How the memory is arranged NetApp FAS: NVRAM, Kesh and Tetris
In this article I want to look at the internal structure of the NetApp FAS storage system and how it can collect Tetris.

The storage memory of any NetApp FAS controller consists of RAM modules that are used for reading and writing caching, and are powered by a battery, hence the “NV” prefix - Non Volatile MEMory / RAM / LOG. RAM is divided into the following functional parts: NVRAM, MBUF buffer (or system cache), which are more detailed.

')
* Data is reset to disk from MBUF, according to the NVRAM full event , and not from NVRAM itself.
NVRAM consistently, like LOG entries in the database, gathers NVLOG entries, in their original form, as they were sent by the hosts. As soon as the data from the host enters NVRAM, the host receives a confirmation of the record. After the CP event occurs, which generates a data reset from the MBUF to the disks, followed by confirmation, the NVRAM is cleared. Thus, in a normally running storage system, the contents of NVRAM are never read, but only written, and when space ends there, a CP occurs and the NVRAM is cleared. Reading NVRAM occurs only after a crash.
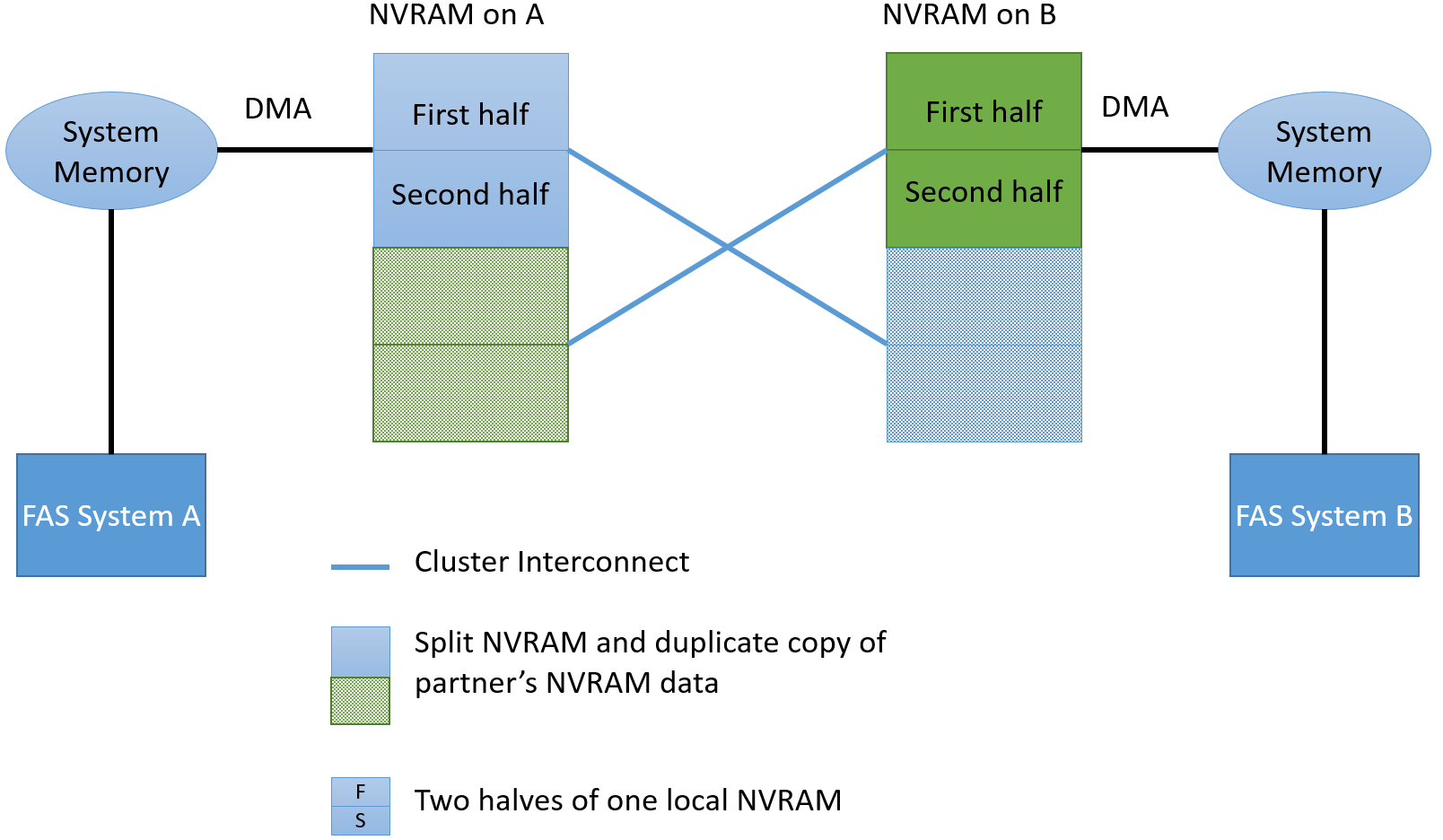
In the High Availability (HA) pair, of two NetApp FAS controllers, NVRAM is always mirrored, each controller has a copy of its neighbor. This allows in case of failure of one controller to switch and continue to service all hosts to the remaining controller. After the CP event occurs (data is flushed to the confirmation disk), the NVRAM is cleared.
To be more precise, each of these two parts is further divided into two parts, for a total of 4 for the HA pair (i.e., 2 local). This was done to ensure that after filling in half of the local NVRAM, the data reset did not slow down the new incoming commands. That is, while data is being reset from one part of the local NVRAM, new ones are already arriving in the second half of the local NVRAM.
In order to protect data from Split-Brain in the MCC , the data that is received on the recording will be confirmed to the host only after they get into the NVRAM of one local controller, its neighbor and one remote neighbor (if the MCC consists of 4 nodes ). Synchronization between local controllers is performed via HA Interconnect (this is an external connection for two-controller systems in two different chassis), and synchronization to a remote node is performed via FC-IV adapters (this is also an external connection). This scheme allows you to perform switching within the site if the second HA controller of the pair is intact, or switch to the second site if all local storage nodes have failed. Switching to the second site occurs in seconds.

