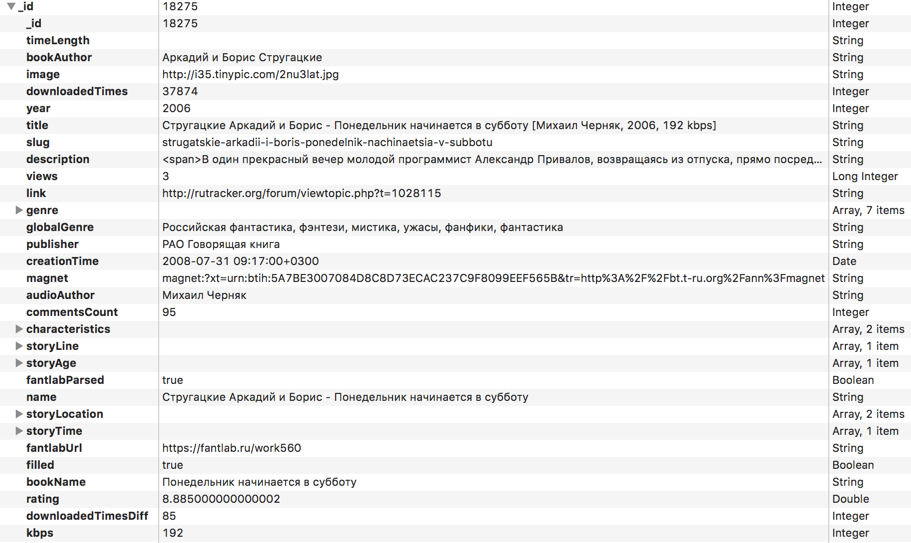
Immediately, we do not forget to create an index for all fields that will be sorted or filtered:

This will slow down the insertion time, but will greatly speed the selection. Database synchronization occurs once a day, so the second option for the site is preferable.
Data loading occurs on all sub-forums audiobooks:
We downloaded the data, but there is a problem: there is no accuracy in the specified data. Someone will write “V. Gerasimov ", someone" Vyacheslav Gerasimov. " In one place will indicate the full or alternative title of the work. Also, the question arose in obtaining an independent evaluation of the work. Googled a couple of book titles and looked at issuing the first sites. One of them turned out to be fantlab.ru, which builds a rating by the votes of users, has a rather impressive database of books, contains a full description of the genre and subgenres of books, the exact name of the author and the work.
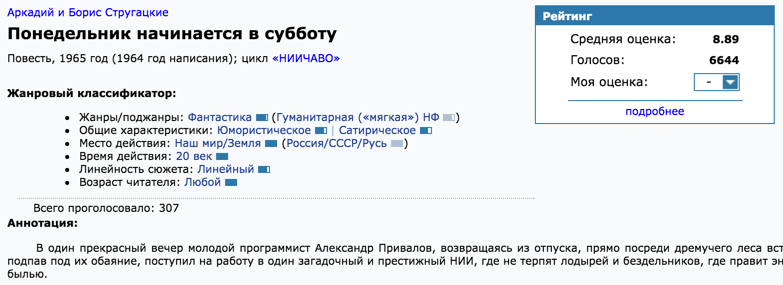
Absolutely all the information from the screenshot is parsed and entered into the database. All fields are manually checked by members of the fantlab community. Everything is perfect, but there is one problem: how to link distribution with a rutreker and a specific record with fantlab? In the distributions do not indicate separately the name of the work. Sometimes even the author is incorrectly written (or not indicated). In fact, a complete source of information is the title. All the pain can be seen in the following screenshot distributions:

Needless to say, even excluding all the text in angle brackets, the built-in search for fantlab does not cope and does not find anything. I found a way out, though not quite elegant: phantomjs (selenium) + google.
I have quite a few projects using this bundle, so the customized headless browser and basic scripts for selenium were ready for use. In fact, I took the title from the rutracker, added the prefix "fantlab" to it and googled it. The first result, which was matched to the address of the work, was parsed. I’ll leave a couple of comments about phantomjs: memory flows very strongly. I have long done for myself a couple of "crutches" that allow the process to live for months on the server and not fall due to lack of memory:
This function is performed at the time of the request of a resource and checks it by the mask of media files. All images and videos are excluded. Those. they are not even loaded into memory. The second function forcibly resets the cache. You need to call on the timer once in ~ hour:
Open Google and drive any text into the search field to change the UI (to get the result of the issue). All further requests will occur on the same page.
