How to write a bloom filter in C ++
A Bloom filter is a data structure that can effectively determine whether an element is a possible element of a set or is definitely not related to it. This article will demonstrate a simple implementation of the Bloom filter in C ++.
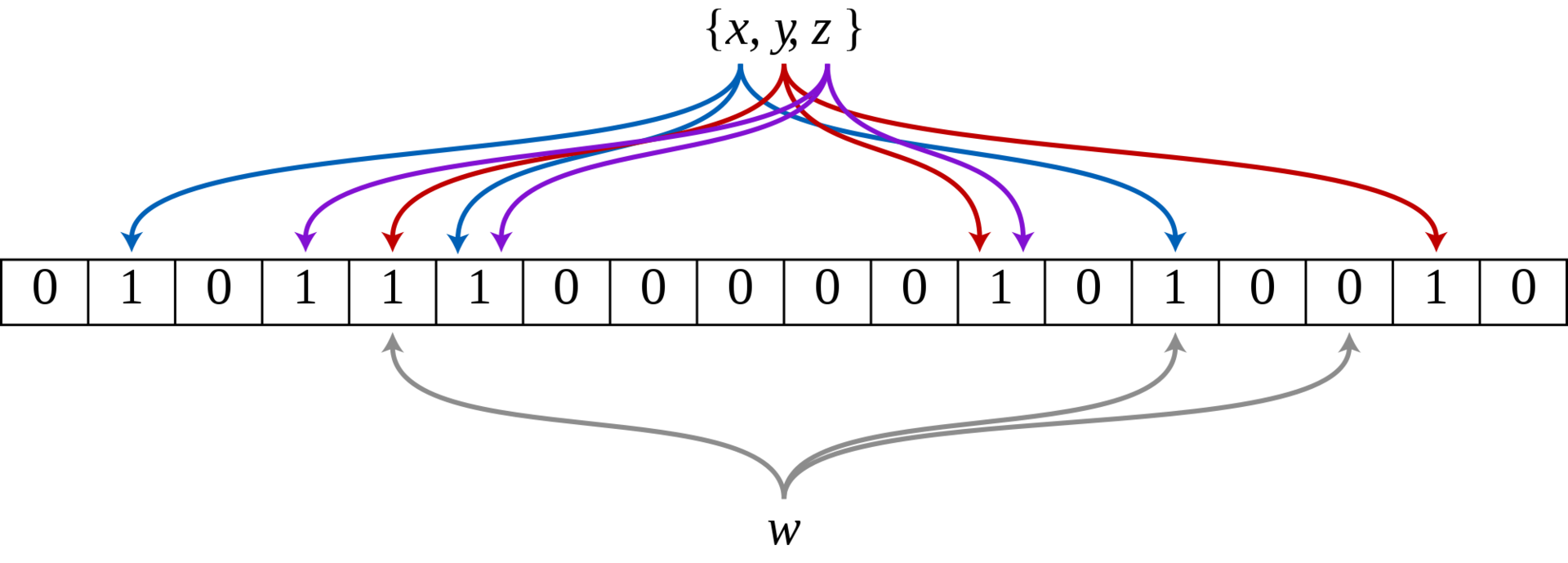
Let's first define the interface of this filter. There are three main functions:
')
Several variables involved, including a small number of vectors, also contain a filter state.
It should be noted that
You can process this structure on the template, as an extension. Instead of hard coding key types and hash functions, we can process the class with a pattern with something similar:
This will allow the Bloom filter to be generalized for more complex data types.
There are two options for building a Bloom filter:
We can calculate a false positive error rate — n, based on the size of the filter — m, the number of hash functions — K, and the number of nested elements — N, using the formula:

This formula is not very useful in this form. But we need to know how big the filter should be and how many hash functions it will need to use, given the estimated number of elements of the set and the error rate. There are two equations that we can use to calculate these parameters:

You may wonder how to implement kk hash functions; double hashing can be used to generate kk hash values without affecting the probability of a false-positive result! This result can be obtained using the formula, where i is the ordinal, m is the size of the Bloom filter and x is the value to be hashed:

First you need to write a constructor. It simply writes scaling parameters and a bitmap.
Next, let's write a function to calculate the 128-bit hash of this element. This implementation uses MurmurHash3 , a 128-bit hash function, which has good trade-offs between performance, distribution, streaming behavior, and resistance to inconsistencies. Since this function generates 128-bit hash and we need 2x64 bit hashes, we can split the returned hash in half to get the hash a (x) hash b (x).
Now that we have a hash value, we need to write a function to return the output n of the hash function.
All that remains to be done is to write functions for the set of check bits for the given elements.
Using the Bloom 4.3MB filter and 13 hash functions, inserting 1.8MB elements took about 189 nanoseconds for each element on average laptop performance.
The original of this post can be found at the link .
Interface
Let's first define the interface of this filter. There are three main functions:
')
- Constructor
- Function to add an element to bloom's filter
- The function for querying whether an element is part of the Bloom filter
Several variables involved, including a small number of vectors, also contain a filter state.
#include <vector> struct BloomFilter { BloomFilter(uint64_t size, uint8_t numHashes); void add(const uint8_t *data, std::size_t len); bool possiblyContains(const uint8_t *data, std::size_t len) const; private: uint64_t m_size; uint8_t m_numHashes; std::vector<bool> m_bits; }; It should be noted that
std::vector<bool.> Is a much more efficient specialization of std::vector, requires only one bit per element (as opposed to one byte in typical implementations).You can process this structure on the template, as an extension. Instead of hard coding key types and hash functions, we can process the class with a pattern with something similar:
template< class Key, class Hash = std::hash<Key> > struct BloomFilter { ... }; This will allow the Bloom filter to be generalized for more complex data types.
Bloom filter options
There are two options for building a Bloom filter:
- Filter size in bits
- The number of hash functions to use
We can calculate a false positive error rate — n, based on the size of the filter — m, the number of hash functions — K, and the number of nested elements — N, using the formula:
This formula is not very useful in this form. But we need to know how big the filter should be and how many hash functions it will need to use, given the estimated number of elements of the set and the error rate. There are two equations that we can use to calculate these parameters:
Implementation
You may wonder how to implement kk hash functions; double hashing can be used to generate kk hash values without affecting the probability of a false-positive result! This result can be obtained using the formula, where i is the ordinal, m is the size of the Bloom filter and x is the value to be hashed:
First you need to write a constructor. It simply writes scaling parameters and a bitmap.
#include "BloomFilter.h" #include "MurmurHash3.h" BloomFilter::BloomFilter(uint64_t size, uint8_t numHashes) : m_size(size), m_numHashes(numHashes) { m_bits.resize(size); } Next, let's write a function to calculate the 128-bit hash of this element. This implementation uses MurmurHash3 , a 128-bit hash function, which has good trade-offs between performance, distribution, streaming behavior, and resistance to inconsistencies. Since this function generates 128-bit hash and we need 2x64 bit hashes, we can split the returned hash in half to get the hash a (x) hash b (x).
std::array<uint64_t, 2> hash(const uint8_t *data, std::size_t len) { std::array<uint64_t, 2> hashValue; MurmurHash3_x64_128(data, len, 0, hashValue.data()); return hashValue; } Now that we have a hash value, we need to write a function to return the output n of the hash function.
inline uint64_t nthHash(uint8_t n, uint64_t hashA, uint64_t hashB, uint64_t filterSize) { return (hashA + n * hashB) % filterSize; } All that remains to be done is to write functions for the set of check bits for the given elements.
void BloomFilter::add(const uint8_t *data, std::size_t len) { auto hashValues = hash(data, len); for (int n = 0; n < m_numHashes; n++) { m_bits[nthHash(n, hashValues[0], hashValues[1], m_size)] = true; } } bool BloomFilter::possiblyContains(const uint8_t *data, std::size_t len) const { auto hashValues = hash(data, len); for (int n = 0; n < m_numHashes; n++) { if (!m_bits[nthHash(n, hashValues[0], hashValues[1], m_size)]) { return false; } } return true; } results
Using the Bloom 4.3MB filter and 13 hash functions, inserting 1.8MB elements took about 189 nanoseconds for each element on average laptop performance.
The original of this post can be found at the link .
Source: https://habr.com/ru/post/281517/
All Articles