It is important to note that NVRAM, on the one hand, is a technology that is not only in service with NetApp, but on the other hand, is used by NetApp to store logs (hardware implementation of a journaling file system), while most other storage vendors use NVRAM at the “block level” (Disk Driver level or Disk Cache) for caching data in NVRAM - this is a big difference.
The presence of NVLOG allows NetApp FAS not to transfer in the HA pair, the surviving single controller to the Pass-Through mode (write, without cache, directly to the disks) if one of them died. Let's dwell on this a bit and start with why we need a write cache at all? The cache is needed to deceive the hosts and speed up the recording, it confirms the recording of the data before, how the data actually gets on the disks. Why bother to switch the controller to Pass-Through mode, if the cache has a battery, while all A-brands of the storage system also have a cache mirroring in the HA pair? The answer is not quite easy to see at a glance, first, the HA mechanism ensures that the data is not damaged and dumped onto the disks when one of the two controllers in the HA pair fails, and the clients transparently switch to the partner, secondly, the most important, in this case, that the data were not damaged at the level of the data structure of the storage itself, it is worthwhile to dwell on this in more detail. Recalculation of check-sums for RAID, in memory, is not new for a long time, as it speeds up the disk subsystem, many if not all A-brands have mastered this trick, but it is the reset of data from the cache in the already processed RAID-level leaves the likelihood of data corruption which cannot be traced and restored after the restart of the two controllers . So, if the first controller fails, and then the second controller fails, it may turn out that it is impossible to track the integrity of the initially received data as a result of processing, that is, the data may be damaged, in other situations it is possible to track and repair the damage, but for this it is necessary to start checking the data storage structure. Since the write cache becomes a cornerstone and a potential big problem, when a single controller fails in an AT pair, most storage systems need to go into PassThrough mode with direct writing to discs by turning off the write cache to eliminate the likelihood of damage to their file structure.
