Reverse Engineering Visual Stories
 I want to admit: I adore visual novels. Who does not know - these are either interactive books, or games — in which — it is necessary — mostly — read-text, or radio plays-with-pictures, predominantly Japanese. For the last 5 years, I probably don’t accept any fiction in another format: visual novels have much more immersive experience than visual books, audio books and even TV series.
I want to admit: I adore visual novels. Who does not know - these are either interactive books, or games — in which — it is necessary — mostly — read-text, or radio plays-with-pictures, predominantly Japanese. For the last 5 years, I probably don’t accept any fiction in another format: visual novels have much more immersive experience than visual books, audio books and even TV series.
And since my childhood I love to understand how things are arranged and what is inside them. He started from the first broken toys, grew to reverse engineering and virus analyst in one not the smallest company. And it occurred to me - why not try to combine these things? See what the visual stories are inside and figure out what this or that engine is based on?
And then just recently released Kaitai Struct release - this is such a new framework for reverse engineering of binary data structures (although the authors are actively unlocked, saying that they are all just for peaceful purposes). The idea there is trivial, but it is captivating: declaratively describing a data structure in a certain markup language - and then you get a ready-made class library for parsing in any supported programming language. Included are a visualizer (to make it easier to check) and, in fact, a compiler. Well, let's try, what is it good for?
As a warm-up, and at the same time, in order to show the typical actions that you will encounter in reverse engineering, I suggest starting with something not very trivial, namely, the wonderful visual novel Koisuru Shimai no Rokujuso (in the original - 恋 す る 姉妹六 重奏) authorship is widely known in narrow circles of PeasSoft. This is a fun, non-addictive romantic comedy, with traditionally beautiful visuals for PeasSoft. From the point of view of reversing, she hooked me up with the fact that she uses her own engine, which is not widely used and seems to have not been studied by anyone yet. And this is at least more interesting than picking on KiriKiri or Ren'Py, already completely tortured and driven apart .
First of all, here is a list of the tools we need:
- Kaitai Struct - compiler and visualizer to it
- Java JRE - unfortunately, Kaitai Struct is written
in Javaon Scala and requires either JRE or node.js, but I have not tried with node.js - Any programming language supported by KS (currently Java, JavaScript, Ruby, Python) - I will use Ruby , but this is not so important, we will write a lister and an extractor at the very end
- some kind of hex editor - by and large, no matter what, they are all imperfect; in principle, the hex editor is inside the KS visualizer, but it is also not the most convenient; I personally use okteta (simply because there is a humanly convenient copy-paste) - but almost anything will go - there would be an opportunity to watch the dump, go to the specified address and quickly copy the selected piece to a separate file
Next you need the product of the study itself - the distribution of the visual novel. Here, too, was lucky: PeasSoft on its website puts out trial versions for completely legal free download, which are enough for us to become familiar with the formats. On the site you need to find such a page:

Circled in blue - in fact, links to myrrh (all the same), where they give download trial.
After downloading and unpacking the distribution, we start by collecting information. Let's think about what we already know about our exhibit. First, the platform. At least the version that is distributed on the site works under Windows on Intel processors (in general, there is another version under Android, but in practice it is sold only in application markets of Japanese cellular operators, plus it is nontrivially pulled from the phone). From the fact that this is Windows / Intel, several very likely things follow:
- integers in binary formats will be encoded in little-endian
- Windows programmers in Japan are still
living in the Stone Ageusing Shift-JIS encoding - the ends of the lines, if we meet them once in an explicit form, will be denoted by "\ r \ n", and not just "\ n"
A quick inspection of the unpacked and installed shows that the mining consists of:
- data01.ykc - 8393294
- data02.ykc - 560418878
- data03.ykc - 219792804
- sextet.exe - 978944
- AVI / op.mpg - 122152964
Those. there is one small exe-schnick (obviously, with the engine), several giant .ykc files (probably, archives with content) and op.mpg - a video file with a splash screen (which you can verify immediately by opening it with any player).
