Flume - manage data streams. Part 2
Hi, Habr! We continue the series of articles on Apache Flume . In the previous part, we examined this tool superficially and figured out how to configure and launch it. This time the article will be devoted to the key components of Flume, with the help of which it is not terrible to manipulate already real data.

In the last article we looked at the Memory Channel. Obviously, the channel that uses memory to store data is not reliable. Restarting the node will result in all the data stored in the channel being lost. This does not make the Memory Channel useless, there are some cases where its use is very justified by virtue of speed. However, a truly fault tolerant solution is needed for a truly reliable transport system.
Such a solution is the file channel - File Channel. It is easy to guess that this channel stores data in files. At the same time, the channel uses Random Access to work with the file, allowing you to add and pick up events in this way, preserving their sequence. For fast navigation, the channel uses a labeling system (checkpoints), with the help of which the WAL mechanism is implemented. All this, in general, is hidden “under the hood” of the channel, and the following parameters are used to configure it (the bold font is the required parameters).
The remaining settings relate to encrypting data in the channel files and the process of recovery (replay). Now a few words about what needs to be considered when working with the file channel.
')
Alternatively, File-Channel Flume offers several more channels - in particular, the JDBC-channel , which uses a database as its buffer, and the Kafka-channel . Of course, to use such channels, you need to separately deploy the database and Kafka.
Avro is one of the data serialization tools , thanks to which the source and the drain got their names. Networking of these components is implemented using Netty. Compared to Netcat Source, discussed in the previous article, Avro Source has the following advantages:
So, consider the settings that offers us Avro Source.
As with any other source, for Avro Source you can specify:
Also for this source you can configure Netty filters and data encryption settings . You can use this code to send events to this source.
Now consider the configuration of Avro-drain.
Now let's talk about what is important to consider when setting up these components.
So, we figured out how to configure transport nodes based on Avro Source / Sink and file channel. It remains now to deal with the components that close (i.e., output data from the Flume area of responsibility) our transport network.

The first closing stock worth considering is File-Roll Sink. I would say that this is a stock for the lazy. It supports a minimum of settings and can do only one thing - write events to files.
Why do I consider it a drain for the lazy? Because absolutely nothing can be configured in it. No compression, no file name (the timestamp of the creation will be used as the name), no grouping by subfolders — nothing. Even the file size can not be limited. This stock is suitable, perhaps, only for cases when “there is no time to explain - we need to urgently begin to receive data!”.
This stock is already more serious - it supports a lot of settings. It is a little surprising that File-Roll Sink is not made in the same way.
Here is a huge list of settings for HDFS-flow. This drain allows you to cut the data into files almost as you like - especially nice that you can use the date elements. The official documentation on this stock is on the same page .
Perhaps you noticed an interesting feature of the HDFS configuration - there is no parameter indicating the HDFS address. The creators of the drain suggest that this drain should be used on the same machines as HDFS.
So, what should be considered when setting up this flow.
I mentioned these mysterious interceptors many times, now is probably the time to talk about what it is. Interceptors are event handlers that work at the stage between receiving events at the source and sending them to the channel. Interceptors can transform events, modify them, or filter them.
Flume provides many interceptors by default , allowing you to:
, , . , . , Flume, Flume — .
, , . 2 :
. , (, ) .
, . Flume HDFS. — 2000 . roll («15m» «60m»), dir sr — .
, , :
File channel
In the last article we looked at the Memory Channel. Obviously, the channel that uses memory to store data is not reliable. Restarting the node will result in all the data stored in the channel being lost. This does not make the Memory Channel useless, there are some cases where its use is very justified by virtue of speed. However, a truly fault tolerant solution is needed for a truly reliable transport system.
Such a solution is the file channel - File Channel. It is easy to guess that this channel stores data in files. At the same time, the channel uses Random Access to work with the file, allowing you to add and pick up events in this way, preserving their sequence. For fast navigation, the channel uses a labeling system (checkpoints), with the help of which the WAL mechanism is implemented. All this, in general, is hidden “under the hood” of the channel, and the following parameters are used to configure it (the bold font is the required parameters).