On the other hand, most of these storage systems allow the administrator to manually transfer the surviving controller manually to the record caching mode, but this is not safe, because if the second controller fails, the data at the file storage structure level may be damaged and will have to be restored. sometimes it can lead to tragic consequences. Due to the fact that FAS systems store data in the form of logs, and not in the processed form after WAFL or RAID , and the already processed data is reset as rolling a system snapshot of CP, in a single transaction, this allows you to completely circumvent the probability of data corruption. Thus, in many modern competing storage systems, when one controller dies in an HA pair, it is not only that the load from the dead controller drops to the second, it also disables its cache to optimize entries, which greatly impairs the speed in such situations. This is done to ensure that the recorded data is accurately recorded in a non-corrupted form on the disks, and most importantly, the file structure of the storage system remains uncorrupted. Some do not bother with this question at all and just honestly write about this “nuance” in their documentation. And some try to circumvent this problem with the help of a “crutch”, offering to buy not 4-node, but 4-node system at once. So, for example, the HP 3PAR system is arranged, where in the event of a single controller failure, in the 4 node system, the remaining 3 controllers will work in normal recording mode, but in the event of a failure of 50% of the node, the system will go into Pass-through. Sometimes there are funny situations when it is better that the entire storage system has already died, rather than that it works with such terrible brakes. This contrasts with FAS systems, which even in single-channel configurations never turn off the cache, as they are architecturally protected from such problems.
Writing, in fact, always happens in the MBUF (Write Memory Buffer). And from it using the Direct Memory Access (DMA) request, NVRAM performs a copy of this data to itself, which saves CPU resources. After that, the WAFL module allocates block ranges to which data from the MBUF will be written, this process is called Write Allocation. The WAFL module does not just allocate mindlessly blocks, but first collects Tetris (oh yeah, Tetris! Did you not hear about it?, Then look at the 28th minute), and allocate empty blocks, so as to be able to burn all Tetris on disks with one inseparable a piece.
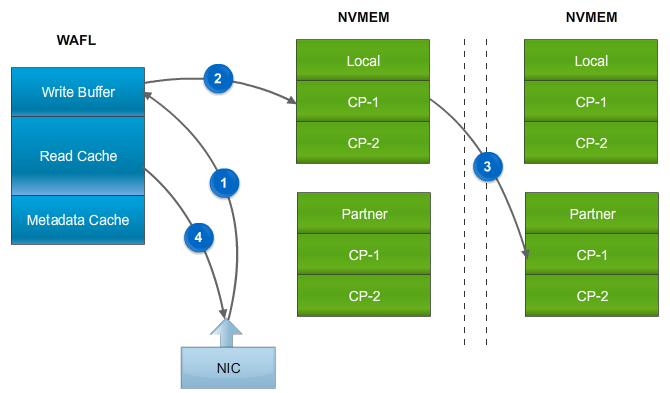
WAFL also performs other write optimizations for data. After the record confirmation from NVRAM comes to the WAFL module, the data from the MBUF, according to the selected blocks, is processed by the RAID module, where the checksum for the pair of disks is calculated and the checksum is calculated, which is stored with each block (Block / Zone checksums). It is also important to note that the data from MBUF being transferred to the RAID module is “unpacked”, for example, some commands may request recording of a repeating pattern of information blocks or a request for moving blocks, such commands themselves do not take up much space in NVRAM, but when “unpacking” generate a large amount of new data.
This is part of WAFL, which has undergone significant changes from its original device architecture, especially in terms of working with new information carriers and parallelization (the new architecture began to be delivered in 2011) and prepared a springboard for using new storage technologies that may appear in the near future. Thanks to the intelligence of your device, Write Allocation allows you to granularly write data in different ways and to different places of the disk subsystem. Each separate stream of recorded information is processed separately and can be processed, depending on how the data is written, read, the block size and the nature of the record (and others). Based on the nature of the recorded WAFL data, it can decide on what type of media it is worth writing it in which way. An example of this is Flash drives, where it makes sense to write with granularity and along block boundaries, which erase block size takes place. In addition, meta information, which usually takes up a lot less space than the data itself, can be placed separately from large blocks with useful data, in some cases it has a great advantage, which was established experimentally. In fact, the description of the internal device Write Allocation is a separate, very large topic.
