How we scored on asynchrony when hiking on backends
Under the pressure of the emergence of new asynchronous non-blocking frameworks, it may seem that blocking calls are a relic of the past, and all new services need to be written on a fully asynchronous architecture. In this post, I will tell you how we decided to abandon non-blocking asynchronous calls of backends in favor of the usual blocking.
In the architecture of HeadHunter there is a service that collects data from other services. For example, to show vacancies for a search query, you need:
- go to the search backend for vacancies aydis;
- go to the vacancy backend for a description of them.
This is the simplest example. Often in this service a lot of all logic. We even called it “logic”.
')
It was originally written in python. For several years of the existence of logic in it has accumulated all those. debt. And the developers were not thrilled by the need to dig in both python and java, in which we have written most of the backends. And we thought, why not rewrite logic to java.
And the python logic is progressive, built on an asynchronous non-blocking tornado framework. The question of “blocking or not blocking when going to backends” did not even stand: because of GIL, in python there is no real parallel execution of threads, so if you want, you don’t want, and requests must be processed in one thread and not blocked when going to other services.
But when switching to java, we decided to once again assess whether we want to continue writing the inverted callback code.
def search_vacancies(query): def on_vacancies_ids_received(vacancies_ids): get_vacancies(vacancies_ids, callback=reply_to_client) search_vacancies_ids(query, callback=on_vacancies_ids_received) Of course the callback hell can be smoothed. In java 8, for example, appeared CompletableFuture. You can also look in the direction of Akka, Vert.x, Quasar, etc. But maybe we don’t need new levels of abstraction, and we can return to normal synchronous blocking calls?
def search_vacancies(query): vacancies_ids = search_vacancies_ids(query) return get_vacancies(vacancies_ids) In this case, we will allocate a stream for processing each request, which, when going to the backend, will be blocked until it receives the result and then continues execution. Please note that I am talking about blocking the stream at the time of calling the remote service. Subtracting the query and writing the result to the socket will still be performed without blocking. That is, the stream will be allocated for the finished request, and not for the connection. What is potentially bad blocking flow?
- It will take a lot of memory, since each thread needs a stack memory.
- Everything will slow down, since switching between thread contexts is not a free operation.
- If the backends are blunt, then there will be no free threads in the pool.
We decided to estimate how many streams we will need, and then we will evaluate whether we notice these problems.
How many threads are needed?
The lower limit is easy to estimate.
Suppose now the python logic has such logs:
15:04:00 400 ms GET /vacancies 15:04:00 600 ms GET /resumes 15:04:01 500 ms GET /vacancies 15:04:01 600 ms GET /resumes The second column is the time from the request to the response. That is, the logic processed:
15:04:00 - 1000 ms 15:04:01 - 1100 ms If we allocate a stream for processing each request, then:
- at 3:04:00 pm theoretically we can do with one thread, which first processes the GET / vacancies request, and then processes the GET / resumes request;
- at 15:04:01, at least 2 streams will have to be allocated, since one stream cannot process more than a second requests in one second.
In fact, at the most stressful time on python logic, such a total query duration:
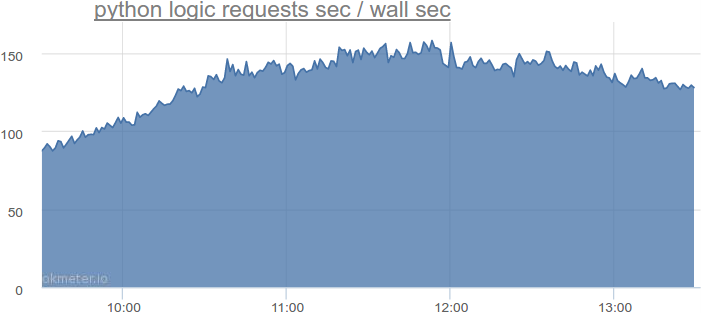
More than 150 seconds of requests per second. That is, we need more than 150 threads. Remember this number. But we still need to somehow take into account that requests come unevenly, the thread can be returned to the pool not immediately after processing the request, but a little later, and so on.
Let's take another service that is blocked when going to the database, see how many threads it needs, and extrapolate the numbers. For example, the service of invitations and feedback:
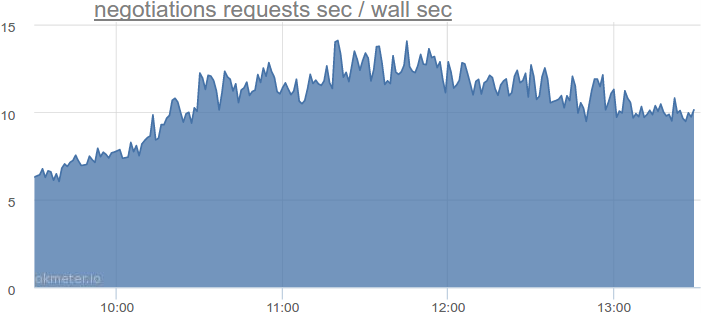
Up to 14 seconds of requests per second. And what about the actual use of streams?
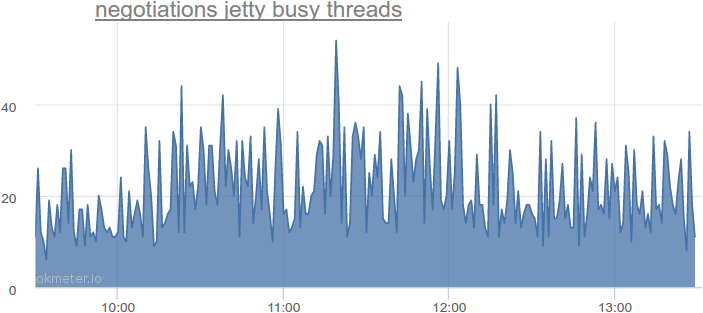
Up to 54 simultaneously used streams, which is 2-4 times more compared to the theoretically minimal amount. We looked at other services - there is a similar picture.