It is useful to quickly visually inspect the exe-file in the hex editor: modern developers are even quite adequate and often use ready-made libraries for working with images, sounds and music. And such libraries, as a rule, leave some signatures visible with the naked eye when compiled. What to look for:
- "libpng version 1.0.8 - July 24, 2000" - libpng is used, it means the pictures will be in png format
- "zlib version error", "Unknown zlib error" - means that zlib compression will be used; may in fact be a false trace, since zlib compression is used when encoding png; until we make far-reaching conclusions
- "Xiph.Org libVorbis I 20020717" - libvorbis, which means that music, speech and sounds will most likely be in ogg / vorbis
- "Corrupt JPEG data", "Premature end of JPEG file" - lines from libjpeg; if there is - it means that the engine is most likely able to also pictures in jpg format
- "D3DX8 Shader Assembler Version 0.91" - somewhere inside something uses the shaders D3DX8
- scattering of messages like "Microsoft Visual C ++ Runtime Library", "
local vftable'", "eh vector constructor iterator'", etc. tells us that this has been linked with the Microsoft C ++ library, and, most likely, written in C ++; if you want, you can rummage and find out even a specific version, but now we don’t need it especially - we are not going to disassemble it or something, we have an absolutely honest clean room
You can also search for lines like "version", "copyright", "compiler", "engine", "script" - moreover, since This is a Windows file, do not forget to do it also in double-byte encodings like UTF16-LE - sometimes there is something else interesting. We have, for example, "Yuka Compiler Error", "YukaWindowClass", "YukaApplicationWindowClass", "YukaSystemRunning", as well as references to "start.yks", "system.ykg". From all this, it is logical to assume that the programmers themselves called their engine something like "Yuka", and all the types of files used by them all start with yk - ykc, yks, ykg. There is also "CDPlayMode" and "CDPlayTime" - from which we can assume that the engine can play music from Audio CD tracks, and also "MIDIStop" and "MIDIPlay" - from which we can assume support for MIDI music.
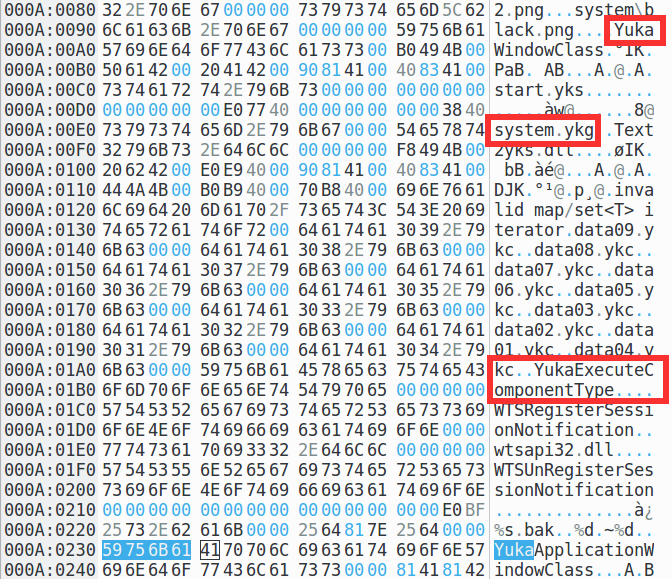
According to our novel in the dry residue, a rather optimistic picture is obtained:
- pictures in png and jpg formats, which immediately simplifies the task by an order of magnitude - most likely you will not need to dig into custom image compression formats
- music, speech and sounds - most likely in ogg (but maybe MIDI and CDDA - although not likely, because there is no physical carrier)
Initial information is collected - now you can roll up your sleeves and dive into the files. In fact, there are several files - and this is also good. In general, reverse engineering is often very important to become a purely statistical question, when a studied object can be obtained more than one in different variations and see how they differ. It is much more difficult to guess what the next 7F 02 00 00 means when you have it exactly one.
Check if the files have the same format. Judging by the fact that all of them - data * .ykc - one. We look inside the beginning of the file: everything starts with "YKC001 \ 0 \ 0" - very good, it seems that these are really archives of the same format.
Quickly empirically check if some kind of compression is used. We take any archiver, try to compress the file and see how much it was before and how much it became after. I stupidly used zip:
- to - 8393294
- after - 6758313
It is compressed, but not much. Most likely the same or no compression, or it is not for all files. On the other hand, if some png or ogg are in the archive — they are already compressed, they will not be compressed with zip.
For general reasons, almost any archive has some kind of header, as a rule, there is a directory of archive contents (relatively small), and 99% of the archive file is occupied, the actual content is attached files or data blocks. The title, by the way, does not necessarily start right from the beginning of the file — perhaps with some stepping back from the end of the file or some (usually a little) from the beginning. It is extremely rare to find a file starting from the very beginning of a career to read from the middle.