From the WAFL module, the data is transferred to the RAID module, which processes and writes them in one transaction, stripes to disks, including parity disks. And since the data is always written in stripes and always in a new place, the data for parity disks do not need to be recalculated, they were already prepared for recording by the RAID module. Due to this, in FAS systems in practice, parity disks are always much less loaded than other disks, which contrasts with the usual implementation of RAID 4/6. It is also worth noting that the check-sum calculation is performed immediately for the entire stripe of the recorded data, never overwriting the data (recording occurs to a new place), only the meta-information changes (links to new blocks with data). This leads to the fact that in the case of overwriting one of the disks it is not necessary to read the information from the other disks into the memory each time and recalculate the check-sum, thanks to which the system memory is used more efficiently. Read more about the device RAID-DP .

Tetris is a write and read optimization mechanism that collects data, between CPs (CP Time Frame), into chains of blocks of sequences from one host, turning small blocks into larger sequential records (IO-reduction). On the other hand, this allows, without complex logic, to include a preemptive reading of data. So, for example, there is no difference - read 5KB, or 8KB, 13KB or 16KB, etc. This logic is used to read ahead. Read-ahead is a form of caching data that can potentially be requested in the future, followed by the data that has just been requested. And when the question becomes, which “extra” blocks should be read ahead of time for transferring to the cache, with Tetris, you automatically get an answer to this question: those that were recorded along with the requested data.

The system cache (MBUF) is used for both write and read operations. All read operations without exception get into the cache, as well as the newly recorded data is read from it. When the CPU of the storage system cannot find the data in the system cache, it accesses the disks, and the first thing it does is put it into the cache for reading, and then give it to the host. Further, these data can be either simply deleted (the same read cache, everything is on disks) or moved to a level below (cache level II), if there is one: FlashPool (SSD drives, read-write cache) or FlashCache ( PCIe Flash card, read only cache). First, the system cache, both the first and the second level, is pushed out very granularly: i.e. 4 KB block of information can be pushed out. Secondly, the system and level II cache, it is deduplication-aware, i.e. if such a block is duplicated or cloned, it will not be copied again and will take up space in the memory. This significantly improves performance by increasing cache hit. This happens when the dataset on the storage system can be well prodduplitsirovany or cloned many times , for example, in the VDI environment.
Like many modern file systems, WAFL is a journaling file system. Like any journaling file system, a log with log entries is used to ensure consistency and its inherentness at the storage level. While all other implementations of journaling file systems are designed in such a way that if they are damaged, they can roll back to a consistent state (it is necessary to check and restore) and try to recover, WAFL is designed so as to prevent damage in the event of a sudden failure of the controllers. This is achieved, first of all, due to the atomicity of the Consistency Point recording, and secondly due to the use of system snapshots during write operations.
NetApp technology has been so successful that ONTAP is literally everywhere, as a basis, for many other features and functions. Let me remind you that CP contains data already processed by WAFL and RAID. The CP is also a snapshot, which, before the contents are dumped from the system memory (after being processed by the WAFL and RAID modules), the data storage system removes the system snapshot from the unit, and adds new data to the disks, then the data storage system marks the data successfully. after which it clears NVLOG entries in NVRAM. Before a new data is reset to disk (always to a new place), a system snapshot is taken, after which the data is either recorded as a whole in one transaction or (in case of an accident) the previously created snapshot is used (at the aggregate level) as the last working version of the file system in case of a sudden restart of the storage system in the middle of a transaction. If a failure has occurred and both controllers have rebooted or have lost power, the data from NVRAM will restore all the information and reset the data to the disks as soon as the controllers are turned on again. If only one controller turns off or reboots, the second controller from the copy of NVLOG to NVRAM will immediately restore the data and write it down, it will even happen transparently for the applications. When data is successfully dumped onto disks, the last CP block, based on the old root inode (snepshot), creates a new one, including references to old and new, newly recorded data.