Since the requests are all ayaksovye, we need to manually check the fact of loading. In selenium, there are some methods for this that wait until a certain element appears on the page.
The next step: bringing to one type all the names of the authors and all genres. In some distributions they wrote “horror”, in others “horrors”. This is where the pymorphy2 library came to the rescue: it allows you to get the initial form of the word.
We could also come up with something with the authors of the pymorphy2 library: break into words, check the occurrences of words and their coincidence. But then I remembered the point about the global search for everything in all fields. This will be the solution. For full-text search took sphinx. It is not directly friendly with mongodb, so you need to write a script that will throw out xml with the data according to the specified scheme.
Parameters in sphinx.conf:
And the command: indexer bookaudio --rotate
How to use search to unify the fields? We take a list of all authors of the books, and add the same entries. It turns out something like:
What is used as often as possible is probably the most correct form. We take top entries and do a global search on all authors.
All similar entries (including “V. Gerasimov”, for example) will be replaced with the most used forms.
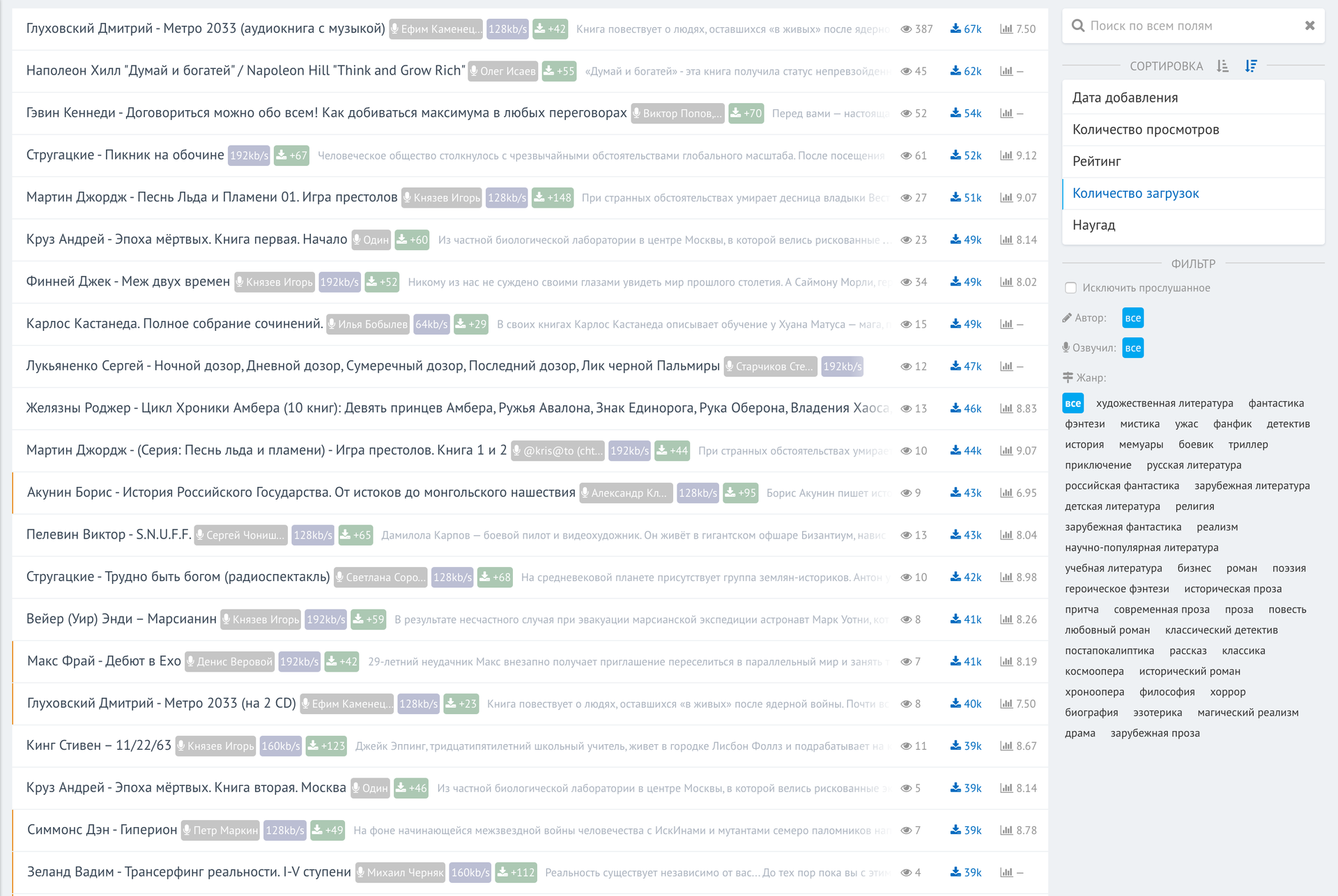
Writing a web interface for all this does not carry any technical complexity. In fact, this is an add-on for access to the database. Here's what I got. The list of the most downloaded audiobooks in the entire tracker history:
And work with filters:
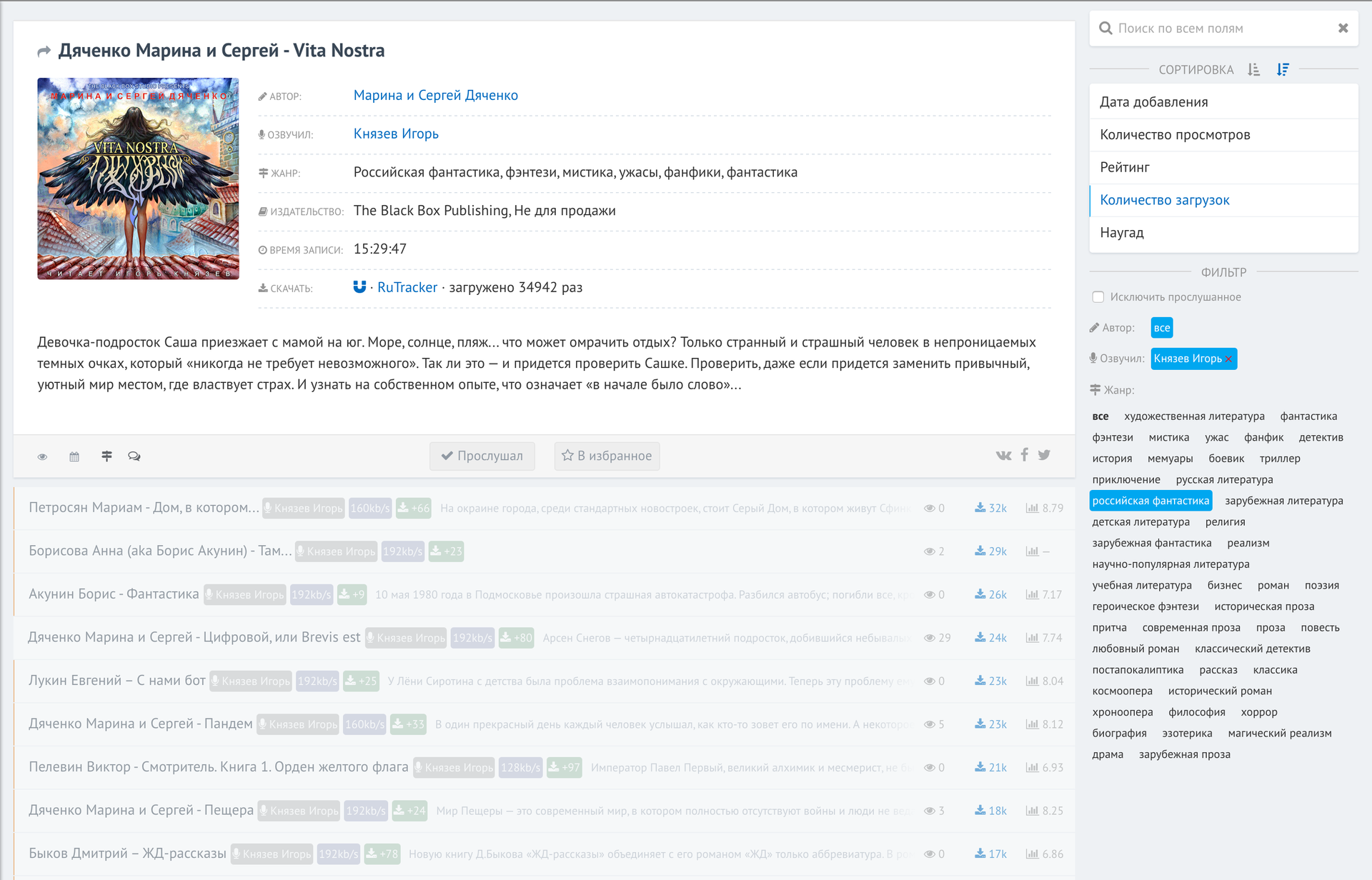
As you can see, I wanted to see all the books sounded by Igor Knyazev by the genre of “Russian fiction”, sorted by the number of downloads on the rutracker (the most downloaded ones at the top).
