Veeam Backup & Replication: workaround for one problem with backup job metadata
Disclaimer practically
When writing this text, the author was guided by the following key points:
0. To a large number of respected highly experienced colleagues, all this will seem petty and not worthy of attention. Facil omnes, cum valemus, recta consilia aegrotis damus.
1. Some - albeit a small - number of respected less experienced colleagues will be useful / necessary / interesting.
2. Hints of a device for maintaining the patient's body weight while standing and walking have the right to exist, since it is therefore workaround and workaround.
3. Google does not know or I was looking bad. But honestly tried.
4. Experience in writing something like the first, hence the lumps in the texture.
Greetings, dear community.
Preamble
')
In the infrastructure of our company there are three parallel branches of servers Veeam B & R. Branches, as we like to explain almost any incidents, "historically".
One maintains backup jobs that slowly reduce the virtualization farm left after the merger.
The second was the pilot-industrial implementation of Veeam B & R, which has gradually become an industrial solution, and currently maintains the backup and replication job of the vSphere 4.1 virtualization farm (yes, still in use, sorry) and the backup job of the vSphere 5.5 virtualization farm.
The third service exclusively replication job 'and failover planes of the vSphere 5.5 virtualization farm.
All of this is in the process of living and incessant migration.
The honor and happiness of administering all this wealth over the past ~ 5 years has been my main administrator of VMware vSphere virtualization, Veeam B & R and Wintel servers.
+ There is a colleague in the role of administrator spare.
During the recent preparation for testing a DR solution based on virtual server replication using Veeam B & R, we found an incomprehensible discrepancy between the number of virtual servers included in the backup and replication jobs and information on the number of recovery points for these servers.
Information about the number of points was obtained through powershell using Veeam Backup & Replication Powershell snapin.
Selective verification of the number of points by a request through the web interface Veeam Backup Enterprise Manager showed a similar discrepancy with reality.
Not that it is very difficult to live or have a significant impact. But in some cases it could lead to wrong conclusions - for example, using Powershell scripts to collect statistical data, we would gasify a small body of water and for a long time could not notice.
Yes, and worries, itching - well, not neatly. Need to fix it.
The backup administrator is currently training with the Veeam TP on an open case, investigating the problem as part of the replication job.
I decided to delve into the part of the backup job'ov on another branch of Veeam B & R so as not to distort the picture investigated by the vendor's TP.
The moment of occurrence of discrepancies and their causes are not yet clear to us. With an accurate response from the TP Veeam will make an update to the text.
So far I have accepted the working hypothesis for myself that repeated in-place upgrades of the Veeam B & R from version 7 to the current version 9 update 1, repeated changes to the settings of existing jobs, etc. the processes were not in vain and, presumably, the Veeam B & R DB accumulated “garbage”, duplicate records in the tables.
MS SQL is used as a DBMS, theoretically it is possible to dig into the structure of the database, but, paraphrasing Aramis, "... but, really, I'm not a DBA ...".
A selective test of the servers in the backup job showed that everything was just as bad with the data on recovery points.
I will give an example:
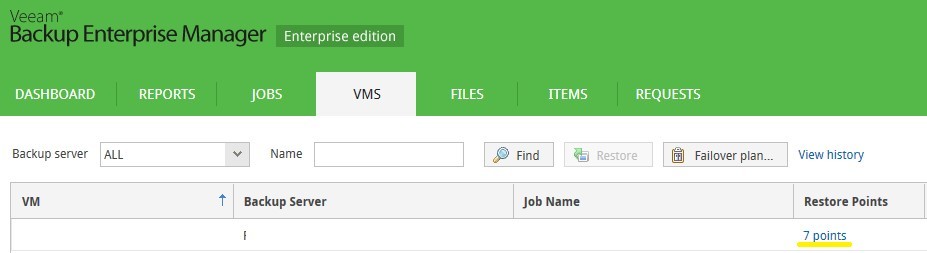
A certain virtual server named imerek is part of the job Veeam Backup & Replication. According to information given by Veeam Backup Enterprise Manager, it has 36 recovery points.

At the same time, the properties of the backup job'a never changed in terms of the number of stored points - i.e. from the moment of creation of the job, in the version of Veeam B & R 7 - and it was always equal to 7 for the job described
The expandable list of 36 restore points looks quite “working” - there are no fails, unaccessible parts, or anything else suggestive ofspoiling the problems with dots:
I did not try to restore virtual machines from points with dates that are clearly beyond the number stored in the properties of the task. Mainly due to lack of time for experiments. Lack of time in general was the decisive factor in finding a way out of the situation - immediately after it was impossible to stop the execution of backup jobs for an indefinite period of time for experiments.
KMK, while trying to restore, would fail, because physically there is 1 full backup, 6 incremental backups and a metadata file in the repository - that is, there are really 7 points, counting from the current day. For May 10, the earliest stored point would have been created on May 3. And everything that was created earlier by dates does not really exist and lives only in the Veeam B & R DB.
