You do not know Node: a brief overview of the main features

Remark from the author
This article is new, but it is not about new features. It is about the core, that is, about the platform and the fact that many who simply use grunt, or the webpack may be unaware, so skazat about the fundamentals.
Read more:
')
rumkin comments:
habrahabr.ru/company/mailru/blog/283228/#comment_8890604
Aiditz comments:
habrahabr.ru/company/mailru/blog/283228/#comment_8890476
Suvitruf comments:
habrahabr.ru/company/mailru/blog/283228/#comment_8890430
The idea of this publication was inspired by the series of Kyle Simpson's books “ You don't know JavaScript ”. They are a good start to learn the basics of this language. And Node is almost the same JavaScript, except for small differences, which I will discuss in this article. All the code below can be downloaded from the repository , from the
code folder.Why bother about Node at all? Node is JavaScript, and JavaScript is used almost everywhere! The world would be better off if most developers were perfectly fluent in Node. The better the application, the better the life!
This article is a realistic look at the most interesting main features of Node. Key points of the article:
- Event loop: refresh key concept that allows non-blocking I / O operations.
- Global object and process: how to get more information.
- Event emitters: an intensive introduction to the event-based model (event-based pattern)
- Streaming and buffers: an efficient way to work with data
- Clusters: Forky processes like a professional
- Handling asynchronous errors: AsyncWrap, Domain and uncaughtException
- Addons in C ++: adding your own developments to the kernel and writing your own addons in C ++
Event cycle
Let's start with the cycle of events that underlies the Node.
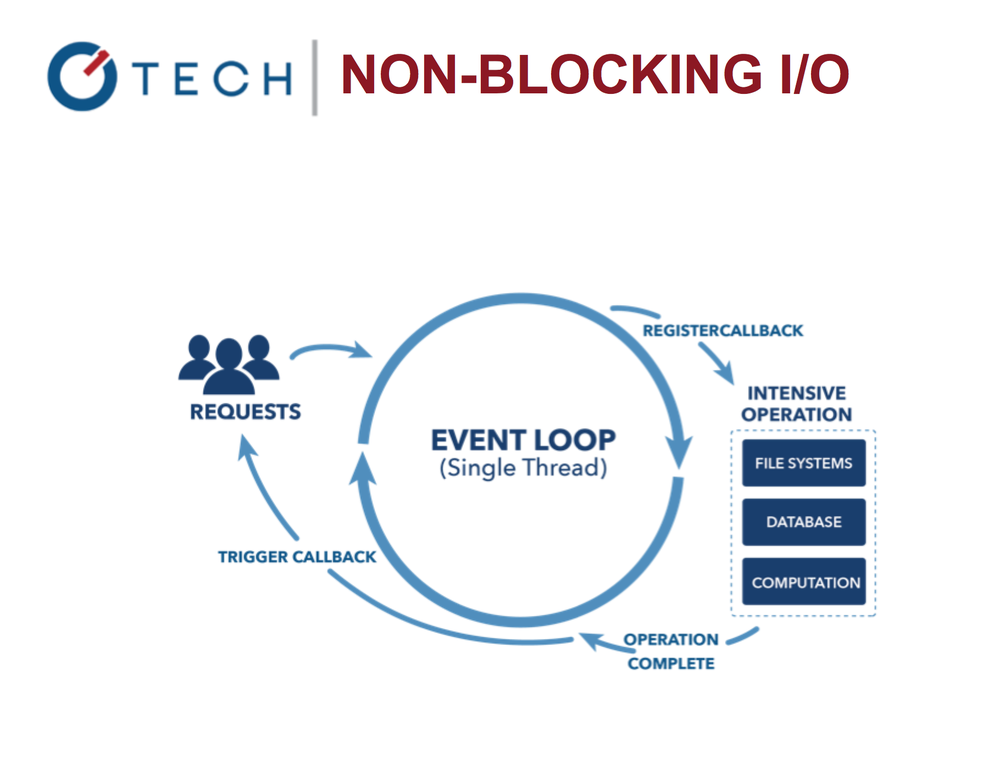
Non-blocking I / O operations in Node.js
The cycle allows us to work with other tasks in parallel with performing I / O operations. Compare Nginx and Apache. Thanks to the event loop, Node works very quickly and efficiently, since blocking I / O operations are expensive!