| Parameter | Description | Default |
|---|---|---|
type | Channel implementation, must be specified file | - |
checkpointDir | Folder for storing files with tags. If not specified, the channel will use the Flume home folder. | $ HOME / ... |
useDualCheckpoints | Do backup folders with tags. | false |
backupCheckpointDir | The folder for backups of files with labels, you must specify if useDualCheckpoints = true (of course, it is better to keep this backup away from the original - for example, on another disk). | - |
dataDirs | Comma-separated list of folders in which data files will be placed. It is better to specify several folders on different disks to improve performance. If no folders are specified, the channel will also use the Flume home folder. | $ HOME / ... |
capacity | The capacity of the channel indicates the number of events. | 1,000,000 |
transactionCapacity | The maximum number of events in a single transaction. A very important parameter that may affect the performance of the entire transport system. More on this will be written below. | 10,000 |
checkpointInterval | The interval between the creation of new labels, in milliseconds. Tags play an important role during a restart, allowing you to “jump over” portions of the data files when the channel status is restored. As a result, the channel does not re-read the data files entirely, which significantly speeds up the launch when the channel is “clogged”. | 30,000 |
checkpointOnClose | Whether to record the label when closing the channel. The trailing label will allow the channel to recover as soon as possible after restarting - but creating it will take some time when the channel is closed (in fact, very insignificant). | true |
keep-alive | Timeout (in seconds) for adding to the channel. That is, if the channel is clogged, the transaction “will give it a chance” after waiting some time. And if there is no free space in the channel, the transaction will be rolled back. | 3 |
maxFileSize | Maximum file size of the channel, in bytes. The value of this parameter does not determine how much space your channel can “bite off” - it sets the size of a single data file, and a channel can create several of these files. | 2146435071 (2GB) |
minimumRequiredSpace | If your disk has less free space than specified in this parameter, the channel will not accept new events. In case data folders are located on multiple disks, Flume will use | 524288000 (500MB) |
')
- Make sure Flume has the right to write data to folders .
Or, to be more precise, the user, on whose behalf Flume is running, has write rights in the folders for checkpoints and data .
- SSD significantly speeds up the channel .
The graph below shows the sending time of a pack of 500 events to Flume nodes using file channels. One of the nodes uses an SSD to store channel data, the other is SATA. The difference is significant.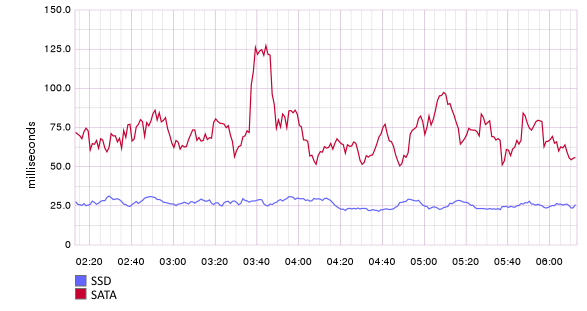
If you perform a simple division, you will find that the Flume node with the file channel on the SSD can digest up to 500 / 0.025 = 20,000 events per second (for reference, the size of the messages in this example is about 1 KB, and the channel uses only one disk to store).
- Channel capacity is very sensitive to change .
If you suddenly decide to change the capacity of your channel, then an unpleasant surprise may be waiting for you - the channel will launch a replay for data recovery. This means that instead of using checkpoints files for further navigation / work with data, the channel will run through all the data files. If there is a lot of data in the channel, the process can take a fair amount of time.
- An abnormal stopping of the channel may result in data loss .
This can happen if you kill the Flume process (or hard reset). And it may not happen. In my memory, this happened to us only once - the data file was “corrupted” and we had to manually delete all the data files of the channel (fortunately, the channels were not clogged and we managed to avoid losses). Thus, the channel still does not give 100% reliability - there is always the possibility that someone will “pull the switch” and the irreparable will happen. Well, if this happens and the channel refuses to start, your actions may be as follows:- Try deleting checkpoints files - in this case the channel will try to recover only by data files.
- If the previous item did not help and the channel writes something in the style of “Unable to read data from channel, channel will be closed”, then the data file is corrupted. Only complete cleaning of all data folders will help here. Alas.
- Try deleting checkpoints files - in this case the channel will try to recover only by data files.
Alternatively, File-Channel Flume offers several more channels - in particular, the JDBC-channel , which uses a database as its buffer, and the Kafka-channel . Of course, to use such channels, you need to separately deploy the database and Kafka.
Avro Source and Avro Sink
Avro is one of the data serialization tools , thanks to which the source and the drain got their names. Networking of these components is implemented using Netty. Compared to Netcat Source, discussed in the previous article, Avro Source has the following advantages:
- May use headers in events (i.e., transmit supporting information with data).
- It can receive information from several clients at the same time. Netcat runs on a regular socket and accepts incoming connections sequentially, which means it can serve only one client at a time.
So, consider the settings that offers us Avro Source.
| Parameter | Description | Default |
type | Source implementation, avro must be specified. | - |
channels | Channels to which the source will send events (separated by spaces). | - |
bind | Host / IP to which we fix the source. | - |
port | The port on which the source will accept connections from clients. | - |
threads | The number of threads that handle incoming events (I / O workers). When choosing a value, you should be guided by the number of potential customers who will send events to this source. You need to set at least 2 streams, otherwise your source may simply “hang”, even if the client has only one. If you are not sure how many threads are needed - do not specify this parameter in the configuration. | not limited |
compression-type | Data compression, there are few options - either none , or deflate . It is necessary to specify only if the client transmits data in a compressed form. Compression will help you significantly save traffic, and the more events you transmit at a time, the more significant this savings will be. | none |
- selector.type is a channel selector, I mentioned them in the previous article. Allow to divide or duplicate events in several channels by some rules. More selectors will be discussed below.