A CP is an event that is automatically generated under one of several conditions:
By the way, the CP reset status, very often, may indirectly indicate what problems exist in the storage system, for example, when you do not have enough spindles or they are damaged . Learn more about working in an article on the Knowledge Base FAQ: Consistency Point .
As mentioned earlier, NVRAM is used in FAS systems as a storage of log records, rather than a write cache, so its size, in HDD and hybrid FAS systems, is not as large as its competitors. Just to increase NVRAM is not necessary. Each system is designed so that it has enough resources to service the maximum supported number of spindles.
As already mentioned, the battery powers the system memory. But it also powers the system flash disk installed in the controller. In the event of a power failure, after that, the contents of the memory will be merged onto the system Flash-drive, so the storage system can live for a very long time in the off state. Restore content to memory automatically when you start storage. The battery can withstand up to 72 hours, and therefore, if the power is restored during this time, the contents will remain in the cache and recovery from the system Flash-drive will not occur.
As mentioned earlier, WAFL always writes to a new place, this is done architecturally for a variety of reasons, and one of them is the job of resetting the MBUF contents as a snapshot. After all, otherwise, in the case of physical rewriting of blocks - new ones, on top of old ones, with an incomplete cache reset transaction, this could lead to data corruption. It turned out that the “write to a new place” approach is very successful not only for rotating disks, and the snepshot mechanism, but also for Flash technologies, due to the need to evenly dispose of all the cells of SSD disks.
NetApp FAS RAM not only accelerates read and write operations, but is also architecturally designed to provide high reliability, speed and optimization for such operations. Rich functionality, multiple protection and system cache speed are qualitatively distinguished by A-class systems, for high productive loads and critical tasks.
English translation
How memory works in ONTAP:
This may contain links to Habra articles that will be published later .
I ask to send messages on errors in the text to the LAN .
Comments, additions and questions on the article on the contrary, please in the comments .
System memory
The storage memory of any NetApp FAS controller consists of RAM modules that are used for reading and writing caching, and are powered by a battery, hence the “NV” prefix - Non Volatile MEMory / RAM / LOG. RAM is divided into the following functional parts: NVRAM, MBUF buffer (or system cache), which are more detailed.
')
* Data is reset to disk from MBUF, according to the NVRAM full event , and not from NVRAM itself.
NVRAM & NVLOG
NVRAM consistently, like LOG entries in the database, gathers NVLOG entries, in their original form, as they were sent by the hosts. As soon as the data from the host enters NVRAM, the host receives a confirmation of the record. After the CP event occurs, which generates a data reset from the MBUF to the disks, followed by confirmation, the NVRAM is cleared. Thus, in a normally running storage system, the contents of NVRAM are never read, but only written, and when space ends there, a CP occurs and the NVRAM is cleared. Reading NVRAM occurs only after a crash.
NVRAM to HA
In the High Availability (HA) pair, of two NetApp FAS controllers, NVRAM is always mirrored, each controller has a copy of its neighbor. This allows in case of failure of one controller to switch and continue to service all hosts to the remaining controller. After the CP event occurs (data is flushed to the confirmation disk), the NVRAM is cleared.
To be more precise, each of these two parts is further divided into two parts, for a total of 4 for the HA pair (i.e., 2 local). This was done to ensure that after filling in half of the local NVRAM, the data reset did not slow down the new incoming commands. That is, while data is being reset from one part of the local NVRAM, new ones are already arriving in the second half of the local NVRAM.
NVRAM to MCC
In order to protect data from Split-Brain in the MCC , the data that is received on the recording will be confirmed to the host only after they get into the NVRAM of one local controller, its neighbor and one remote neighbor (if the MCC consists of 4 nodes ). Synchronization between local controllers is performed via HA Interconnect (this is an external connection for two-controller systems in two different chassis), and synchronization to a remote node is performed via FC-IV adapters (this is also an external connection). This scheme allows you to perform switching within the site if the second HA controller of the pair is intact, or switch to the second site if all local storage nodes have failed. Switching to the second site occurs in seconds.