Take a look at this simple example of the Java
println deferred function: System.out.println("Step: 1"); System.out.println("Step: 2"); Thread.sleep(1000); System.out.println("Step: 3"); This is comparable (though not quite) with the Node code:
console.log('Step: 1') setTimeout(function () { console.log('Step: 3') }, 1000) console.log('Step: 2') This is not the same. Start thinking in terms of asynchronous work. Output Node-script - 1, 2, 3; but if after “Step 2” we had more expressions, they would first be executed, and only then callback functions
setTimeout . Take a look at this snippet: console.log('Step: 1') setTimeout(function () { console.log('Step: 3') console.log('Step 5') }, 1000); console.log('Step: 2') console.log('Step 4') The result of his work will be a sequence of 1, 2, 4, 3, 5. The reason is that
setTimeout places its callback in future periods of the event cycle.You can perceive the cycle of events as an infinite loop like
for … while . It stops only when there is nothing more to do, either now or in the future.
Blocking I / O: Multi-threaded Java
The event loop allows the system to work more efficiently, the application can do something else while waiting for the completion of expensive I / O operations.
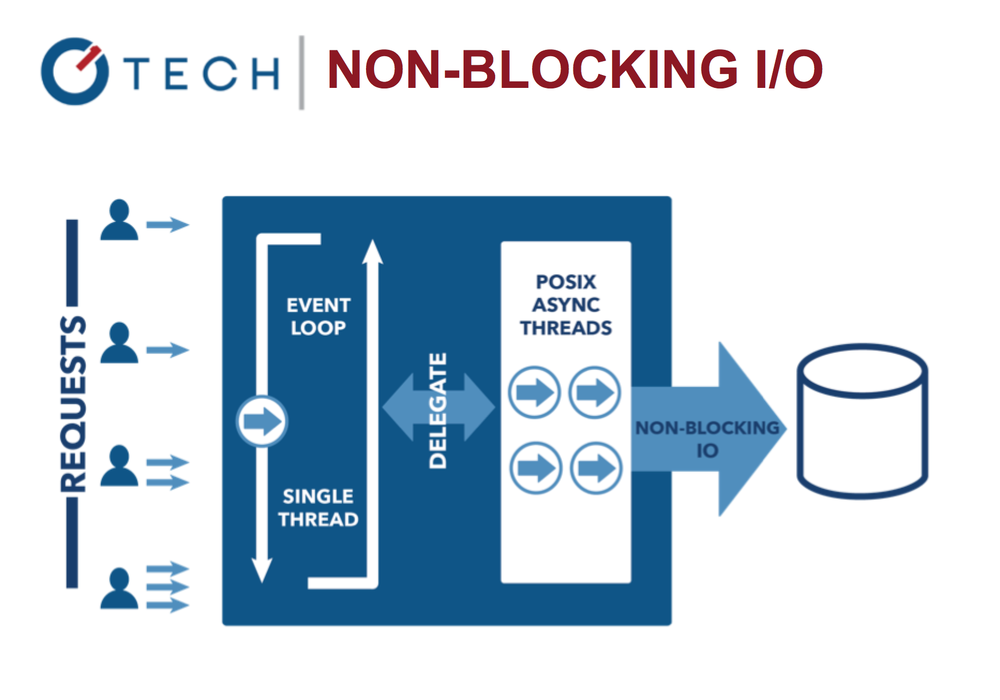
Non-blocking I / O operations in Node.js
This contrasts with the more common model of parallel processing (concurrency model), which involves the threads of the operating system. The network flow model (thread-based networking) is rather inefficient and very difficult to use. Moreover, Node users may not be afraid of complete blocking of processes - there are no lockes here.