We look at the beginning of the files. We see approximately the following picture:
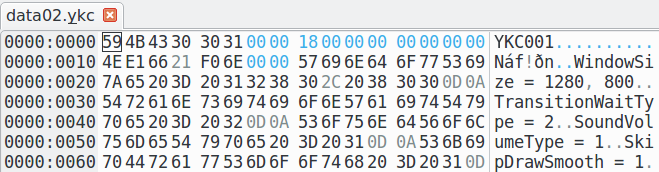
59 4B 43 30 │ 30 31 00 00- this is obviously just the signature of the file, in ASCII this is "YKC001", most likely it means something like "Yuka Container", version 00118 00 00 00 │ 00 00 00 00 │ 1A 00 80 00 │ 34 12 00 00- apparently, this is the title- then the body of some file inside the archive clearly begins; This is especially well seen in data02.ykc - there are lines of some kind of either a config, or a scripting language: "WindowSize = 1280, 800", "TransitionWaitType = 2", etc .; those. look no further
We look at how the header looks in all three files we have:
- data01.ykc:
18 00 00 00 │ 00 00 00 00 │ 1A 00 80 00 │ 34 12 00 00 - data02.ykc:
18 00 00 00 │ 00 00 00 00 │ 4E E1 66 21 │ F0 6E 00 00 - data03.ykc:
18 00 00 00 │ 00 00 00 00 │ 5C E1 18 0D │ 48 E4 00 00
What is "18 00 00 00 │ 00 00 00 00" is still not clear, but it is the same everywhere. The other 2 fields are much more interesting - these are obviously two 4-byte integers. It seems, it is time to get Kaitai Struct and begin to describe the received guesses in the form of a ksy format:
meta: id: ykc application: Yuka Engine endian: le seq: - id: magic contents: ["YKC001", 0, 0] - id: magic2 contents: [0x18, 0, 0, 0, 0, 0, 0, 0] - id: unknown1 type: u4 - id: unknown2 type: u4 It seems to be nothing complicated. ksy are actually ordinary YAML files. The "meta" section describes what we are actually working on and what we have gathered following the results of our preliminary investigation - i.e. that we parse the "ykc" files, presumably processes their application called "Yuka Engine" (the "application" field doesn’t seem to affect anything, this is a comment), and by default the integers will be in little endian format (endian: le ).
Next comes a description of how to parse the file and what data structures we found in it - this is specified by an array of fields in the "seq" section. Each field must have an id (and this is logical, for the sake of it we work to understand what lies where) and a description of the content. Here we used two constructions:
- The
contents: [0x18, 0, 0, 0, 0, 0, 0, 0]type constructcontents: [0x18, 0, 0, 0, 0, 0, 0, 0]specifies a field with fixed content. It works like this: the content automatically follows its length, plus KS will automatically make a check and throw an exception if the content does not match the expected when reading such a field - Type construction
type: u4specifies the type field "unsigned integer (_u_nsigned) number, length 4 bytes". Endianness is the same as we specified in meta.
Now we load our new format into the visualizer:
ksv data01.ykc ykc.ksy and see for data01.ykc:
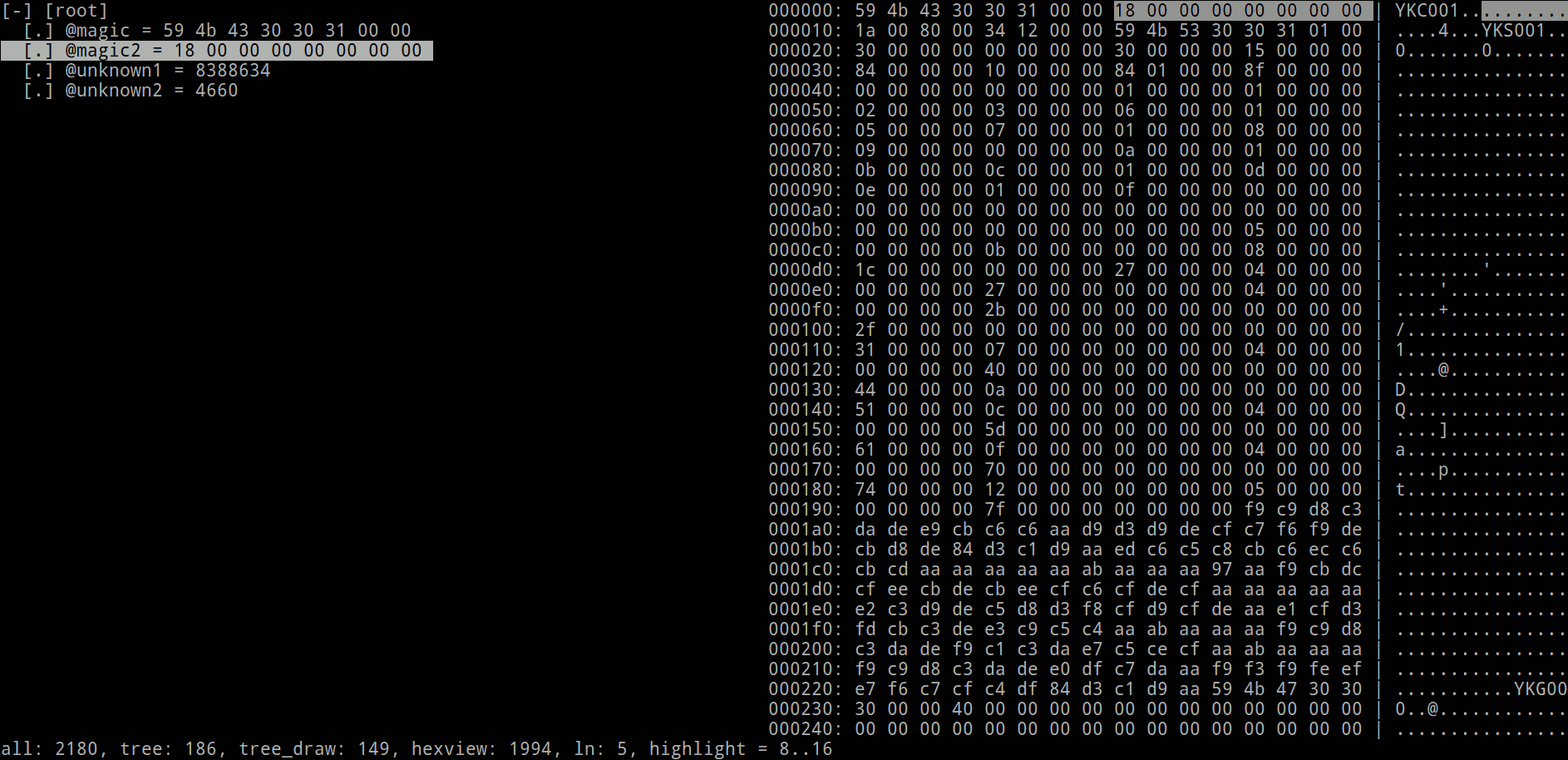
Yes, the visualizer works in the console, you can start to feel like a hacker. But now we are interested in the structure tree:
[-] [root] [.] @magic = 59 4b 43 30 30 31 00 00 [.] @magic2 = 18 00 00 00 00 00 00 00 [.] @unknown1 = 8388634 [.] @unknown2 = 4660 In the visualizer, you can use the arrows to walk through the fields, you can switch to the hex viewer and back by pressing Tab, and by pressing Enter you can fall into the contents of the fields, open instances (you will see about them below) and view hex dumps in full screen. To save space and time, I’ll not show any more screenshots of the visualizer, I’ll only show the part with the text tree.
We look for data02.ykc:
[-] [root] [.] @magic = 59 4b 43 30 30 31 00 00 [.] @magic2 = 18 00 00 00 00 00 00 00 [.] @unknown1 = 560390478 [.] @unknown2 = 28400 for data03.ykc:
[-] [root] [.] @magic = 59 4b 43 30 30 31 00 00 [.] @magic2 = 18 00 00 00 00 00 00 00 [.] @unknown1 = 219734364 [.] @unknown2 = 58440 Sparsely, in general. There is no file directory, where to look for the ends, at first glance, is not clear. Now is the time to recall once again how much these files occupy and estimate whether one of these two can be a link somewhere else:
- data01.ykc - 8393294 @ unknown1 = 8388634
- data02.ykc - 560418878 @ unknown1 = 560390478
- data03.ykc - 219792804 @ unknown1 = 219734364
What a striking resemblance. Let's check what lies there by this offset:
meta: id: ykc application: Yuka Engine endian: le seq: - id: magic contents: ["YKC001", 0, 0] - id: magic2 contents: [0x18, 0, 0, 0, 0, 0, 0, 0] - id: unknown_ofs type: u4 - id: unknown2 type: u4 instances: unknown3: pos: unknown_ofs size-eos: true We have added the description of this field "unknown3". This time it went not to the "seq" section, but to the "instances" section. In fact, these are approximately the same fields that can be described in "seq", but they do not go in order, but have an explicit indication of where to read them (at what offset, from which stream, etc.). We have indicated that we want to have a field called "unknown3" (we do not yet know what is there), starting from the offset unknown_ofs ( pos: unknown_ofs ) and continuing to the end of the file ( size-eos: true ). As you do not know, what is there - just a stream of bytes will be read to us. Yes, while it is not enough, but with this you can already try to live. We try:
Immediately pay attention to the fact that the length of what we read was strikingly similar to the contents of the unknown2 field. Those. it seems that at the beginning of the YKC file there is simply an indication of the offset and what size of the actual file header. Correct our format file to reflect this guess:
meta: id: ykc application: Yuka Engine endian: le seq: - id: magic contents: ["YKC001", 0, 0] - id: magic2 contents: [0x18, 0, 0, 0, 0, 0, 0, 0] - id: header_ofs type: u4 - id: header_len type: u4 instances: header: pos: header_ofs size: header_len The changes are minor: we renamed all unknown-fields to reflect their meaning, and "size-eos: true" (read all of them to the end of the file) changed to "size: header_len". Most likely this closely matches the plan of the person who invented this format. Load again and now we are concentrating on the data block that we called the "header". Here is what its beginning for data01.ykc looks like:
000000: 57 e7 7f 00 0a 00 00 00 18 00 00 00 13 02 00 00 | W............... 000010: 00 00 00 00 61 e7 7f 00 0b 00 00 00 2b 02 00 00 | ....a.......+... 000020: db 2a 00 00 00 00 00 00 6c e7 7f 00 11 00 00 00 | .*......l....... 000030: 06 2d 00 00 92 16 00 00 00 00 00 00 7d e7 7f 00 | .-..........}... for data02.ykc:
000000: d1 2b 66 21 0c 00 00 00 18 00 00 00 5a 04 00 00 | .+f!........Z... 000010: 00 00 00 00 dd 2b 66 21 14 00 00 00 72 04 00 00 | .....+f!....r... 000020: 26 1a 00 00 00 00 00 00 f1 2b 66 21 16 00 00 00 | &........+f!.... 000030: 98 1e 00 00 a8 32 00 00 00 00 00 00 07 2c 66 21 | .....2.......,f! for data03.ykc:
000000: ec 30 17 0d 26 00 00 00 18 00 00 00 48 fd 00 00 | .0..&.......H... 000010: 00 00 00 00 12 31 17 0d 26 00 00 00 60 fd 00 00 | .....1..&...`... 000020: 0d 82 03 00 00 00 00 00 38 31 17 0d 26 00 00 00 | ........81..&... 000030: 6d 7f 04 00 d0 85 01 00 00 00 00 00 5e 31 17 0d | m...........^1.. At first glance, nothing is clear and there is nothing in common. At second glance, in fact, the eye clings to a sequence of repeating bytes. In the first file this is e7 7f , in the second - 2b 66 , in the third - 30 17 and 31 17 . It is very likely that we are dealing with repeated records of fixed length and this length is 0x14 (i.e., 20) bytes. By the way, this agrees well with the lengths of the header in all three files: both 4660 and 28400 and 58440 are divided by 20. Let's test this hypothesis:
meta: id: ykc application: Yuka Engine endian: le seq: - id: magic contents: ["YKC001", 0, 0] - id: magic2 contents: [0x18, 0, 0, 0, 0, 0, 0, 0] - id: header_ofs type: u4 - id: header_len type: u4 instances: header: pos: header_ofs size: header_len type: header types: header: seq: - id: entries size: 0x14 repeat: eos Notice what happened with the instance "header". It still starts with header_ofs and has a length of header_len, but also added a type: header indication. Unlike "u4" (integer), we will now declare and use a custom type, and the entire block "header" will be parsed by this type. Below is a description of the type "header" - see "types: header:". As you can guess from the appearance and the word "seq" - then follows exactly the same syntax as at the top level of the file. Those. inside our new type of header, you can also specify fields that will be read from the very beginning of the block sequentially (in "seq"), fields on certain offsets (in "instances"), their subtypes (in "types"), etc. .
So, we set the type "header", consisting so far from one field of entries, having a size of 0x14 bytes, but repeated as many times as possible until the end of the stream ( repeat: eos ). By the way, the stream in this case is already considered the header block, which we explicitly declared as a block in header_len bytes, starting with header_ofs. Those. if there was something else behind it - it would not be read, everything is in order.
