Taming the elephant or what is HUE
The post will be about how to make work on Hadup a bit more comfortable.

In this article I want to consider one of the components of the Hadoop ecosystem - HUE. We correctly pronounce “Huey” or “HHYUI”, but not others that are consonant with the widely known Russian word, variants.
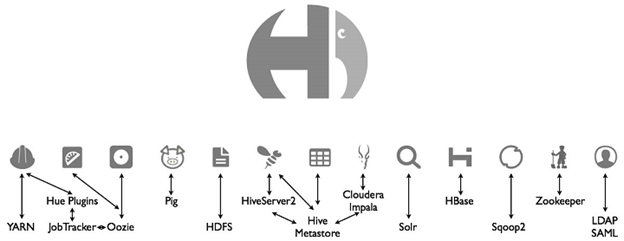
HUE (Hadoop User Experience) is a web interface for analyzing data on Hadoop. At least that is how they position themselves. HUE is an open source project released under the Apache license. Owned by HUE, at the time of writing, Cloudera. It is put on all the most popular Hadup distributions:
')
If you translate the abbreviation HUE, you get something like “Hadup User Experience” or “Hadup User Experience”. And indeed it is. I came to HUE with some experience with Hadup. I worked with Hadup both through the console and through the CDM (cloudera manager). Mostly used frameworks Spark and YARN, as well as just a little bit of Oozie. And over time, I have a couple of ideas / user requirements:
This was my user experience, and it was implemented in HUE. I'll start with the file browser. It is much more convenient than the native of the clooders. You can create / copy / move files and directories from one place in HDFS to another. You can change the access rights and upload files from the local machine to HDFS, and open files of some formats (.txt, .seq) without downloading them to the local machine. Task Scheduler is essentially an automated Oozie. HUE itself creates job.properties and workflow.xml, in general, all the routine work that Oozie had to do with its hands is done by HUE for us! Below I will give a few examples and tell you more about this.
But HUE is not only a file browser and a scheduler (task scheduler), it is a set of applications giving access to almost all cluster modules, as well as a platform for developing applications.
This article will discuss HUE + Oozie, HUE + YARN, HUE + Spark, HUE + HDFS.
To begin, let me remind you that there are 3 main types of tasks in Oozie:

At the top of the screen there is a section Workflows, it has two subsections Dashboards and Editors, and in them, respectively, subsections for each type of task.
Dashbord is monitoring running / spent tasks.
Editor is an Oozie task editor.
Dashbord displays Oozie tasks. Those. if you have a coordinator who starts a workflow (for example, a task running in YARN) at 18.00, and now only at 12 o'clock in the afternoon, then you will not see it in YARN Resource Manager, because only running tasks are displayed there, and in Dashbord it will hang, with the status of Running / Prepare (Running - if the task has already been performed at least once, for example, the coordinator has been hanging since yesterday and yesterday there was a workflow launch; Prepare - if the task has never been completed). The picture below shows a piece of my Dashbord, I think everything is clear on it without additional explanations (black smeared confidential information).

Let's start with the Workflows section. This section displays all available and available for this Workflow user. From here, you can launch, share with other users, copy, delete, import, export and create a workflow, as well as some information about them. Consider the process of creating a new workflow:

In the ACTIONS line, all possible actions on the basis of which you can create a workflow, namely: Hive Script, Hive Server2 Script, Pig Script, Spark program, Java program, Sqoop 1, Map Reduce job, Subworkflow, Shell, Ssh, HDFS fs, Email , Streaming, distcp, kill.
Create a simple workflow that creates a directory in HDFS, while parametrizing it.

Where $ {Dir} is a variable, the value of which will be the directory from which our directory will be created.
$ {Year}, $ {Month}, $ {Day} are also variables, their purpose is clear.
Gray fields have appeared around our action, actions can also be placed in them, so you can get a branched workflow with several outputs, an example of such workflow will be shown later. Also, there were gears in the corners of our action and stop actions. By clicking on these gears, we will go to the settings menu. Each type of action has its own settings, but there is a common set of settings, for example, a sequence. Which action should be taken upon successful completion of the task, which action should the task fail.