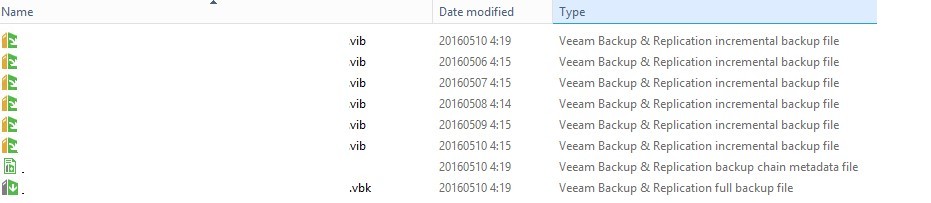
Here is the contents of the repository for the backup job being considered:
Rescan for the repository containing backup files did not give any results, the metadata was not updated.
Most tasks have backup files of such size that there is simply no place to transfer them + N TB archives will be copied for a long time, the task for this time needs to be stopped, and simple backups are unacceptable. Therefore, the option of transferring backup files to another repository followed by rescan repository and map backup in the task settings was not accepted as the best way out. For the same reason, you cannot delete everything, reinstall it, by restoring the settings of Veeam B & R from a regularly created backup.
I had to look for a way to solve the problem in a rather narrow framework, so to speak.
And, if not too elegant, but he was groped.
The algorithm is about the following:
1. In the repository containing backup files, change the extension in the file name
- full backup
- backup chain metadata file
Note. Renaming / transfer to another repository of one backup chain metadata file followed by rescan of the repository does not help.
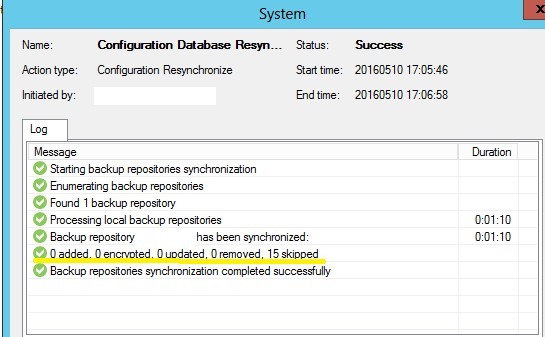
2. Execute Rescan for the repository containing backup files. We see that one backup has been removed from the database.
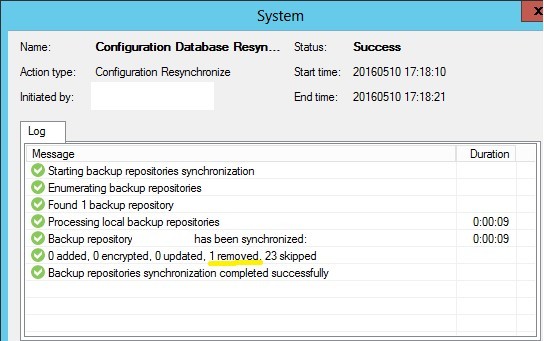
3. We return the extension in the name of the full backup file and the metadata in the repository to the original position.
4. We execute the repeated Rescan for the repository containing the backup files. We see that one backup has been added to the database.
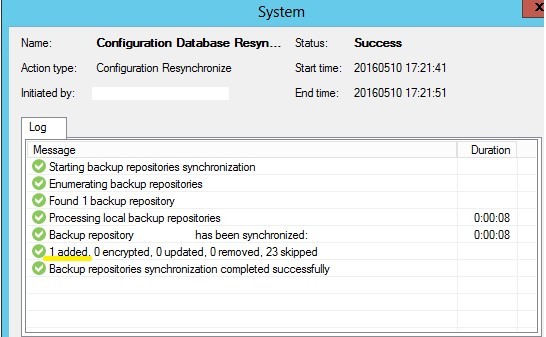
5. We check the virtual server inamerek again and see the number of recovery points corresponding to the settings of the task and the number of files in the repository.
6. In the properties of Job, we perform Map backup to the chain imported in step 4.
I repeat that the decision is far from grace. If the number of jobs is significantly larger from about 70 in my case, I would have to look for another way - from scripts to reinstalling the Veeam B & R server.
It would be nice to poke your nose at not found solutions, kb, opinions, suggestions, etc. - fas est et ab hoste doceri.
When writing this text, the author was guided by the following key points:
0. To a large number of respected highly experienced colleagues, all this will seem petty and not worthy of attention. Facil omnes, cum valemus, recta consilia aegrotis damus.
1. Some - albeit a small - number of respected less experienced colleagues will be useful / necessary / interesting.
2. Hints of a device for maintaining the patient's body weight while standing and walking have the right to exist, since it is therefore workaround and workaround.