It is appropriate to make a small digression. In HeadHunter, jetty is used as the http server, but other http servers have a similar architecture:
- each request is a task;
- this task enters the queue before the thread pool;
- if there is free flow in the pool, it takes the task from the queue and executes it;
- if there is no free stream, the task is in the queue until the free stream appears.
If we are not afraid that the request will be in the queue for some time - you can select a little more threads than the calculated minimum. But if we want to reduce delays as much as possible, we need to allocate more flows.
Let's select 4 times more threads.
That is, if we now translate the entire python logic to java logic with a blocking architecture, then we will need 150 * 4 = 600 threads.
Let's imagine that the load will increase by 2 times. Then, if we do not rest on the CPU, we will need 1200 threads.
Let's also imagine that our backends are stupid, and it takes 2 times more time to service requests, but more on that later, for as long as there are 2400 threads.
Now the python logic is spinning on four servers, that is, there will be 2400/4 = 600 threads on each server.
600 threads is a lot or a little?
Are hundreds of threads a lot or a little?
By default, on 64-bit machines, java allocates 1 MB of memory for the thread stack.
That is, 600 threads will require 600 MB of memory. Not a disaster. In addition, it is 600 MB of virtual address space. Physical RAM will be used only when this memory is actually required. We almost never need 1 MB of stack, we often pinch it to 512 KB. In this sense, neither 600 nor even 1000 flows is a problem for us.
What about the cost of context switching between threads?
Here is a simple java test:
- create a pool of threads of 1, 2, 4, 8 ... 4096;
- we throw 16 384 tasks into it;
- each task is 600,000 iterations of folding random numbers;
- we are waiting for all the tasks;
- run the test 2 times to warm up;
- we run the test 5 more times and take the average time.
static final int numOfWarmUps = 2; static final int numOfTests = 5; static final int numOfTasks = 16_384; static final int numOfIterationsPerTask = 600_000; public static void main(String[] args) throws Exception { for (int numOfThreads : new int[] {1, 2, 4, 8, 16, 32, 64, 128, 256, 512, 1024, 2048, 4096}) { System.out.println(numOfThreads + " threads."); ExecutorService executorService = Executors.newFixedThreadPool(numOfThreads); System.out.println("Warming up..."); for (int i=0; i < numOfWarmUps; i++) { test(executorService); } System.out.println("Testing..."); for (int i = 0; i < numOfTests; i++) { long start = currentTimeMillis(); test(executorService); System.out.println(currentTimeMillis() - start); } executorService.shutdown(); executorService.awaitTermination(1, TimeUnit.SECONDS); System.out.println(); } } static void test(ExecutorService executorService) throws Exception { List<Future<Integer>> resultsFutures = new ArrayList<>(numOfTasks); for (int i = 0; i < numOfTasks; i++) { resultsFutures.add(executorService.submit(new Task())); } for (Future<Integer> resultFuture : resultsFutures) { resultFuture.get(); } } static class Task implements Callable<Integer> { private final Random random = new Random(); @Override public Integer call() throws InterruptedException { int sum = 0; for (int i = 0; i < numOfIterationsPerTask; i++) { sum += random.nextInt(); } return sum; } } Here are the results on 4-core i7-3820, HyperThreading is disabled, Ubuntu Linux 64-bit. We expect that the best result will show a pool with four threads (by the number of cores), so we compare the remaining results with it:
| Number of threads | Average time, ms | Standard deviation | Difference% |
|---|---|---|---|
| one | 109152 | 9.6 | 287.70% |
| 2 | 55072 | 35.6 | 95.61% |
| four | 28153 | 3.8 | 0.00% |
| eight | 28142 | 2.8 | -0.04% |
| sixteen | 28141 | 3.6 | -0.04% |
| 32 | 28152 | 3.7 | 0.00% |
| 64 | 28149 | 6,6 | -0.01% |
| 128 | 28146 | 2.3 | -0.02% |
| 256 | 28146 | 4.1 | -0.03% |
| 512 | 28148 | 2.7 | -0.02% |
| 1024 | 28146 | 2.8 | -0.03% |
| 2048 | 28157 | 5.0 | 0.01% |
| 4096 | 28160 | 3.0 | 0.02% |
The difference between 4 and 4096 streams is comparable to the error. So in terms of overhead from switching contexts 600 threads for us is not a problem.
And if backends blunted?
Imagine that we have blunted one of the backends, and now requests to it take 2, 4, 10 times more time. This can lead to the fact that all threads will hang blocked, and we can not handle other requests that this backend is not needed. In this case, we can do several things.
First, keep in reserve even more threads.
Secondly, set hard timeouts. Timeouts must be monitored, this can be a problem. Is it worth writing asynchronous code? The question is open.
Thirdly, no one forces us to write everything in a synchronous style. For example, we can write some controllers in asynchronous style, if we expect problems with backends.
Thus, for the service of hikes on backends under our loads, we made a choice in favor of a predominantly blocking architecture. Yes, we need to keep track of timeouts, and we cannot quickly scale up to 100 times. But, on the other hand, we can write simple and clear code, release business features faster and spend less time on support, which, in my opinion, is also very cool.
useful links
Source: https://habr.com/ru/post/280892/
All Articles