If we run our workflow, he will be asked to set the values of the variables. Now let's create a coordinator based on our workflow.
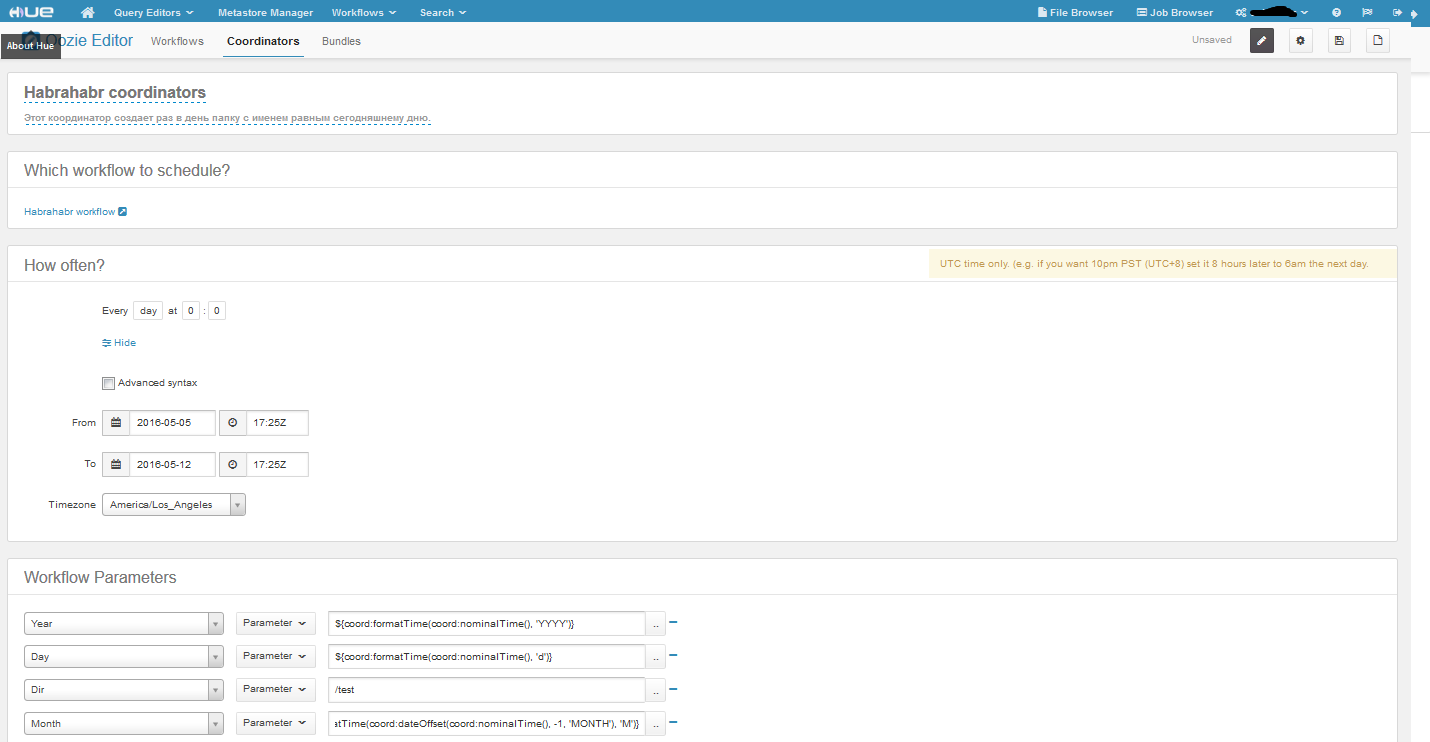
Here is our coordinator. We set the time frame in the appropriate fields, everything is simple, the only feature is that you can run the task in the past. The coordinator has two kinds of time, nominal and actual. Nominal is the one that goes on in time frames, and actual is real time. About what I want to say again, this is about Advanced syntax, by making this checkbox active, it will be possible to set the frequency in crontab format. With frequency everything seems to be. As for the parameters of our workflow, we set them using EL functions (Expression Language Functions). The function specified in the variable year will return the value - 2016, the day - 5, but with the month more interesting - it will return the number of the previous month (the beginning did not fit, but it is the same as the day and year). Well, Dir is a constant. According to the settings, our coordinator runs once a day for a week, which means that we will have 7 folders in HDFS along the path / test / 2016/4 /. This is such a simple example, it has no practical application, but if we change it a bit, for example, if our task does not create folders and delete folders with logs for the previous day / month / year, then there will already be a benefit.
