Four words that can not (the study of Russian obscene vocabulary on the materials of social media)
A friend of mine, a Latin teacher, at the beginning of the lesson asked his students if they had done their homework. As a rule, if not the first, then the second or third student confessed: forgive me, Mr. Teacher, I have not done anything. “ Fak !” Said the teacher. “ Fak !” He repeated, introducing his children into even more bewilderment. “Today we will pass the verb of the third conjugation of the facio - to do, ” which in the imperative mood of the singular is pronounced: fac ! - do it !
No, we are not going to believe that there are no good and bad words, but our assessment of them. Also, we will not talk about the origins and functions of the Russian battle, will not discuss the moral side of the issue, as well as look for the causal relationships of its use. We will conduct a small study of obscene vocabulary on the materials of the Russian-speaking soc. media, we will make a number of measurements and calculations on a large sample of Internet sources.
As a material, a two-month stream of the Russian-speaking segment of social services was processed. media collected by Brand-Analytics from the beginning of November 2014 to the beginning of January 2015 (why this period was chosen will become clear at the end of the article). About 45 billion words were processed (set Big Data tag). The processing consisted in building frequency dictionaries (unigrams and bigrams) for each day and building language models - the SRILM tool (set the Text Mining tag).
Thus, it was possible to see the dynamics of any word or phrase during this period. We looked different and much. Something like something not. For example, Figure 1 shows the frequencies of personal pronouns and prepositions:
')
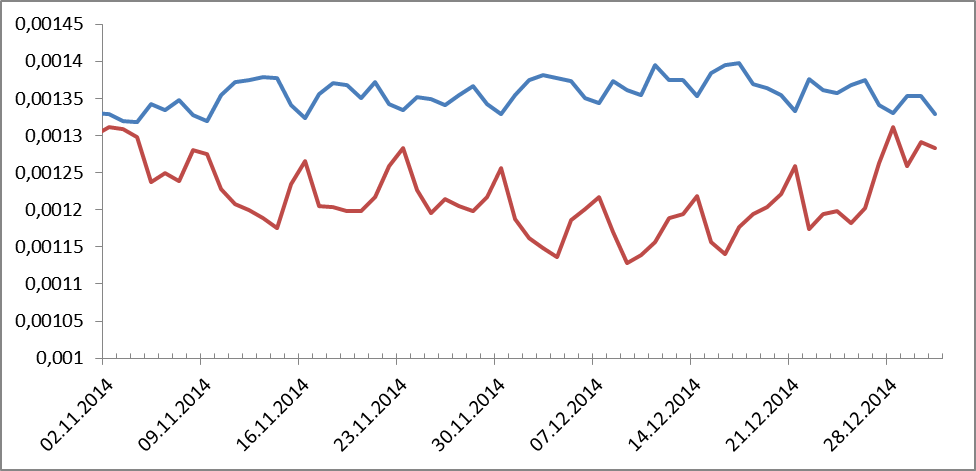
Figure 1. Dynamics of frequency distributions for prepositions (blue color) and personal pronouns (red color).
