We use undocumented site API captionbot.ai
In this article we will discuss how to get and use the site's API, if there is no documentation on it or it is not yet officially open. The guide is written for beginners who have not tried to fix a simple API yet. For those who are engaged in such things, there is nothing new here.
The analysis will be conducted on the example of the service API https://www.captionbot.ai/, which Microsoft recently opened (thanks to them for this). Many could read about it in article on Geektimes . The site uses ajax requests in JSON format, so copying them will be easy and pleasant. Go!
We analyze requests
First of all, open the developer tools and analyze the requests that the site sends to the server.
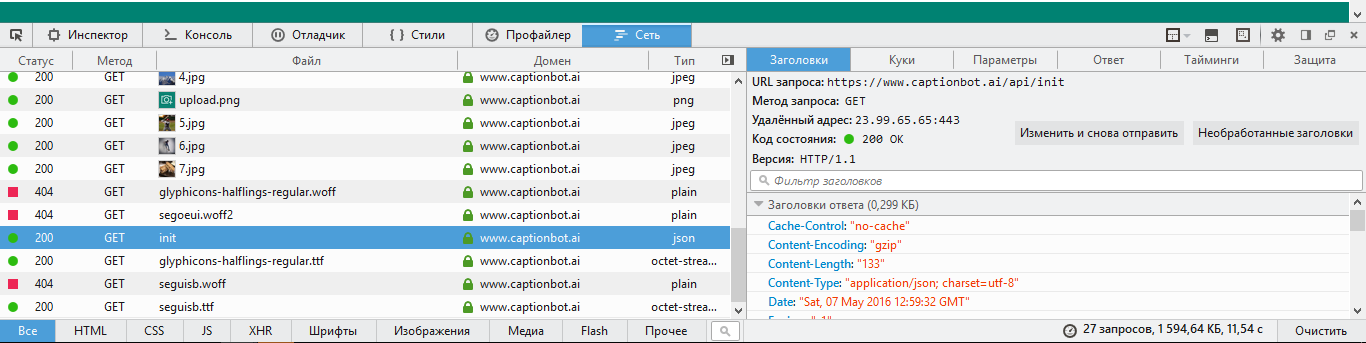
In our case, all requests that interest us have the base URL https://www.captionbot.ai/api
Initialization
When you first open the site, there is a GET request for /api/init with no parameters.
The answer has Content-Type: application/json , while in the body of the answer we just get a line of the form:
"54cER5HILuE" Remember this and move on.
Submit URL
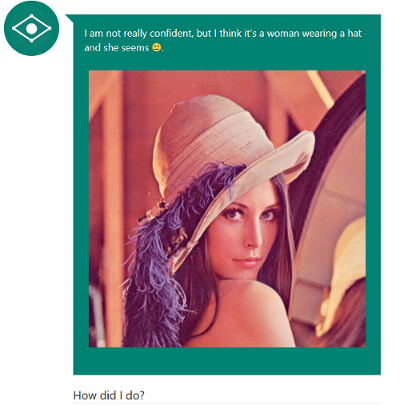
We have two ways to upload an image: via the URL and via file upload. For the test, we take the URL of Lena's image from the wiki and send it. In the network activity, a POST request for /api/message appears with the following parameters:
{ "conversationId": "54cER5HILuE", "waterMark": "", "userMessage": "https://upload.wikimedia.org/wikipedia/ru/2/24/Lenna.png" } Yeah, we tell ourselves, the init method returned us a string for conversationId , and our link got into userMessage . What is waterMark is not yet clear. We look at the response data:
"{\"ConversationId\":null,\"WaterMark\":\"131071012038902294\",\"UserMessage\":\"I am not really confident, but I think it's a woman wearing a hat\\nand she seems . \",\"Status\":null}" For some reason JSON was encoded twice, but oh well. In human form, it looks like this:
{ "ConversationId": null, "WaterMark": "131071012038902294", "UserMessage": "I am not really confident, but I think it's a woman wearing a hat\\nand she seems .", "Status": null } All the parameters along the way changed the style of writing, but this is the little things in life. So, we were given back some WaterMark value, for some reason, an empty ConversationId , the actual caption to the photo in the UserMessage field UserMessage and some empty status.
Loading image
Next, without closing the tab, we try the same operation with loading photos from a local file. We see a POST request for /api/upload in multipart/form-data format with the name of the file field:
-----------------------------50022246920687 Content-Disposition: form-data; name="file"; filename="Lenna.png" Content-Type: image/png In response, we get the line URL of our uploaded file, we can go over it and see this:
"https://captionbot.blob.core.windows.net/images-container/2ogw3q4m.png" Then the already familiar request to /api/message sent:
{ "conversationId": "54cER5HILuE", "waterMark": "131071012038902294", "userMessage": "https://captionbot.blob.core.windows.net/images-container/2ogw3q4m.png" } waterMark from the previous answer came in handy, and the URL is the one that the upload method returned to us. Response data are similar to the previous ones.
We write a wrapper
To use this knowledge with convenience, we make a simple wrapper in your favorite programming language. I'll do it in Python. For requests to the site I use requests, as it is convenient and it has sessions that store cookies for me. The site uses SSL, but by default requests will swear on the certificate:
hostname 'www.captionbot.ai' doesn't match either of '*.azurewebsites.net', '*.scm.azurewebsites.net', '*.azure-mobile.net', '*.scm.azure-mobile.net' This is solved by setting the verify = False flag on each request.
import json import mimetypes import os import requests import logging logger = logging.getLogger("captionbot") class CaptionBot: BASE_URL = "https://www.captionbot.ai/api/" def __init__(self): self.session = requests.Session() url = self.BASE_URL + "init" resp = self.session.get(url, verify=False) logger.debug("init: {}".format(resp)) self.conversation_id = json.loads(resp.text) self.watermark = '' def _upload(self, filename): url = self.BASE_URL + "upload" mime = mimetypes.guess_type(filename)[0] name = os.path.basename(filename) files = {'file': (name, open(filename, 'rb'), mime)} resp = self.session.post(url, files=files, verify=False) logger.debug("upload: {}".format(resp)) return json.loads(resp.text) def url_caption(self, image_url): data = json.dumps({ "userMessage": image_url, "conversationId": self.conversation_id, "waterMark": self.watermark }) headers = { "Content-Type": "application/json" } url = self.BASE_URL + "message" resp = self.session.post(url, data=data, headers=headers, verify=False) logger.debug("url_caption: {}".format(resp)) if not resp.ok: return None res = json.loads(json.loads(resp.text)) self.watermark = res.get("WaterMark") return res.get("UserMessage") def file_caption(self, filename): upload_filename = self._upload(filename) return self.url_caption(upload_filename) The source code is on Github , plus the finished package in pip .
')
Source: https://habr.com/ru/post/283112/
All Articles