You can create workflows with actions like Java program, MapReduce program and also parameterize them as in the example with the HDFS link. The process of executing the task will be logged, with the logs in the HUE being pulled from the YARN Resource Manager or the History Server. Only they are a little more conveniently structured (this is already a matter of taste, of course). And one more difference from the direct launch of the task on YARN is that a little more resources are spent. Since the Oozie task is first created, the purpose of which will be to call our workflow (Java / MapReduce / Spark task). This Oozie task eats up one core (vcore, not the real core) and 1.5 Gb of RAM per cluster.
This link will be considered on the example of running MapReduce procedures, calling it from a Java program action in a workflow.
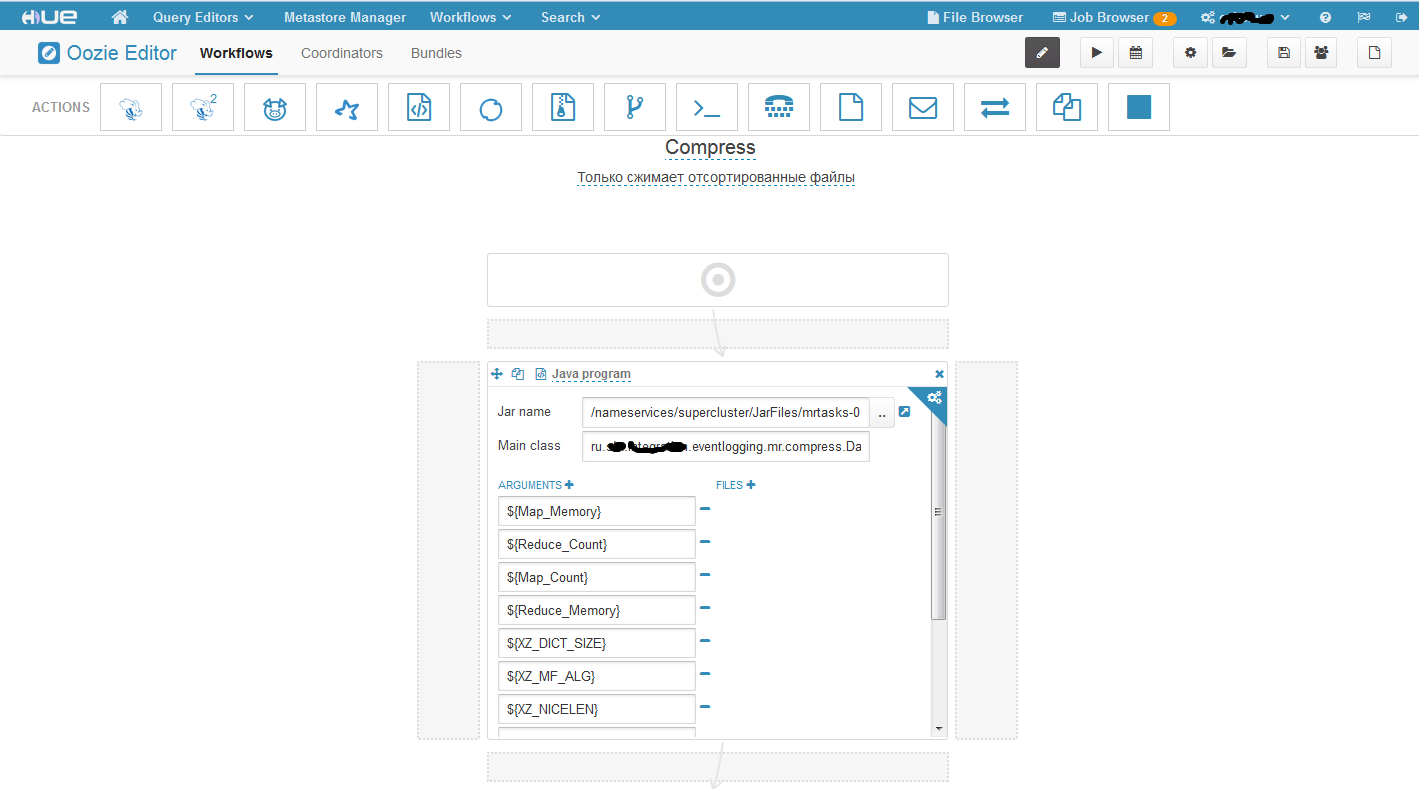