- interceptors - list of interceptors, separated by spaces. Interceptors are triggered BEFORE events get into the channel. They are used to somehow modify the events (for example, add headers or change the contents of the event). They will also be discussed below.
Also for this source you can configure Netty filters and data encryption settings . You can use this code to send events to this source.
Primitive Java-client for Avro Source
import java.util.HashMap; import java.util.Map; import org.apache.flume.Event; import org.apache.flume.EventDeliveryException; import org.apache.flume.api.RpcClient; import org.apache.flume.api.RpcClientFactory; import org.apache.flume.event.EventBuilder; import org.apache.flume.event.SimpleEvent; public class FlumeSender { public static void main(String[] args) throws EventDeliveryException { RpcClient avroClient = RpcClientFactory.getDefaultInstance("127.0.0.1", 50001); Map<String, String> headers = new HashMap<>(); headers.put("type", "common"); Event event = EventBuilder.withBody(" ".getBytes(), headers); avroClient.append(event); avroClient.close(); } } Now consider the configuration of Avro-drain.
| Parameter | Description | Default |
|---|---|---|
type | Implementation of the flow, should be specified avro . | - |
channel | The channel from which the stock will pull the event. | - |
hostname | The host / IP to which the stock will send events. | - |
port | The port on which the specified host machine is listening for clients. | - |
batch-size | A very important parameter: the size of the "packs" of events sent to the client in one request. At the same time, the same value is used when the channel is empty. That is, it is also the number of events read from the channel in one transaction. | 100 |
connect-timeout | Connection timeout (handshake), in milliseconds. | 20,000 |
request-timeout | Request timeout (sending event bundles), in milliseconds. | 20,000 |
reset-connection-interval | Interval "host change". It is understood that several machines serviced by the balancer may be hidden behind the specified hostname . This parameter forces the stock to switch between machines at a specified time interval. Convenience, according to the creators of the runoff, is that if a new machine is added to the balancer’s area of responsibility, there is no need to restart the Flume node - the runoff will figure out that another “destination” has appeared. By default, the stock does not change hosts. | -one |
maxIoWorkers | Analog threads for Avro Source. | 2 * PROC_CORES |
compression-type | The same as for Avro Source. The difference is that the stock compresses the data, and the source, in contrast, unpacks. Accordingly, if Avro Sink sends events to Avro Source, the type of compression on both should be the same. | none |
compression-level | Compression level, only if compression-type = deflate (0 - do not compress, 9 - maximum compression). | 6 |
- Carefully choose Batch Size .
As I have already said, this is a very important parameter, whose ill-considered choice can significantly impair your life. First of all, batch-size must be less than or equal to the transaction capacity of the channel (transactionCapacity). This is clearly Avro Sink and implicitly Avro Source. Consider an example: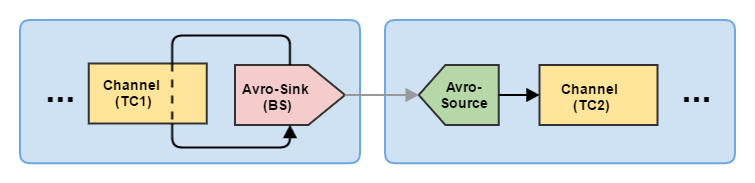
Here TC is transactionCapacity, and BS is batch-size. The condition for normal operation is that: BS <= TC1 and BS <= TC2. That is, it is necessary to take into account not only the transaction capacity of the channel with which the drain works, but the transaction capacity of the channel (s) with which the receiving Avro Source works. Otherwise, the stock will not be able to empty its channel, and the source will not add events to its own. In such cases, Flume begins to intensively log error messages.A case from practice . In one of the stocks we somehow set batch-size = 10,000, while TC = 5000 was set for the channel on the receiving node. And everything worked fine. As long as the amount of data was small, the stock simply didn’t pull 10,000 events at a time out of the channel — the channel did not have time to accumulate so many events. But after a while, the amount of data increased and we started having problems. The receiving node began to reject large bursts of data. The error was noticed in time, the parameters were changed, and the data accumulated in the channel with a mischievous stream began to reach their destination.
- Send events in large batches .
Transaction - the operation is quite expensive in terms of resources. Less transactions - more performance. Again, compression when transmitting a large number of events works much more efficiently. Accordingly, in addition to batch-size, you will have to increase the transactionCapacity of your channels.
