Palantir: Object Model
Srias Vijaykumar, Lead Implementation Engineer, will talk about another element of the internal kitchen of the Palantir system.
Together with Edison, we continue to investigate the capabilities of the Palantir platform.
')
How are organizations managed with data for now?
In existing systems there are quite common artifacts, and many of them, if not all, are familiar to you:
What do we do differently in Palantir?
When we developed the system, we worked a lot with community feedback. The first thing we have tried to design is the maximum flexibility of the system, making it possible to simulate anything.
Flexibility means the ability to work with any type of data in one common space: from highly structured, such as databases with aligned relationships, to unstructured ones, such as a message traffic repository, as well as all those between these extremes. It also means the ability to create many different fields for research without being tied to a single building model. Like an organization, they can change and evolve over time.
The next thing we designed was a lossless compilation of data. We need a platform that tracks every single piece of information to its source or sources. In a multiplatform system, access control is important, especially if such a system allows you to perform all the work with data.

2:26 The next thing we designed is open format and API. The genuine data platform allows you to enter data into the system, interact with the data in this system, and output data from the system so that you can perform the necessary operations with this data.
2:38 The object model is the core of Palantir, and, one way or another, it can be seen in each of our videos.
2:45 Now let's see how the model fits into the overall picture.
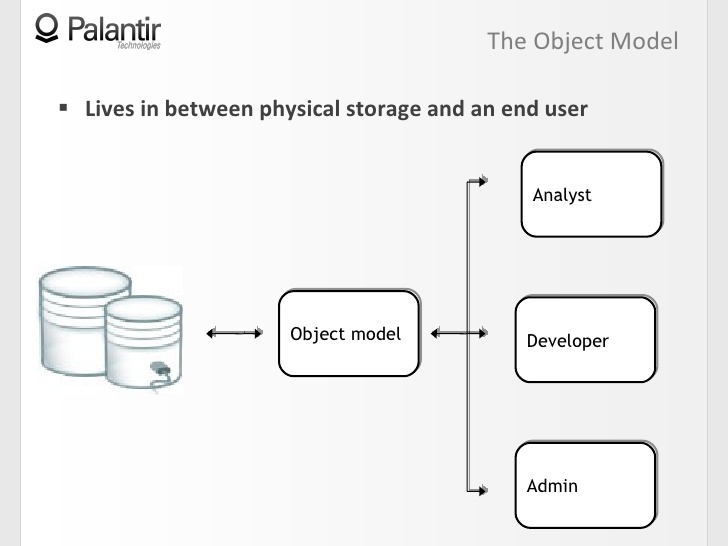
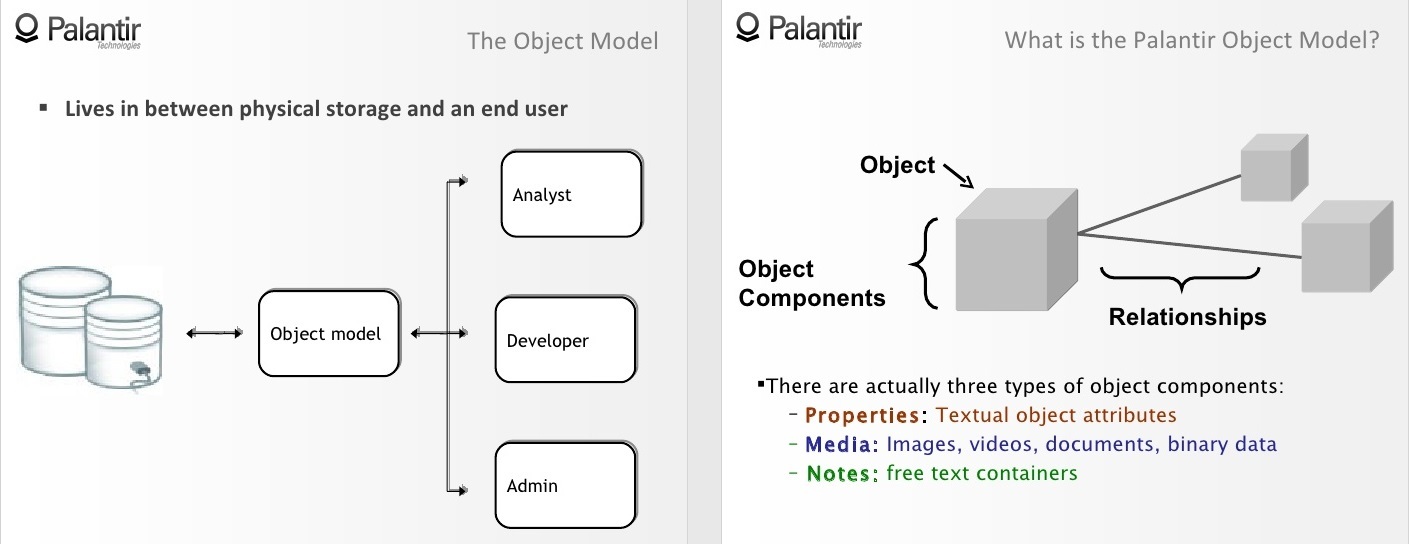
2:50 The object model is an abstraction located between the physical data store and the end user. In our case, the end user can be a workplace analyst, developer, or administrator.
3:07 Through the object model, all users interact with the data as with an abstract object of the first order (first order conceptual object), instead of gathering around a common table, sharing a vision, playing back stored procedures (store procedure) again and again.
3:22 Now that we have an understanding of how the model looks in the big picture, let's move on to the structure. What are these objects?