This is what our workflow looks like. In the Jar name field, we specify the path to the executable jar file that we have in HDFS. It is not necessary to duplicate it on all cluster machines; you just need to put it in HDFS. The Main class field is the Main class. Well, then the parameters. In this task, I have parameterized everything, but it is not necessary to parameterize all parameters. It is worth paying one very important point! Some of the parameters that are passed are in the format: -Dname_parameter = value, and some are simply picked up as string arguments of the array. So first you need to set all the parameters of the –D format, and then the string arguments or vice versa. If you move them, he will misunderstand them. For example, at first we set part of the –D format parameters, then the usual ones, and then again –D format, in this case the second part of the –D format parameters will be perceived as string parameters. I had to spend a lot of time before identifying this feature. Now let's create a coordinator based on our workflow.

It is created as in the previous example.
Workflow is created in the same way as the previous example, coordinator is also similar. There is one feature - if you get an error like the main class is not found at startup, but you definitely put your jar file in HDFS, then you need to duplicate the jar file on all machines in the same directories as it is in HDFS.
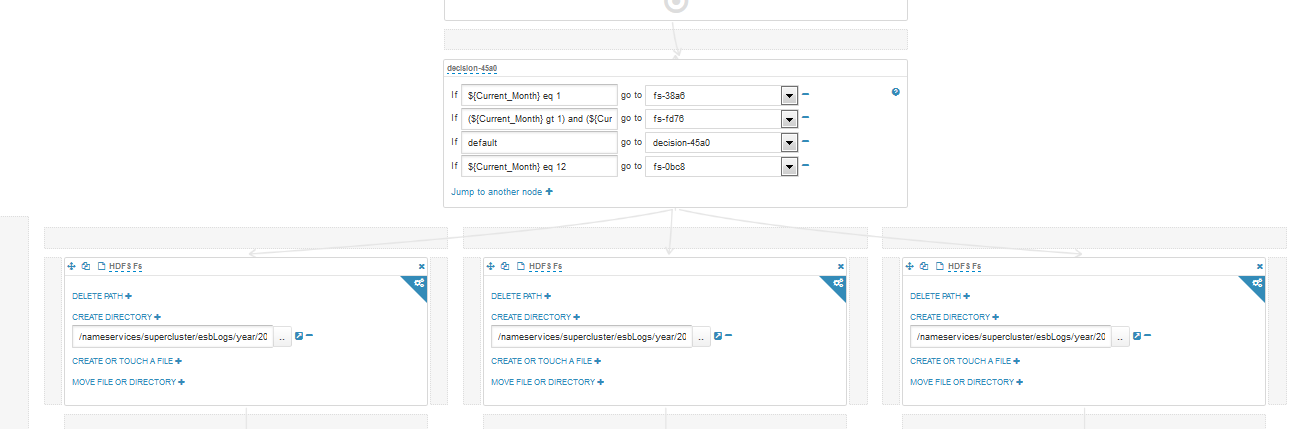
I also want to show branched workflow:
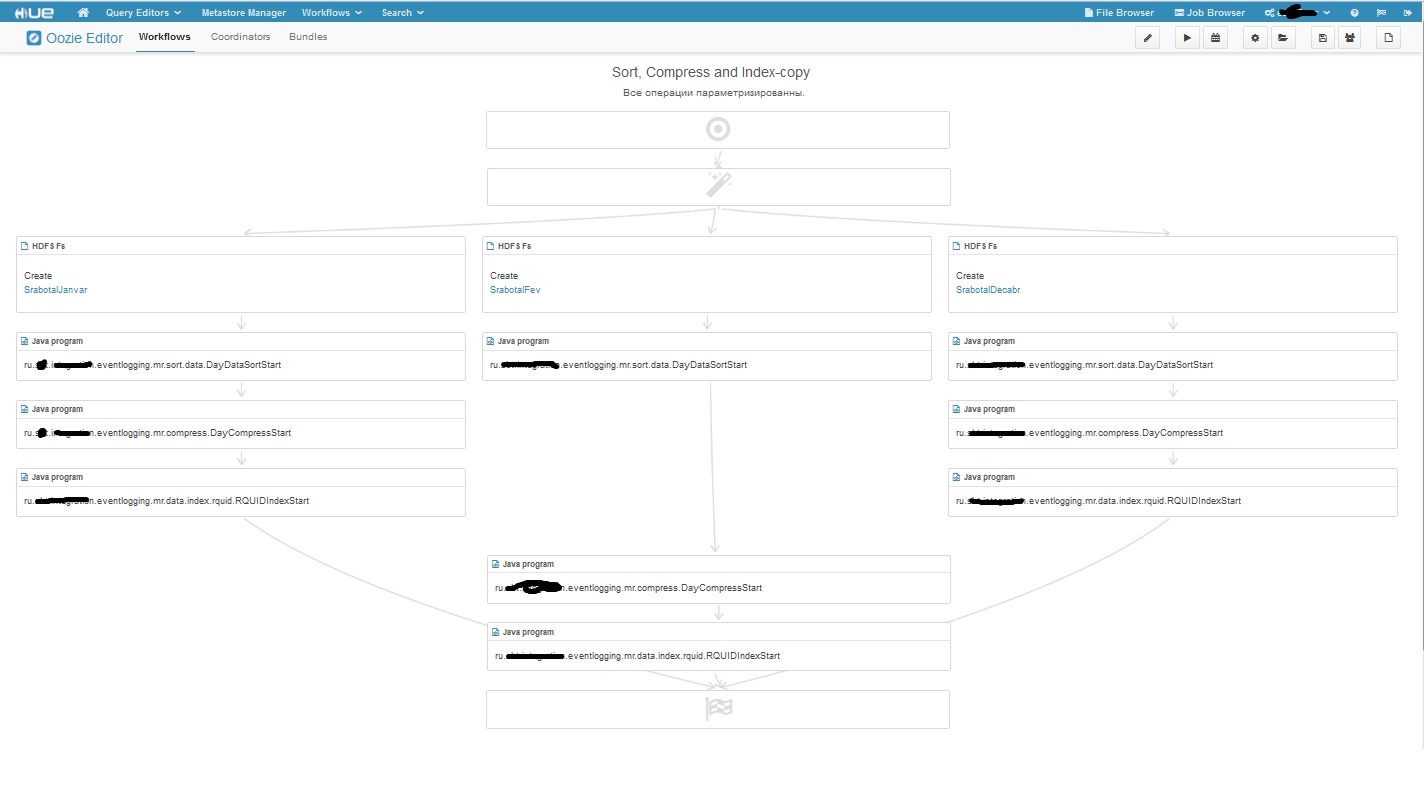
The magic wand at first vorkflow is a solution blog; if we enter edit mode, we will see what the magic wand turns into:
And in the end I will tell…
For me, HUE has made working in the Hadoop ecosystem more comfortable. However, I do not use half of its capabilities. I did not say anything about the other HUE bundles, because either they are quite simple, for example, a bundle with Shell, or I don’t use them and can't say anything about them. I also did not talk about Query Editors, Metastore Manager, Search, since I didn’t work with them either. Thank you for your attention, success in the knowledge of this world.
