Antispam in Mail.Ru: how a machine recognizes a hacker by his behavior

Bat's post delivery by sashulka
E-mail is used to solve a wide range of tasks: we get information about bank accounts, discuss work projects, plan trips and much more, which requires us to exchange valuable information. Thus, mail contains a lot of important and confidential data. And of course, our task is to protect them reliably.
We are constantly working on systems that provide accounts with several levels of protection and significantly complicate the lives of intruders. But there is one weak link. This is a password that can be guessed or, for example, stolen on a third-party service. More information about password theft and mail security can be found in a post on this topic.
')
Our task is to protect the user's box, even if the attacker has learned the password and can enter the account. To do this, we have developed a machine learning system that analyzes the behavior in the account and tries to determine who is in it - the owner or hacker.
How to recognize a burglar?
While working on security tasks, we considered the following scenario: an attacker has a login, password, and the ability to successfully authenticate. In this case, the owner of the box can still work in your account and not suspect anything about hacking. We faced a question: is it possible to somehow understand that an attacker is acting in the account? We analyzed many examples of account theft and made sure that hacking almost always involves a change in behavior. We decided to use behavioral characteristics as signs and on the basis of them to conclude whether the account was hacked or not. And of course, in solving this problem, we could not do without machine learning.
How to describe the behavior?
Different users use email differently. Someone starts a working day at ten in the morning, enters the mail, deletes mailings, cleans the Spam folder, then goes to Mail.Ru Cloud, and then goes to read Mail.Ru News. And someone works late in the evening, never deletes letters and conducts correspondence only from mobile devices.
To describe this activity use a number of different signs. For example, user actions (reading and sending letters, deleting, moving between folders), devices from which the user works in the account, his geographical location. You can also take into account transitions to related services and the time of day, which account for the peak of user activity. In addition, there are more complex features, such as printed handwriting . This approach takes into account the speed of typing and the pause between keystrokes. With the printed handwriting, two people can be distinguished just as if we asked them to write a few sentences on paper.
At the system design stage, we decided to start with an analysis of user actions, devices, and geographic location. In our opinion, this is the minimum required set of features, without which it is difficult to manage, and which is easy to add if in the future new requirements will be imposed on the system.
How to build a profile?
The basis of our system is the following principle: each user has his own habits, and any activity in the mail must be compared with these habits. If the behavior significantly deviates from the patterns that have formed, it is a reason to suspect an account hacking.
A set of stable habits is called a profile. To analyze the behavior in the account, for each user we decided to build:
- account action profile;
- geographical location profile;
- profile of devices used.
Consider for example the construction of the most complex profile - action profile. For example, we have a part of the log, from which we want to extract the characteristic habits of the user.

In this example, check is mail checking, read read message, send send message.
In the first step of the algorithm, we will generate all possible combinations of actions that the user can perform in the mail. Let's call them possible patterns . Next, you need to check the frequency characteristics of possible patterns. The most frequent patterns reflect the user's habits. Those that are rare, habits are not, so we exclude them from further consideration.
All possible patterns that match the example of the log in question look like this.
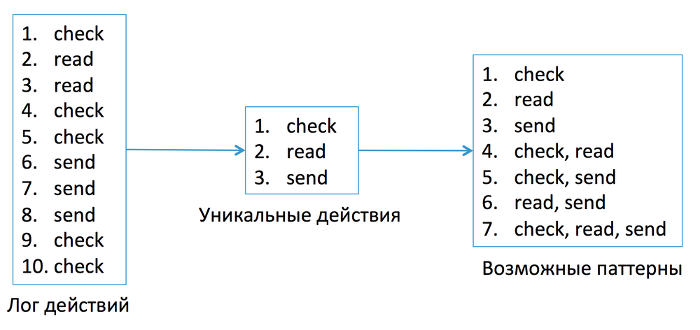
In general, a log can be used to build a profile for a long period of time: for several weeks, for example. During this time, the user has entered the mail many times and solved many problems. But it is obvious that you need to analyze short-term activity sessions, during which the user solved a specific task: he wrote a letter, cleaned a folder, created filters, and so on.
The selection of such sessions is a complex independent task that we wanted to simplify. We decided to try to cut sessions from the log at random: take any action in the log with equal probability as the beginning of the session, and get its duration using some random variable. In this case, the session length must satisfy two requirements:
- it must be positive;
- long sessions should have a small probability, as users solve their problems in the mail for short periods of time.
We decided to obtain the desired session lengths using a gamma distribution, since it is its implementations that meet the specified requirements.
Thus obtained chains of actions will be referred to as transactions . If you take a sufficiently large number of transactions, many of them will overlap with the actual sessions of the user's activity, which means that they reflect his behavior in the mailbox. A sample log sample is provided below.

Thus, we move away from the source log to a set of transactions, and it is this set that we use as the data for building a profile.
Now that moment has come when you need to check which of the possible patterns are really user habits and which are not. Here we need a set of transactions.
For each possible pattern, we calculate the level of support . This is a value that indicates how often a pattern is found in user actions. To calculate the level of support of a specific pattern, you need to count the number of transactions that contain this pattern, and divide it by the total number of transactions. Let's try to calculate the level of support for the “check + read” pattern.