- Override the netty dependency for your nodes .
We use the netty version 3.10.5 Final , while Flume pulls up the older netty 3.6.2 Final . The problem with the old version is a small bug, due to which Avro Sink / Avro Source cannot periodically connect to each other. This leads to the fact that in the transmission of data there are periodic idle times for a few minutes (then everything returns to normal). In case the data should arrive as fast as possible, such traffic jams can become a problem.
In case you start Flume with Java tools, you can override the dependency using Maven tools. If you configure Flume using Cloudera or as a service , you will have to manually change the Netty dependency. You can find them in the following folders:- Cloudera - / opt / cloudera / parcels / CDH - $ {VERSION} / lib / flume-ng / lib ;
- Service (stand-aloone) - $ FLUME_HOME / lib .
File Roll Sink
So, we figured out how to configure transport nodes based on Avro Source / Sink and file channel. It remains now to deal with the components that close (i.e., output data from the Flume area of responsibility) our transport network.
The first closing stock worth considering is File-Roll Sink. I would say that this is a stock for the lazy. It supports a minimum of settings and can do only one thing - write events to files.
| Parameter | Description | Default |
|---|---|---|
type | The implementation of the flow must be specified file_roll . | - |
channel | The channel from which the stock will pull the event. | - |
directory | The folder in which the files will be stored. | - |
rollInterval | The interval between the creation of new files (0 - write everything in one file), in seconds. | thirty |
serializer | Serialization of events. You can specify: TEXT, HEADER_AND_TEXT, AVRO_EVENT or your class that implements the EventSerializer.Builder interface. | TEXT |
batch-size | Similar to Avro Sink, the size of a bundle of events taken from a channel transaction. | 100 |
Why do I consider it a drain for the lazy? Because absolutely nothing can be configured in it. No compression, no file name (the timestamp of the creation will be used as the name), no grouping by subfolders — nothing. Even the file size can not be limited. This stock is suitable, perhaps, only for cases when “there is no time to explain - we need to urgently begin to receive data!”.
Note Since there is still a need to write data to files, we came to the conclusion that it is more expedient to implement our own file drain than to use this. Given that all the Flume sources are open, it was not difficult to make it, we did it in a day. On the second day, minor bugs were corrected - and the stock has been working for more than a year already, putting the data into folders in neat archives. I’ll post this stock on GitHub after the third part of the cycle.
HDFS Sink
This stock is already more serious - it supports a lot of settings. It is a little surprising that File-Roll Sink is not made in the same way.
| Parameter | Description | Default |
|---|---|---|
type | Implementation of the flow, should be specified hdfs . | - |
channel | The channel from which the stock will pull the event. | - |
hdfs.path | The folder in which the files will be written. Make sure that this folder has the necessary permissions. If you configure the stock using Cloudera, the data will be written on behalf of the user flume . | - |
hdfs.filePrefix | File name prefix. The base file name, as for File-Roll, is the timestamp of its creation. Accordingly, if you specify my-data , the resulting file name will be my-data1476318264182 . | Flumedata |
hdfs.fileSuffix | Postfix file name. It is added to the end of the file name. Can be used to specify an extension, for example .gz . | - |
hdfs.inUsePrefix | Similar to filePrefix, but for a temporary file to which data is still being recorded. | - |
hdfs.inUseSuffix | Same as fileSuffix, but for a temporary file. In essence, a temporary extension. | .tmp |
hdfs.rollInterval | The period of creation of new files, in seconds. If the files do not need to be closed by this criterion, set 0. | thirty |
hdfs.rollSize | Trigger to close files by volume, indicated in bytes. We also set 0 if this criterion does not suit us. | 1024 |
hdfs.rollCount | Trigger to close files by the number of events. You can also put 0. | ten |
hdfs.idleTimeout | Trigger to close files due to inactivity, in seconds. That is, if nothing is written to the file for a while, it closes. This trigger is disabled by default. | 0 |
hdfs.batchSize | Same as for other stocks. Although the documentation for the drain says that this is the number of events recorded in the file before they are reset to HDFS. When choosing, we also focus on the channel transaction volume. | 100 |
hdfs.fileType | File type - SequenceFile (Hadoop file with key-value pairs, as a rule, the timestamp from the “timestamp” hider is used as the key), DataStream (text data is, in fact, a line recording with the specified serialization, as in File- Roll Sink) or CompressedStream (analogue DataStream, but with compression). | Sequencefile |
