Network protocol for backing up data in networks with delay and packet loss
The most common way to ensure reliable data storage is to periodically back them up. Modern remote backup services allow you to store backups on a cloud server and have access to them from anywhere in the world.
Data transmission over a distance of thousands of kilometers takes several hundred milliseconds, and some packets simply do not reach the addressee — they are lost along the way. Delay and packet loss have a detrimental effect on the performance of the TCP transport protocol, which is commonly used on the Internet. For example, you are in Moscow and you want to create a backup copy of a 3GB file. Transfer of this file to the server, which is located within the city, will take 10-15 minutes. Now, if you want to restore this file while away from home, say in China, transferring the same file over the network with a delay of the order of hundreds of milliseconds will take several hours.

In this article, we will look at ways to optimize the transfer of backups on the Internet and describe the concept of the remote backup protocol, which will allow you to get a performance boost when working in networks with long delays and packet losses. This article is based on research carried out as part of the master's work of a student at the Academic University of the Russian Academy of Sciences under the guidance of engineers from Acronis.
Let's look at existing ways to solve our problem. First, it is the use of content transfer and distribution networks (CDN). At the same time, data is placed on several geographically distributed servers, which reduces the network route from the server to the client and makes the data exchange process faster. However, when creating backups, the main data stream goes from the client to the server. In addition, there are legal and corporate restrictions on the physical location of data.
')
The next approach is to use WAN optimizers. WAN optimizers are often hardware solutions that eliminate or weaken the main reasons for the poor performance of applications in the global network. To do this, they use mechanisms such as data compression, caching and optimization of the application protocols. Existing solutions of this kind in most cases require additional hardware, do not take into account client mobility, and are also not sharpened for working with remote backup application protocols.
Thus, the existing methods working at the level of transport protocols and below are not suitable for our task. The best solution is to develop an application protocol for remote backup, which can take into account the peculiarities of data transmission over the network. We will deal with the development of just such an application protocol.
Any application protocol uses transport services to deliver data, so it is advisable to start by choosing the most suitable transport protocol. Let's first understand the reasons for the poor performance of the TCP transport protocol. Data transfer in this protocol is controlled by a sliding window mechanism. The window is of fundamental importance: it determines the number of segments that can be sent without receiving confirmation. The regulation of the size of this window has a twofold purpose: to make the most of the connection bandwidth on the one hand and not to allow network overloads on the other. Thus, it can be concluded that the cause of underloading of the channel in the presence of delays and losses is non-optimal control of the size of the transmitter's sliding window. The mechanisms for controlling the TCP congestion window are quite complex, and their details differ for different protocol versions. Improving TCP window management is an area of active research. Most of the proposed TCP extensions (Scalabale TCP, High Speed TCP, Fast TCP, etc.) try to make window management less conservative in order to improve application performance. However, their significant disadvantage is that they are implemented on a limited number of platforms, and also require modification of the kernel of the client and server operating systems.
Considering transport protocols that could show good performance in networks with delay and packet loss, special attention should be paid to the UDT protocol. UDT is a UDP-based data transfer protocol for high-speed networks. The functionality of the UDT protocol is similar to the TCP protocol: it is a full-duplex data stream transmission protocol with pre-established connections, guarantees delivery, and provides flow control mechanisms. The big advantage of the protocol is its work at the application level, which eliminates the need to introduce changes to the kernel of the operating system.
To compare the performance of TCP and UDT, we assembled a test bench, which consisted of a client, a server, and a network emulator. The client and server tasks include network load with continuous traffic with specified parameters (for this we used the iperf utility). The network emulator allows changing the required network characteristics between the client and the server (tc utility from the iproute2 package).
