How to replace ELK for viewing logs?
What does a python programmer usually do when he is sent to fight with an error?
First he climbs into the sentry . Here you can find the time, the server, the details of the error message, traceback, and maybe some useful context. Then, if this data is not enough, the programmer goes with bottle to admins. Those get on the server, look for this message in file logs, and, maybe, find it and some previous records of an error which in rare cases may assist in the investigation.
And what to do if the logs only loglevel=ERROR , and the error is so steep that its localization requires comparing the logic of the behavior of several different demons that are running on a dozen servers?
The solution is a centralized log repository. In the simplest case - syslog (for 5 years that was deployed in the rutube, it was not used even once), for more complex purposes - ELK . Frankly, the “eraser” is cool, and allows you to quickly turn a variety of analytics, but have you seen the Kibana interface? This thing is as far from console less / grep as Windows to Linux. Therefore, we decided to make our own bike, without Java and Node.js, but with sphinxsearch and Python.
In general, the main complaints about ELK are that Kibana is not a navigation tool for logs at all. Not that it's impossible to use at all, but as a replacement for grep / less, it is no good.

So almost the main requirement for the "bike" was a minimalistic layout, to get rid of forever hanging built on the "enemy" technologies Logstash, well, ElasticSearch also throw out at the same time.
Part One: Shipping
To store the logs, they need to be sent somewhere. That same ElasticSearch can be written directly, but much more fun via RabbitMQ - that's why he and the message broker. Taking python-logstash as a basis, we “screwed” RabbitMQ unavailability and several “boot loaders” to it. The logcollect package supports auto configuration for Celery, Django and native python logging. At the same time, a handler is added to the root logger, which sends all the logs in JSON format to RabbitMQ.
Yes, I almost forgot. Example:
from logcollect.boot import default_config default_config( # RabbitMQ URI 'amqp://guest:guest@127.0.0.1/', # - # - activity_identity={'subsystem': 'backend'}, # RabbitMQ routing key. routing_key='site') Part Two, Small: Routing
To pre-filter the logs, we used RabbitMQ functionality: we use topic-exchange, which sends only messages matching a specific pattern to the queue for processing. For example, the Django sql requests for the site project will be processed only if the corresponding queue has routing key site.django.db.backends , and you can catch all the logs from django using routing key site.django.# . This allows you to balance between the amount of stored data and the full coverage of logged messages.
Part Three, Asynchronous: Save
Initially, the letter "A" in ALCO meant "asynchronous", but it quickly became clear that using asyncio-based solutions was useless: it was all about the speed of filtering messages by the Python process. This is understandable: librabbitmq allows you to immediately get a bundle of messages from the "rabbit", each of which needs to be parsed, cut unnecessary fields, renamed invalid, save new values in Redis for some fields, generate id for sphinxsearch based on the time stamp, and also INSERT -request.
Later, however, it turned out that the "asynchronous" is still about us: in order to spend the CPU time more efficiently, the round-trip INSERT request between python and sphinxsearch is performed in a separate thread, synchronized via native python queues.
New columns are saved in the database, after which a number of settings for displaying and storing them become available:
- display a la list-filter, for example, for filtering by levelname,
- indexing as a separate field, for example, for celery task_id,
- message context mode - very helpful for displaying traceback,
- exclusion from indexing and from the list of columns.
Part Four, Front End
From a technical point of view, there is nothing special to tell (bootstrap + backbone.js + django + rest_framework), so I’ll only provide a couple of screenshots.

Logs can be filtered by dates, values of certain columns from the list, by arbitrary values, as well as full-text search by the messages themselves. In addition, you can optionally view the records adjacent to the found full-text search (hello, less).
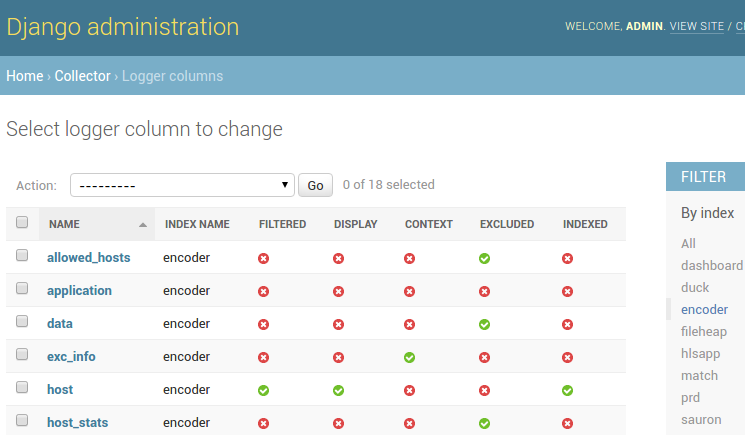
The display of the columns is configured through the admin panel, as well as the settings of the routing_key indexes or the data retention period.
Performance notes
Unfortunately, we cannot yet boast lightning-fast loading of the page: sphinxsearch is so designed that any filtering by attributes requires fullscan of the entire index, so only full-text search (grep) works quickly. But he - megabyst! But we do not give up, and persistently trying filtering performance.
For example, primary keys are specifically generated based on a time stamp, since sphinxsearch can "quickly" retrieve data on the range of id. Starting from a certain index volume, the performance gain is achieved by indexing individual columns: despite the low cardinality power, due to the fact that the full-text index is used, the query processing takes about 20 seconds against a minute in the case of filtering by json attributes. Also, the request indicates a distributed index corresponding to the range of the requested dates: thus, the data for the whole month is not readable if logs for "yesterday" are required.
The rate of insertion into the RT index has increased significantly since the time of this article on the sphinxsearch blog: it was possible to achieve (no matter how ...) 8000 row / s on 1000 records, while receiving records from the RabbitMQ line and processing in python processes. And alco is able to insert records into each index in several streams, although we did not grow up to complete sharding of sphinxsearch on machines: there are not so many interesting logs in production that it becomes critical.
Small trick with config
The attentive reader will notice (c) that the sphinxsearch configuration is clearly not static ;-) In general, this is not a secret, and the documentation says that sphinx.conf may well be an executable file if it starts with "shebang". So our config script is written in Python, it goes over http to the alco admin panel and prints the sphinx config file to stdout, generated using the django template engine, creating the missing directories along the way and deleting the indices that are no longer used.
If anyone is interested in our "bicycle", more about alco can be read on github . To try, sphinxsearch, RabbitMQ, MySQL and Redis are enough. And, of course, we will be happy to receive bug reports and pull requests.
')
Source: https://habr.com/ru/post/283026/
All Articles