NVRAM & Pass-Through
It is important to note that NVRAM, on the one hand, is a technology that is not only in service with NetApp, but on the other hand, is used by NetApp to store logs (hardware implementation of a journaling file system), while most other storage vendors use NVRAM at the “block level” (Disk Driver level or Disk Cache) for caching data in NVRAM - this is a big difference.
The presence of NVLOG allows NetApp FAS not to transfer in the HA pair, the surviving single controller to the Pass-Through mode (write, without cache, directly to the disks) if one of them died. Let's dwell on this a bit and start with why we need a write cache at all? The cache is needed to deceive the hosts and speed up the recording, it confirms the recording of the data before, how the data actually gets on the disks. Why bother to switch the controller to Pass-Through mode, if the cache has a battery, while all A-brands of the storage system also have a cache mirroring in the HA pair? The answer is not quite easy to see at a glance, first, the HA mechanism ensures that the data is not damaged and dumped onto the disks when one of the two controllers in the HA pair fails, and the clients transparently switch to the partner, secondly, the most important, in this case, that the data were not damaged at the level of the data structure of the storage itself, it is worthwhile to dwell on this in more detail. Recalculation of check-sums for RAID, in memory, is not new for a long time, as it speeds up the disk subsystem, many if not all A-brands have mastered this trick, but it is the reset of data from the cache in the already processed RAID-level leaves the likelihood of data corruption which cannot be traced and restored after the restart of the two controllers . So, if the first controller fails, and then the second controller fails, it may turn out that it is impossible to track the integrity of the initially received data as a result of processing, that is, the data may be damaged, in other situations it is possible to track and repair the damage, but for this it is necessary to start checking the data storage structure. Since the write cache becomes a cornerstone and a potential big problem, when a single controller fails in an AT pair, most storage systems need to go into PassThrough mode with direct writing to discs by turning off the write cache to eliminate the likelihood of damage to their file structure.
On the other hand, most of these storage systems allow the administrator to manually transfer the surviving controller manually to the record caching mode, but this is not safe, because if the second controller fails, the data at the file storage structure level may be damaged and will have to be restored. sometimes it can lead to tragic consequences. Due to the fact that FAS systems store data in the form of logs, and not in the processed form after WAFL or RAID , and the already processed data is reset as rolling a system snapshot of CP, in a single transaction, this allows you to completely circumvent the probability of data corruption. Thus, in many modern competing storage systems, when one controller dies in an HA pair, it is not only that the load from the dead controller drops to the second, it also disables its cache to optimize entries, which greatly impairs the speed in such situations. This is done to ensure that the recorded data is accurately recorded in a non-corrupted form on the disks, and most importantly, the file structure of the storage system remains uncorrupted. Some do not bother with this question at all and just honestly write about this “nuance” in their documentation. And some try to circumvent this problem with the help of a “crutch”, offering to buy not 4-node, but 4-node system at once. So, for example, the HP 3PAR system is arranged, where in the event of a single controller failure, in the 4 node system, the remaining 3 controllers will work in normal recording mode, but in the event of a failure of 50% of the node, the system will go into Pass-through. Sometimes there are funny situations when it is better that the entire storage system has already died, rather than that it works with such terrible brakes. This contrasts with FAS systems, which even in single-channel configurations never turn off the cache, as they are architecturally protected from such problems.
Memory Buffer: Write
Writing, in fact, always happens in the MBUF (Write Memory Buffer). And from it using the Direct Memory Access (DMA) request, NVRAM performs a copy of this data to itself, which saves CPU resources. After that, the WAFL module allocates block ranges to which data from the MBUF will be written, this process is called Write Allocation. The WAFL module does not just allocate mindlessly blocks, but first collects Tetris (oh yeah, Tetris! Did you not hear about it?, Then look at the 28th minute), and allocate empty blocks, so as to be able to burn all Tetris on disks with one inseparable a piece.