3:36 First, an object is an empty container, a shell that we fill with attributes and known information. Examples of objects include entities such as: people, places, telephones, computers, events such as meetings, for example, phone calls, documents, emails, and more.
3:54 All of these objects have what we call object components.
3:58 There are four types of object components, three of which we now list:
- signs, that is, text attributes, such as names, emails and other;
- media files, which allows you to associate images, videos, texts and any other binary data formats with the object;
- notes, that is, free text fields for analysts.
4:18 Now we have objects in which we store information and there are connections that connect objects.
4:28 This object system and object components, gives an idea of the object model. The reason why we can model such a number of “fields” (domain is a field, a sphere, an area; most likely, we are talking about a separate workspace in the general Palantir) that we did not register any semantics inside the object as such.
4:42 I did not say that relationships should be unifying, controlling, or hierarchical, an object model exists before these concepts. Each organization individually defines semantics using a dynamic ontology.
4:56 Let's see how the object model and dynamic ontology interact, creating the necessary organization semantics.
5:03 Take an example. Here we have a very simple graph consisting of two objects containing some components and relations.

5:12 There are no semantics here. Some organization will now choose the types of objects, signs and relationships that it needs.
5:22 If I do network security, it can be routers and hosts, if counter-terrorism, it can be terrorist organizations, money, and group members.
5:38 Now, if you combine the object model with ontology, you are expected to get some semantics, for example: Zack works in Palantir.
5:50 The same, from an object point of view, a graph can carry a completely different meaning: it can indicate the presence of a document.
6:00 Abstracting the semantics from structure, we were able to create a wide range of “fields” in an accessible and flexible way.
6:09 There is a tribute to pay if you want flexibility, and this tribute should be very familiar to you.
6:22 The price for the opportunity for the system to be flexible is almost always the loss of support for the ability to create schemes.
