Performance without event loop

This article is based on the presentation materials that I presented this year at the OSCON conference. I edited the text to make it more concise, and at the same time took into account the feedback that I received after my presentation.
About Go it is often said that it is good for servers: there are static binaries (static binaries), advanced concurrency , high performance. In this article we’ll talk about the last two points: how the language and the runtime unobtrusively allow Go programmers to create easily scalable servers and not worry about flow control or blocking I / O operations.
')
Argument in favor of language performance
But before turning to technical details, I want to make two statements describing the market segment of the Go language.
Moore's Law
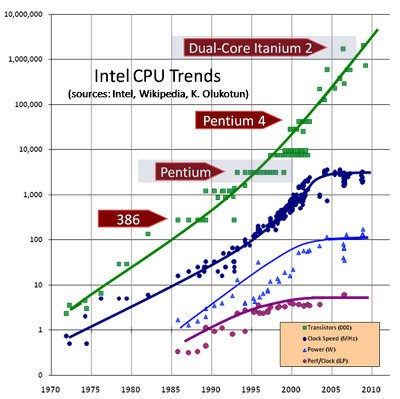
According to Moore’s often mistakenly quoted law, the number of transistors per unit area of a crystal doubles approximately every 18 months. However, the working frequencies, which depend on completely different properties, have stopped growing already a decade ago, with the release of the Pentium 4, and have since been gradually decreasing.
From spatial constraints to energy

Sun Enterprise e450 - about the size of a bar fridge and consumes about the same amount of electricity
This is the Sun e450. When my career began, these computers were the workhorses of the industry. They were massive. If you put one on the other three pieces, they will occupy the whole 19-inch rack. In this case, each consumed only about 500 watts.
Over the past decade, the main limitation for data centers has become not the available space, but the level of electricity consumption. In the last two cases, when I took part in the launch of the data centers, we lacked energy by almost a third when filling out the racks. The density of computing power has grown so fast that now you can not think about where to place the equipment. At the same time, modern servers began to consume much more electricity, although they became much less. This greatly complicates cooling, the quality of which is crucial for the operation of the equipment.
The effect of energy limitations manifested itself:
- at the macro level - few people can ensure the work of the rack with 1200-watt 1U-servers;
- at the micro level, all these hundreds of watts are scattered on a small silicon crystal as heat.
What is the reason for this increase in energy consumption?

CMOS inverter
This is an inverter, one of the simplest logic gates. If input A is fed high, then output Q is low and vice versa. All modern consumer electronics are built on CMOS logic (CMOS is a metal-oxide-semiconductor complementary structure). The key word here is “complementary.” Each logic element inside the processor is implemented using a pair of transistors: when one turns on, the other turns off.
When the inverter output is high or low, no current flows from Vss to Vdd. But during switching times there are short periods when both transistors conduct current, creating a short circuit. And the energy consumption - and hence heat dissipation - is directly proportional to the number of switches per second, that is, the processor clock frequency.
CMOS power consumption is not associated only with short circuits during switching. Contributing to the charge output capacity of the shutter. In addition, the gate leakage current increases with decreasing transistor size. More information about this can be found on the links: one , two .
Reducing the size of the elements of the processor is aimed primarily at reducing power consumption. This is necessary not only for the sake of ecology, the main goal is to keep the heat generation at an acceptable level in order to prevent damage to processors.
Despite the reduction in clock speeds and power consumption, the increase in performance is mainly due to improvements in the microarchitecture and esoteric vector instructions that are not particularly useful for general computing. As a result, each microarchitecture (5-year cycle) exceeds the previous generation by no more than 10%, and recently it is barely less than 4–6%.
"Freebie is over"
I hope you now understand that iron is not getting faster. If performance and scale are important to you, then you will agree with me that it will no longer be possible to solve problems by means of equipment alone, at least in the conventional sense. As stated in the coat of arms of Sutter - " Freebie is over ."
We need a productive programming language, because inefficient languages simply do not justify their use in widespread use, when scaling and in terms of capital investments.
Argument for a parallel programming language
My second argument follows from the first. Processors don't get faster, but they get thicker. It is unlikely that there should be a surprise for you that transistors are developing in this direction.