WAFL also performs other write optimizations for data. After the record confirmation from NVRAM comes to the WAFL module, the data from the MBUF, according to the selected blocks, is processed by the RAID module, where the checksum for the pair of disks is calculated and the checksum is calculated, which is stored with each block (Block / Zone checksums). It is also important to note that the data from MBUF being transferred to the RAID module is “unpacked”, for example, some commands may request recording of a repeating pattern of information blocks or a request for moving blocks, such commands themselves do not take up much space in NVRAM, but when “unpacking” generate a large amount of new data.
Write allocation
This is part of WAFL, which has undergone significant changes from its original device architecture, especially in terms of working with new information carriers and parallelization (the new architecture began to be delivered in 2011) and prepared a springboard for using new storage technologies that may appear in the near future. Thanks to the intelligence of your device, Write Allocation allows you to granularly write data in different ways and to different places of the disk subsystem. Each separate stream of recorded information is processed separately and can be processed, depending on how the data is written, read, the block size and the nature of the record (and others). Based on the nature of the recorded WAFL data, it can decide on what type of media it is worth writing it in which way. An example of this is Flash drives, where it makes sense to write with granularity and along block boundaries, which erase block size takes place. In addition, meta information, which usually takes up a lot less space than the data itself, can be placed separately from large blocks with useful data, in some cases it has a great advantage, which was established experimentally. In fact, the description of the internal device Write Allocation is a separate, very large topic.
RAID
From the WAFL module, the data is transferred to the RAID module, which processes and writes them in one transaction, stripes to disks, including parity disks. And since the data is always written in stripes and always in a new place, the data for parity disks do not need to be recalculated, they were already prepared for recording by the RAID module. Due to this, in FAS systems in practice, parity disks are always much less loaded than other disks, which contrasts with the usual implementation of RAID 4/6. It is also worth noting that the check-sum calculation is performed immediately for the entire stripe of the recorded data, never overwriting the data (recording occurs to a new place), only the meta-information changes (links to new blocks with data). This leads to the fact that in the case of overwriting one of the disks it is not necessary to read the information from the other disks into the memory each time and recalculate the check-sum, thanks to which the system memory is used more efficiently. Read more about the device RAID-DP .
Tetris performs IO-reduction
Tetris is a write and read optimization mechanism that collects data, between CPs (CP Time Frame), into chains of blocks of sequences from one host, turning small blocks into larger sequential records (IO-reduction). On the other hand, this allows, without complex logic, to include a preemptive reading of data. So, for example, there is no difference - read 5KB, or 8KB, 13KB or 16KB, etc. This logic is used to read ahead. Read-ahead is a form of caching data that can potentially be requested in the future, followed by the data that has just been requested. And when the question becomes, which “extra” blocks should be read ahead of time for transferring to the cache, with Tetris, you automatically get an answer to this question: those that were recorded along with the requested data.
Read cache
The system cache (MBUF) is used for both write and read operations. All read operations without exception get into the cache, as well as the newly recorded data is read from it. When the CPU of the storage system cannot find the data in the system cache, it accesses the disks, and the first thing it does is put it into the cache for reading, and then give it to the host. Further, these data can be either simply deleted (the same read cache, everything is on disks) or moved to a level below (cache level II), if there is one: FlashPool (SSD drives, read-write cache) or FlashCache ( PCIe Flash card, read only cache). First, the system cache, both the first and the second level, is pushed out very granularly: i.e. 4 KB block of information can be pushed out. Secondly, the system and level II cache, it is deduplication-aware, i.e. if such a block is duplicated or cloned, it will not be copied again and will take up space in the memory. This significantly improves performance by increasing cache hit. This happens when the dataset on the storage system can be well prodduplitsirovany or cloned many times , for example, in the VDI environment.