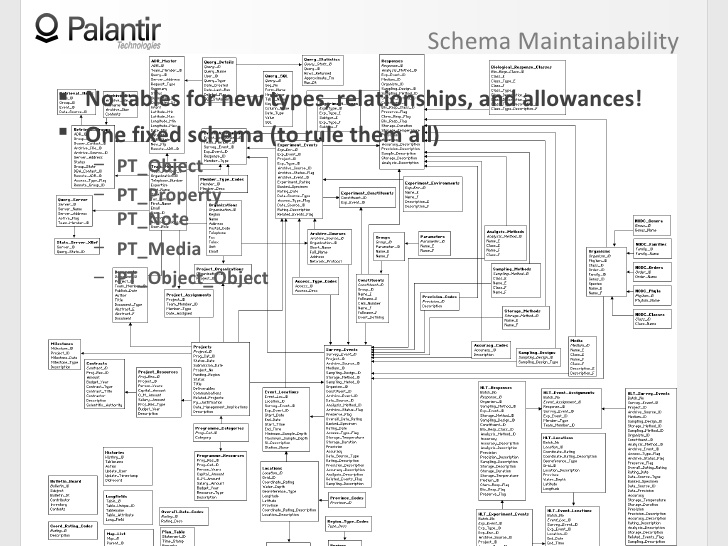
6:29 You can add a new type of object or type of relationship, but it will cost you five separate related tables, with explanations, directions, and more.
6:41 So it’s really hard to maintain and that’s not what you really want from a data platform.
6:45 In Palantir, we use the opposite approach: there is no need to create new tables for object types, relationships, or permissible restrictions.
6:57 To be precise, there is one scheme in Palantir that we use in every organization and in every implementation.
7:02 There are five tables from which you can take content for any object and any component of objects, no matter if you are modeling documents based on message traffic or a highly structured database.
7:15 So, if you look at how the object model looks in the big picture, at the structure of the object model itself and how it interacts with dynamic ontology, we will see high flexibility and the ability to create many “fields”.
7:29 Now, let's talk about how we implemented lossless data extraction.
7:35 The most important thing here is data sources, well, because all the information that is in Palantir comes from sources.
7:43 Examples. It can be anything: tax documents, spreadsheets, xml files, databases, web pages. Created by the analyst himself during the work, it is still based on information from sources.
7:58 Why is this important? You have something, a product: you need to trace where it came from, what it is based on, go back to the sources and make sure that there are no distortions - this is the only way to be confident in your conclusions.
8:11 Now let's look at the links between data sources and the object model that I described to you.
8:17 Every component of an object in Palantir contains an entry about the source of its data. This entry links information to a source or multiple sources.

8:25 So, if I want to justify my graph, we will see that these two objects are supported by sources A, B, and C.
8:34 You can also see that several sources support one component of the object, and I, therefore, are more confident in this piece of information, because it relies on data from the traffic repository and operator logs, for example. Both sources confirm the information, I can move on, based on it.
9:00 am. Data source records provide little more information than just pointing to data sources, if we are dealing with unstructured sources. For example, if this is a document, the entry will point to a specific place in the document. In structured databases, this source record may point to a primary key.
9:17 Now when we saw how data sources are related to objects, let's see what operations we can do here.
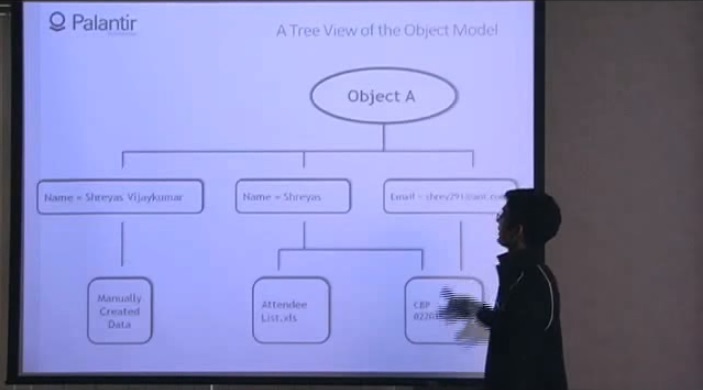
9:23 We see a graph simplified to the limit; it consists of one object, containing two components, and two signs. “Name: Sriyas”, and “Mail: shrey291@aol.com”.