hdfs.writeFormat | The recording format is Text or Writable . Only for SequenceFile . The difference is that the value will be written either as text ( TextWritable ) or bytes ( BytesWritable ). | 5000 |
serializer | Configurable for DataStream and CompressedStream , similar to File-Roll Sink. | TEXT |
hdfs.codeC | This parameter must be specified if you use the file type CompressedStream . The following compression options are offered: gzip, bzip2, lzo, lzop, snappy . | - |
hdfs.maxOpenFiles | The maximum number of simultaneously open files. If this threshold is exceeded, the oldest file will be closed. | 5000 |
hdfs.minBlockReplicas | An important parameter . Minimum number of replicas per HDFS block. If not specified, it is taken from the Hadoop configuration specified in the classpath at startup (i.e. your cluster settings). Honestly, I can't explain the reason for the Flume behavior associated with this parameter. The bottom line is that if the value of this parameter is different from 1, then the drain will start closing files without regard to other triggers and in a record time will produce a lot of small files. | - |
hdfs.maxOpenFiles | The maximum number of simultaneously open files. If this threshold is exceeded, the oldest file will be closed. | 5000 |
hdfs.callTimeout | HDFS access timeout (open / close file, reset data), in milliseconds. | 10,000 |
hdfs.closeTries | The number of attempts to close the file (if the first time did not work). 0 - try to the bitter end. | 0 |
hdfs.retryInterval | How often to try to close a file in case of failure, in seconds. | 180 |
hdfs.threadsPoolSize | The number of threads performing IO operations with HDFS. If you have a “hodgepodge” of events that are packaged in many files, then it is better to put this number more. | ten |
hdfs.rollTimerPoolSize | Unlike the previous pool, this thread pool performs tasks on a schedule (closes files). Moreover, it works on the basis of two parameters - rollInterval and retryInterval . Those. this pool performs both a scheduled shutdown by trigger and periodic repeated attempts to close the file. One thread should be enough. | one |
hdfs.useLocalTimeStamp | HDFS stock implies the use of date elements in the name of the generated files (for example, hdfs.path = / logs /% Y-% m-% d will allow you to group files by day). The use of a date implies that it must be obtained from somewhere. This parameter offers two options: use the time at the time the event is processed ( true ) or use the time specified in the event — namely, in the “timestamp” header (false). If you use timestamp events, make sure that your events have this header. Otherwise they will not be recorded in HDFS. | false |
hdfs.round | Round up the timestamp to some value. | false |
hdfs.roundValue | How much to round off the timestamp. | one |
hdfs.roundUnit | In what units to round ( second , minute or hour ). | second |
Perhaps you noticed an interesting feature of the HDFS configuration - there is no parameter indicating the HDFS address. The creators of the drain suggest that this drain should be used on the same machines as HDFS.
So, what should be considered when setting up this flow.
- Use large batch-size and transactionCapacity .
In general, everything here is similar with other drains - the transaction is quite expensive in terms of resources, so it is better to pour large portions.
- Do not abuse macros in file naming .
Using date elements in file / folder names or placeholders for headings is certainly a handy tool. But not very fast. It seems to me that the date creators could have made the most optimal substitution - if you look at the sources, then you will be surprised at the number of operations performed to format these lines. Suppose we decided to set up the following folder structure:
Here dir and src - the values of the event headers with acc. keys. The resulting file will look like /logs/web/my-source/2016-04-15/2016-04-15-12-00-00.my-host.my-source.gz . On my computer, generating this name for 1 million events takes almost 20 seconds ! Those. for 10,000 events, this will take about 200ms. We conclude: if you claim to write 10,000 events per second, be prepared to give 20% of the time to generate the file name. It's horrible. This can be cured by taking responsibility for generating the file name on the client side. Yes, for this you will have to write some code, but you can change the flow settings to these:hdfs.path = / logs /% {dir} hdfs.filePrefix =% {src} /% Y-% m-% d /% Y-% m-% d-% H-% M-% S.% {host}.% {src}
By transferring the generated file name in the file-name header, you will save resources and time. Forming a file path using such a header no longer takes 20 seconds, but 500-600 milliseconds for 1 million events. Ie, almost 40 times faster.hdfs.path = / logs hdfs.filePrefix =% {file-name}
- Combine events .