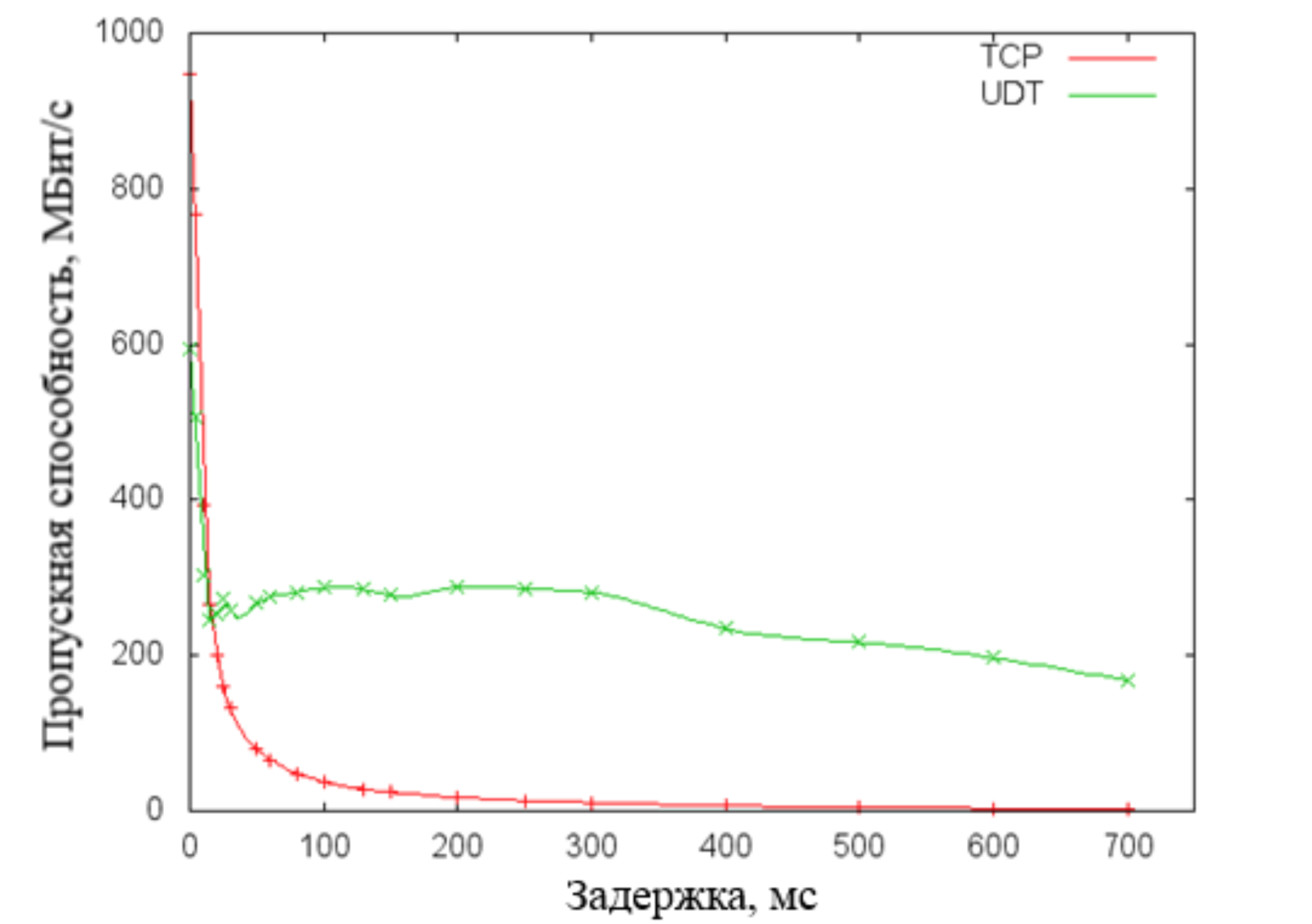
The figure below shows a graph in which it can be seen that the performance of the UDT protocol falls much slower with increasing delays in the transmission network. However, it should be noted that many Internet providers often limit UDP traffic while balancing the loads on network equipment. Thus, on the Internet, the UDT protocol (implemented over UDP) risks losing all its advantages. That is why this protocol is not an effective and universal solution to our problem.
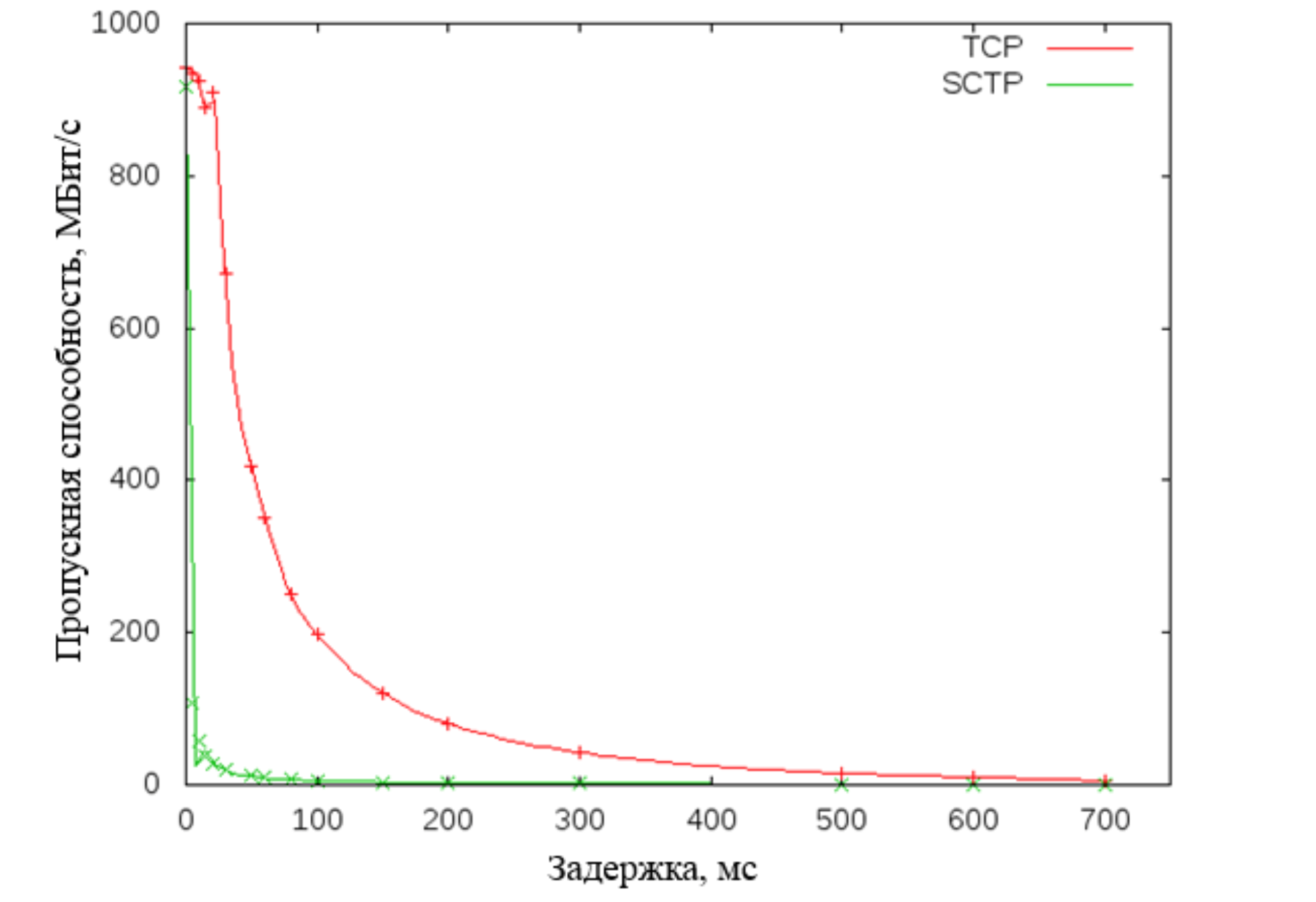
Next, we looked at the SCTP transport protocol. This protocol uses TCP-like sliding window change algorithms, but has several additional advantages: improved error control system, multithreading, path finding with monitoring. However, tests on the bench showed its low performance when working in networks with delays.
As a result, we decided to choose TCP as the transport using a number of optimizations at the application level. One of the possible ways to optimize the performance of the TCP protocol when working with networks with delays and losses is to select the optimal window size (Figures a, b)

The approach to automatically adjusting the size of the window at the kernel level of the OS is very effective and therefore is built into most modern operating systems. However, it is not possible to achieve full utilization of the channel in networks with delays, which is confirmed by tests carried out on a test bench. This is explained by the fact that the automatic adjustment of the window size occurs in a strictly limited interval, which is defined in the OS configuration. Thus, in a channel with a large capacity, the window does not reach its optimal size.
The second optimization method is the creation of several parallel connections (figure c). Let W be the window size of a single connection, which will allow utilization of all available bandwidth P. The bandwidth is equally divided among all active TCP connections. Let them be N, then the available bandwidth for each parallel connection is P / N and, accordingly, the optimal window size is W / N (since W = P * RTT). This means that you can choose an N such that the fixed window size of each parallel connection will be optimal for its throughput. Then each connection will fully utilize the bandwidth allocated to it. This will eventually lead to an increase in the performance of the entire system as a whole.
Creating multiple connections also reduces the negative impact of packet loss on transport performance. When a loss is detected, the TCP protocol multiplicatively reduces the window size. Loss of a packet in one of the connections will reduce only its own window (W / N), and not the window W in the case of a single connection. As a result, the system will be able to quickly restore the maximum bandwidth.