Look what happened:
[-] header [-] @entries (233 = 0xe9 entries) [.] 0 = 57 e7 7f 00|0a 00 00 00|18 00 00 00|13 02 00 00|00 00 00 00 [.] 1 = 61 e7 7f 00|0b 00 00 00|2b 02 00 00|db 2a 00 00|00 00 00 00 [.] 2 = 6c e7 7f 00|11 00 00 00|06 2d 00 00|92 16 00 00|00 00 00 00 [.] 3 = 7d e7 7f 00|14 00 00 00|98 43 00 00|69 25 00 00|00 00 00 00 [.] 4 = 91 e7 7f 00|15 00 00 00|01 69 00 00|d7 12 00 00|00 00 00 00 [.] 5 = a6 e7 7f 00|12 00 00 00|d8 7b 00 00|27 3f 07 00|00 00 00 00 Well, not bad. Some kind of common record is clearly visible. From sports interest we will look at the second file:
[-] header [-] @entries (1420 = 0x58c entries) [.] 0 = d1 2b 66 21|0c 00 00 00|18 00 00 00|5a 04 00 00|00 00 00 00 [.] 1 = dd 2b 66 21|14 00 00 00|72 04 00 00|26 1a 00 00|00 00 00 00 [.] 2 = f1 2b 66 21|16 00 00 00|98 1e 00 00|a8 32 00 00|00 00 00 00 [.] 3 = 07 2c 66 21|16 00 00 00|40 51 00 00|a2 16 00 00|00 00 00 00 [.] 4 = 1d 2c 66 21|16 00 00 00|e2 67 00 00|89 c4 00 00|00 00 00 00 [.] 5 = 33 2c 66 21|16 00 00 00|6b 2c 01 00|fa f5 00 00|00 00 00 00 By the way, "233" and "1420" records is quite similar to the number of files in the archive. The first archive we have is small (8 megabytes), for 233 files - we get an average of 36022 bytes per file. It is quite similar to some scripts, configs, script files, etc. The second archive is the largest (560 megabytes), with 1420 files - 394661 bytes per file, quite similar to some pictures or files with voice recordings.
57 e7 7f 00 , 61 e7 7f 00 , 6c e7 7f 00 , etc. - this is clearly a sequence of increasing numbers, what could it mean? In the second file, these are, respectively, d1 2b 66 21 , dd 2b 66 21 , f1 2b 66 21 . Stop, somewhere I have already seen these numbers. We look at the very beginning of our research - for sure. This is close to the length of the entire archive file. So this is again pointers to something inside the file. Actually, let's describe the structure of these 20-byte records. It seems to be clear from the appearance that it is trite 5 integers. We describe another type of "file_entry". In your silent permission, I will not list the entire ksy file as a whole, but I will give only the changed types section:
types: header: seq: - id: entries repeat: eos type: file_entry file_entry: seq: - id: unknown_ofs type: u4 - id: unknown2 type: u4 - id: unknown3 type: u4 - id: unknown4 type: u4 - id: unknown5 type: u4 There are no new designs here. Added "type" to the entries field and described this very type as 5 consecutive integers (of type u4). Look what happened:
[-] header [-] @entries (233 = 0xe9 entries) [-] 0 [.] @unknown_ofs = 8382295 [.] @unknown2 = 10 [.] @unknown3 = 24 [.] @unknown4 = 531 [.] @unknown5 = 0 [-] 1 [.] @unknown_ofs = 8382305 [.] @unknown2 = 11 [.] @unknown3 = 555 [.] @unknown4 = 10971 [.] @unknown5 = 0 [-] 2 [.] @unknown_ofs = 8382316 [.] @unknown2 = 17 [.] @unknown3 = 11526 [.] @unknown4 = 5778 [.] @unknown5 = 0 Another hypothesis emerges: unknown3 is a pointer to the beginning of the file body in the archive, and unknown4 is its length. After all, 24 + 531 = 555, and 555 + 10971 = 11526. Ie These are files inside the archive, which stupidly go sequentially. A similar observation can be made for unknown_ofs and unknown2: 8382295 + 10 = 8382305, 8382305 + 11 = 8382316. That is, unknown2 is the length of some records starting with unknown_ofs. unknown5, it seems, is always 0. Forward, we add two more fields inside each file_entry: read, content (unknown_ofs; unknown2) and the body of the file to (unknown3; unknown4). I give only the description of file_entry:
file_entry: seq: - id: unknown_ofs type: u4 - id: unknown_len type: u4 - id: body_ofs type: u4 - id: body_len type: u4 - id: unknown5 type: u4 instances: unknown: pos: unknown_ofs size: unknown_len io: _root._io body: pos: body_ofs size: body_len io: _root._io From the new and nontrivial here there is only one construction: io: _root._io . Without it, the pos: body_ofs , say, will count the body_ofs offset in the current thread, i.e. in a stream consisting of 20 bytes file_entry. Of course, an attempt to read the 8-millionth byte of 20 will lead to an error. Therefore, we need this very special magic, which says that we will not read out from the current stream, but from the stream that corresponds to the file as a whole - _root._io .