The “check + read” pattern was met in four transactions, there are ten transactions in total, which means that the support level of this pattern is 0.4.
We perform similar calculations for all patterns.

Thus, we obtain the frequency characteristics of each pattern. The higher the level of support pattern, the more it reflects the user's habit. The profile includes those patterns whose support level exceeds a certain threshold. If we take the threshold equal to 0.5, then the “check” , “send” and “check + send” patterns will be included in the profile. They are marked in red in the picture.
So we got a set of patterns that characterize familiar to the user actions in the account. The described approach is called an association rule search algorithm and is used to extract patterns from data.
Using the same algorithm, we build a profile of a user-specific geographical area. But building a profile by device gave an unexpected result. But more on that later.
Now that we know how to build a profile, we need to understand how to compare mail activity with this profile.
How to compare actions with a profile?
We got user habits. Now you need to understand how his activity in the mail matches these habits. Consider the transaction “search + search + send” and try to evaluate numerically how it corresponds to the habits profile (in this transaction, “search” is a search by mail content).

To calculate the measure of the similarity of a transaction to a profile, you need to check which patterns from the profile it contains, add the support levels of these patterns and divide by the total number of all patterns in the profile. In this example, the transaction contains only the “send” pattern, which has a support level of 0.7, and the profile contains three patterns. Then the measure of similarity, which is called the outlier factor (OF), can be calculated like this:
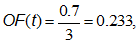
where t is the transaction being tested. But this measure has one drawback - it does not take into account the noise of the transaction.
Consider the transaction “delete filter + move message + create folder + search + send” (deleting the filter, moving a message between folders, creating a folder, searching the mail, and sending a letter) and denote it by r . Obviously, transactions t and r have equal values of the outlier factor measure:
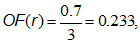
which is not quite true, because transaction r is very noisy with actions that are not in the profile. To eliminate this drawback, another measure is introduced - the long outlier factor , which reflects how much the transaction is similar to profile patterns in length. To calculate the long outlier factor, you need to find the pattern of the maximum length that is contained in the transaction, and divide its length by the length of the transaction. Under the length of the transaction is to understand the number of unique actions that it contains. Then we get:

The LOF metric clearly demonstrates that transaction r is much less similar to a profile than transaction t .
Further, based on the outlier factor and long outlier factor metrics, we calculate the transaction suspicion index :

which will take into account the similarity of the transaction with the profile both in content and in the length of the patterns. The closer the suspicion index is to 1, the stronger the transaction is uncharacteristic for the user. And the closer its value is to 0, the more the transaction coincides with the profile. We calculate the suspicion indices for the considered examples:
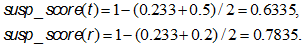
Now we need a threshold with which we could compare the obtained values and decide whether the transaction is abnormal or not. At this stage, you need to return to the set of transactions obtained by sampling the log, and calculate the suspiciousness index for them.

