SDK for the introduction of support for e-books in FB2 format

You know that the Chinese science author Liu Cixin (Liu Cixin, ) with the work of The Three-Body Problem () orth) got the "nobel" in science fiction . Barack Obama ( proof ) and Mark Zuckerberg ( proof ) paid attention to this book.

Olga Braatkhen, on her own initiative, translated the book into Russian ( here you can swing fb2 ), for which she thanks a lot.
')
Another candidate for the “Nobel Prize” in 2016 is Neil Stevenson (who wrote “Avalanche” and “Kryptonomicon”) with the work of Seveneves ( you can swing in English here , it’s a pity that no one took it to Russian).
The developers of EDISON created an Electronic Documents Access Control program, which I wrote about a couple of years ago, and today the SDK will be discussed to introduce support for electronic books in FB2 format.
Introduction
The use of information technology in the library field has led to the emergence of Internet services that provide readers with remote access to a rich set of fiction, scientific and technical literature. These services take the library to a new level. Libraries can unite in a single network, forming a huge geographically distributed base of digitized content, and the provision of library services on the Internet expands the target audience and provides additional income. Key users also receive benefits: no need to spend time traveling to the library, borrow books for personal use and take care of timely delivery; Access to rare literature that is absent in a particular locality is possible. Rights holders can receive royalties by providing content on mutually beneficial terms.
Special attention in library services is given to respecting copyright and copy protection. At the transport level, proprietary formats are used, and client-side software should not save received content on disk.
The main part of the content is formed by manual digitization of physical media using scanners and subsequent text recognition to enable search, but this is not the only source. There are many digital formats designed to store electronic books, and already digitized books in these formats is also not enough. Accordingly, support of various electronic formats in library services is needed. I'll tell you about the development of the SDK (developer's toolkit) for introducing support for electronic books in the Fiction Book format to one of the services.
Task
The content delivery service provides users with paged access to literature in a remote repository. Access to each page is fixed and charged. The service is implemented full-text search, the results of which are highlighted by translucent rectangles. The traffic between the server and the client is protected and is a proprietary binary format.
EDISON programmers were faced with the task of creating an SDK that provides the end developer with a set of ready-to-use functions that help simplify the process of implementing support for e-books in FB2 format, as well as using a common code base when building the server and client side of the solution.
Based on the functionality of the service, the requirements for the SDK feature set were defined in advance:
- obtaining bibliographic information;
- getting the number of pages of the e-book;
- Retrieving full-text search results with links to relevant pages;
- getting the coordinates of the rectangles to highlight the full-text search results;
- getting the content of an arbitrary page in binary format and rendering the page.
Implementation and technology: C ++ / Qt
Decision
The e-book in FB2 is a one-page document. The format does not provide information on how the document should look. First of all, it was necessary to solve the problem of splitting an FB2 document into pages, without duplicating the contents of the document. As a result, an index file format was designed that stores the metadata about the original FB2 document, obtained by parsing the original document, rendering and splitting the document into pages.
The index file contains the location of the XML document fragments as an offset from the beginning of the document and the fragment length in the number of characters, as well as the XML prefix.
The structure of the index file includes three sections:
- description - a fragment with the description of the document;
- binary - fragments with pictures in the original document;
- page - fragments of the document, where the pages obtained as a result of rendering with the specified page size, indentation and font parameters begin and end.
Information about the location of a fragment of an XML document allows you to subtract the necessary piece of information from the original document without having to parse it; the XML prefix allows you to build a miniature XML document containing markup of only the necessary page, parse it and immediately render the necessary page upon user request.
An example of an index file with a pagination of the document.
<document> <description> <fragment> <offset>418</offset> <length>5230</length> <prefix><![CDATA[<FictionBook xmlns="http://www.gribuser.ru/xml/fictionbook/2.0" xmlns:xlink="http://www.w3.org/1999/xlink">]]></prefix> </fragment> </description> <binary id="cover.jpg" > <fragment> <offset>43034</offset> <length>48151</length> </fragment> </binary> <page number="1" > <fragment> <offset>5657</offset> <length>1779</length> <prefix><![CDATA[<FictionBook xmlns="http://www.gribuser.ru/xml/fictionbook/2.0" xmlns:xlink="http://www.w3.org/1999/xlink"><body>]]></prefix> </fragment> </page> <page number="2" > <fragment> <offset>7436</offset> <length>2366</length> <prefix><![CDATA[<FictionBook xmlns="http://www.gribuser.ru/xml/fictionbook/2.0" xmlns:xlink="http://www.w3.org/1999/xlink"><body><section><section><p>]]></prefix> </fragment> </page> </document> When the idea of a pagination algorithm appeared, we started to implement it. For the formation of the index, the method of streaming parsing of the original document using the standard Qt library classes was chosen, thanks to the possibility of sequentially reading the XML file and storing the offset information in the file in the number of characters using the QXmlStreamReader :: characterOffset method.