In this article I want to consider one of the components of the Hadoop ecosystem - HUE. We correctly pronounce “Huey” or “HHYUI”, but not others that are consonant with the widely known Russian word, variants.
HUE (Hadoop User Experience) is a web interface for analyzing data on Hadoop. At least that is how they position themselves. HUE is an open source project released under the Apache license. Owned by HUE, at the time of writing, Cloudera. It is put on all the most popular Hadup distributions:
')
- Pivotal HD 3.0
- Apache bigtop
- HDInsight Hadoop
- MAPR
- Hortonworks Hadoop (HDP)
- Cloudera Hadoop (CDH)
If you translate the abbreviation HUE, you get something like “Hadup User Experience” or “Hadup User Experience”. And indeed it is. I came to HUE with some experience with Hadup. I worked with Hadup both through the console and through the CDM (cloudera manager). Mostly used frameworks Spark and YARN, as well as just a little bit of Oozie. And over time, I have a couple of ideas / user requirements:
- It would be nice to be able to quickly see with what configurations the task was launched in YARN.
- It would be great to have a more functional file browser than the native one from Cloudera (I did not use the Enterprise version).
- It would be AMAZING to have a more convenient, more automated task scheduler than Oozie.
This was my user experience, and it was implemented in HUE. I'll start with the file browser. It is much more convenient than the native of the clooders. You can create / copy / move files and directories from one place in HDFS to another. You can change the access rights and upload files from the local machine to HDFS, and open files of some formats (.txt, .seq) without downloading them to the local machine. Task Scheduler is essentially an automated Oozie. HUE itself creates job.properties and workflow.xml, in general, all the routine work that Oozie had to do with its hands is done by HUE for us! Below I will give a few examples and tell you more about this.
But HUE is not only a file browser and a scheduler (task scheduler), it is a set of applications giving access to almost all cluster modules, as well as a platform for developing applications.
This article will discuss HUE + Oozie, HUE + YARN, HUE + Spark, HUE + HDFS.
HUE + Oozie
To begin, let me remind you that there are 3 main types of tasks in Oozie:
- Workflow is Directed Acyclic Action Graphs (DAGs action). Or, in Russian, this is just some kind of task (Map Reduce task, YARN task, Spark task, task for working with HDFS, etc.);
- The Coordinator is a Workflow, with a specified start time / frequency;
- Bundle is the highest level of abstraction in Oozie. It is a set of Coordinators, not necessarily related to each other (I did not use it, so I can’t say anything special).
At the top of the screen there is a section Workflows, it has two subsections Dashboards and Editors, and in them, respectively, subsections for each type of task.
Dashbord is monitoring running / spent tasks.
Editor is an Oozie task editor.
Dashbord
Dashbord displays Oozie tasks. Those. if you have a coordinator who starts a workflow (for example, a task running in YARN) at 18.00, and now only at 12 o'clock in the afternoon, then you will not see it in YARN Resource Manager, because only running tasks are displayed there, and in Dashbord it will hang, with the status of Running / Prepare (Running - if the task has already been performed at least once, for example, the coordinator has been hanging since yesterday and yesterday there was a workflow launch; Prepare - if the task has never been completed). The picture below shows a piece of my Dashbord, I think everything is clear on it without additional explanations (black smeared confidential information).
Editors
Let's start with the Workflows section. This section displays all available and available for this Workflow user. From here, you can launch, share with other users, copy, delete, import, export and create a workflow, as well as some information about them. Consider the process of creating a new workflow:
In the ACTIONS line, all possible actions on the basis of which you can create a workflow, namely: Hive Script, Hive Server2 Script, Pig Script, Spark program, Java program, Sqoop 1, Map Reduce job, Subworkflow, Shell, Ssh, HDFS fs, Email , Streaming, distcp, kill.