Another small hack that allows you to significantly improve the performance of the flow. If you write events to the file line by line, then you can combine them on the client side. For example, your service generates logs that should go to the same file. So why not combine several lines into one, using \ n as a delimiter? By itself, writing data to HDFS or a file system takes much less time than all this “digital bureaucracy” around data.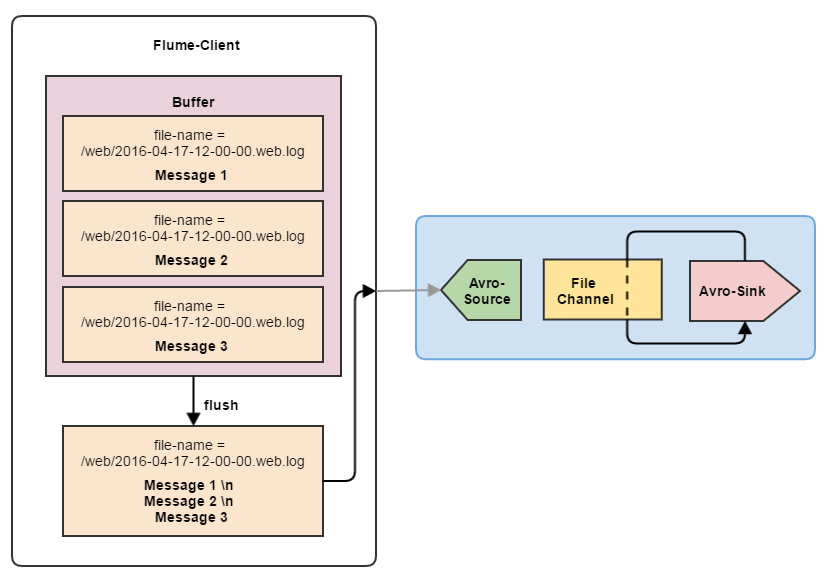
Combining events in a ratio of at least 5 to 1, you already get a significant performance boost. Naturally, you need to be careful here - if the events on the client are generated one at a time, then filling the buffer to combine the events may take some time. All this time, events will be stored in memory, waiting for the formation of a group to combine. This means that the chances of losing data increase. Summary:- For small amounts of data, it is better for the client to send events to Flume one at a time - less likely to lose them.
- For large amounts of data it is preferable to use event combining If events are generated intensively, the buffer for 5-10 events will be typed quickly enough. At the same time you will significantly increase the productivity of wastewater.
- For small amounts of data, it is better for the client to send events to Flume one at a time - less likely to lose them.
- Deploy sewers across multiple HDFS cluster machines .
When configuring Flume via Cloudera, it is possible to start a separate Flume node on each node of the cluster. And it is better to use this opportunity - since in this way the load is distributed among all the cluster machines. However, if you are using a common configuration (i.e., the same configuration file on all machines), make sure that you do not have file name conflicts. This can be done by using the event interceptor, which adds the host name to the headers. Correspondingly, you will only need to specify this title in the template of the file name (see below).Note In fact, when making such a decision, it is worth considering - after all, every stock will write uniform data to its file. As a result, you can get a bunch of small files on HDFS. The solution must be weighted - if the amount of data is small, then you can limit yourself to one Flume node for writing to HDFS. This is the so-called data consolidation - when data from multiple sources end up in a single sink. However, if the data is "flowing river", then one node may not be enough. In more detail about design of all transport network we will talk in the following article of this cycle.
Event Interceptors (Flume Interceptors)
I mentioned these mysterious interceptors many times, now is probably the time to talk about what it is. Interceptors are event handlers that work at the stage between receiving events at the source and sending them to the channel. Interceptors can transform events, modify them, or filter them.
Flume provides many interceptors by default , allowing you to:
- Add static headers (constants, timestamp, hostname).
- Generate random UUID in headers.
- Extract values from the event body (by regular expressions) and use them as headers.
- Modify the contents of events (again regular expressions).
- Filter events based on content.
An example configuration of various interceptors
# ============================ Avro- ============================ # # Vvro- my-agent.sources.avro-source.type = avro my-agent.sources.avro-source.bind = 0.0.0.0 my-agent.sources.avro-source.port = 50001 my-agent.sources.avro-source.channels = my-agent-channel # , ( ) my-agent.sources.avro-source.interceptors = ts directory host replace group-replace filter extractor # ------------------------------------------------------------------------------ # # . # "dir", — "test-folder". my-agent.sources.avro-source.interceptors.directory.type = static my-agent.sources.avro-source.interceptors.directory.key = dir my-agent.sources.avro-source.interceptors.directory.value = test-folder # — ( — false) my-agent.sources.avro-source.interceptors.directory.preserveExisting = true # ------------------------------------------------------------------------------ # # "timestamp" , my-agent.sources.avro-source.interceptors.ts.type = timestamp my-agent.sources.avro-source.interceptors.ts.preserveExisting = true # ------------------------------------------------------------------------------ # # /IP my-agent.sources.avro-source.interceptors.host.type = host my-agent.sources.avro-source.interceptors.host.useIP = true # ( directory.key) my-agent.sources.avro-source.interceptors.host.hostHeader = host my-agent.sources.avro-source.interceptors.host.preserveExisting = true # ------------------------------------------------------------------------------ # # ; my-agent.sources.avro-source.interceptors.replace.type = search_replace my-agent.sources.avro-source.interceptors.replace.searchPattern = \t my-agent.sources.avro-source.interceptors.replace.replaceString = ; # byte[], ( — UTF-8) my-agent.sources.avro-source.interceptors.replace.charset = UTF-8 # ------------------------------------------------------------------------------ # # "" my-agent.sources.avro-source.interceptors.group-replace.type = search_replace # , 2014-01-20 20/01/2014 # . "" 4 () , # my-agent.sources.avro-source.interceptors.group-replace.searchPattern = (\\d{4})-(\\d{2})-(\\d{2})(.*) my-agent.sources.avro-source.interceptors.group-replace.replaceString = $3/$2/$1$4 # ------------------------------------------------------------------------------ # # -, my-agent.sources.avro-source.interceptors.filter.type = regex_filter my-agent.sources.avro-source.interceptors.filter.regex = error$ # true — , , # — , my-agent.sources.avro-source.interceptors.filter.excludeEvents = true # ------------------------------------------------------------------------------ # # , my-agent.sources.avro-source.interceptors.extractor.type = regex_extractor # , : "2016-04-15;WARINING;- " my-agent.sources.avro-source.interceptors.extractor.regex = (\\d{4}-\\d{2}-\\d{2});(.*); # — , # . # (\\d{4}-\\d{2}-\\d{2}) -> $1 -> ts # (.*) -> $2 -> loglevel my-agent.sources.avro-source.interceptors.extractor.serializers = ts loglevel # , TS my-agent.sources.avro-source.interceptors.extractor.serializers.ts.type = org.apache.flume.interceptor.RegexExtractorInterceptorMillisSerializer my-agent.sources.avro-source.interceptors.extractor.serializers.ts.name = timestamp my-agent.sources.avro-source.interceptors.extractor.serializers.ts.pattern = yyyy-MM-dd # as is my-agent.sources.avro-source.interceptors.extractor.serializers.loglevel.name = level , , . , . , Flume, Flume — .
(Flume Channel Selectors)
, , . 2 :
- replicating — , . Flume . , «» . , .
- multiplexing — , . multiplexing- .
multiplexing-
# ============================ Avro- ============================ # my-source.sources.avro-source.type = avro my-source.sources.avro-source.port = 50002 my-source.sources.avro-source.bind = 127.0.0.1 my-source.sources.avro-source.channels = hdfs-channel file-roll-channel null-channel # — multiplexing, # , "" "" , # HDFS, — my-source.sources.avro-source.selector.type = multiplexing # , my-source.sources.avro-source.selector.header = type # type = important, HDFS, my-source.sources.avro-source.selector.mapping.important = hdfs-channel file-roll-channel # type = common, my-source.sources.avro-source.selector.mapping.common = file-roll-channel # type - , # ( , memchannel null-sink) my-source.sources.avro-source.selector.mapping.default = hdfs-null-channel . , (, ) .
Conclusion
, . Flume HDFS. — 2000 . roll («15m» «60m»), dir sr — .
Flume HDFS