In the process of parsing an FB2 document as you move from tag to tag, the paragraphs of the document are broken down into sets of words, which are then reassembled into lines. In accordance with the settings file, each line is set to the maximum width, taking into account the specified width of the page margins and the indent for paragraphs. For lines, the line spacing specified in the settings file is also set. Depending on the tags of the XML document, the font parameters, size, style and alignment are set. For headings and subtitles, center alignment is set, for epigraphs, right alignment, by default, left alignment. As words are added to the string, the length of the string is recalculated by adding the length of all the words added. If the length of the line exceeds the specified width of the page, then the line is added to the page object; a word that does not fit into the line is added to the next line. As you add lines to the page, the height of all lines is recalculated, taking into account the line spacing. When introducing images for the height of the line I had to consider the maximum height of the object added to the line. If the height of all added lines exceeds the specified page height with regard to indents, the next fragment is added to the index file. The described algorithm is used both when splitting an FB2 document into pages, as well as with random access to a page by means of using an index file.
Since the QXmlStreamReader :: characterOffset method returns the offset in the number of characters, not in bytes, when randomly accessing the pages of the document, you had to read the beginning of the original file, and only then read the interesting part of the document, since the document can contain Cyrillic and Latin characters, and only one file offset in bytes using the seek method would inevitably lead to errors.
QString Document::documentFragment(uint offset, uint length) { QString fragment; QFile file(m_fileName); if (!file.open(QIODevice::ReadOnly)) { m_error = IOError; return fragment; } QTextStream fileStream(&file); fileStream.setCodec("UTF-8"); fileStream.setAutoDetectUnicode(true); fileStream.seek(0); fileStream.read(offset); fragment = fileStream.read(length); file.close(); if ((uint) fragment.size() < length) { m_error = IOError; fragment = QString(); return fragment; } return fragment; } Despite this, there is no loss in performance, access to the last page of the document is as fast as the first page, and takes less than a second. The fact is that the average volume of a book without pictures in the FB2 format rarely exceeds 10 MB.
Splitting a 7 MB file into 998 pages and preparing the index takes about 10 seconds. Splitting a 9 MB file into 1576 pages takes about 15 seconds. On average, about 100 pages are rendered per second. If there is an index, the document opens in 50 milliseconds.
Next was to solve the problem of full-text search with reference to the pages of the document. And here, to ensure speed, I still had to duplicate the contents of the document, but without the XML markup, but as a plain text file. Markers of the beginning and end of the page are inserted into the text index as a zero byte. To bind the search results to the pages and store the coordinates of the rectangles, it was necessary to organize two auxiliary indices in binary format. A sub-index for binding search results to pages stores the page number, the sequence number of the start and end bytes of the page marker in the text index.
Full-text search was carried out using the library provided by the customer, which returns all word forms for a given word. The search query is divided into a set of words, then for each word there are all word forms, then by the generated array of the found word forms a search is performed in the text index. Using an auxiliary index and page start / end markers, the text index determines the page numbers to which the search results belong. The auxiliary index with the coordinates of the rectangles is formed only when the page is requested. A separate index file is formed for each page. In the process of obtaining the coordinates of the rectangles, the same algorithm of splitting the original document into pages is used due to the division of lines into words and the calculation of the boundaries of each word, and the index is used in order not to call this algorithm again when going to the same page.
Creating indexes for full-text search takes about a minute on documents of about 10 MB. The search, if there are indexes, works for about one second on a document with 1576 pages.
Another surprise was the display of translucent rectangles over the found text fragments. Since the original mathematics for calculating the boundaries of words was in pixels, this caused inaccuracies of a few pixels when scaling pages of the document. The solution was found: it was necessary only to translate all calculations into inches taking into account the DPI output device, using floating point values instead of integer values, correcting a significant part of the code.
m_dpiX = (qreal) QApplication::desktop()->physicalDpiX(); m_dpiY = (qreal) QApplication::desktop()->physicalDpiY(); QFontMetricsF fm(m_font); m_rect = fm.boundingRect(m_text); m_textDescent = fm.descent() / m_dpiY; qreal width = m_rect.width() / m_dpiX; qreal height = m_rect.height() / m_dpiY; m_rect.setSize(QSizeF(width, height)); At the finish line, it remained to solve the problem of serializing the page view, including a set of rectangles, into a binary format and reading back from it to transfer the page content to the client and then render it using the same SDK. Everything turned out to be quite simple here: the standard class of the QT, QDataStream library came to the rescue.
