DGA Domain Detection
In this article we will talk about the method of identifying domain names generated using the Domain Generation Algorithm. For example, moqbwfijgtxi.info, nraepfprcpnu.com, ocfhoajbsyek.net, pmpgppocssgv.biz, qwujokiljcwl.ru, our e-mail service, our cfmkugwwgccuit.info, pohyqxdbrqiu.com, your e-mail, your email, your qqmkugwwgccuit.info, pohyqxdbrqiu.com, your e-mail; Such domain names are often given to sites related to illegal activities.
One of the DGA usage scenarios can be observed in the event of malware infection of a computer system. Malicious software on a compromised machine will attempt to connect to systems under the attacker's control in order to receive commands or send back the collected information.
Attackers use DGA to compute the sequence of domain names to which infected machines will attempt to connect. This is done to prevent loss of control over the hacked infrastructure in cases where the domains or IP addresses of the attacker, written directly in the code, are blocked by security systems.
')
Solving the problem of detecting a malicious DGA domain using a blacklist does not work, here a different approach is required. One of these approaches will be discussed.
The basic idea is that the sequences of characters used in legitimate domain names are different from the sequences of characters of domain names obtained using DGA, since the legitimate domain is often human-readable and carries a meaning.
To solve the problem, machine learning and N-gram analysis were used. The top million from alexa (white domains) and 700 thousand from bambenekconsulting.com (malicious domains) were taken as a training sample.
To begin with, the entire set of domains is divided into a training and test sample. On the basis of the training sample of domains, a multitude of N-grams is constructed taking into account their uniqueness. As the N-gram is taken the substring of the domain name of a fixed length.
Consider the example of the DGA-domain Cryptolocker vzdzrsensinaix.com. It will make 11 N-grams 4 characters long.

Fig. 1. Domain Splitting into N-grams
The set of unique N-grams built on the basis of the training sample is divided into three parts: the set of non-harmful N-grams (found only in legitimate domains), the set of malicious N-grams (found only in malicious domains) and many neutral N-grams (found in both types of domains). Each unique N-gram is assigned a numerical coefficient:
Under the trained model, we will understand many pairs
For this task, we have developed a specific sampling method. Its main idea is that as a training sample of the set of malicious and white domains is composed of a set containing a maximum of information about all available domains. In essence, this means that for any domain from the test sample there are at least k N-grams in the model belonging to this domain, where k is a predetermined natural number.
In this case, for training, we essentially take as a model the core of our sample. This allows you to avoid situations at the training stage when the next domain from the test sample does not have a single match with the model and, accordingly, it is impossible to make a decision about its belonging to one or another class.
This method of sampling made it possible to improve the accuracy of the classification of domains - compared to, for example, random sampling. The test results of both methods will be presented below.

Fig. 2. Each domain name contains a non-empty intersection with a training set. The minimum number of intersections for each domain is specified in the parameters of the splitting algorithm.
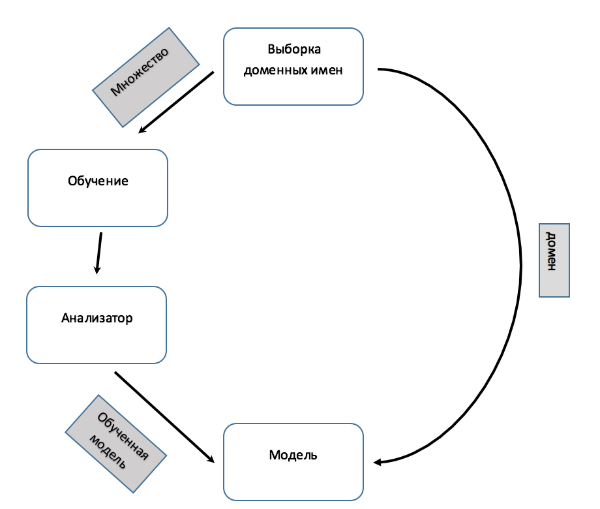
Fig. 3. Scheme of work of the classifier
To determine the harmfulness of the analyzed domain, the algorithm calculates the recursive function:
We illustrate the operation of the analyzer on the example of a malicious (pushdo bot) domain.
jrgxmwgwjz.com (α = 0.9; T = −1.5)
Table 1. An example of the analyzer:
−1.99 <T therefore the domain is malicious. The threshold value T is determined empirically based on the studies performed (see Fig. 4).
Now let's take a closer look at the coefficients of neutral N-grams. To obtain these coefficients, an evolutionary algorithm is used (evolutionary algorithms are a family of algorithms designed to solve optimization problems based on the principles of natural evolution), in which a vector of N-gram coefficients is taken as an individual of a population.
The task of this implementation of the evolutionary algorithm is the calculation of optimal numerical values for neutral N-grams. The solution obtained as a result of the work of the evolutionary algorithm is the vector of values of the coefficients of neutral N-grams, which ensures the greatest accuracy of the classifier. The accuracy of the classifier is estimated by the value of a non-decreasing objective function chosen as a result of experimental testing:
The closer the Fitness value is to 2, the higher the classification accuracy.
To assess the effectiveness of our proposal, a series of experiments was conducted on a sample of domains. The entire set of domains was divided into two parts: a training and test sample.
Table 2. Sizes of the studied samples:

Fig. 4. The choice of the optimal threshold
From the graph in fig. 4 it follows that the optimal threshold value is −1.5, since a balance is reached between false positive and false negative (both errors of the order of 1%).