A space or by clicking on the cards below reveals information about the book. Thanks to mongodb, all filters are processed instantly in a database of 30k books.
Not everything is perfect: the base is not always accurate, the interface can be improved. Filter by genre needs to be translated into a tree structure. All this work for 3 days and for personal use and selection of books is enough for me. Would you use this service?
Over time, more and more often there was a problem of choosing the material. After all, the reader plays a rather big role. Often there is a situation when someone advises a book (or in the same article on the habre in the reading room), but the audio version is not corny. I tried to solve all these problems with a separate site. Now there are a couple of quite large and well-known audiobooks where you can listen to them directly online. Such sites have a rather weak book filter. And, in fact, are purely a directory.
')
A source of information
For all the time, I noticed that the root tracker is one of the largest repositories of audio books. If a book exists in this format, then it is almost certainly in handouts. Many readers even manually make releases of torrents. The first task was the complete synchronization of all available audiobooks from the roottracker.
Book selection
The next goal was to create a broad filter for the selection of the book. Convenient filters will help change the approach to the choice of books. If earlier you simply found an option for yourself, and then searched for its audiobook (which could not be), then now you exclude the first item and search in the database for as much as possible all existing books. Specifically, now I managed to make the following set of filters:
- Semantic global search in the entire database for all text fields
- Sorting (asc / desc) by date of torrent creation, number of views (on the site), rating (from external sources), number of downloads (according to the rutracker), and at random
- Filter by author of work, author of voice acting, genres, and the ability to exclude books that you have marked as “read”
- Ability to subscribe to authors of books or voice. Yes Yes! You can choose the artist you like and subscribe to all his updates. For example, I monitor all the books of Igor Knyazev
Rutracker base
So, the first point is the analysis of rutraker publications and the formation of the base. For storage I chose MongoDB. First, ideally for a heap of not particularly related data, and second, ideally proved to be in terms of performance. In general, it’s very simple to develop a website with a simple “forwarding” json from UI to the base and takes minimal time. By the way, in MongoDB 3.2 added the left outer join.
The main difficulty was the unification of information. Rutreker, though, forces him to arrange distributions (for which he thanks), but all the same for 10 years (exactly so much time has passed since the publication of the first audiobook), the format is different. I had to open different sections at random and collect possible options.
The parser script is written in Python, the mechanize library is used to emulate the browser, and the BeautifulSoup is used to work with the DOM.
A method that returns an object that maximizes the behavior of a regular browser. The second method receives the browser object, authorizes on the root-tracker and returns this very object, within which the authorization cookies are already stored.
def getBrowser(): br = mechanize.Browser() cj = cookielib.LWPCookieJar() br.set_cookiejar(cj) br.set_handle_equiv(True) br.set_handle_gzip(True) br.set_handle_redirect(True) br.set_handle_referer(True) br.set_handle_robots(False) br.set_handle_refresh(mechanize._http.HTTPRefreshProcessor(), max_time=1) br.addheaders = [ ('User-agent', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.2327.5 Safari/537.36'), ('Accept', 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8'), ('Accept-Encoding', 'gzip, deflate, sdch'), ('Accept-Language', 'ru,en;q=0.8'), ] return br def rutrackerAuth(): params = {u'login_username': '...', u'login_password': '...', u'login' : ''} data = urllib.urlencode(params) url = 'http://rutracker.org/forum/login.php' browser = getBrowser() browser.open(url, data) return browser By itself, data collection looks like a set of regular expressions in different variations:
yearRegex = r' .*(\d{4}?)' result['year'] = int(re.search(yearRegex, descContent, re.IGNORECASE).group(1)) # , timeData = soupHandle.find('div', {'id' : 'tor-reged'}).find('span').encode_contents() import locale locale.setlocale(locale.LC_ALL, 'ru_RU.UTF-8') result['creationTime'] = datetime.datetime.strptime(timeData, u'[ %d-%b-%y %H:%M ]') It is very important to use BULK queries in mongo, so that the parser does not load the base inserts with single inserts. Fortunately, all this is done very simply:
BULK = tableHandle.initialize_unordered_bulk_op() # ... BULK.find({'_id' : book['_id']}).upsert().update({'$set' : result}) BULK.execute() The slug field is generated by the slugify package (pip install slugify).