In the process of decomposition in solving the problem, the following classes were identified.
- Fb2Document - FB2 document, the main class, encapsulates the logic of document parsing, pagination, index creation, providing access to an arbitrary page using the generated index, as well as full-text search.
- Fb2Page - an FB2-document page, encapsulates the logic of filling a page with a set of document lines and rendering a page, defining the sign of the end of a page. Provides an interface for setting the page size in inches in width and height, as well as indents from the edges of the page.
- Fb2Word is a word, encapsulates the logic of calculating the word boundaries in inches on the document outline, in accordance with the specified font parameters, serializing the words of the document page to the binary format, reading words from the binary format.
- Fb2String - a string from a set of words (Fb2Word), encapsulates the logic of filling strings with a list of words, determining the end of a string, aligning the string to the left, right and center, taking into account the line spacing of the document specified in the binary format, reading from strings from binary format.
- Fb2Image - image, encapsulates the logic of rendering document images, serializing images into a binary format, reading pictures from a binary format.
- Fb2Index - index, encapsulates the logic of forming the index file and reading from it.
- Fb2Fragment - a fragment of the FB2-document, represents the main structure of the index file.
- Fb2Settings - settings file, encapsulates the logic of working with the read / write settings file.
- Fb2Func - class wrapper, provides a set of SDK functions in accordance with the interface specified when setting the task.
- Dictionary - class wrapper over a morphological dictionary.
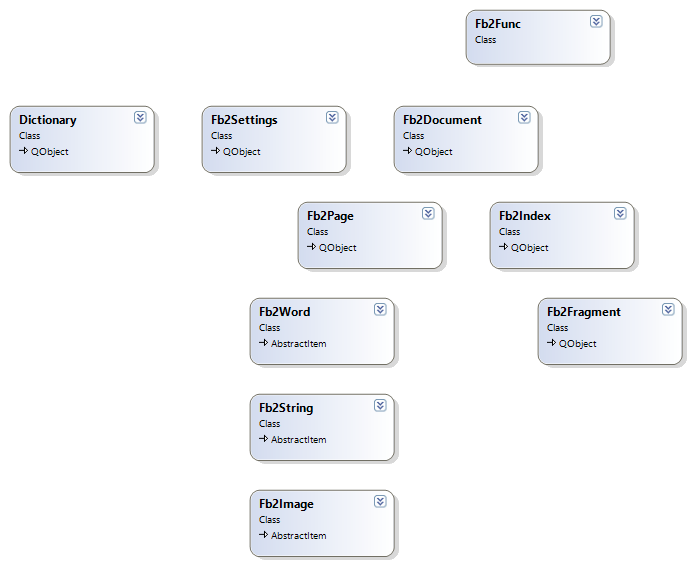
The methods of all SDK classes were covered with unit tests to ensure that the FB2 document is paginated correctly, and that the user in the client program sees exactly the same picture when the page is requested, which will be initially rendered on the server side when preparing the index file.
As a result, the ultimate goal was achieved. The advantage of developing an SDK over a boxed solution is flexibility. The most difficult part is hidden behind the call of simple functions, and the developer using the SDK can make decisions on how to use it: for example, whether to build indexes in advance to ensure the speed of system functions and more comfortable user experience or to build indexes on the first access to the document and the first search engine. request and delete them with rare use to save disk space.