Fig. 5. Comparison of sample breaks
Experiments have shown that our proposed method has a sufficiently high classification accuracy, which additionally increases with the application of the developed partitioning method.
Posted by Alexander Kolokoltsev, Positive Technologies
One of the DGA usage scenarios can be observed in the event of malware infection of a computer system. Malicious software on a compromised machine will attempt to connect to systems under the attacker's control in order to receive commands or send back the collected information.
Attackers use DGA to compute the sequence of domain names to which infected machines will attempt to connect. This is done to prevent loss of control over the hacked infrastructure in cases where the domains or IP addresses of the attacker, written directly in the code, are blocked by security systems.
')
Solving the problem of detecting a malicious DGA domain using a blacklist does not work, here a different approach is required. One of these approaches will be discussed.
The basic idea is that the sequences of characters used in legitimate domain names are different from the sequences of characters of domain names obtained using DGA, since the legitimate domain is often human-readable and carries a meaning.
To solve the problem, machine learning and N-gram analysis were used. The top million from alexa (white domains) and 700 thousand from bambenekconsulting.com (malicious domains) were taken as a training sample.
Method Description
To begin with, the entire set of domains is divided into a training and test sample. On the basis of the training sample of domains, a multitude of N-grams is constructed taking into account their uniqueness. As the N-gram is taken the substring of the domain name of a fixed length.
Consider the example of the DGA-domain Cryptolocker vzdzrsensinaix.com. It will make 11 N-grams 4 characters long.
Fig. 1. Domain Splitting into N-grams
The set of unique N-grams built on the basis of the training sample is divided into three parts: the set of non-harmful N-grams (found only in legitimate domains), the set of malicious N-grams (found only in malicious domains) and many neutral N-grams (found in both types of domains). Each unique N-gram is assigned a numerical coefficient:
- 1 - legitimate,
- −1 - Malicious,
- the numbers from {−1.0..1.0} are neutral.
Under the trained model, we will understand many pairs
{( q, Ng(q))} , where Ng(q) = p , p is the numerical coefficient of the N-gram q, q belongs to Q, Q is the set of all N-grams in the training set.Sample split
For this task, we have developed a specific sampling method. Its main idea is that as a training sample of the set of malicious and white domains is composed of a set containing a maximum of information about all available domains. In essence, this means that for any domain from the test sample there are at least k N-grams in the model belonging to this domain, where k is a predetermined natural number.
In this case, for training, we essentially take as a model the core of our sample. This allows you to avoid situations at the training stage when the next domain from the test sample does not have a single match with the model and, accordingly, it is impossible to make a decision about its belonging to one or another class.
This method of sampling made it possible to improve the accuracy of the classification of domains - compared to, for example, random sampling. The test results of both methods will be presented below.
Fig. 2. Each domain name contains a non-empty intersection with a training set. The minimum number of intersections for each domain is specified in the parameters of the splitting algorithm.
Model training
Fig. 3. Scheme of work of the classifier
To determine the harmfulness of the analyzed domain, the algorithm calculates the recursive function:
I(i) = I(i-1) * α + Ng(q i ) , where q i is the i-th N-gram of the domain, Ng (qi) is the coefficient of the considered N -grams, α is a softening coefficient, I (0) = 0. For acceptable values of the recursive function, the boundary T is defined. As soon as the result of the calculation of the next iteration of the recursive function becomes less than this limit, the corresponding domain is declared malicious.We illustrate the operation of the analyzer on the example of a malicious (pushdo bot) domain.
jrgxmwgwjz.com (α = 0.9; T = −1.5)
Table 1. An example of the analyzer:
| N-grams number | N-gram | Coefficient N-grams from the model | Value recursive function |
|---|---|---|---|
| one | jrgx | -one | −1 |
| 2 | rgxm | 0 | −0.9 |
| 3 | gxmw | 0 | −0,81 |
| four | xmwg | 0 | −0.73 |
| five | mwgw | 0.06 | −0,6 |
| 6 | wgwj | −0.92 | −1.45 |
| 7 | gwjz | −0.68 | −1.99 |
−1.99 <T therefore the domain is malicious. The threshold value T is determined empirically based on the studies performed (see Fig. 4).
Now let's take a closer look at the coefficients of neutral N-grams. To obtain these coefficients, an evolutionary algorithm is used (evolutionary algorithms are a family of algorithms designed to solve optimization problems based on the principles of natural evolution), in which a vector of N-gram coefficients is taken as an individual of a population.
The task of this implementation of the evolutionary algorithm is the calculation of optimal numerical values for neutral N-grams. The solution obtained as a result of the work of the evolutionary algorithm is the vector of values of the coefficients of neutral N-grams, which ensures the greatest accuracy of the classifier. The accuracy of the classifier is estimated by the value of a non-decreasing objective function chosen as a result of experimental testing:
Fitness = P/TP + N/TN + FP/P + FN/NThe closer the Fitness value is to 2, the higher the classification accuracy.
results
To assess the effectiveness of our proposal, a series of experiments was conducted on a sample of domains. The entire set of domains was divided into two parts: a training and test sample.
Table 2. Sizes of the studied samples:
| amount malicious domains | amount legitimate domains | |
|---|---|---|
| Training sample | 60,000 | 70,000 |
| Test sample | 640,000 | 830,000 |
Fig. 4. The choice of the optimal threshold
From the graph in fig. 4 it follows that the optimal threshold value is −1.5, since a balance is reached between false positive and false negative (both errors of the order of 1%).
Quality assessment method
Fig. 5. Comparison of sample breaks
Experiments have shown that our proposed method has a sufficiently high classification accuracy, which additionally increases with the application of the developed partitioning method.
Posted by Alexander Kolokoltsev, Positive Technologies
Source: https://habr.com/ru/post/282349/
All Articles