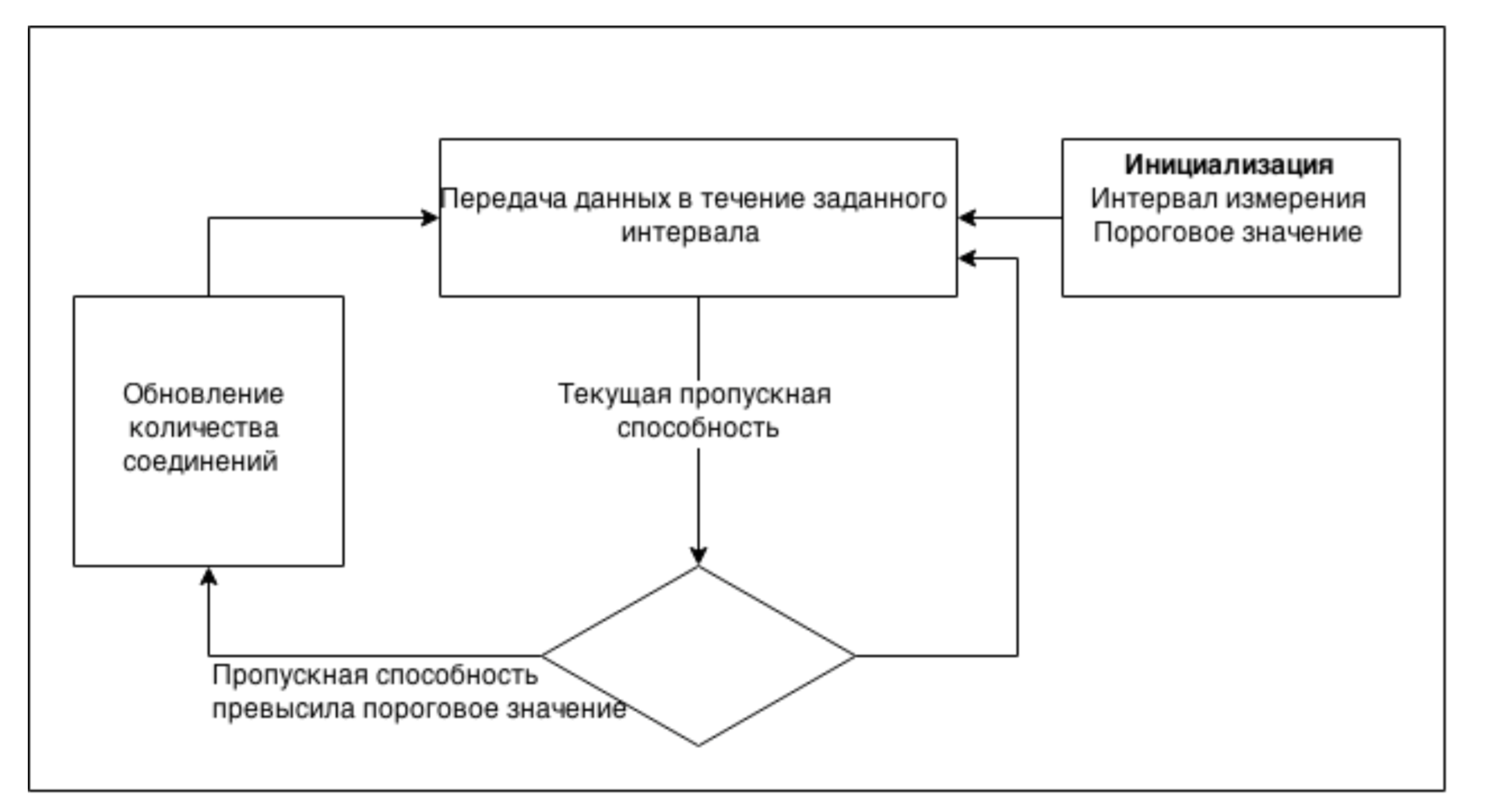
The main problem of this approach is the optimal choice of the number of connections: an insufficient number will underload the network, and an overabundance may cause overloads. The main objective of our application protocol is the transfer of large amounts of data. This makes it possible to use information on the transfer of this data to estimate the current channel capacity. Therefore, to determine the optimal number of connections, it was decided to use the following approach: the number of active parallel connections is determined dynamically and adapts to the current state of the network. Initially, the system is initialized by a bandwidth measurement interval, as well as a threshold value. Next, data is transmitted in parallel across all active connections. Each measurement interval results in throughput estimation based on the transmitted data. The current value is compared with the maximum value and, based on the threshold value, a decision is made on an additive increase or decrease in the number of connections. Then the maximum value is updated and the process is repeated anew. Thus, the number of connections will gradually be established in the region of the optimal value, which will allow to achieve maximum utilization of the channel.
Now let's imagine that you want to create a backup of the operating system of your work computer. It is logical to conclude that the storage server with a high degree of probability already has some separate blocks of your data, which got there from other clients with the same operating system. Obviously, reducing the amount of data transferred can serve as an excellent optimization of the application backup protocol. To this end, we added support for the data deduplication mechanism to our protocol. Its essence is as follows: we divide client data into small segments (our protocol provides only an interface for sending ready-made segments, methods for efficiently partitioning data are a large separate topic); we calculate the hash value of each segment and send a request for its availability to the server; transmit only unique segments over the network.
Let's summarize and briefly describe the model of client-server interaction that our application protocol implements. The client side of the protocol provides the user with a POSIX-like interface for interacting with files on the server. The remote backup procedure begins with opening the required file on the server. In this case, the client initiates a request to start a session, in which the name and attributes of the file opening, as well as the desired session parameters are indicated. The server creates all the necessary resources for processing client requests and responds with a message in which it indicates the result of the request and the parameters of the established session (session ID, deduplication block size, type of hash function).