What happened:
[-] @entries (233 = 0xe9 entries) [-] 0 [.] @unknown_ofs = 8382295 [.] @unknown_len = 10 [.] @body_ofs = 24 [.] @body_len = 531 [.] @unknown5 = 0 [-] unknown = 73 74 61 72 74 2e 79 6b 73 00 [-] body = 59 4b 53 30 30 31 01 00 30 00 00 00… [-] 1 [.] @unknown_ofs = 8382305 [.] @unknown_len = 11 [.] @body_ofs = 555 [.] @body_len = 10971 [.] @unknown5 = 0 [-] unknown = 73 79 73 74 65 6d 2e 79 6b 67 00 [-] body = 59 4b 47 30 30 30 00 00 40 00 00 00… Even with the naked eye you can see that 73 74 61 72 74 2e 79 6b 73 00 is an ASCII string, and by looking at the char representation, you can verify that it is “start.yks” with the terminating 0 byte, and 73 79 73 74 65 6d 2e 79 6b 67 00 is "system.ykg". Hooray, it looks like file names. And about them we know for sure that they are strings. Let's reflect this fact:
file_entry: seq: - id: filename_ofs type: u4 - id: filename_len type: u4 - id: body_ofs type: u4 - id: body_len type: u4 - id: unknown5 type: u4 instances: filename: pos: filename_ofs size: filename_len type: str encoding: ASCII io: _root._io body: pos: body_ofs size: body_len io: _root._io From innovations - type: str (means that the captured bytes must be interpreted as a string) and encoding: ASCII (we still do not exactly know what the encoding is, so let's take the path of least resistance). We look in the visualizer:
[-] header [-] @entries (233 = 0xe9 entries) [-] 0 [.] @filename_ofs = 8382295 [.] @filename_len = 10 [.] @body_ofs = 24 [.] @body_len = 531 [.] @unknown5 = 0 [-] filename = "start.yks\x00" [-] body = 59 4b 53 30 30 31 01 00 30 00 00 00… [-] 1 [.] @filename_ofs = 8382305 [.] @filename_len = 11 [.] @body_ofs = 555 [.] @body_len = 10971 [.] @unknown5 = 0 [-] filename = "system.ykg\x00" [-] body = 59 4b 47 30 30 30 00 00 40 00 00 00… [-] 2 [.] @filename_ofs = 8382316 [.] @filename_len = 17 [.] @body_ofs = 11526 [.] @body_len = 5778 [.] @unknown5 = 0 [-] filename = "SYSTEM\\black.PNG\x00" [-] body = 89 50 4e 47 0d 0a 1a 0a 00 00 00 0d… Beauty. In fact, everything, we have already completed the task, this is enough to extract the files. And now - the magic for which everything was started. Let's write a script that will upload us all the files from one archive. And for this we do not have to write a parsing of all these fields again. We just take the ksc compiler and do:
ksc -t ruby ykc.ksy and we get in the current folder an excellent file ykc.rb, which you can immediately connect as a library and use. How? Let us show you how to warm up the listing of all archive files:
require_relative 'ykc' Ykc.from_file('data01.ykc').header.entries.each { |f| puts f.filename } Inspires? Just one line (not counting the library connection) - and that's it. We start and see a healthy listing:
start.yks system.ykg SYSTEM\black.PNG SYSTEM\bt_click.ogg SYSTEM\bt_select.ogg SYSTEM\config.yks SYSTEM\Confirmation.yks SYSTEM\confirmation_load.png SYSTEM\confirmation_no.ykg SYSTEM\confirmation_no_load.ykg ... Let's see what is happening here:
Ykc.from_file(...)- spawns an object of class Ykc from the specified file on disk; In the fields of the object, what is described in the format is automatically parsed..header- selects the "header" field of the class Ykc, thereby returning an instance of the class Ykc :: Header.entries- selects the "entries" field in the header, returns an array of elements of the class Ykc :: FileEntry.each { |f| ... }.each { |f| ... }- does something with each element of the arrayputs f.filename- displays the "filename" field of the f object (which is of class Ykc :: FileEntry)
Before you write the code that will extract all files from the archive, let's pay attention to a couple of facts:
- First, there are folders in the paths, and since This archive was made on a Windows system, and a backslash ("\") is used as a separator character for the path elements. I don’t know how where, but at least in Ruby this results in the creation of a folder with backslashes in it. To work correctly, everyone there mkdir_p will need to change the "\" to "/".
- Secondly, there is a terminating 0 in the file names at the end, apparently, we have a heavy legacy C. When printing, it is not visible, but for good it would also be worth removing.
