Cloud-as-a-Tier, or How to build an IT infrastructure using a hybrid cloud
The explosive growth of private and corporate content is recognized as one of the most significant characteristics of the decade. According to the Economist magazine, in the early
At Cloud4Y, we believe that the only possible forecast regarding the requirements for future data warehouses is their complete unpredictability, as well as the fact that their volume will be much larger than what one can imagine. Instead of trying to manage this growth, you should shift the focus to managing the “Big Content”.
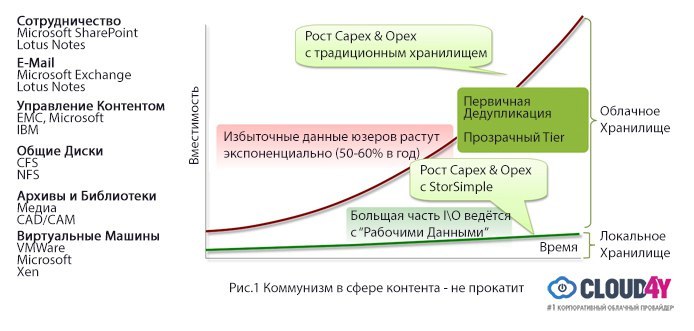
Content Communism doesn't work, or think like Google
The total amount of content is steadily increasing. However, most people only care about some “working set” of content. For example, in SharePoint, people are more likely to worry about the latest data added, and when it comes to email, we are more concerned about today's emails, rather than those received a year ago.
The traditional problem of “Big Content” is considered to be a modest shared disk, where common content is stored. For example, a corporate presentation can be stored here, and a typical individual simply takes it, makes a copy-paste, adds a couple of slides from himself and saves a new copy. The same slides are saved again and again, while the old presentations do not go away. Familiar, is not it? 
New big problem of “Big Content” is considered a huge amount of video and other
If the search engines considered all the data to be the same, the required information could be found both on the first and on the twentieth page. Search services have learned to rank the information, and the same approach should be applied to the data we keep daily - and automatically, without human intervention. Essential content should be located on accessible local disks, and secondary data - automatically ranked stored in the cloud.
')
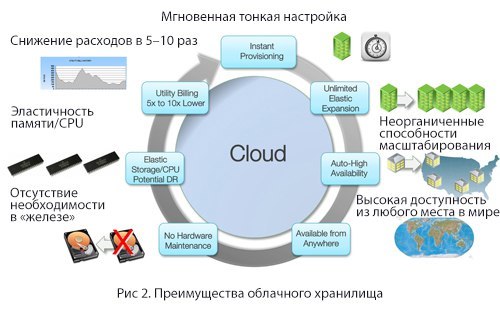
The potential of the cloud and resilient cloud storage
When it comes to storage, the cloud has some undeniable advantages:
- Instant fine tuning
- Unorganized Scaling Capabilities
- High availability from anywhere in the world
- No need for "iron"
- Memory / CPU elasticity
- Cost reduction 5-10 times
Here are some cloud storage myths:
- You will have to rewrite user applications and reorganize backups, because the cloud uses the HTTP / REST API .
- You will face performance issues
due to latency and WAN bandwidth costs. - WAN optimization does not work with public clouds
- Cloud is unsafe
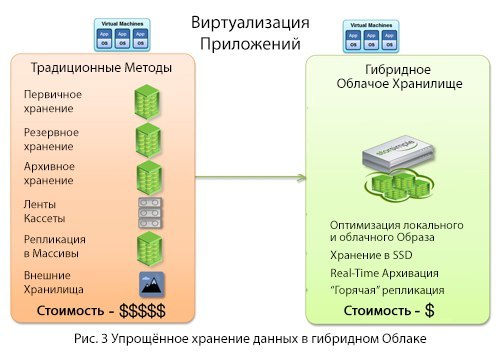
Cloud -as-a-Tier Architecture: Enterprise Cloud Storage Strategy
To use the benefits inherent in the cloud, you need to have an architecture designed for it. This article will explore the use patterns of the Cloud-
As a conclusion, we will present to you a model of a new, simpler corporate cloud storage architecture, which will become an alternative for purchasing hardware and software in order to create:
- Main storage
- Backup repositories
- Archive storage
- Infrastructure and data management tape
- Data replica for disaster recovery
- Remote sites for
geo-sustainability
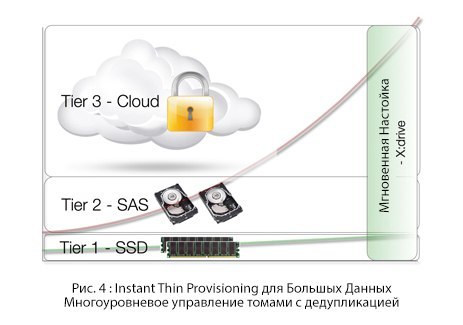
Subtle allocation of resources for "Big Content"
When you are planning to deploy applications for “Big Content”, the main question is how much memory is needed for it.