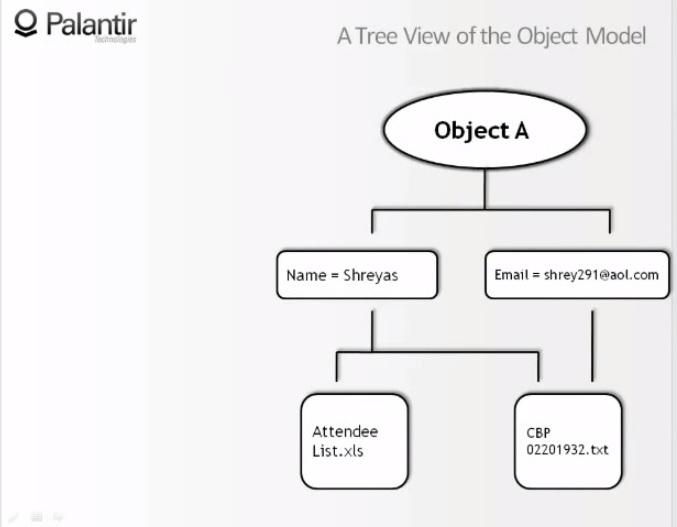
9:37 And we see that the name is taken from the visitors' spreadsheet (attendee - participant, listener, visitor), and from a text document, and the mail is taken only from a text document.
9:46 Let's look at these sources. First, the list of visitors: we see that the name Sriyas is taken from a raw file, something like an excerpt from another source.
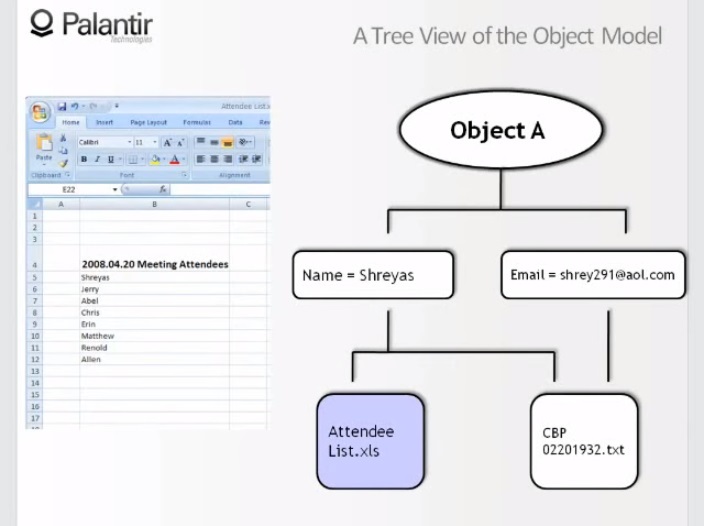
10:00 Imagine that the second, text file was recalled (recall), or the user no longer has access to this source. How will the object look now?
10:11 If we remove the text file, we will see that only the name component remains, so we effectively led the object to a new view, since its second feature is no longer supported.
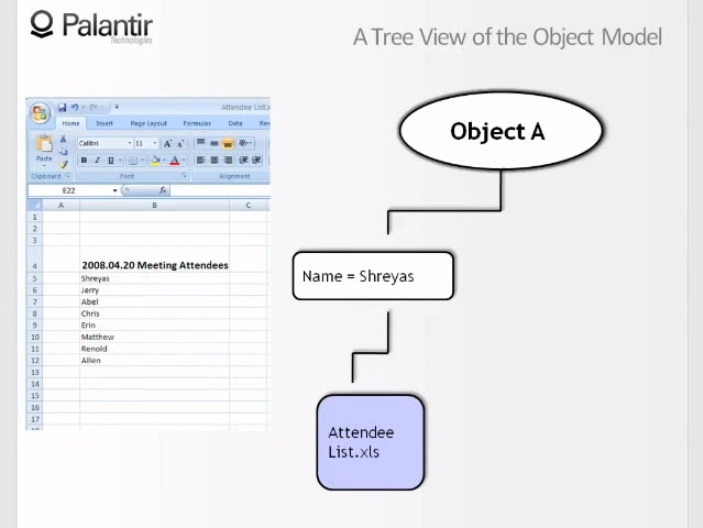
10:25 Let's go back to the original view and take a look at another source.