Simultaneous multithreading, or Hyper-Threading, as Intel calls it, allows a single core to simultaneously execute multiple instruction streams by adding a little hardware strapping. Intel uses Hyper-Threading technology to artificially segment the processor market, while Oracle and Fujitsu are more actively using it in their products, bringing the number of hardware execution threads to 8 or 16 per core.
Dual-processor motherboards appeared in the late 1990s, when the Pentium Pro came out. Today, this is a standard solution; most servers support two- or four-processor configurations. Increasing the density of transistors even allowed to place several cores on a single crystal. Dual-core processors settled in the mobile segment, quad-core - in the desktop, even more cores in the server segment. In fact, today the number of cores in the server is limited only by your budget.
And in order to take advantage of all these cores, you need a programming language with advanced parallelism.
Processes, execution threads and gorutiny
At the heart of Go parallelism are the so-called goroutines. Let's get a little distracted and remember the history of their occurrence.
Processes
At the dawn of time, with the batch processing model, computers could perform only one task at a time. The pursuit of more interactive forms of computing led in the 1960s to the development of multi-process operating systems, or systems operating in time-sharing mode. In the 1970s, this idea penetrated servers, FTP, Telnet, rlogin, and later on CERN httpd by Tim Berners-Lee. Processing all incoming network connections was accompanied by forking child processes.
In time-sharing systems, the OS maintains the illusion of parallelism by quickly switching processor resources between active processes. To do this, first write the state of the current process, and then restore the state of another. This is called context switching.
Context switch

Context switching has three main expense items:
- The kernel must save the contents of all processor registers first for one process, then restore the values for another. Since switching between processes can occur at any time, the OS must store the contents of all registers, because it does not know which of them are currently being used. Of course, this is an extremely simplified description. In some cases, the OS can avoid saving and restoring frequently used architectural registers, starting the process in a mode in which access to the floating-point or MMX / SSE registers causes an interrupt (fault). In such situations, the kernel understands that the process will use these registers and they need to be saved and restored.
- The kernel should clear the cache of virtual memory physical addresses ( TLB, associative translation buffer ). Some processors use the so-called tagged TLB . In this case, the OS can order the processor to assign identifiers derived from the process ID to specific buffer entries, rather than treat each entry as global. This allows you to avoid deleting entries from the cache each time a process is switched, if the desired process quickly returns to the same kernel.
- OS overhead for context switching, as well as the overhead of the scheduler function when choosing the next process to provide the processor with work.
All these costs are relatively constant in terms of equipment, but it depends on the amount of work performed between switching operations whether these costs are justified. Too frequent switching reduces to nothing the amount of work done between them.
Streams
This has led to the emergence of threads, which are the same processes that use the shared address space. Because of this, they are easier to plan than processes, they are created faster and you can switch between them faster.
However, the cost of context switching for threads is quite high. It is necessary to save a lot of information about the state. The gorutines are actually a further development of the idea of flows.
Gorutiny
Instead of imposing responsibilities on time management for their implementation, the gorutines use cooperative multitasking. Switching between them takes place only at clearly defined points, when making explicit calls to the runtime-scheduler Go. The main situations in which gorutina will return control to the scheduler:
- sending and receiving from the channel, if they lead to blocking;
- calling the go func (...) instruction, although there is no guarantee that switching to a new gorutin will take place immediately;
- the occurrence of blocking system calls, such as file operations or network operations;
- after stopping execution to run the garbage collection cycle.
In other words, we are talking about situations where Gorutin lacks data to continue working, or she needs more space to write data.
In the course of work, the Go runtime scheduler switches between several gorutins within one operating system thread. This reduces the cost of creating and switching between them. A completely normal situation, when in one process tens of thousands of gorutins are performed, not uncommon and hundreds of thousands.
From the point of view of language, planning looks like a function call and has the same semantics. The compiler knows which registers are used, and it automatically saves them. The thread calls the scheduler, working with a certain stack of gorutin, but upon return, the stack may be different. Compare this with multi-threaded applications, where a thread can be preempted at any time, at the time of execution of any instruction.
All this leads to the fact that for every Go process there are relatively few OS threads. The Go runtime environment takes care of assigning ready-for-execution gorutines to free OS threads.
Stack management
In the previous section, we talked about how the gorutins reduce the overhead of managing multiple — sometimes hundreds of thousands — parallel flows. There is another side to the story of gorutines - stack management.
Process address space
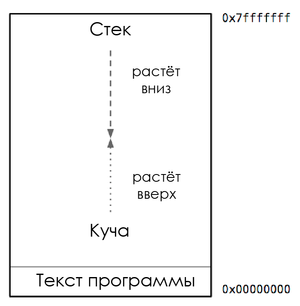
This diagram shows a typical process memory card. Here we are interested in placing the heap and stack. Inside the process address space, the heap is usually located at the bottom of the memory, immediately above the program code, and grows upwards. The stack is located at the top of the virtual address space and grows down.