Here is a list of all the fields for each of the books, which I eventually collected:
Immediately, we do not forget to create an index for all fields that will be sorted or filtered:
This will slow down the insertion time, but will greatly speed the selection. Database synchronization occurs once a day, so the second option for the site is preferable.
Data loading occurs on all sub-forums audiobooks:
forums = [ {'id' : '1036'}, {'id' : '400'}, {'id' : '574'}, {'id' : '2387'}, {'id' : '2388'}, {'id' : '695'}, {'id' : '399'}, {'id' : '402'}, {'id' : '490'}, {'id' : '499'}, {'id' : '2325'}, {'id' : '2342'}, {'id' : '530'}, {'id' : '2152'}, {'id' : '403'}, {'id' : '716'}, {'id' : '2165'} ] for i in xrange(pagesCount): url = 'http://rutracker.org/forum/viewforum.php?f='+forum['id']+'&start=' + str(i*50) + '&sort=2&order=1' Base normalization
We downloaded the data, but there is a problem: there is no accuracy in the specified data. Someone will write “V. Gerasimov ", someone" Vyacheslav Gerasimov. " In one place will indicate the full or alternative title of the work. Also, the question arose in obtaining an independent evaluation of the work. Googled a couple of book titles and looked at issuing the first sites. One of them turned out to be fantlab.ru, which builds a rating by the votes of users, has a rather impressive database of books, contains a full description of the genre and subgenres of books, the exact name of the author and the work.
The name of the author, the name of the book
Absolutely all the information from the screenshot is parsed and entered into the database. All fields are manually checked by members of the fantlab community. Everything is perfect, but there is one problem: how to link distribution with a rutreker and a specific record with fantlab? In the distributions do not indicate separately the name of the work. Sometimes even the author is incorrectly written (or not indicated). In fact, a complete source of information is the title. All the pain can be seen in the following screenshot distributions:
Needless to say, even excluding all the text in angle brackets, the built-in search for fantlab does not cope and does not find anything. I found a way out, though not quite elegant: phantomjs (selenium) + google.
I have quite a few projects using this bundle, so the customized headless browser and basic scripts for selenium were ready for use. In fact, I took the title from the rutracker, added the prefix "fantlab" to it and googled it. The first result, which was matched to the address of the work, was parsed. I’ll leave a couple of comments about phantomjs: memory flows very strongly. I have long done for myself a couple of "crutches" that allow the process to live for months on the server and not fall due to lack of memory:
def resourceRequestedLogic(self): driver.execute('executePhantomScript', {'script': ''' var page = this; page.onResourceRequested = function(request, networkRequest) { if (/\.(jpg|jpeg|png|gif|tif|tiff|mov|css)/i.test(request.url)) { //console.log('Final with css! Suppressing image: ' + request.url); networkRequest.abort(); return; } } ''', 'args': []}) This function is performed at the time of the request of a resource and checks it by the mask of media files. All images and videos are excluded. Those. they are not even loaded into memory. The second function forcibly resets the cache. You need to call on the timer once in ~ hour:
def clearDriverCache(self): driver.execute('executePhantomScript', {'script': ''' var page = this; page.clearMemoryCache(); ''', 'args': []}) Open Google and drive any text into the search field to change the UI (to get the result of the issue). All further requests will occur on the same page.
driver.get('http://google.ru') driver.find_element_by_css_selector('input[type="text"]').send_keys(u" fantlab") driver.find_element_by_css_selector('button').click() Since the requests are all ayaksovye, we need to manually check the fact of loading. In selenium, there are some methods for this that wait until a certain element appears on the page.
count = 0 while True: count += 1 time.sleep(0.25) if count >= 3: break try: link = driver.find_element_by_css_selector('a[href*="fantlab.ru/work"]') if link: return link.get_attribute('href') except: continue Genres
The next step: bringing to one type all the names of the authors and all genres. In some distributions they wrote “horror”, in others “horrors”. This is where the pymorphy2 library came to the rescue: it allows you to get the initial form of the word.