10:30 We see a text document, we see that the name and email are extracted from the document. In case the list of visitors was withdrawn or access was denied, our object still looks the same. This is all because both components have proven sources.

10:55 Now we have seen what happens when changes occur at the source level, and that we can look at the signs, where they come from, and this is a useful opportunity.
10:53 Let's take a look at the properties of "Name: Srias."
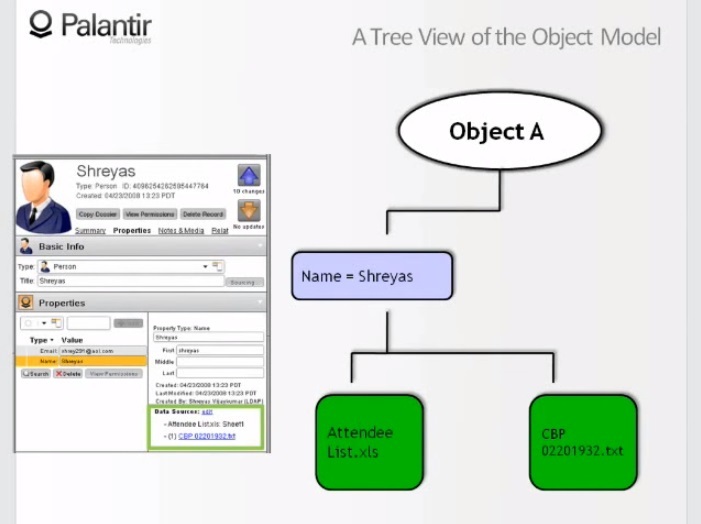
11:07 We see that the name is taken from the list of visitors and from a text file. For the analyst, it is important to understand where the information comes from.
11:18 It is also important that everything we talked about is used to control access to information, to protect sources of information. It also allows us to do other things.
11:30 For example, using this approach, it is easy to maintain a multiplicity of attributes. What does “add a new sign” mean for the sign “Name: Sriyas”?
11:38 This means that we have added a new branch to my graph, from the “manually created data” source, and I can perform the same manipulations with this data that we considered before.
11:50 Using the object model, I can perform a number of useful data manipulations.
11:58 Separately, I want to mention that this approach is one of the components of data resynchronization. For example, you have some external data source that may change the value of your attribute, and it is not very clear how not to miss this value in Palantir.
12:12 All you need to know is that any discrepancies return to the sign itself, that is, if there is a discrepancy associated with the sign “Name: Sriyas”, since this sign in another source changes to “Srias Vijaykumar ", You can not just change the value, because the old value is based on its own data source. You will have to create a new tag.
12:31 Now that we have seen the operations that can be performed with the object model, let's see how you can interact with this model, how you will enter and retrieve data.
12:39 As I said at the beginning, we support a very open format, an open API, these are our requirements for the data platform.
12:48 Usually in such environments there is the problem of data and tools. This is a data problem, as it is difficult to get data from different formats and interact with them.
13:00 But this is also a problem with tools, since you can come across products that hold you in a proprietary or binary format, and such products can be difficult to interact with your data.
13:08 In Palantir, the open xml format, which is called Palantir XML, is the embodiment of the object model.
13:19 This means that you can do all your work and extract data from Palantir as Palantir XML, or, if you have a set of data, from unstructured documents to whole file systems, you can add them to Palantir using same palantir xml.
13:33 The reason this is possible is that you are entering data as an object model.
13:36 The reason this is important is that the object model effectively describes every piece of information in the system.