3. Google does not know or I was looking bad. But honestly tried.
4. Experience in writing something like the first, hence the lumps in the texture.
Greetings, dear community.
Preamble
')
In the infrastructure of our company there are three parallel branches of servers Veeam B & R. Branches, as we like to explain almost any incidents, "historically".
One maintains backup jobs that slowly reduce the virtualization farm left after the merger.
The second was the pilot-industrial implementation of Veeam B & R, which has gradually become an industrial solution, and currently maintains the backup and replication job of the vSphere 4.1 virtualization farm (yes, still in use, sorry) and the backup job of the vSphere 5.5 virtualization farm.
The third service exclusively replication job 'and failover planes of the vSphere 5.5 virtualization farm.
All of this is in the process of living and incessant migration.
The honor and happiness of administering all this wealth over the past ~ 5 years has been my main administrator of VMware vSphere virtualization, Veeam B & R and Wintel servers.
+ There is a colleague in the role of administrator spare.
During the recent preparation for testing a DR solution based on virtual server replication using Veeam B & R, we found an incomprehensible discrepancy between the number of virtual servers included in the backup and replication jobs and information on the number of recovery points for these servers.
Information about the number of points was obtained through powershell using Veeam Backup & Replication Powershell snapin.
Selective verification of the number of points by a request through the web interface Veeam Backup Enterprise Manager showed a similar discrepancy with reality.
Not that it is very difficult to live or have a significant impact. But in some cases it could lead to wrong conclusions - for example, using Powershell scripts to collect statistical data, we would gasify a small body of water and for a long time could not notice.
Yes, and worries, itching - well, not neatly. Need to fix it.
The backup administrator is currently training with the Veeam TP on an open case, investigating the problem as part of the replication job.
I decided to delve into the part of the backup job'ov on another branch of Veeam B & R so as not to distort the picture investigated by the vendor's TP.
The moment of occurrence of discrepancies and their causes are not yet clear to us. With an accurate response from the TP Veeam will make an update to the text.
So far I have accepted the working hypothesis for myself that repeated in-place upgrades of the Veeam B & R from version 7 to the current version 9 update 1, repeated changes to the settings of existing jobs, etc. the processes were not in vain and, presumably, the Veeam B & R DB accumulated “garbage”, duplicate records in the tables.
MS SQL is used as a DBMS, theoretically it is possible to dig into the structure of the database, but, paraphrasing Aramis, "... but, really, I'm not a DBA ...".
A selective test of the servers in the backup job showed that everything was just as bad with the data on recovery points.
I will give an example:
A certain virtual server named imerek is part of the job Veeam Backup & Replication. According to information given by Veeam Backup Enterprise Manager, it has 36 recovery points.