After creating the session, the client starts writing data blocks to the appropriate file. For each block, the client calculates the value of the specified hash function and sends the server a request for a block. Upon receiving this request, the server checks for the presence of a block in its own deduplication cache:
In order to ensure that each data block is written to the storage area, an asynchronous confirmation mechanism for each block is implemented at the application level. The session ends with the closing of the file and sending to the server a request to end the session. The server responds with a message in which it returns information about the success of the operation. Note also that the client’s tasks include monitoring and controlling local memory resources, as well as monitoring server overloads (based on the received confirmations).
In order to check the characteristics of the obtained solution, we started to implement prototypes of the client and server. The architecture of the network layer of the client and server is based on events that are processed in the same thread (see figure).
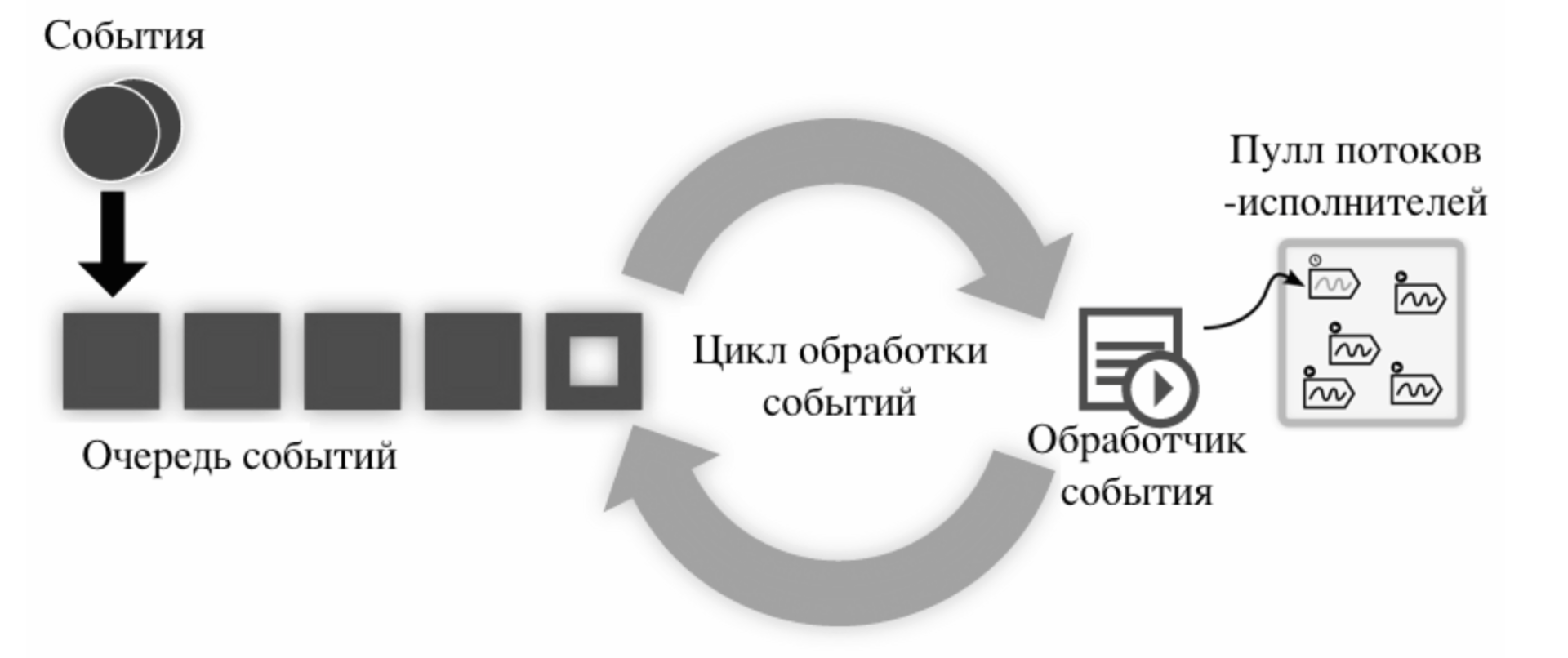
Asynchronous non-blocking I / O mechanisms are used to interact with the network. The basis of the architecture is the main processing loop, which sequentially maintains the event queue (receiving / transmitting data, processing a new connection, etc.). When registering an event, a handler is set, which must be called when an event occurs. In order not to block the processing cycle, the handler delegates all labor-intensive tasks to the thread pool. To implement this architecture, the libevent cross-platform library was chosen.
Server logic also includes:
On the client side there are additionally:
To test the performance of the resulting implementation, a test was conducted at the stand. For each delay value, random data blocks of 8 KBytes were continuously transmitted for 1 minute. Protocol deduplication was disabled.