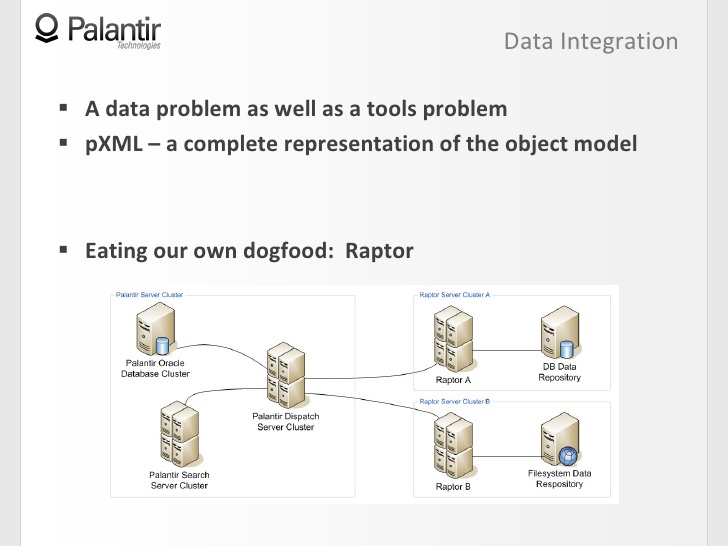
13:43 The last thing I want to touch on is how we used the object model when we designed our own Raptor system, an integrated search component.
13:57 Raptor's idea is to work efficiently with rapidly changing data sources, so they need to be in sync with your Palantir.
14:09 Usually, Palantir works like this: sends requests to the search cluster, the search cluster returns the result to the dispatch server.
14:14 Raptor serves as a bridge between external data sources and the dispatch server, and its task is to recognize the right objects based on the object model.
14:29 When you run a search through Raptor, it combines the entire data stream, sends all clumsy objects, and for the user it looks like a smooth process, without a single break.

14:36 Summing up, I would say that the object model is the core of the Palantir platform, and when we developed this platform, we proceeded from three considerations:
(For assistance in preparing the article, special thanks to Alexey Vorsin, Russian expert on the Palantir system)
More about Palantir:
Together with Edison, we continue to investigate the capabilities of the Palantir platform.
')
How are organizations managed with data for now?
In existing systems there are quite common artifacts, and many of them, if not all, are familiar to you:
- Users often leave notes for themselves in the file name, so that we can come up with constructions like send_on_mail.pryat.10_utra.not_wash !!;
- every change of ontology requires modification of the whole scheme;
- data from different sources cannot be explored together, in the same environment, so you may have a database of people and traffic messages that you have to investigate separately;
- resynchronization of data is inexpedient or impossible - and this is often necessary;
- information can not be traced to its source.
What do we do differently in Palantir?
When we developed the system, we worked a lot with community feedback. The first thing we have tried to design is the maximum flexibility of the system, making it possible to simulate anything.
Flexibility means the ability to work with any type of data in one common space: from highly structured, such as databases with aligned relationships, to unstructured ones, such as a message traffic repository, as well as all those between these extremes. It also means the ability to create many different fields for research without being tied to a single building model. Like an organization, they can change and evolve over time.
The next thing we designed was a lossless compilation of data. We need a platform that tracks every single piece of information to its source or sources. In a multiplatform system, access control is important, especially if such a system allows you to perform all the work with data.
2:26 The next thing we designed is open format and API. The genuine data platform allows you to enter data into the system, interact with the data in this system, and output data from the system so that you can perform the necessary operations with this data.
2:38 The object model is the core of Palantir, and, one way or another, it can be seen in each of our videos.
2:45 Now let's see how the model fits into the overall picture.
2:50 The object model is an abstraction located between the physical data store and the end user. In our case, the end user can be a workplace analyst, developer, or administrator.
3:07 Through the object model, all users interact with the data as with an abstract object of the first order (first order conceptual object), instead of gathering around a common table, sharing a vision, playing back stored procedures (store procedure) again and again.
3:22 Now that we have an understanding of how the model looks in the big picture, let's move on to the structure. What are these objects?
3:36 First, an object is an empty container, a shell that we fill with attributes and known information. Examples of objects include entities such as: people, places, telephones, computers, events such as meetings, for example, phone calls, documents, emails, and more.