By the way, you can still write blocking code in Node.js. Look at this simple snippet:
console.log('Step: 1') var start = Date.now() for (var i = 1; i<1000000000; i++) { // This will take 100-1000ms depending on your machine } var end = Date.now() console.log('Step: 2') console.log(end-start) Of course, there are usually no empty loops in our code. When using foreign modules, it may be more difficult to detect synchronous, and therefore blocking code. For example, the main
fs module (file system) comes with two sets of methods. Each pair does the same thing, but in different ways. The blocking methods in the fs module have the word Sync in their names: var fs = require('fs') var contents = fs.readFileSync('accounts.txt','utf8') console.log(contents) console.log('Hello Ruby\n') var contents = fs.readFileSync('ips.txt','utf8') console.log(contents) console.log('Hello Node!') The result of executing this code is completely predictable, even for beginners in Node / JavaScript:
data1->Hello Ruby->data2->Hello NODE! But everything changes when we switch to asynchronous methods. Here is an example of non-blocking code:
var fs = require('fs'); var contents = fs.readFile('accounts.txt','utf8', function(err,contents){ console.log(contents); }); console.log('Hello Python\n'); var contents = fs.readFile('ips.txt','utf8', function(err,contents){ console.log(contents); }); console.log("Hello Node!"); contents are displayed last, because their execution takes some time, they are also in callbacks. The event loop will go to them upon completion of reading the file: Hello Python->Hello Node->data1->data2 In general, the event loop and non-blocking I / O operations are very powerful things, but you have to write asynchronous code, which many people are not used to.
Global object
When developers switch from browser-based JavaScript or another language to Node.js, they have the following questions:
- Where to store passwords?
- How to create global variables (in Node there is no
window)? - How to access CLI, OS, platform, memory, version, etc. input?
For this, there is a global object that has certain properties. Here are some of them:
global.process: process, system, environment information (you can access CLI input data, environment variables with passwords, memory, etc.)global.__filename: the file name and the path to the currently running script that contains this expression.global.__dirname: the full path to the currently running script.global.module: an object for exporting code that creates a module from this file.global.require(): method for importing modules, JSON files and folders.
There are also common suspects - methods from browser JavaScript:
global.console()global.setInterval()global.setTimeout()
Each of the global properties can be accessed using the
GLOBAL name typed in capital letters, or without a name at all, simply by writing process instead of global.process .Process
The process object deserves a separate chapter, because it contains a lot of information. Here are some of its properties:
process.pid: The process ID of this Node instance.process.versions: different versions of Node, V8 and other componentsprocess.arch: system architectureprocess.argv: CLI argumentsprocess.env: environment variables
Some methods:
process.uptime(): get running timeprocess.memoryUsage(): gets the amount of memory consumedprocess.cwd(): get the current working folder. Not to be confused__dirname, independent of the place from which the process was launched.process.exit(): exits the current process. For example, you can pass the code 0 or 1.process.on(): attaches to the event, for example, ʻon ('uncaughtException')
The hard question is: who likes and who understands the essence of callbacks?
Someone is so "in love" with them that he created http://callbackhell.com . If this term is not familiar to you, here is an illustration:
fs.readdir(source, function (err, files) { if (err) { console.log('Error finding files: ' + err) } else { files.forEach(function (filename, fileIndex) { console.log(filename) gm(source + filename).size(function (err, values) { if (err) { console.log('Error identifying file size: ' + err) } else { console.log(filename + ' : ' + values) aspect = (values.width / values.height) widths.forEach(function (width, widthIndex) { height = Math.round(width / aspect) console.log('resizing ' + filename + 'to ' + height + 'x' + height) this.resize(width, height).write(dest + 'w' + width + '_' + filename, function(err) { if (err) console.log('Error writing file: ' + err) }) }.bind(this)) } }) }) } }) The “hell of callbacks” is difficult to read, and mistakes can easily be made here. So how do we divide into modules and organize asynchronous code, if not using callbacks that are not very convenient for scaling from a development point of view.
Event emitters
To deal with the hell of callbacks, or the pyramid of doom, event emitters are used. With their help, you can implement asynchronous code using events.
In short, an event emitter is a trigger for an event that anyone can listen to. In Node.js, each event is assigned a string name, to which the callback can be hung by the emitter.
What are emitters for:
- In the Node, events are processed using the “observer” pattern.
- An event (or a subject) keeps track of all related functions.
- These functions — observers — are executed when the event is activated.