- Third, in fact, an autopsy showed that there are files in data02.ykc that look something like this:
"SE\\00050_\x93d\x98b\x82P.ogg\x00" "SE\\00080_\x83J\x81[\x83e\x83\x93.ogg\x00" "SE\\00090_\x83`\x83\x83\x83C\x83\x80.ogg\x00" "SE\\00130_\x83h\x83\x93\x83K\x83`\x83\x83\x82Q.ogg\x00" "SE\\00160_\x91\x96\x82\xE8\x8B\x8E\x82\xE9\x82Q.ogg\x00" Remembering the hypothesis from the very beginning of the article that programmers were clearly Japanese and it could be ShiftJIS, we change the encoding of the filename to "SJIS", actively consoling ourselves with the idea that for those who use non-ASCII characters in file names prepared special circle in hell. Do not forget to recompile ksy => rb, check, now everything is in order:
SE\00050_電話1.ogg SE\00080_カーテン.ogg SE\00090_チャイム.ogg SE\00130_ドンガチャ2.ogg SE\00160_走り去る2.ogg Well, it’s not quite alright, but it’s quite similar to Japanese. Using at least a google translate, you can check that "電話" is a "phone", and "SE \ 00050" is probably the sound effect of a phone ringing.
The final upload script just looks like this:
require 'fileutils' require_relative 'ykc' EXTRACT_PATH = 'extracted' ARGV.each { |ykc_fn| Ykc.from_file(ykc_fn).header.entries.each { |f| filename = f.filename.strip.encode('UTF-8').gsub("\\", '/') dirname = File.dirname(filename) FileUtils::mkdir_p("#{EXTRACT_PATH}/#{dirname}") File.write("#{EXTRACT_PATH}/#{filename}", f.body) } } Not a single line, of course, but, on the other hand, there is nothing to comment on here either. From the command line arguments we get the names of files with archives (it is quite possible to run something like ./extract-ykc * .ykc - it works), we cast the necessary file name from f.filename, create, if necessary, folders in the path, f.body .
— , , . , png ( ), — ogg ( ). , , BG :
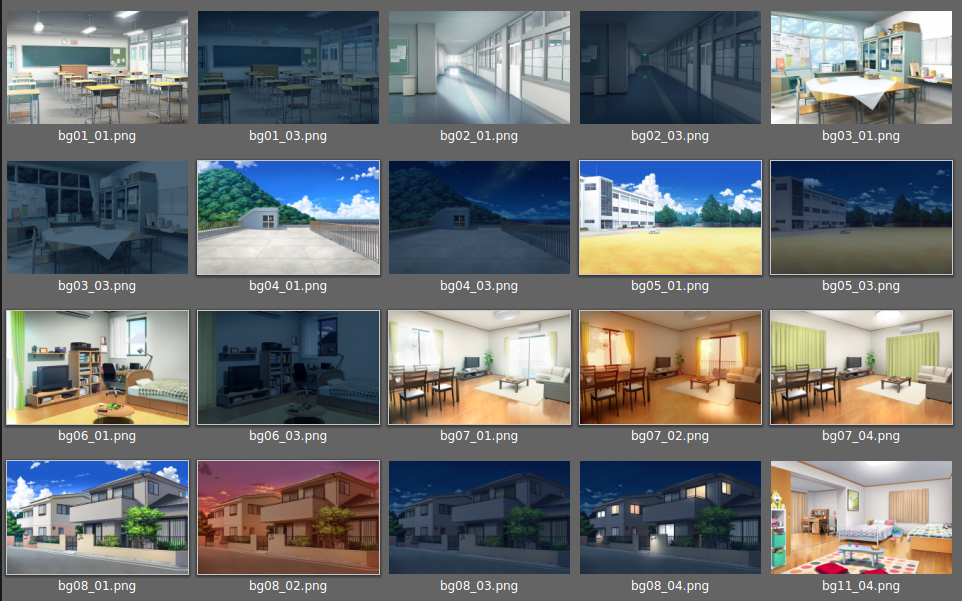
TA/ , . , , :

. , — yks ykg — , . — . , :)
KS:
- Kaitai Struct , , . — , , - Ruby Python: , , — . - "" 101 Hexinator — ( — ).
- Kaitai Struct — , , , , , . - okteta.
- -, , , . , . + exe-.
- ksy ( , — , , , , ), , , . — , , KS.
io: _root._io— , . , 1.0 .
UPDATE : . , — . , , .
UPDATE 2 : , , KS — GreyCat — . .
UPDATE 3 : . gem install kaitai-struct-visualizer .
')
Source: https://habr.com/ru/post/281595/
All Articles