3:54 All of these objects have what we call object components.
3:58 There are four types of object components, three of which we now list:
- signs, that is, text attributes, such as names, emails and other;
- media files, which allows you to associate images, videos, texts and any other binary data formats with the object;
- notes, that is, free text fields for analysts.
4:18 Now we have objects in which we store information and there are connections that connect objects.
4:28 This object system and object components, gives an idea of the object model. The reason why we can model such a number of “fields” (domain is a field, a sphere, an area; most likely, we are talking about a separate workspace in the general Palantir) that we did not register any semantics inside the object as such.
4:42 I did not say that relationships should be unifying, controlling, or hierarchical, an object model exists before these concepts. Each organization individually defines semantics using a dynamic ontology.
4:56 Let's see how the object model and dynamic ontology interact, creating the necessary organization semantics.
5:03 Take an example. Here we have a very simple graph consisting of two objects containing some components and relations.
5:12 There are no semantics here. Some organization will now choose the types of objects, signs and relationships that it needs.
5:22 If I do network security, it can be routers and hosts, if counter-terrorism, it can be terrorist organizations, money, and group members.
5:38 Now, if you combine the object model with ontology, you are expected to get some semantics, for example: Zack works in Palantir.
5:50 The same, from an object point of view, a graph can carry a completely different meaning: it can indicate the presence of a document.
6:00 Abstracting the semantics from structure, we were able to create a wide range of “fields” in an accessible and flexible way.
6:09 There is a tribute to pay if you want flexibility, and this tribute should be very familiar to you.
6:22 The price for the opportunity for the system to be flexible is almost always the loss of support for the ability to create schemes.
6:29 You can add a new type of object or type of relationship, but it will cost you five separate related tables, with explanations, directions, and more.
6:41 So it’s really hard to maintain and that’s not what you really want from a data platform.
6:45 In Palantir, we use the opposite approach: there is no need to create new tables for object types, relationships, or permissible restrictions.
6:57 To be precise, there is one scheme in Palantir that we use in every organization and in every implementation.
7:02 There are five tables from which you can take content for any object and any component of objects, no matter if you are modeling documents based on message traffic or a highly structured database.
7:15 So, if you look at how the object model looks in the big picture, at the structure of the object model itself and how it interacts with dynamic ontology, we will see high flexibility and the ability to create many “fields”.
7:29 Now, let's talk about how we implemented lossless data extraction.
7:35 The most important thing here is data sources, well, because all the information that is in Palantir comes from sources.
7:43 Examples. It can be anything: tax documents, spreadsheets, xml files, databases, web pages. Created by the analyst himself during the work, it is still based on information from sources.
7:58 Why is this important? You have something, a product: you need to trace where it came from, what it is based on, go back to the sources and make sure that there are no distortions - this is the only way to be confident in your conclusions.
8:11 Now let's look at the links between data sources and the object model that I described to you.
8:17 Every component of an object in Palantir contains an entry about the source of its data. This entry links information to a source or multiple sources.
8:25 So, if I want to justify my graph, we will see that these two objects are supported by sources A, B, and C.
8:34 You can also see that several sources support one component of the object, and I, therefore, are more confident in this piece of information, because it relies on data from the traffic repository and operator logs, for example. Both sources confirm the information, I can move on, based on it.
9:00 am. Data source records provide little more information than just pointing to data sources, if we are dealing with unstructured sources. For example, if this is a document, the entry will point to a specific place in the document. In structured databases, this source record may point to a primary key.
9:17 Now when we saw how data sources are related to objects, let's see what operations we can do here.
9:23 We see a graph simplified to the limit; it consists of one object, containing two components, and two signs. “Name: Sriyas”, and “Mail: shrey291@aol.com”.
9:37 And we see that the name is taken from the visitors' spreadsheet (attendee - participant, listener, visitor), and from a text document, and the mail is taken only from a text document.
9:46 Let's look at these sources. First, the list of visitors: we see that the name Sriyas is taken from a raw file, something like an excerpt from another source.