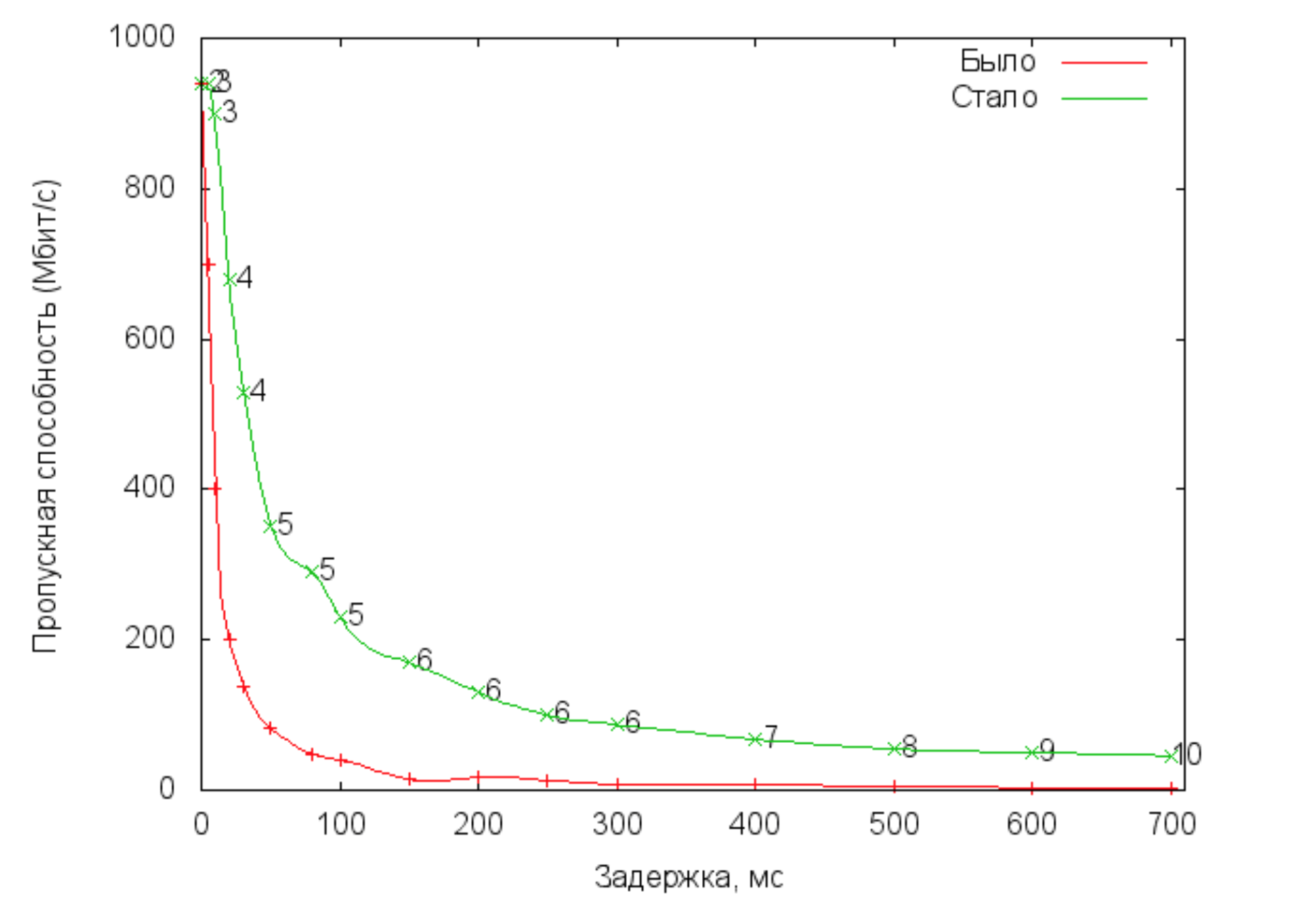
In this graph, we see bandwidth versus latency for various remote backup protocols. “By” is a protocol using a single TCP connection. “Became” is a protocol with dynamic control of the number of TCP connections. Numbers indicate the number of active connections.
In this article, we tried to find approaches and mechanisms to deal with the problem of poor performance of the remote backup protocol in networks with large delays and losses. Dynamic optimization of the number of connections implemented on the client, allows to obtain a significant increase in throughput with large delays in the network. The implemented deduplication mechanism allows to reduce the amount of transmitted traffic, and thus improve the overall system performance. However, for a complete analysis of the effectiveness of deduplication, it is required to perform testing using large amounts of real data and complex non-server caching algorithms, which is beyond the scope of this article and the master's research.
Data transmission over a distance of thousands of kilometers takes several hundred milliseconds, and some packets simply do not reach the addressee — they are lost along the way. Delay and packet loss have a detrimental effect on the performance of the TCP transport protocol, which is commonly used on the Internet. For example, you are in Moscow and you want to create a backup copy of a 3GB file. Transfer of this file to the server, which is located within the city, will take 10-15 minutes. Now, if you want to restore this file while away from home, say in China, transferring the same file over the network with a delay of the order of hundreds of milliseconds will take several hours.