Consistency point
Like many modern file systems, WAFL is a journaling file system. Like any journaling file system, a log with log entries is used to ensure consistency and its inherentness at the storage level. While all other implementations of journaling file systems are designed in such a way that if they are damaged, they can roll back to a consistent state (it is necessary to check and restore) and try to recover, WAFL is designed so as to prevent damage in the event of a sudden failure of the controllers. This is achieved, first of all, due to the atomicity of the Consistency Point recording, and secondly due to the use of system snapshots during write operations.
NetApp technology has been so successful that ONTAP is literally everywhere, as a basis, for many other features and functions. Let me remind you that CP contains data already processed by WAFL and RAID. The CP is also a snapshot, which, before the contents are dumped from the system memory (after being processed by the WAFL and RAID modules), the data storage system removes the system snapshot from the unit, and adds new data to the disks, then the data storage system marks the data successfully. after which it clears NVLOG entries in NVRAM. Before a new data is reset to disk (always to a new place), a system snapshot is taken, after which the data is either recorded as a whole in one transaction or (in case of an accident) the previously created snapshot is used (at the aggregate level) as the last working version of the file system in case of a sudden restart of the storage system in the middle of a transaction. If a failure has occurred and both controllers have rebooted or have lost power, the data from NVRAM will restore all the information and reset the data to the disks as soon as the controllers are turned on again. If only one controller turns off or reboots, the second controller from the copy of NVLOG to NVRAM will immediately restore the data and write it down, it will even happen transparently for the applications. When data is successfully dumped onto disks, the last CP block, based on the old root inode (snepshot), creates a new one, including references to old and new, newly recorded data.
CP Generating Events
A CP is an event that is automatically generated under one of several conditions:
- 10 seconds passed
- Half NVRAM filled
- local MBUF filled (High Water Mark). It is caused by the fact that one or several commands from the host generated a large amount of data for the CP, for example, recording a certain amount of information by repeating patterns.
- Controller stop command started (Halt)
- Other.
By the way, the CP reset status, very often, may indirectly indicate what problems exist in the storage system, for example, when you do not have enough spindles or they are damaged . Learn more about working in an article on the Knowledge Base FAQ: Consistency Point .
Why is NVRAM size not always important?
As mentioned earlier, NVRAM is used in FAS systems as a storage of log records, rather than a write cache, so its size, in HDD and hybrid FAS systems, is not as large as its competitors. Just to increase NVRAM is not necessary. Each system is designed so that it has enough resources to service the maximum supported number of spindles.
Battery and Flash Disk
As already mentioned, the battery powers the system memory. But it also powers the system flash disk installed in the controller. In the event of a power failure, after that, the contents of the memory will be merged onto the system Flash-drive, so the storage system can live for a very long time in the off state. Restore content to memory automatically when you start storage. The battery can withstand up to 72 hours, and therefore, if the power is restored during this time, the contents will remain in the cache and recovery from the system Flash-drive will not occur.
SSD and WAFL
As mentioned earlier, WAFL always writes to a new place, this is done architecturally for a variety of reasons, and one of them is the job of resetting the MBUF contents as a snapshot. After all, otherwise, in the case of physical rewriting of blocks - new ones, on top of old ones, with an incomplete cache reset transaction, this could lead to data corruption. It turned out that the “write to a new place” approach is very successful not only for rotating disks, and the snepshot mechanism, but also for Flash technologies, due to the need to evenly dispose of all the cells of SSD disks.
findings
NetApp FAS RAM not only accelerates read and write operations, but is also architecturally designed to provide high reliability, speed and optimization for such operations. Rich functionality, multiple protection and system cache speed are qualitatively distinguished by A-class systems, for high productive loads and critical tasks.
English translation
How memory works in ONTAP:
- NVRAM / NVMEM (Part 1)
- NVRAM / NVMEM & Write-Through (Part 2)
- Write Allocation, Tetris, MBUF & CP (Part 3)
This may contain links to Habra articles that will be published later .
I ask to send messages on errors in the text to the LAN .
Comments, additions and questions on the article on the contrary, please in the comments .
Source: https://habr.com/ru/post/280616/
All Articles