Perfect HTTP performance
One aspect of the concept of "Web performance" is to reduce user observable delays; get the page ready for work as quickly as possible. With respect to the HTTP protocol, this implies that the ideal communication protocol looks something like this:

The client sends the minimum required amount of data to describe his request, and the server gives him the minimum necessary amount of data to display the page and all this happens in the minimum possible number of communication rounds. The extra data sent to the server or received from the server means an increase in load time and an increased chance of packet loss, congestion of the communication channel. The extra cycles of sending / receiving data due to the "talkativeness" of the protocol and the delay (especially in mobile networks, where 100ms is the best possible response time ) also worsen the situation.
')
So, if we described the ideal case, does the HTTP protocol match it? And can we somehow improve it?
HTTP / 1.1
HTTP / 1.1 is a good protocol for a number of reasons, but, unfortunately, performance is not one of them due to the way modern web applications use it. And they use it today like this:
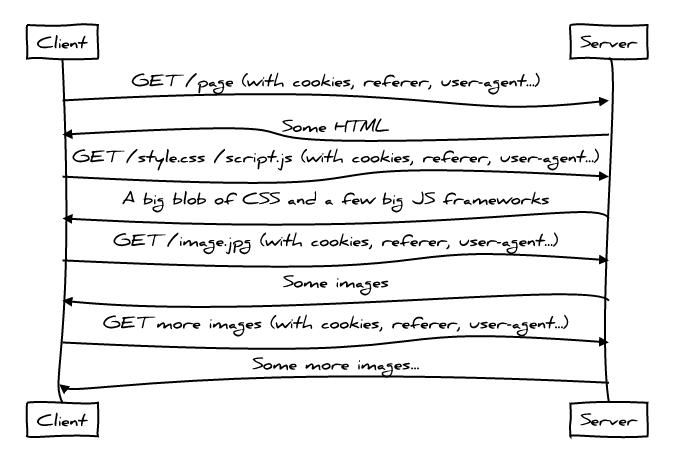
Not very good.
The use of HTTP / 1 by web applications is quite “talkative”, since the client is accessing the server again and again to download the files it needs; HTML is loaded first, then CSS and Javascript. Downloading each next file is added to our “conversation” with the server, a new chapter increases the overall delay in loading the page, breaking our rule of “minimality of the necessary communication rounds”.
Moreover, even requests themselves to resources already add a lot of unnecessary data, breaking the rule of “minimality of necessary data”. This is due to the presence of headers like Referer, User-Agent and, of course, Cookies, which are repeated in each request, sometimes multiplying by a hundred times the minimum required number (by the number of resources required by the average page of the modern Web).
And finally, due to the inherent HOL-blocking phenomenon of HTTP / 1, it has become common practice to put several separate resources into one (for example, CSS spriting ). All these elegant HTTP / 1 hacks, however, come at a price; they force the client to load more data than he needs at the moment to display a specific page, which violates the ideal case described by us, which means we will not show the page as quickly as possible.
Despite all this, HTTP / 1.1 is still not that bad, even in terms of performance. For example, it has caching , which saves you from reloading unchanged resources, as well as conditional requests , which allows you to understand whether you need to download a new version of the file.
HTTP / 2
The HTTP / 2 protocol tries to solve problems 1.1 in several ways:
Thus, a communication session using the HTTP / 2 protocol looks like this:

Here you can see how the server starts sending CSS and Javascript to the client even before the client has asked for it. The server knows that the client who requested the HTML will most likely request the related CSS and Javascript files, which means you can send them without waiting for the request itself. Thus, we lose less waiting time, use the network more efficiently.
It should be noted, it all works not so easy. So far HTTP / 2 has open questions regarding what and when the server should be considered necessary to be sent without a client request.
HTTP / 2 + cache digests
A good question regarding the file transfer initiated by the server: “What if the client already has a copy of it in the cache?”. Indeed, it would be foolish to force the client to send something that he already has.
HTTP / 2 allows the client in this case to complete the download of such a resource ahead of time using the RESET_STREAM message. But even in this case, extra data is being chased by us, one more communication round is being added, which we would like to avoid. You remember the rule from the first paragraph of the article: “send only the minimum necessary amount of data to display the page”.
The proposed solution to the problem is to give the client the opportunity to form a compact cache digest and send it to the server so that he knows what resources the client does not exactly need.