In this article, we will look at ways to optimize the transfer of backups on the Internet and describe the concept of the remote backup protocol, which will allow you to get a performance boost when working in networks with long delays and packet losses. This article is based on research carried out as part of the master's work of a student at the Academic University of the Russian Academy of Sciences under the guidance of engineers from Acronis.
Let's look at existing ways to solve our problem. First, it is the use of content transfer and distribution networks (CDN). At the same time, data is placed on several geographically distributed servers, which reduces the network route from the server to the client and makes the data exchange process faster. However, when creating backups, the main data stream goes from the client to the server. In addition, there are legal and corporate restrictions on the physical location of data.
')
The next approach is to use WAN optimizers. WAN optimizers are often hardware solutions that eliminate or weaken the main reasons for the poor performance of applications in the global network. To do this, they use mechanisms such as data compression, caching and optimization of the application protocols. Existing solutions of this kind in most cases require additional hardware, do not take into account client mobility, and are also not sharpened for working with remote backup application protocols.
Thus, the existing methods working at the level of transport protocols and below are not suitable for our task. The best solution is to develop an application protocol for remote backup, which can take into account the peculiarities of data transmission over the network. We will deal with the development of just such an application protocol.
Any application protocol uses transport services to deliver data, so it is advisable to start by choosing the most suitable transport protocol. Let's first understand the reasons for the poor performance of the TCP transport protocol. Data transfer in this protocol is controlled by a sliding window mechanism. The window is of fundamental importance: it determines the number of segments that can be sent without receiving confirmation. The regulation of the size of this window has a twofold purpose: to make the most of the connection bandwidth on the one hand and not to allow network overloads on the other. Thus, it can be concluded that the cause of underloading of the channel in the presence of delays and losses is non-optimal control of the size of the transmitter's sliding window. The mechanisms for controlling the TCP congestion window are quite complex, and their details differ for different protocol versions. Improving TCP window management is an area of active research. Most of the proposed TCP extensions (Scalabale TCP, High Speed TCP, Fast TCP, etc.) try to make window management less conservative in order to improve application performance. However, their significant disadvantage is that they are implemented on a limited number of platforms, and also require modification of the kernel of the client and server operating systems.
Considering transport protocols that could show good performance in networks with delay and packet loss, special attention should be paid to the UDT protocol. UDT is a UDP-based data transfer protocol for high-speed networks. The functionality of the UDT protocol is similar to the TCP protocol: it is a full-duplex data stream transmission protocol with pre-established connections, guarantees delivery, and provides flow control mechanisms. The big advantage of the protocol is its work at the application level, which eliminates the need to introduce changes to the kernel of the operating system.
To compare the performance of TCP and UDT, we assembled a test bench, which consisted of a client, a server, and a network emulator. The client and server tasks include network load with continuous traffic with specified parameters (for this we used the iperf utility). The network emulator allows changing the required network characteristics between the client and the server (tc utility from the iproute2 package).
The figure below shows a graph in which it can be seen that the performance of the UDT protocol falls much slower with increasing delays in the transmission network. However, it should be noted that many Internet providers often limit UDP traffic while balancing the loads on network equipment. Thus, on the Internet, the UDT protocol (implemented over UDP) risks losing all its advantages. That is why this protocol is not an effective and universal solution to our problem.
Next, we looked at the SCTP transport protocol. This protocol uses TCP-like sliding window change algorithms, but has several additional advantages: improved error control system, multithreading, path finding with monitoring. However, tests on the bench showed its low performance when working in networks with delays.
As a result, we decided to choose TCP as the transport using a number of optimizations at the application level. One of the possible ways to optimize the performance of the TCP protocol when working with networks with delays and losses is to select the optimal window size (Figures a, b)
The approach to automatically adjusting the size of the window at the kernel level of the OS is very effective and therefore is built into most modern operating systems. However, it is not possible to achieve full utilization of the channel in networks with delays, which is confirmed by tests carried out on a test bench. This is explained by the fact that the automatic adjustment of the window size occurs in a strictly limited interval, which is defined in the OS configuration. Thus, in a channel with a large capacity, the window does not reach its optimal size.
The second optimization method is the creation of several parallel connections (figure c). Let W be the window size of a single connection, which will allow utilization of all available bandwidth P. The bandwidth is equally divided among all active TCP connections. Let them be N, then the available bandwidth for each parallel connection is P / N and, accordingly, the optimal window size is W / N (since W = P * RTT). This means that you can choose an N such that the fixed window size of each parallel connection will be optimal for its throughput. Then each connection will fully utilize the bandwidth allocated to it. This will eventually lead to an increase in the performance of the entire system as a whole.
Creating multiple connections also reduces the negative impact of packet loss on transport performance. When a loss is detected, the TCP protocol multiplicatively reduces the window size. Loss of a packet in one of the connections will reduce only its own window (W / N), and not the window W in the case of a single connection. As a result, the system will be able to quickly restore the maximum bandwidth.