To use emitters, you need to import the module and create an instance of the object:
var events = require('events') var emitter = new events.EventEmitter() Then you can attach event recipients and activate / send events:
emitter.on('knock', function() { console.log('Who\'s there?') }) emitter.on('knock', function() { console.log('Go away!') }) emitter.emit('knock') Let's use the
EventEmitter do something useful, inheriting it from it. Suppose you regularly need to implement a class - monthly, weekly, or every day. This class must be flexible enough for other developers to customize the final result. In other words, at the end of your work, everyone should be able to put some kind of logic into the class.This diagram shows how we use
Job inherit from the event module, and then use the done event receiver to change the behavior of the Job class:
Event emitters in Node.js: “observer” pattern
The
Job class will retain its properties, but at the same time will receive events. At the end of the process, we just need to run the done event: // job.js var util = require('util') var Job = function Job() { var job = this // ... job.process = function() { // ... job.emit('done', { completedOn: new Date() }) } } util.inherits(Job, require('events').EventEmitter) module.exports = Job Finally, change the
Job behavior. Once it sends done , then we can attach the event receiver: // weekly.js var Job = require('./job.js') var job = new Job() job.on('done', function(details){ console.log('Job was completed at', details.completedOn) job.removeAllListeners() }) job.process() Emitters have other options:
emitter.listeners(eventName): lists all recipients for this event.emitter.once(eventName, listener): attaches a one-time event listener.emitter.removeListener(eventName, listener): deletes the event receiver.
Node uses an event pattern everywhere, especially in the core modules. So if you use events wisely, you will save a lot of time.
Streams
There are several problems with working with large amounts of data in Node. Performance may be low, and the buffer size is limited to about 1 GB. In addition, how to work in conditions of an infinite resource, which was created on the basis that it will never end? In these situations, we will help stream'y.
Stream'y in Node are an abstraction, denoting the continuous splitting of data into fragments. In other words, you do not need to wait for the resource to be fully loaded. The diagram shows the standard approach to buffering:
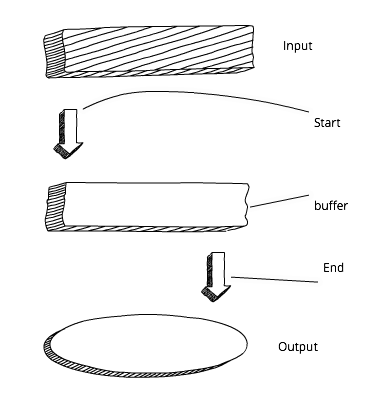
Node.js buffering approach
Before we start processing the data and / or output them, we have to wait for the buffer to load completely. Now compare this with the work flow scheme. In this case, we can immediately start processing the data and / or output it as soon as we receive the first chunk:
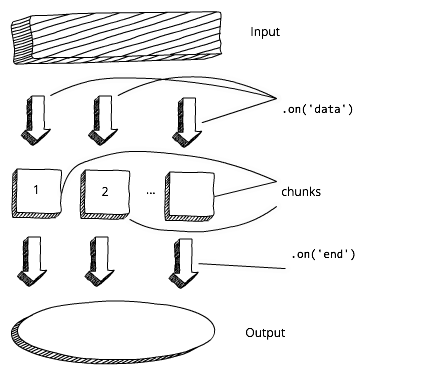
Stream approach in Node.js
There are four types of streams in Node:
- Readable: you can read from them.
- Writable (writable): they can be written.
- Duplex (duplex): you can both write and read.
- Transform streams: You can use them to transform data.
Virtually streams are used everywhere in Node. Most popular implementations of streams:
- HTTP requests and responses.
- Standard I / O operations.
- Reading from files and writing to them.
To provide the “observer” pattern, streams — events — inherit from the “emitter of events” object. We can use this to implement streams.