Since cache digests use Golomb codes , it's realistic to assume that for an average page size, the browser will need less than 1000 bytes to explain to the server what resources it has in the cache.
Now we really avoid unnecessary communication cycles between the client and the server, transferring unnecessary data, stitching several files into one and similar hacks, as well as inefficient sending of unnecessary data to us. This brings us very close to the ideal!
Cache digests are only a proposal for expanding the protocol, but the HTTP community has a great interest in them. We will definitely see and evaluate their use in the very near future.
Tcp
Let's talk about the impact on the overall performance of other protocols used by the browser to load pages. And it can also be significant: TCP uses a threefold handshake before the first byte of the HTTP value above is sent:

This adds "talkativeness" to each conversation. TCP Fast Open allows applications to send data directly to SYN and SYN + ACK packets. Unfortunately, this is currently supported only in Linux and OSX, and moreover, there are some features of using TCP Fast Open with the HTTP protocol that the community is currently working on. For example, it is not guaranteed that the data attached to the SYN packet will be sent only once. This opens up a potential repeated request vulnerability that can be used for attacks. Thus, a POST request is not the best candidate for using TCP Fast Open. Moreover, some GET requests also have noticeable side effects, and browsers have no means to distinguish such requests from those that do not have such effects.
Tls
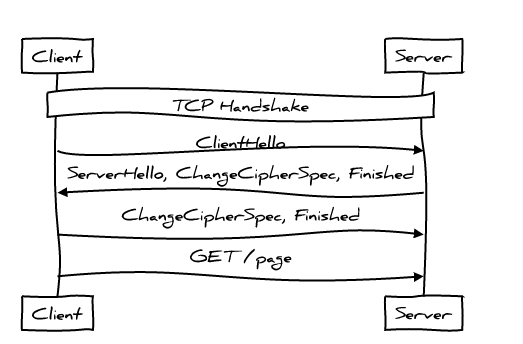
TLS adds another layer of client and server interaction, after the TCP connection has been established. It looks like this:

These are two complete message exchanges before the HTTP protocol sends its first request; quite talkative, isn't it? If the client and the server have already communicated before, we can somewhat reduce the communication:
Soon TLS 1.3 will allow to achieve a “zero” handshake for the case when the client and server have already communicated before - in other words, the HTTP protocol will be able to add the payload already to the first data packet sent to the server. But just as with TCP Fast Open, you need some solution to avoid duplicate requests.
HTTP / next
TCP Fast Open and TLS 1.3 reduce the number of client and server communication cycles when opening a connection. Another way to achieve the same is to reuse a previously opened connection. Now there is a discussion about how to combine HTTP / 2 connections more aggressively; This will not only avoid the cost of opening new connections, but also make more efficient use of the existing ones - TCP is the best option for long-lived, tightly populated connections. This includes sending certificates to the client , proving that the connection can be safely reused to work with other sources.
Even more drastic experiments are being discussed: replacing TCP with UDP, like QUIC . There are many controversial issues, but the prospect of reducing the initial data exchange to virtually zero is very attractive. Moreover, the ability to access data in the wrong order as it was sent can also be very useful. This is another way to avoid HOL-blocking in TCP (a protocol with ordered packet delivery). We can choose from the stream of packets we need, understand that some have been lost, request them again - and continue processing the next ones without waiting for the results of the second request.
QUIC is just beginning its journey, so we still will not see its good implementation for a while (or maybe never at all). One of the possible options is to use the example of QUIC to examine all the pros and cons of the approach in order to understand how we can improve TCP performance without hitting such drastic changes in the Web architecture.
The client sends the minimum required amount of data to describe his request, and the server gives him the minimum necessary amount of data to display the page and all this happens in the minimum possible number of communication rounds. The extra data sent to the server or received from the server means an increase in load time and an increased chance of packet loss, congestion of the communication channel. The extra cycles of sending / receiving data due to the "talkativeness" of the protocol and the delay (especially in mobile networks, where 100ms is the best possible response time ) also worsen the situation.
')
So, if we described the ideal case, does the HTTP protocol match it? And can we somehow improve it?
HTTP / 1.1
HTTP / 1.1 is a good protocol for a number of reasons, but, unfortunately, performance is not one of them due to the way modern web applications use it. And they use it today like this:
Not very good.
The use of HTTP / 1 by web applications is quite “talkative”, since the client is accessing the server again and again to download the files it needs; HTML is loaded first, then CSS and Javascript. Downloading each next file is added to our “conversation” with the server, a new chapter increases the overall delay in loading the page, breaking our rule of “minimality of the necessary communication rounds”.
Moreover, even requests themselves to resources already add a lot of unnecessary data, breaking the rule of “minimality of necessary data”. This is due to the presence of headers like Referer, User-Agent and, of course, Cookies, which are repeated in each request, sometimes multiplying by a hundred times the minimum required number (by the number of resources required by the average page of the modern Web).
And finally, due to the inherent HOL-blocking phenomenon of HTTP / 1, it has become common practice to put several separate resources into one (for example, CSS spriting ). All these elegant HTTP / 1 hacks, however, come at a price; they force the client to load more data than he needs at the moment to display a specific page, which violates the ideal case described by us, which means we will not show the page as quickly as possible.
Despite all this, HTTP / 1.1 is still not that bad, even in terms of performance. For example, it has caching , which saves you from reloading unchanged resources, as well as conditional requests , which allows you to understand whether you need to download a new version of the file.
HTTP / 2
The HTTP / 2 protocol tries to solve problems 1.1 in several ways:
- Full multiplexing means solving a HOL-blocking problem. You can download all the resources of your page on one HTTP connection and not worry about how many requests will be needed for this. "Optimization" with gluing files into one can be left in the past.
- Header compression solves the problem of redundancy. Now you can fit dozens (or even hundreds) of requests into literally several IP packets. This seriously brings us closer to the “minimum required data set” of our ideal protocol.
- HTTP / 2 allows the server to send data to the client before it is requested by the client, assuming that he will need it soon. This reduces the number of rounds of client and server communication.
Thus, a communication session using the HTTP / 2 protocol looks like this:
Here you can see how the server starts sending CSS and Javascript to the client even before the client has asked for it. The server knows that the client who requested the HTML will most likely request the related CSS and Javascript files, which means you can send them without waiting for the request itself. Thus, we lose less waiting time, use the network more efficiently.
It should be noted, it all works not so easy. So far HTTP / 2 has open questions regarding what and when the server should be considered necessary to be sent without a client request.
HTTP / 2 + cache digests
A good question regarding the file transfer initiated by the server: “What if the client already has a copy of it in the cache?”. Indeed, it would be foolish to force the client to send something that he already has.
HTTP / 2 allows the client in this case to complete the download of such a resource ahead of time using the RESET_STREAM message. But even in this case, extra data is being chased by us, one more communication round is being added, which we would like to avoid. You remember the rule from the first paragraph of the article: “send only the minimum necessary amount of data to display the page”.
The proposed solution to the problem is to give the client the opportunity to form a compact cache digest and send it to the server so that he knows what resources the client does not exactly need.
Since cache digests use Golomb codes , it's realistic to assume that for an average page size, the browser will need less than 1000 bytes to explain to the server what resources it has in the cache.
Now we really avoid unnecessary communication cycles between the client and the server, transferring unnecessary data, stitching several files into one and similar hacks, as well as inefficient sending of unnecessary data to us. This brings us very close to the ideal!
Cache digests are only a proposal for expanding the protocol, but the HTTP community has a great interest in them. We will definitely see and evaluate their use in the very near future.
Tcp
Let's talk about the impact on the overall performance of other protocols used by the browser to load pages. And it can also be significant: TCP uses a threefold handshake before the first byte of the HTTP value above is sent:
This adds "talkativeness" to each conversation. TCP Fast Open allows applications to send data directly to SYN and SYN + ACK packets. Unfortunately, this is currently supported only in Linux and OSX, and moreover, there are some features of using TCP Fast Open with the HTTP protocol that the community is currently working on. For example, it is not guaranteed that the data attached to the SYN packet will be sent only once. This opens up a potential repeated request vulnerability that can be used for attacks. Thus, a POST request is not the best candidate for using TCP Fast Open. Moreover, some GET requests also have noticeable side effects, and browsers have no means to distinguish such requests from those that do not have such effects.
Tls
TLS adds another layer of client and server interaction, after the TCP connection has been established. It looks like this:
These are two complete message exchanges before the HTTP protocol sends its first request; quite talkative, isn't it? If the client and the server have already communicated before, we can somewhat reduce the communication:
Soon TLS 1.3 will allow to achieve a “zero” handshake for the case when the client and server have already communicated before - in other words, the HTTP protocol will be able to add the payload already to the first data packet sent to the server. But just as with TCP Fast Open, you need some solution to avoid duplicate requests.
HTTP / next
TCP Fast Open and TLS 1.3 reduce the number of client and server communication cycles when opening a connection. Another way to achieve the same is to reuse a previously opened connection. Now there is a discussion about how to combine HTTP / 2 connections more aggressively; This will not only avoid the cost of opening new connections, but also make more efficient use of the existing ones - TCP is the best option for long-lived, tightly populated connections. This includes sending certificates to the client , proving that the connection can be safely reused to work with other sources.
Even more drastic experiments are being discussed: replacing TCP with UDP, like QUIC . There are many controversial issues, but the prospect of reducing the initial data exchange to virtually zero is very attractive. Moreover, the ability to access data in the wrong order as it was sent can also be very useful. This is another way to avoid HOL-blocking in TCP (a protocol with ordered packet delivery). We can choose from the stream of packets we need, understand that some have been lost, request them again - and continue processing the next ones without waiting for the results of the second request.
QUIC is just beginning its journey, so we still will not see its good implementation for a while (or maybe never at all). One of the possible options is to use the example of QUIC to examine all the pros and cons of the approach in order to understand how we can improve TCP performance without hitting such drastic changes in the Web architecture.
Source: https://habr.com/ru/post/282517/
All Articles