For the user, which we consider as an example, a suspiciousness level of 0.6 is the norm. We can use this value as a boundary value and compare with it the index of suspiciousness of new transactions.
For transactions t and r, we obtained suspicion index values of 0.6335 and 0.7835, respectively. Both values exceed the threshold of 0.6, which means that we take both transactions as suspicious.
Thus, we learned to determine how the user's actions correspond to his habits.
If it becomes necessary to analyze a long chain of actions (for example, user behavior per day), then we cut the chain of actions into transactions using the algorithm described above, and then we check each transaction for suspicion. If the number of suspicious transactions exceeds a certain threshold, then the behavior for the period in question should be considered abnormal.
We use the described algorithms to build a profile of user actions and a profile of his geographic location.
How to deal with devices?
Using pattern processing algorithms, we have learned how to distinguish familiar to the user actions in the account and its characteristic geographical region. In the same way, we tried to build a device usage profile. And they found out that the change of pattern on this basis is not suspicious. Each person has his own set of devices and certain patterns of their use. For example, during the day we work in the mail from a laptop, in the evening from a tablet, and on weekends only from a smartphone. Devices vary depending on the time of day and day of the week, and this is due to the user's preferences.
But still this feature turned out to be very valuable. After analyzing the hacking scripts and comparing them with the behavior of ordinary users, we noticed that the number of devices can tell about hacking. And we decided to use this feature in the future. We compare the number of user devices with a certain critical threshold, and on the basis of this, we decide whether this number is characteristic of a cracker or an ordinary user.
How to detect hacking?
As a result, for each user, we get three signs: an index of suspicion by action, an index of suspicion by change of geographic location and the number of devices. At the very beginning we planned to build a classifier over these signs. Here it is worth noting that the classifier requires additional costs: for it you need to collect a training sample, keep it up to date and fight retraining.
Analyzing the test samples, we noticed the following pattern: exceeding the critical thresholds for two signs out of three corresponded with high precision to cracking.
Thus, we have the opportunity to use logical rules and abandon the classifier, which greatly simplified the development, debugging and maintenance of the entire system.
How to evaluate false positives?
In Antispam there is one very important requirement - we must not harm our users. Restricting a user to an account that is not actually hacked is something that needs to be avoided by all means. Therefore, it was necessary to figure out how to track such false alarms of the system and how to keep statistics on them.
For this we have developed the following approach. For example, a significant change in behavior occurred in the account. We suspected that the account was hacked, and asked the owner to confirm the identity and change the password. After changing the password, we assume that only the owner and no one else is in the account. If, however, after restoring access to the account, the same behavior that previously caused us suspicion continues, then we believe that this behavior is now typical for the user and the system has worked falsely. We include such cases in the statistics for further research, and the user profiles are updated with new behavioral patterns.
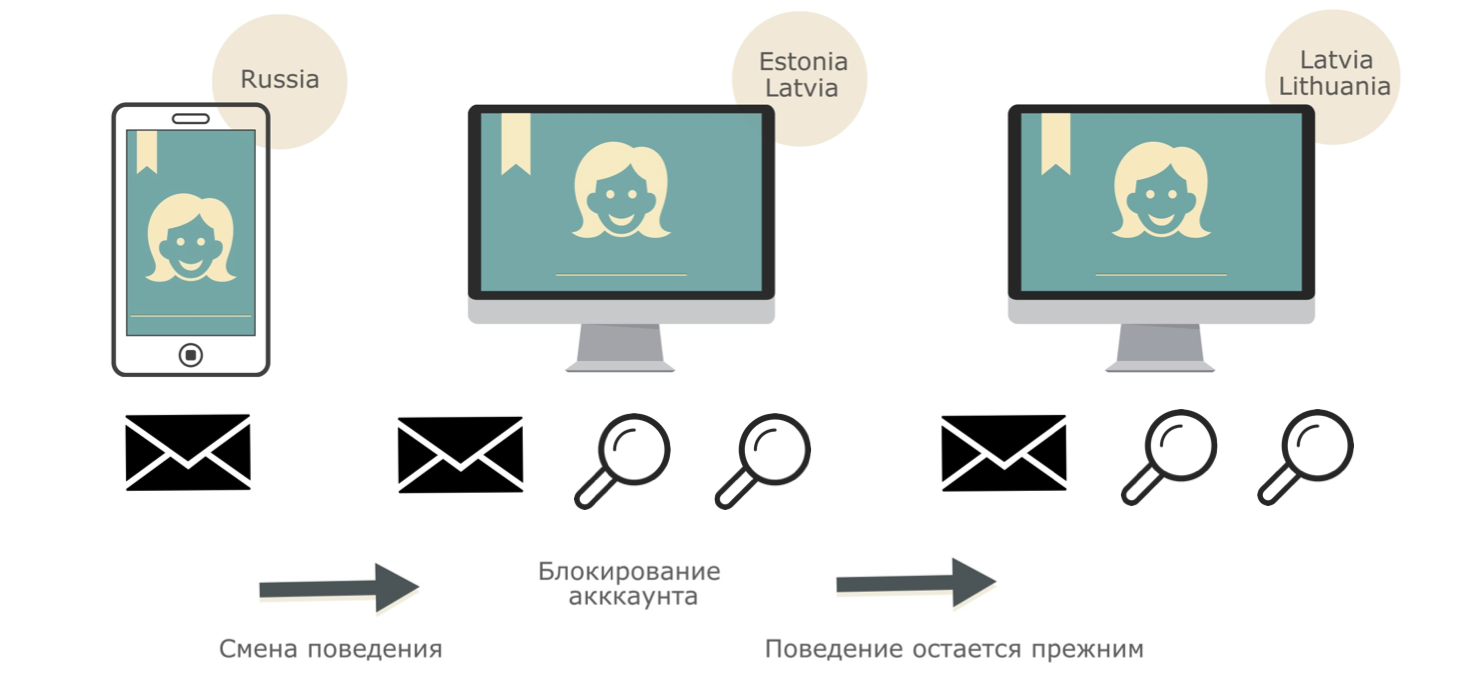
How this approach works can be seen by example. The characteristic behavior of the user in the mail: regular sending letters from a mobile device from Russia. At a certain point, the behavior changes completely: in the box, mass searches from the Baltics begin with a personal computer. The behavior analysis system asks the user to change the password. After changing the password in the account, the search and sending of letters from the Baltic States continue. In this case, we replenish the user profile with new behavioral patterns, and consider the first actuation of the system as false.
results
We developed a machine learning system that attempts to detect hacking by analyzing user behavior in an account. Of course, it is too early to talk about a complete solution: there is still a lot of work ahead, and we have to solve a lot of puzzles. But nevertheless, the results that we have now speak about the prospects of this approach, so we plan to develop it in order to make our services even more reliable.
PS: The system is called Marshal (abbreviated from Mail.Ru Suspicious Hacking Alert). We talked about it in detail at Data Fest, which took place at the Moscow office of Mail.Ru Group on March 5 and 6, 2016. Video presentations and presentations can be found here .
Source: https://habr.com/ru/post/282375/
All Articles