An example of readable stream
An example is
process.stdin , which is the standard input stream. It contains data that goes into the application. This is usually keyboard information used to start the process.The
data and end events are used to read data from stdin . The callback of the data event will have a chunk as an argument: process.stdin.resume() process.stdin.setEncoding('utf8') process.stdin.on('data', function (chunk) { console.log('chunk: ', chunk) }) process.stdin.on('end', function () { console.log('--- END ---') }) Next, the
chunk fed to the program as input. This event can be activated several times, depending on the total amount of incoming information. The completion of stream must be signaled using the end event.Note:
stdin is paused by default, from which it must be output before reading data from it.Readable streams have a synchronous
read() interface. When the stream ends, it returns chunk or null . We can take advantage of this behavior by putting the construction null !== (chunk = readable.read()) in a while condition null !== (chunk = readable.read()) : var readable = getReadableStreamSomehow() readable.on('readable', () => { var chunk while (null !== (chunk = readable.read())) { console.log('got %d bytes of data', chunk.length) } }) Ideally, we would like to write asynchronous code in Node as often as possible in order to avoid blocking thread. But due to the small size of the chunks, you can not worry about the fact that synchronous
readable.read() blocks thread.An example of a recorded stream
An example is
process.stdout , which is the standard output stream. It contains data that leaves the application. You can write to stream using the write operation. process.stdout.write('A simple message\n') The data written to the standard stream is displayed on the command line as if we used
console.log() .Pipe
In Node, there is an alternative to the events described above - the
pipe() method. The following example reads data from a file, compresses with GZip and writes the result to a file: var r = fs.createReadStream('file.txt') var z = zlib.createGzip() var w = fs.createWriteStream('file.txt.gz') r.pipe(z).pipe(w) Readable.pipe() takes the data stream and passes through all the streams, so we can create chains from the pipe() methods.So when using streams, you can use events or pipe.
HTTP streaming
Most of us use Node to create web applications: traditional (server) or based on REST API (client). What about HTTP requests? Can you stream them? Definitely!
Requests and responses are readable and writable streams inherited from event emitters. You can attach the recipient of the
data event and take a chunk in its callback, which you can immediately convert without waiting for the entire response. In the following example, we concatenate the body and parse it in the end callback event: const http = require('http') var server = http.createServer( (req, res) => { var body = '' req.setEncoding('utf8') req.on('data', (chunk) => { body += chunk }) req.on('end', () => { var data = JSON.parse(body) res.write(typeof data) res.end() }) }) server.listen(1337) Note: according to ES6,
()=>{} is a new syntax for anonymous functions, and const is a new operator. If you are not familiar with the features and syntax of ES6 / ES2015, then you can read the article Top 10 ES6 properties that every busy JavaScript developer should know about .Let's use Express.js now to make our server less detached from real life. Take a huge image (about 8 MB) and two sets of Express routes
/stream and /non-stream .server-stream.js:
app.get('/non-stream', function(req, res) { var file = fs.readFile(largeImagePath, function(error, data){ res.end(data) }) }) app.get('/stream', function(req, res) { var stream = fs.createReadStream(largeImagePath) stream.pipe(res) }) I also have an alternative implementation of
/stream2 with events, and a synchronous implementation of /non-stream2 . They do the same thing, but they use a different syntax and style. In this case, synchronous methods work faster because we send only one request, and not several competing ones.You can run this code through the terminal:
$ node server-stream Now open in Chrome http: // localhost: 3000 / stream and http: // localhost: 3000 / non-stream . Notice the headers on the Network tab in the developer tools by comparing
X-Response-Time . In my case, /stream and /stream2 differed by orders of magnitude: 300 ms. and 3-5 seconds. You may have other values, but the idea is clear: in the case of /stream users / clients will start receiving data earlier. Streaming in Node is a very powerful tool! You can learn how to manage your streaming resources well by becoming an expert in this field on your team.With npm, you can set your own Stream Handbook and stream-adventure :
$ sudo npm install -g stream-adventure $ stream-adventure Buffers
What types can we use for binary data? If you remember, there is no binary data type in JavaScript browser, but there is in Node. This is called a buffer. It is a global object, so there is no need to import it as a module.