# fullGenre = fullGenre.replace('/', ',').replace(';', ',').replace('--', '-').replace(u'', u'') fullGenre = re.sub(r'[\.|"«»]', '',fullGenre) fullGenre = re.sub(r'\[.*?\]', '',fullGenre) # , / allGenres = filter(None, fullGenre.split(',')) allGenres = [item.strip() for item in allGenres] # ( ) allGenres = list(set(allGenres)) insertGenresList = [] for genre in allGenres: # , morphology = morph.parse(genre)[0] genre = morphology.normal_form insertGenresList.append(genre) Authors Names
We could also come up with something with the authors of the pymorphy2 library: break into words, check the occurrences of words and their coincidence. But then I remembered the point about the global search for everything in all fields. This will be the solution. For full-text search took sphinx. It is not directly friendly with mongodb, so you need to write a script that will throw out xml with the data according to the specified scheme.
docset = ET.Element("sphinx:docset") schema = ET.SubElement(docset, "sphinx:schema") # ID , idAttribute = ET.SubElement(schema, "sphinx:attr") idAttribute.set("name", "mongoid") idAttribute.set("type", "int") # , text = ET.SubElement(schema, "sphinx:field") text.set("name", "audioauthor") text = ET.SubElement(schema, "sphinx:field") text.set("name", "bookauthor") text = ET.SubElement(schema, "sphinx:field") text.set("name", "title") text = ET.SubElement(schema, "sphinx:field") text.set("name", "publisher") text = ET.SubElement(schema, "sphinx:field") text.set("name", "description") # id globalIterator = 0 all = bookTable.find() # , xml def safeText(data): data = re.sub('<[^<]+?>', ' ', data) data = "".join([c for c in data if c.isalpha() or c.isdigit() or c==' ']).rstrip() return data for card in all: document = ET.SubElement(docset, "sphinx:document") globalIterator += 1 # id document.set("id", str(globalIterator)) mongoid = ET.SubElement(document, "mongoid") mongoid.text = str(card["_id"]) title = ET.SubElement(document, "audioauthor") title.text = safeText(card["audioAuthor"]) # ... Parameters in sphinx.conf:
source src_bookaudio { type = xmlpipe2 xmlpipe_command = python /path/to/sphinx.py sql_attr_uint = mongoid } index bookaudio { morphology = stem_enru charset_type = utf-8 source = src_bookaudio path = /var/lib/sphinxsearch/data/bookaudio.main } And the command: indexer bookaudio --rotate
How to use search to unify the fields? We take a list of all authors of the books, and add the same entries. It turns out something like:
Vyacheslav Gerasimov - 1324
Igor Knyazev - 432
...
authors = {} for book in allBooks: author = book['audioAuthor'] if author in authors: authors[author] += 1 else: authors[author] = 1 What is used as often as possible is probably the most correct form. We take top entries and do a global search on all authors.
import sphinxapi client = sphinxapi.SphinxClient() client.SetServer('localhost', 9312) client.SetMatchMode(sphinxapi.SPH_MATCH_ALL) client.SetLimits(0, 10000, 10000) import operator sorted_x = reversed(sorted(authors.items(), key=operator.itemgetter(1))) counter = 0 for i in sorted_x: print i[0].encode('utf-8'), print ' - ' + str(i[1]) searchData = client.Query(i[0], 'bookaudio') for match in searchData['matches']: mongoId = int(match['attrs']['mongoid']) BULK.find({'_id' : mongoId}).upsert().update({'$set' : {'audioAuthor' : i[0]}}) All similar entries (including “V. Gerasimov”, for example) will be replaced with the most used forms.
Interface
Writing a web interface for all this does not carry any technical complexity. In fact, this is an add-on for access to the database. Here's what I got. The list of the most downloaded audiobooks in the entire tracker history:
And work with filters:
As you can see, I wanted to see all the books sounded by Igor Knyazev by the genre of “Russian fiction”, sorted by the number of downloads on the rutracker (the most downloaded ones at the top).
A space or by clicking on the cards below reveals information about the book. Thanks to mongodb, all filters are processed instantly in a database of 30k books.
Completion
Not everything is perfect: the base is not always accurate, the interface can be improved. Filter by genre needs to be translated into a tree structure. All this work for 3 days and for personal use and selection of books is enough for me. Would you use this service?
Source: https://habr.com/ru/post/283538/
All Articles