HUE + HDFS
Create a simple workflow that creates a directory in HDFS, while parametrizing it.
Where $ {Dir} is a variable, the value of which will be the directory from which our directory will be created.
$ {Year}, $ {Month}, $ {Day} are also variables, their purpose is clear.
Gray fields have appeared around our action, actions can also be placed in them, so you can get a branched workflow with several outputs, an example of such workflow will be shown later. Also, there were gears in the corners of our action and stop actions. By clicking on these gears, we will go to the settings menu. Each type of action has its own settings, but there is a common set of settings, for example, a sequence. Which action should be taken upon successful completion of the task, which action should the task fail.
If we run our workflow, he will be asked to set the values of the variables. Now let's create a coordinator based on our workflow.
Here is our coordinator. We set the time frame in the appropriate fields, everything is simple, the only feature is that you can run the task in the past. The coordinator has two kinds of time, nominal and actual. Nominal is the one that goes on in time frames, and actual is real time. About what I want to say again, this is about Advanced syntax, by making this checkbox active, it will be possible to set the frequency in crontab format. With frequency everything seems to be. As for the parameters of our workflow, we set them using EL functions (Expression Language Functions). The function specified in the variable year will return the value - 2016, the day - 5, but with the month more interesting - it will return the number of the previous month (the beginning did not fit, but it is the same as the day and year). Well, Dir is a constant. According to the settings, our coordinator runs once a day for a week, which means that we will have 7 folders in HDFS along the path / test / 2016/4 /. This is such a simple example, it has no practical application, but if we change it a bit, for example, if our task does not create folders and delete folders with logs for the previous day / month / year, then there will already be a benefit.
HUE + YARN
You can create workflows with actions like Java program, MapReduce program and also parameterize them as in the example with the HDFS link. The process of executing the task will be logged, with the logs in the HUE being pulled from the YARN Resource Manager or the History Server. Only they are a little more conveniently structured (this is already a matter of taste, of course). And one more difference from the direct launch of the task on YARN is that a little more resources are spent. Since the Oozie task is first created, the purpose of which will be to call our workflow (Java / MapReduce / Spark task). This Oozie task eats up one core (vcore, not the real core) and 1.5 Gb of RAM per cluster.
This link will be considered on the example of running MapReduce procedures, calling it from a Java program action in a workflow.
This is what our workflow looks like. In the Jar name field, we specify the path to the executable jar file that we have in HDFS. It is not necessary to duplicate it on all cluster machines; you just need to put it in HDFS. The Main class field is the Main class. Well, then the parameters. In this task, I have parameterized everything, but it is not necessary to parameterize all parameters. It is worth paying one very important point! Some of the parameters that are passed are in the format: -Dname_parameter = value, and some are simply picked up as string arguments of the array. So first you need to set all the parameters of the –D format, and then the string arguments or vice versa. If you move them, he will misunderstand them. For example, at first we set part of the –D format parameters, then the usual ones, and then again –D format, in this case the second part of the –D format parameters will be perceived as string parameters. I had to spend a lot of time before identifying this feature. Now let's create a coordinator based on our workflow.
It is created as in the previous example.
HUE + Spark
Workflow is created in the same way as the previous example, coordinator is also similar. There is one feature - if you get an error like the main class is not found at startup, but you definitely put your jar file in HDFS, then you need to duplicate the jar file on all machines in the same directories as it is in HDFS.
I also want to show branched workflow:
The magic wand at first vorkflow is a solution blog; if we enter edit mode, we will see what the magic wand turns into:
And in the end I will tell…
For me, HUE has made working in the Hadoop ecosystem more comfortable. However, I do not use half of its capabilities. I did not say anything about the other HUE bundles, because either they are quite simple, for example, a bundle with Shell, or I don’t use them and can't say anything about them. I also did not talk about Query Editors, Metastore Manager, Search, since I didn’t work with them either. Thank you for your attention, success in the knowledge of this world.
Source: https://habr.com/ru/post/283242/
All Articles