You can use one of these expressions to create a binary type:
new Buffer(size)new Buffer(array)new Buffer(buffer)new Buffer(str[, encoding])
A full list of methods and encodings is available in the buffer documentation . The most common encoding used is
utf8 .Usually, the contents of the buffer look like an abracadabra, therefore, in order to be readable by a person, you must first convert it to a string representation with
toString() . Create a buffer with the alphabet using the for loop: let buf = new Buffer(26) for (var i = 0 ; i < 26 ; i++) { buf[i] = i + 97 // 97 is ASCII a } If you do not convert the buffer to a string representation, it will look like an array of numbers:
console.log(buf) // <Buffer 61 62 63 64 65 66 67 68 69 6a 6b 6c 6d 6e 6f 70 71 72 73 74 75 76 77 78 79 7a> Carry out the conversion:
buf.toString('utf8') // outputs: abcdefghijklmnopqrstuvwxyz buf.toString('ascii') // outputs: abcdefghijklmnopqrstuvwxyz If we need only a part of the string (sub string), then the method takes the initial number and the final position of the desired segment:
buf.toString('ascii', 0, 5) // outputs: abcde buf.toString('utf8', 0, 5) // outputs: abcde buf.toString(undefined, 0, 5) // encoding defaults to 'utf8', outputs abcde Remember
fs ? The default value of data also a buffer: fs.readFile('/etc/passwd', function (err, data) { if (err) return console.error(err) console.log(data) }); data acts as a buffer when working with files.Clusters
Opponents of Node often give the argument that it can scale because it has only one thread. However, using the main
cluster module (you do not need to install it, it is part of the platform) we can use all the processor resources on any machine. In other words, thanks to clusters, we can vertically scale Node applications.The code is very simple: we import a module, create one master and several workers (worker). Usually one process is created for each CPU, but this is not an unshakable rule. You can make as many processes as you want, but from a certain point the productivity gains stop, according to the law of decreasing returns.
The master and worker code is in the same file. The worker can listen to the same port by sending messages to the master through events. The master can listen to events and, if necessary, restart the clusters. For the wizard,
cluster.isMaster() , for the employee - cluster.isWorker() . Most of the server code will be located in the worker ( isWorker() ). // cluster.js var cluster = require('cluster') if (cluster.isMaster) { for (var i = 0; i < numCPUs; i++) { cluster.fork() } } else if (cluster.isWorker) { // }) In this example, my server issues process IDs, so you can observe how different workers process different requests. It looks like a load balancer, but this is only an impression, because the load will not be evenly distributed. For example, by the PID, you will see how one of the processes can handle much more requests.
, ,
loadtest Node:loadtestnpm: $ npm install -g loadtestcode/cluster.jsnode ($ node cluster.js); .- :
$ loadtest http://localhost:3000 -t 20 -c 10. loadtest.- Ctrl+C. PID.
loadtest -t 20 -c 10 , 10 20 .— , . , . :
strong-cluster-control(https://github.com/strongloop/strong-cluster-control)$ slc runpm2(https://github.com/Unitech/pm2)
pm2
pm2 , Node-. , pm2 production.pm2 :- .
- , .
- .
https://github.com/Unitech/pm2 http://pm2.keymetrics.io .
pm2 -
server.js . , isMaster() , , cluster . pid . var express = require('express') var port = 3000 global.stats = {} console.log('worker (%s) is now listening to http://localhost:%s', process.pid, port) var app = express() app.get('*', function(req, res) { if (!global.stats[process.pid]) global.stats[process.pid] = 1 else global.stats[process.pid] += 1; var l ='cluser ' + process.pid + ' responded \n'; console.log(l, global.stats) res.status(200).send(l) }) app.listen(port) pm2 start server.js . /, ( -i 0 , , , 4). -l log.txt : $ pm2 start server.js -i 0 -l ./log.txt , pm2 . :
$ pm2 list loadtest , cluster . : $ loadtest http://localhost:3000 -t 20 -c 10 ,
log.txt - : cluser 67415 responded { '67415': 4078 } cluser 67430 responded { '67430': 4155 } cluser 67404 responded { '67404': 4075 } cluser 67403 responded { '67403': 4054 } Spawn, Fork Exec
cluter.js Node- fork() . , Node.js : spawn() , fork() exec() . child_process . :require('child_process').spawn(): ; stream'; ; V8.require('child_process').fork(): V8 ; Node.js (node).require('child_process').exec(): , ; , callback'; ,node.