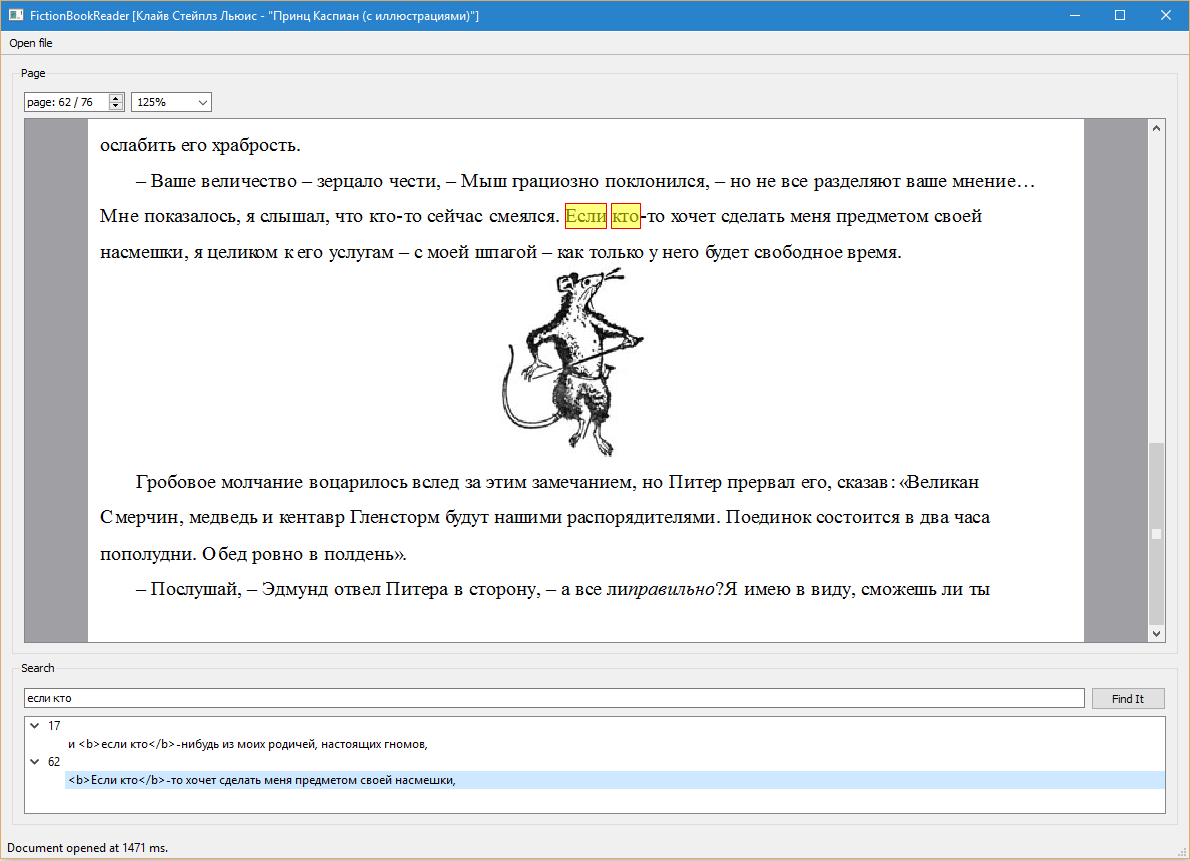
To demonstrate the performance of the SDK to the customer, on its basis two Desktop applications were implemented. FictionBookReader provides the functionality of a primitive FB2 document reader with the ability to paginate and full-text search with highlighted search results.
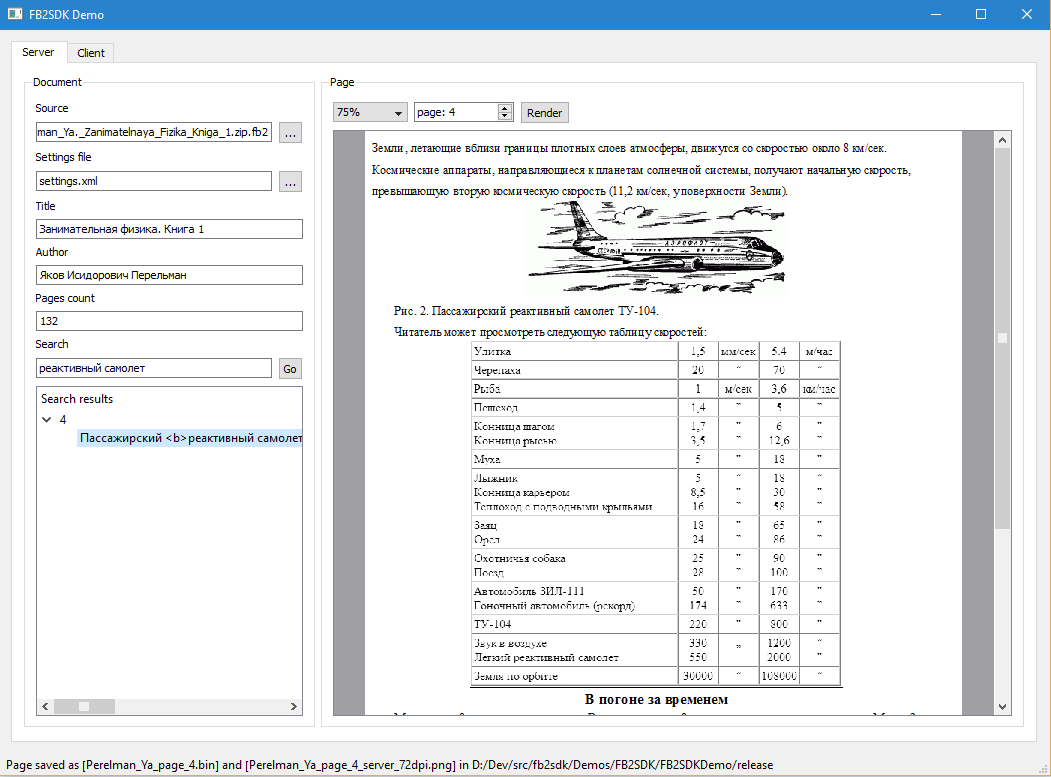
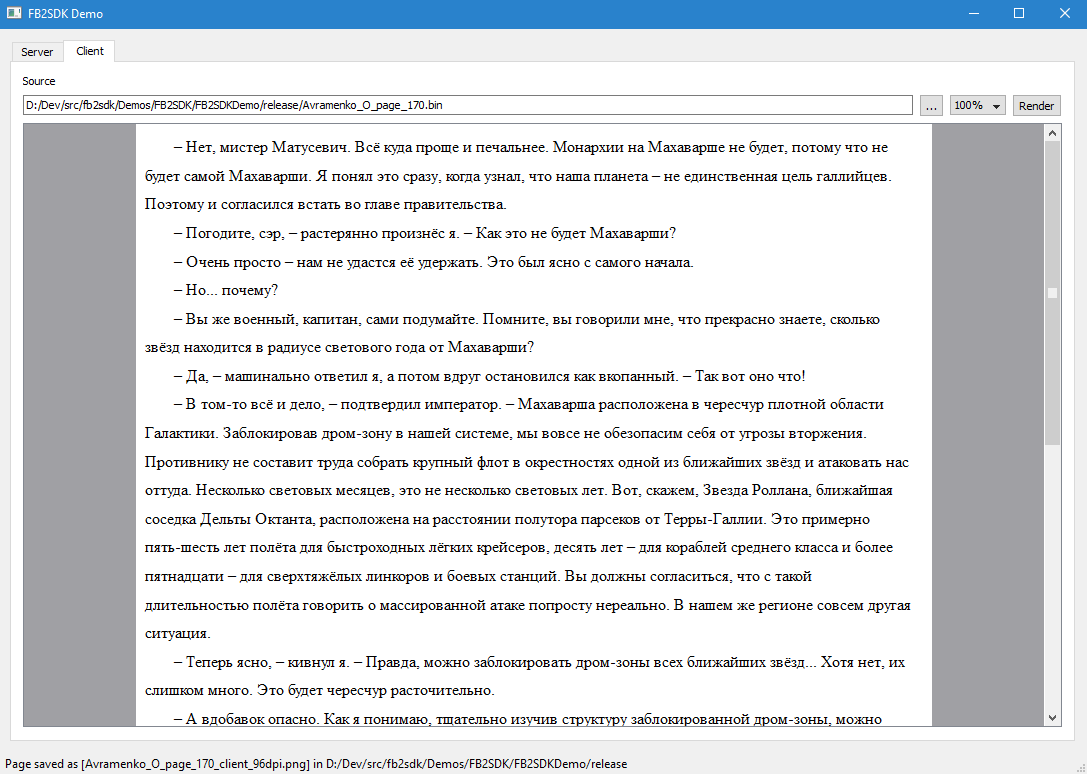
FB2SDK Demo clearly shows the functionality of the server and client side of the SDK. The server side functionality is highlighted in the Server tab, which demonstrates document parsing and the formation of a multi-page index, as well as the formation of files with rectangles and a full-text index. The client-side functionality is highlighted in the Client tab, which demonstrates the rendering of the document page using the generated binary file.

More projects:
How to create software for a microtomograph for 5233 man-hours
SDK for the introduction of support for e-books in FB2 format
Control access to electronic documents. From DefView to Vivaldi
We integrate two video surveillance systems: Axxon Next and SureView
More about the development of x-ray tomograph software
Sphere: how to monitor billions of kilowatt-hours
Developing a simple plugin for JIRA to work with a database
To help DevOps: a firmware builder for network devices on Debian for 1008 hours
Windows Service Auto Update for Poor AWS
Source: https://habr.com/ru/post/282804/
All Articles