At the same time, the properties of the backup job'a never changed in terms of the number of stored points - i.e. from the moment of creation of the job, in the version of Veeam B & R 7 - and it was always equal to 7 for the job described
The expandable list of 36 restore points looks quite “working” - there are no fails, unaccessible parts, or anything else suggestive of
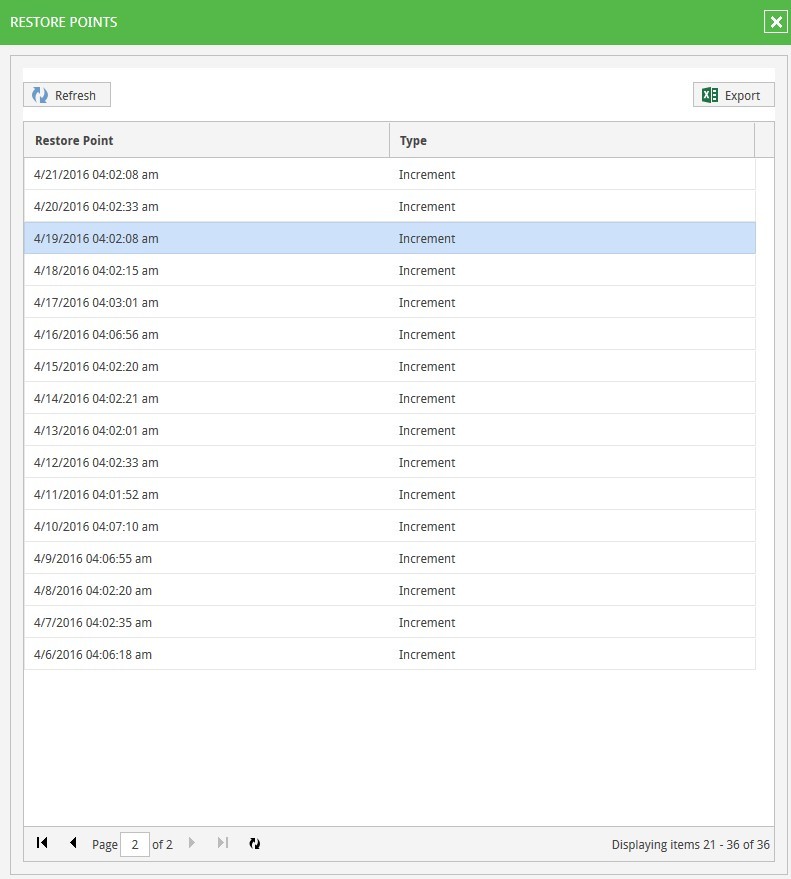 | 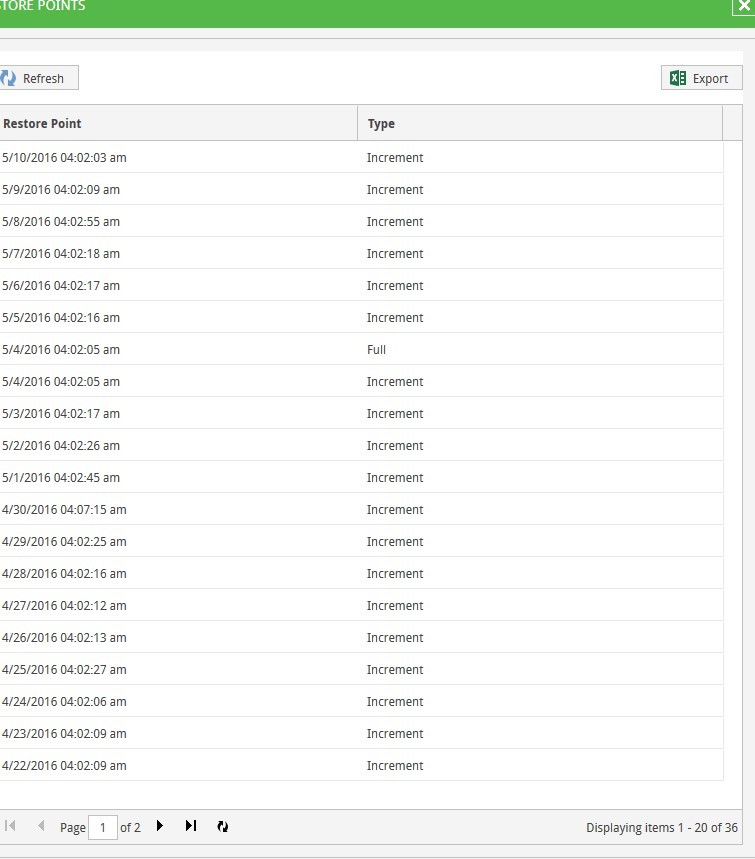 |
I did not try to restore virtual machines from points with dates that are clearly beyond the number stored in the properties of the task. Mainly due to lack of time for experiments. Lack of time in general was the decisive factor in finding a way out of the situation - immediately after it was impossible to stop the execution of backup jobs for an indefinite period of time for experiments.
KMK, while trying to restore, would fail, because physically there is 1 full backup, 6 incremental backups and a metadata file in the repository - that is, there are really 7 points, counting from the current day. For May 10, the earliest stored point would have been created on May 3. And everything that was created earlier by dates does not really exist and lives only in the Veeam B & R DB.
Here is the contents of the repository for the backup job being considered:
Rescan for the repository containing backup files did not give any results, the metadata was not updated.
Most tasks have backup files of such size that there is simply no place to transfer them + N TB archives will be copied for a long time, the task for this time needs to be stopped, and simple backups are unacceptable. Therefore, the option of transferring backup files to another repository followed by rescan repository and map backup in the task settings was not accepted as the best way out. For the same reason, you cannot delete everything, reinstall it, by restoring the settings of Veeam B & R from a regularly created backup.
I had to look for a way to solve the problem in a rather narrow framework, so to speak.
And, if not too elegant, but he was groped.
The algorithm is about the following:
1. In the repository containing backup files, change the extension in the file name
- full backup
- backup chain metadata file
Note. Renaming / transfer to another repository of one backup chain metadata file followed by rescan of the repository does not help.
2. Execute Rescan for the repository containing backup files. We see that one backup has been removed from the database.
3. We return the extension in the name of the full backup file and the metadata in the repository to the original position.
4. We execute the repeated Rescan for the repository containing the backup files. We see that one backup has been added to the database.
5. We check the virtual server inamerek again and see the number of recovery points corresponding to the settings of the task and the number of files in the repository.
6. In the properties of Job, we perform Map backup to the chain imported in step 4.
I repeat that the decision is far from grace. If the number of jobs is significantly larger from about 70 in my case, I would have to look for another way - from scripts to reinstalling the Veeam B & R server.
It would be nice to poke your nose at not found solutions, kb, opinions, suggestions, etc. - fas est et ab hoste doceri.
Source: https://habr.com/ru/post/283276/
All Articles