:
node program.js , — bash, Python, Ruby .. , , spawn() . data stream': var fs = require('fs') var process = require('child_process') var p = process.spawn('node', 'program.js') p.stdout.on('data', function(data)) { console.log('stdout: ' + data) }) node program.js , data , , .fork() spawn() , : , fork() , Node.js: var fs = require('fs') var process = require('child_process') var p = process.fork('program.js') p.stdout.on('data', function(data)) { console.log('stdout: ' + data) }) ,
exec() . , , callback. error, standard output : var fs = require('fs') var process = require('child_process') var p = process.exec('node program.js', function (error, stdout, stderr) { if (error) console.log(error.code) }) error stderr , exec() (, program.js ), — (, program.js ).Node.js
try/catch . . try { throw new Error('Fail!') } catch (e) { console.log('Custom Error: ' + e.message) } , . Java Node. Node.js , thread.
, , /. , .
,
setTimeout() , callback'. , HTTP-, : try { setTimeout(function () { throw new Error('Fail!') }, Math.round(Math.random()*100)) } catch (e) { console.log('Custom Error: ' + e.message) } callback ,
try/catch . , callback try/catch , , . . try/catch ., . ? , callback'
error . : callback' . if (error) return callback(error) // or if (error) return console.error(error) :
- (on error).
uncaughtException.domain( ) AsyncWrap .- .
- ( ).
- .
on('error')
on('error') , Node.js, http . error , Express.js, LoopBack, Sails, Hapi .., http . js server.on('error', function (err) { console.error(err) console.error(err) process.exit(1) }) uncaughtException
uncaughtException process ! uncaughtException — . , — Node.js — .An unhandled exception means your application – and by extension Node.js itself – is in an undefined state. , .
process.on('uncaughtException', function (err) { console.error('uncaughtException: ', err.message) console.error(err.stack) process.exit(1) }) or
process.addListener('uncaughtException', function (err) { console.error('uncaughtException: ', err.message) console.error(err.stack) process.exit(1) Domain
domain . Node.js . , . : domain callback' run() : var domain = require('domain').create() domain.on('error', function(error){ console.log(error) }) domain.run(function(){ throw new Error('Failed!') }) 4.0
domain , Node . Node domain . , , domain npm-, npm. domain .setTimeout() : // domain-async.js: var d = require('domain').create() d.on('error', function(e) { console.log('Custom Error: ' + e) }) d.run(function() { setTimeout(function () { throw new Error('Failed!') }, Math.round(Math.random()*100)) }); !
domain error “Custom Error”, Node .C++
Node , IoT, , , /++. /++ ?
. Node , ++! , .
hello.cc , . , . #include <node.h> namespace demo { using v8::FunctionCallbackInfo; using v8::HandleScope; using v8::Isolate; using v8::Local; using v8::Object; using v8::String; using v8::Value; void Method(const FunctionCallbackInfo<Value>& args) { Isolate* isolate = args.GetIsolate(); args.GetReturnValue().Set(String::NewFromUtf8(isolate, "capital one")); // String } void init(Local<Object> exports) { NODE_SET_METHOD(exports, "hello", Method); // Exporting } NODE_MODULE(addon, init) } , , , JavaScript.
capital one : args.GetReturnValue().Set(String::NewFromUtf8(isolate, "capital one")); hello : void init(Local<Object> exports) { NODE_SET_METHOD(exports, "hello", Method); } hello.cc , . binding.gyp , : { "targets": [ { "target_name": "addon", "sources": [ "hello.cc" ] } ] } binding.gyp hello.cc , node-gyp : $ npm install -g node-gyp ,
hello.cc binding.gyp , : $ node-gyp configure $ node-gyp build build . build/Release/ .node . , Node.js hello.js , C++: var addon = require('./build/Release/addon') console.log(addon.hello()) // 'capital one' capital one , : $ node hello.js C++ : https://github.com/nodejs/node-addon-examples .
Conclusion
GitHub . Node.js, callback' Node-, Node: callback' observer' .
:
- : , / Node.
- : .
- : “observer” Node.js.
- : .
- : .
- : .
- Domain: .
- C++: .
Node JavaScript, , , , . , Node.js.
Source: https://habr.com/ru/post/283228/
All Articles