If the heap and stack overwrite each other, it will be a disaster. Therefore, the OS allocates a buffer zone of inaccessible memory between them. It is called the guard page and actually limits the size of the process stack, usually within a few megabytes.
Thread stacks

Threads use the same shared address space. Each thread needs its own stack with a separate watch page. Since it is difficult to predict the needs of each of the threads, each stack has to reserve a large amount of memory. It remains only to hope that this will be enough and we will never get to the guard page.
The disadvantage of this approach is that with an increase in the number of threads in the program, the amount of available address space decreases.
Management stack gorutin
In an earlier version of the process model, programmers could assume that the heap and stack were large enough not to worry about it. However, the simulation of subtasks became difficult and expensive.
With the introduction of threads, the situation has improved slightly. But programmers must guess the best stack size. There will be too little - the program will crash, too much - the virtual address space will end.
We have already seen that the Go scheduler performs a large number of gorutin inside a small number of threads. What about the requirements for the stack sizes of these gorutin?
Growth stack gorutin

Initially, each gorutina has a small stack allocated from the heap. Its size varied depending on the language version; in Go 1.5, two kilobytes are allocated by default. Instead of using the watch page, the Go compiler inserts a check, which is part of the call to each function.
The check allows you to determine if the stack size is sufficient for executing the function. If yes, then the function is performed normally. If the stack is too small, then the runtime allocates a larger segment on the heap, copies the contents of the current stack there, releases it and restarts the function.
Thanks to this mechanism, very small initial stacks of gorutin can be made. In turn, this allows us to consider the gorutines as a cheap resource. There is also a mechanism for reducing the size of the stack, if a sufficient part of it remains unused. The reduction procedure is performed during garbage collection.
Integrated network poller
In 2002, Dan Kegel published an article, " The c10k Problem. " In simple terms, it was dedicated to writing server software capable of processing at least 10,000 TCP sessions on inexpensive hardware available at the time. After writing this article, the conventional wisdom emerged that high-performance servers need native streams. Later their place was taken by event loops.
From the point of view of planning costs and memory consumption, flows have high costs. Cycles of events have a better situation, but they have their own requirements due to the complex principle of work based on callbacks.
Go took all the best of these two approaches.
Go answer to c10k problem
System calls in Go are usually blocking operations. These calls include reading and writing to file descriptors. Go scheduler handles these cases by finding a free stream or creating a new one so that you can continue to maintain the gorutinas while the original stream is blocked. In life, this is well suited for file operations, because a small number of blocking threads can quickly exhaust local I / O bandwidth.
However, with network sockets, everything is not so simple. At any given time, almost all your gorutiny will be blocked in anticipation of network I / O operations. In the case of a primitive implementation, you will need to make one thread for each such gorutina, and all of them will be blocked waiting for network traffic. An integrated network poller Go helps to cope with this situation, providing interaction between the language runtime environment and the net package.
In old versions of Go, a single polynomial was a single gorutina, which with the help of kqueue or epoll requested readiness notifications. Such a gorutina communicated with waiting Gorutins through the channel. This made it possible to avoid allocating a stream for each system call, but it was necessary to use a generalized wake-up mechanism by writing to the channel. This means that the scheduler was not aware of the source or importance of the awakening.
In current versions of Go, the network poller is integrated into the runtime itself (at runtime). Since the medium knows which gorutin expects the socket to be ready, it can continue to perform gorutin on the same processor core upon arrival of the packet, reducing latency and increasing system capacity.
Gorutiny, stack management and integrated network poller
Let's sum up. Gorutiny are a powerful abstraction, thanks to which you can not worry about thread pools or event loops.
The stack of gorutines grows as needed, and you don’t have to worry about resizing stacks or thread pools.
The integrated network poller avoids the use of ornate callback-based schemes. This involves the most efficient logic for performing I / O operations, which can only be obtained from the OS.
The runtime ensures that there are exactly as many threads as needed to service all your gorutin and to load the processor cores.
And all these features are completely transparent to the Go programmer.
Source: https://habr.com/ru/post/283038/
All Articles