If your plans go far ahead and calculate the storage volumes not by years, but by terabytes (that is, you want to pay only for the used space), then you save a lot. On the other hand, if you only do short-term planning, and your disk space suddenly runs out, you lose time and have to re-plan and reorganize.
After all, as we said in the introduction, “the only possible forecast regarding the requirements for future data warehouses is their complete unpredictability.”
The traditional approach, first tested by HP with their 3PAR, implies a “Subtle Resource Allocation”, eliminating the need for an advance allocation of capacity. Hybrid cloud takes this principle to a new level, allowing companies to instantly provide themselves with the necessary storage space, paying only for used ones.
Deduplication, data ranking and automatic leveling
The simplest example to illustrate all of this is SharePoint. As we have said, it is common for a user to change, for example, in a 5 MB presentation only the author’s name and the title page, keeping both versions. Traditionally, both versions weigh 5 MB; deduplication changes this approach, representing the entire information world as a set of information blocks. The same block is never saved twice; in our example, only modified blocks will be saved, allowing the second version of the presentation to occupy tens of kilobytes instead of 5 MB.
A look at the information world as a set of blocks has other advantages. For example, content that is constantly needed is displayed at the front level, while content that has not been used for years is simply stored
Cloud- as-a-Tier Security
Security breaches usually involve a person accessing unencrypted data. Recent examples are as follows: the UK government retained insurance data for every citizen along with his bank details and sent them to London. Subsequently, all these data were sold on the Internet. Today, sophisticated data encryption would make these security breaches impossible. Security in the cloud is just a matter of education.
There are several key architectural issues that are important for implementing a secure cloud. All blocks that move from local storage to the storage cloud must be encrypted both at rest and in motion. The second important component is key management: they should be stored at the customer, and not in the cloud. Otherwise, we rely on the person again, allowing him to access the unencrypted content.
There is an additional way: aggregated access to the repository, when each client has its own key. However, the seller - the aggregator, also has access to these keys - and again this is a security risk.
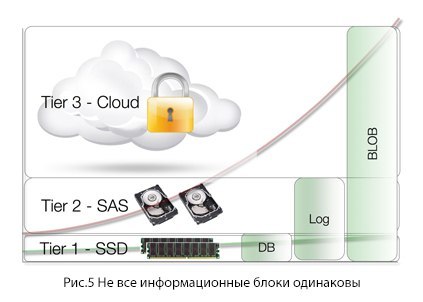
Not all information blocks are the same.
As we have already said, Content Communism is not applicable to the cloud: you would not want all your content to be transferred to the cloud — you need an unused part of it to disappear from the visibility zone. All that is needed for a “Cloud-
“Live” archiving, or “No more Tears with Tiers”
As the amount of information stored increases, administrators have a need to archive part of it and withdraw it from live access. This is usually done for reasons of economy. At the same time, problems are possible as the data needs: for example, what if the data archived after six months of inactivity is urgently needed for the annual report?
In systems like Content Management Systems or SharePoint, archiving is even more difficult, because you need to archive not only content, but also security policies associated with it, and much more. Numerous interconnected blocks should be archived in such a way that, if necessary, access is provided to all information in the complex.