flume-hdfs.sources = hdfs-source flume-hdfs.channels = hdfs-15m-channel hdfs-60m-channel hdfs-null-channel flume-hdfs.sinks = hdfs-15m-sink hdfs-60m-sink # =========== Avro-, host ============ # flume-hdfs.sources.hdfs-source.type = avro flume-hdfs.sources.hdfs-source.port = 50002 flume-hdfs.sources.hdfs-source.bind = 0.0.0.0 flume-hdfs.sources.hdfs-source.interceptors = hostname flume-hdfs.sources.hdfs-source.interceptors.hostname.type = host flume-hdfs.sources.hdfs-source.interceptors.hostname.hostHeader = host flume-hdfs.sources.hdfs-source.channels = hdfs-null-channel hdfs-15m-channel flume-hdfs.sources.hdfs-source.selector.type = multiplexing flume-hdfs.sources.hdfs-source.selector.header = roll flume-hdfs.sources.hdfs-source.selector.mapping.15m = hdfs-15m-channel flume-hdfs.sources.hdfs-source.selector.mapping.60m = hdfs-60m-channel flume-hdfs.sources.hdfs-source.selector.mapping.default = hdfs-null-channel # ============================ , 15 ============================ # flume-hdfs.channels.hdfs-15m-channel.type = file flume-hdfs.channels.hdfs-15m-channel.maxFileSize = 1073741824 flume-hdfs.channels.hdfs-15m-channel.capacity = 10000000 flume-hdfs.channels.hdfs-15m-channel.transactionCapacity = 10000 flume-hdfs.channels.hdfs-15m-channel.dataDirs = /flume/flume-hdfs/hdfs-60m-channel/data1,/flume/flume-hdfs/hdfs-60m-channel/data2 flume-hdfs.channels.hdfs-15m-channel.checkpointDir = /flume/flume-hdfs/hdfs-15m-channel/checkpoint # ============================ , 60 ============================ # flume-hdfs.channels.hdfs-60m-channel.type = file flume-hdfs.channels.hdfs-60m-channel.maxFileSize = 1073741824 flume-hdfs.channels.hdfs-60m-channel.capacity = 10000000 flume-hdfs.channels.hdfs-60m-channel.transactionCapacity = 10000 flume-hdfs.channels.hdfs-60m-channel.dataDirs =/flume/flume-hdfs/hdfs-60m-channel/data1,/flume/flume-hdfs/hdfs-60m-channel/data2 flume-hdfs.channels.hdfs-60m-channel.checkpointDir = /flume/flume-hdfs/hdfs-60m-channel/checkpoint # =========== , 15 (5 . ) =========== # flume-hdfs.sinks.hdfs-15m-sink.type = hdfs flume-hdfs.sinks.hdfs-15m-sink.channel = hdfs-15m-channel flume-hdfs.sinks.hdfs-15m-sink.hdfs.filePrefix = %{src}/%Y-%m-%d/%Y-%m-%d-%H-%M-%S.%{src}.%{host}.log flume-hdfs.sinks.hdfs-15m-sink.hdfs.path = /logs/%{dir} flume-hdfs.sinks.hdfs-15m-sink.hdfs.fileSuffix = .gz flume-hdfs.sinks.hdfs-15m-sink.hdfs.writeFormat = Text flume-hdfs.sinks.hdfs-15m-sink.hdfs.codeC = gzip flume-hdfs.sinks.hdfs-15m-sink.hdfs.fileType = CompressedStream flume-hdfs.sinks.hdfs-15m-sink.hdfs.minBlockReplicas = 1 flume-hdfs.sinks.hdfs-15m-sink.hdfs.rollInterval = 0 flume-hdfs.sinks.hdfs-15m-sink.hdfs.rollSize = 0 flume-hdfs.sinks.hdfs-15m-sink.hdfs.rollCount = 0 flume-hdfs.sinks.hdfs-15m-sink.hdfs.idleTimeout = 300 flume-hdfs.sinks.hdfs-15m-sink.hdfs.round = true flume-hdfs.sinks.hdfs-15m-sink.hdfs.roundValue = 15 flume-hdfs.sinks.hdfs-15m-sink.hdfs.roundUnit = minute flume-hdfs.sinks.hdfs-15m-sink.hdfs.threadsPoolSize = 8 flume-hdfs.sinks.hdfs-15m-sink.hdfs.batchSize = 10000 # =========== , 60 (20 . ) =========== # flume-hdfs.sinks.hdfs-60m-sink.type = hdfs flume-hdfs.sinks.hdfs-60m-sink.channel = hdfs-60m-channel flume-hdfs.sinks.hdfs-60m-sink.hdfs.filePrefix = %{src}/%Y-%m-%d/%Y-%m-%d-%H-%M-%S.%{src}.%{host}.log flume-hdfs.sinks.hdfs-60m-sink.hdfs.path = /logs/%{dir} flume-hdfs.sinks.hdfs-60m-sink.hdfs.fileSuffix = .gz flume-hdfs.sinks.hdfs-60m-sink.hdfs.writeFormat = Text flume-hdfs.sinks.hdfs-60m-sink.hdfs.codeC = gzip flume-hdfs.sinks.hdfs-60m-sink.hdfs.fileType = CompressedStream flume-hdfs.sinks.hdfs-60m-sink.hdfs.minBlockReplicas = 1 flume-hdfs.sinks.hdfs-60m-sink.hdfs.rollInterval = 0 flume-hdfs.sinks.hdfs-60m-sink.hdfs.rollSize = 0 flume-hdfs.sinks.hdfs-60m-sink.hdfs.rollCount = 0 flume-hdfs.sinks.hdfs-60m-sink.hdfs.idleTimeout = 1200 flume-hdfs.sinks.hdfs-60m-sink.hdfs.round = true flume-hdfs.sinks.hdfs-60m-sink.hdfs.roundValue = 60 flume-hdfs.sinks.hdfs-60m-sink.hdfs.roundUnit = minute flume-hdfs.sinks.hdfs-60m-sink.hdfs.threadsPoolSize = 8 flume-hdfs.sinks.hdfs-60m-sink.hdfs.batchSize = 10000 # ================ NULL- + =============== # flume-hdfs.channels.hdfs-null-channel.type = memory flume-hdfs.channels.hdfs-null-channel.capacity = 30000 flume-hdfs.channels.hdfs-null-channel.transactionCapacity = 10000 flume-hdfs.channels.hdfs-null-channel.byteCapacityBufferPercentage = 20 flume-hdfs.sinks.hdfs-null-sink.channel = hdfs-null-channel flume-hdfs.sinks.hdfs-null-sink.type = null , , :
- Flume.
- .
- , .
Source: https://habr.com/ru/post/281933/
All Articles