The main problem of this approach is the optimal choice of the number of connections: an insufficient number will underload the network, and an overabundance may cause overloads. The main objective of our application protocol is the transfer of large amounts of data. This makes it possible to use information on the transfer of this data to estimate the current channel capacity. Therefore, to determine the optimal number of connections, it was decided to use the following approach: the number of active parallel connections is determined dynamically and adapts to the current state of the network. Initially, the system is initialized by a bandwidth measurement interval, as well as a threshold value. Next, data is transmitted in parallel across all active connections. Each measurement interval results in throughput estimation based on the transmitted data. The current value is compared with the maximum value and, based on the threshold value, a decision is made on an additive increase or decrease in the number of connections. Then the maximum value is updated and the process is repeated anew. Thus, the number of connections will gradually be established in the region of the optimal value, which will allow to achieve maximum utilization of the channel.
Now let's imagine that you want to create a backup of the operating system of your work computer. It is logical to conclude that the storage server with a high degree of probability already has some separate blocks of your data, which got there from other clients with the same operating system. Obviously, reducing the amount of data transferred can serve as an excellent optimization of the application backup protocol. To this end, we added support for the data deduplication mechanism to our protocol. Its essence is as follows: we divide client data into small segments (our protocol provides only an interface for sending ready-made segments, methods for efficiently partitioning data are a large separate topic); we calculate the hash value of each segment and send a request for its availability to the server; transmit only unique segments over the network.
Let's summarize and briefly describe the model of client-server interaction that our application protocol implements. The client side of the protocol provides the user with a POSIX-like interface for interacting with files on the server. The remote backup procedure begins with opening the required file on the server. In this case, the client initiates a request to start a session, in which the name and attributes of the file opening, as well as the desired session parameters are indicated. The server creates all the necessary resources for processing client requests and responds with a message in which it indicates the result of the request and the parameters of the established session (session ID, deduplication block size, type of hash function).
After creating the session, the client starts writing data blocks to the appropriate file. For each block, the client calculates the value of the specified hash function and sends the server a request for a block. Upon receiving this request, the server checks for the presence of a block in its own deduplication cache:
- Match found: the server writes the correct block to the storage area and sends confirmation to the client.
- No match found: the server responds with a message that asks the client to begin transmitting the required block. Upon receiving the block, the server responds with a confirmation.
In order to ensure that each data block is written to the storage area, an asynchronous confirmation mechanism for each block is implemented at the application level. The session ends with the closing of the file and sending to the server a request to end the session. The server responds with a message in which it returns information about the success of the operation. Note also that the client’s tasks include monitoring and controlling local memory resources, as well as monitoring server overloads (based on the received confirmations).
In order to check the characteristics of the obtained solution, we started to implement prototypes of the client and server. The architecture of the network layer of the client and server is based on events that are processed in the same thread (see figure).
Asynchronous non-blocking I / O mechanisms are used to interact with the network. The basis of the architecture is the main processing loop, which sequentially maintains the event queue (receiving / transmitting data, processing a new connection, etc.). When registering an event, a handler is set, which must be called when an event occurs. In order not to block the processing cycle, the handler delegates all labor-intensive tasks to the thread pool. To implement this architecture, the libevent cross-platform library was chosen.
Server logic also includes:
- Session Manager, which is engaged in the correct installation and completion of sessions.
- Deduplication block for caching data and processing requests from the client for the existence of a block.
- Data manager for writing blocks to persistent storage.
On the client side there are additionally:
- Current Bandwidth Estimator. Allows you to evaluate the current throughput at specified intervals. To do this, it receives information about server confirmations and monitors the status of send buffers for all connections.
- Compound Number Optimizer. This block implements the logic for optimizing the number of connections described earlier. This unit also solves the problem of eliminating the effect of random fluctuations in throughput.
- Outbound traffic balancer. Required to evenly distribute data across all active connections.
To test the performance of the resulting implementation, a test was conducted at the stand. For each delay value, random data blocks of 8 KBytes were continuously transmitted for 1 minute. Protocol deduplication was disabled.
In this graph, we see bandwidth versus latency for various remote backup protocols. “By” is a protocol using a single TCP connection. “Became” is a protocol with dynamic control of the number of TCP connections. Numbers indicate the number of active connections.
Conclusion
In this article, we tried to find approaches and mechanisms to deal with the problem of poor performance of the remote backup protocol in networks with large delays and losses. Dynamic optimization of the number of connections implemented on the client, allows to obtain a significant increase in throughput with large delays in the network. The implemented deduplication mechanism allows to reduce the amount of transmitted traffic, and thus improve the overall system performance. However, for a complete analysis of the effectiveness of deduplication, it is required to perform testing using large amounts of real data and complex non-server caching algorithms, which is beyond the scope of this article and the master's research.
Source: https://habr.com/ru/post/282157/
All Articles