The cloud with its elasticity offers huge amounts of free data to accommodate, and has the potential to be a solution. The storage economy becomes optimal when deduplication, compression, and encryption are combined, and the cloud is used for primary and backup storage.
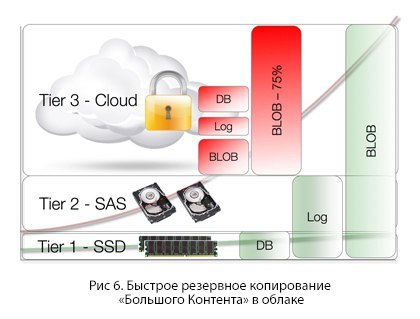
Fast backup of “Big Content” in the cloud
The cloud should not be viewed as just a disk on the global network; by doing so, you can get a sad experience, especially if you do not know about the backup.
People jokingly say: “What is the fastest way to backup to the cloud? The answer is simply to do nothing. ” If you are storing data in the cloud, this is the backup. Only the content that is currently stored on the device should be copied to create a backup version - naturally, after deduplication, compression and encryption. More precisely, only unique blocks of information of such content are quite a modest volume.
Rapid recovery of “Big Content” from the cloud
It is known that people do not
Cloud architecture has a big impact on data recovery in the primary or secondary data center. If your backup version is one big information “lump” weighing several terabytes, then recovery can be a slow and painful process. For quick recovery, you need to use the capabilities of cloud-
This approach allows you to store information in multi-level structures for storing the working set on fast SSDs and local drives. The architecture makes it possible to rationally restore multi-terabyte volumes - without pulling out the entire information volume. Only a small amount of data, the “working set,” is retrieved, and the remaining blocks remain in the cloud and are issued as needed. The “working set” is re-created literally on the fly, but at this time the full amount of data is already in place again.
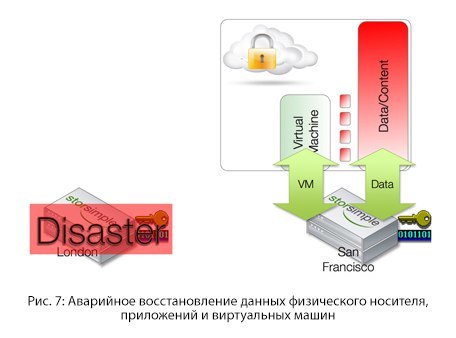
Disaster Recovery in Cloud- as-a-Tier
If you ask users how often they check their disaster recovery procedures, they begin to speak very quietly or blush. Accidents by their nature are unpredictable. Until September 11, the procedure for transferring recorded data was carried out using airplanes, and when Hurricane Katrina happened, all data remained in the flooded mines.
With the advent of the cloud, it became possible to regularly check disaster recovery policies, because the cloud is accessible from everywhere and at any time.
All that is needed is to have an accessible device at hand, on which you can install the entire configuration. Then the cloud volumes can be transferred back to storage in a remote place, and the content becomes available again.
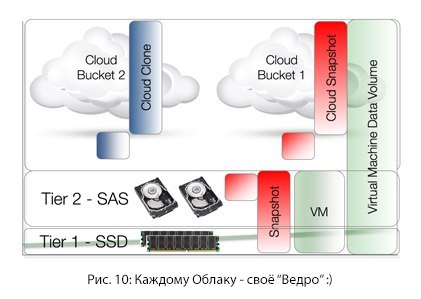
"Big Content" and the virtual machine have one thing in common - they are quite voluminous. Extensive virtual machine libraries can also be stored using the cloud-
Instead of conclusion
The traditional approach to corporate storage is rather complicated
The cloud
- Device for transmitting information to the cloud
- Cloud provider
Simply put, the cloud allows you to rank information and store in a local access only what is needed on a daily basis. Your local applications remain in place - the cloud simply integrates into the existing network. Nothing guarantees the simplicity of storing “Great Content” as a virtual machine. As small planets revolve around huge ones, the “Big Content” will attract smart virtual machines, and then force them to move in the direction of the content and the cloud provider that manages the content.
“Big Content” will become a new center of gravity, and applications will follow it to the cloud.
Source: https://habr.com/ru/post/281483/
All Articles