10:00 Imagine that the second, text file was recalled (recall), or the user no longer has access to this source. How will the object look now?
10:11 If we remove the text file, we will see that only the name component remains, so we effectively led the object to a new view, since its second feature is no longer supported.
10:25 Let's go back to the original view and take a look at another source.
10:30 We see a text document, we see that the name and email are extracted from the document. In case the list of visitors was withdrawn or access was denied, our object still looks the same. This is all because both components have proven sources.
10:55 Now we have seen what happens when changes occur at the source level, and that we can look at the signs, where they come from, and this is a useful opportunity.
10:53 Let's take a look at the properties of "Name: Srias."
11:07 We see that the name is taken from the list of visitors and from a text file. For the analyst, it is important to understand where the information comes from.
11:18 It is also important that everything we talked about is used to control access to information, to protect sources of information. It also allows us to do other things.
11:30 For example, using this approach, it is easy to maintain a multiplicity of attributes. What does “add a new sign” mean for the sign “Name: Sriyas”?
11:38 This means that we have added a new branch to my graph, from the “manually created data” source, and I can perform the same manipulations with this data that we considered before.
11:50 Using the object model, I can perform a number of useful data manipulations.
11:58 Separately, I want to mention that this approach is one of the components of data resynchronization. For example, you have some external data source that may change the value of your attribute, and it is not very clear how not to miss this value in Palantir.
12:12 All you need to know is that any discrepancies return to the sign itself, that is, if there is a discrepancy associated with the sign “Name: Sriyas”, since this sign in another source changes to “Srias Vijaykumar ", You can not just change the value, because the old value is based on its own data source. You will have to create a new tag.
12:31 Now that we have seen the operations that can be performed with the object model, let's see how you can interact with this model, how you will enter and retrieve data.
12:39 As I said at the beginning, we support a very open format, an open API, these are our requirements for the data platform.
12:48 Usually in such environments there is the problem of data and tools. This is a data problem, as it is difficult to get data from different formats and interact with them.
13:00 But this is also a problem with tools, since you can come across products that hold you in a proprietary or binary format, and such products can be difficult to interact with your data.
13:08 In Palantir, the open xml format, which is called Palantir XML, is the embodiment of the object model.
13:19 This means that you can do all your work and extract data from Palantir as Palantir XML, or, if you have a set of data, from unstructured documents to whole file systems, you can add them to Palantir using same palantir xml.
13:33 The reason this is possible is that you are entering data as an object model.
13:36 The reason this is important is that the object model effectively describes every piece of information in the system.
13:43 The last thing I want to touch on is how we used the object model when we designed our own Raptor system, an integrated search component.
13:57 Raptor's idea is to work efficiently with rapidly changing data sources, so they need to be in sync with your Palantir.
14:09 Usually, Palantir works like this: sends requests to the search cluster, the search cluster returns the result to the dispatch server.
14:14 Raptor serves as a bridge between external data sources and the dispatch server, and its task is to recognize the right objects based on the object model.
14:29 When you run a search through Raptor, it combines the entire data stream, sends all clumsy objects, and for the user it looks like a smooth process, without a single break.
14:36 Summing up, I would say that the object model is the core of the Palantir platform, and when we developed this platform, we proceeded from three considerations:
- flexibility in modeling anything;
- the need to retrieve data without loss;
- open format and API.
(For assistance in preparing the article, special thanks to Alexey Vorsin, Russian expert on the Palantir system)
More about Palantir:
- Dynamic ontology. How the Palantir engineers explain this to the CIA, the NSA and the military
- Cybercontrol. How can Palantir catch snowdens?
- Palantir: how to detect a botnet
- Palantir and money laundering
- Palantir: arms trade and the spread of the pandemic
- Palantir, PayPal Mafia, special services, world government
- Palantir 101. What is allowed to ordinary mortals to know about the second most abrupt private company in Silicon Valley
Source: https://habr.com/ru/post/281733/
All Articles