Appeared in antiphase. Suddenly, right? And the peaks - as you guess - the weekend. And what did they say about money? We look:
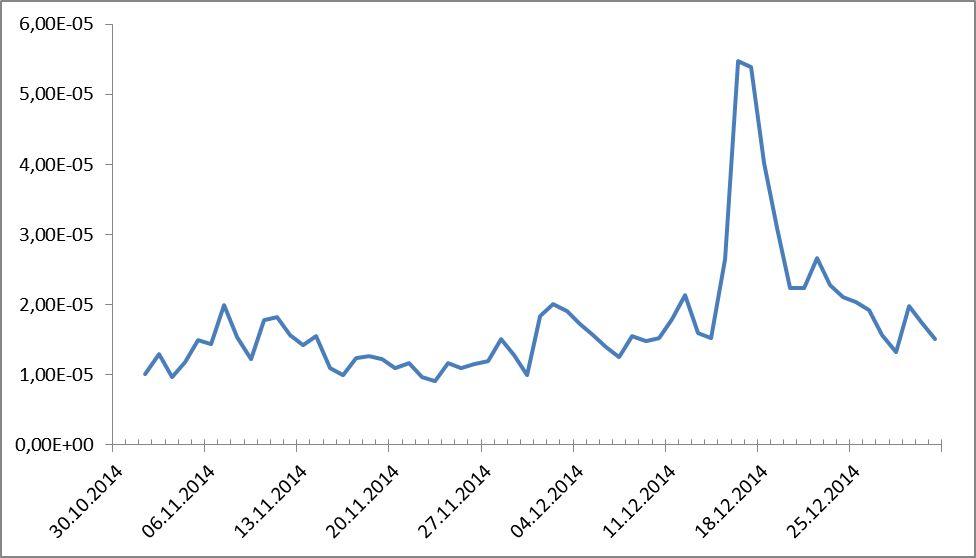
Figure 2. Dynamics of frequency distributions for the names of monetary units.
There seems to be no questions, everyone remembers December 18, 2014. But if someone forgot, then we recall:
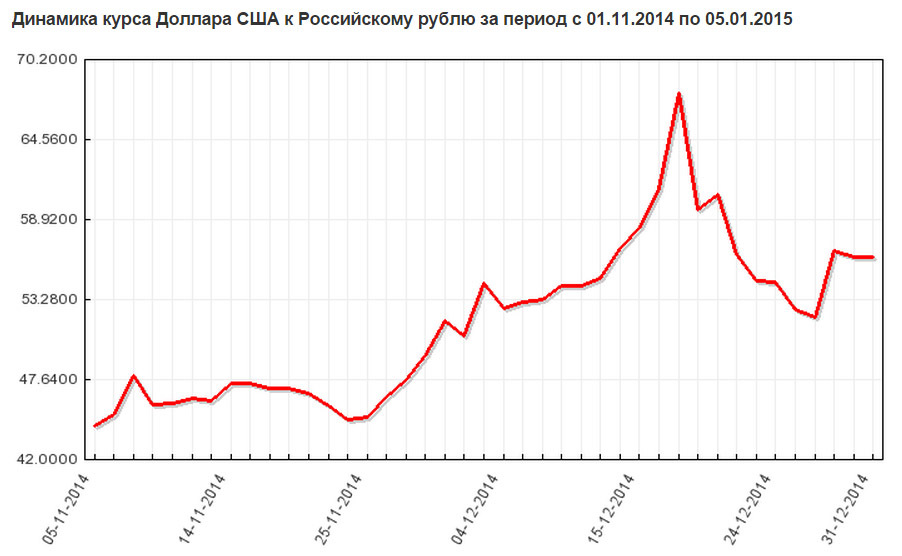
But this is a topic for a separate publication. Well, how can you not see what you can not say with the ladies, and even more so to write on a respected Habré! Yes, their - our, Russian, fourcherished famous words.
Ok, it is said - done. They took our filter Russian obscene vocabulary. And there are already more than five hundred unique words with morphotypes. Generated all word forms. Something around 8650 turned out. Wow, however, not a frail word formation ...
So that we are not banned for foul language, and plus, as they say, “when I ask the ladies I don’t express myself”, let's do this: conditionally combine them (by the way of the pronoun anaphora: vocabulary, I will not) on the morphological basis and call them in groups of their immutable components letters (well, yet these words know, no need to explain?):
Let's add two more:
Note We took into account all the word forms, including illiterately written (changing letters: bea ), lengthening the shock vowels ( * lyaia ) and the most frequent errors, you know yourself. Euphemisms did not take into account, i.e. any damn, fuck, bang - the normal words themselves.
At once we will say that from these 8,650 words about a thousand were found throughout the frequency distribution. First, the frequency dictionaries were cut off: 95% of the sum of the frequency distribution were taken into account (i.e., the tail was cut off - which would bring all the trash with it), which made it possible to reduce to 30-50% of the volume of the dictionary, but only 5% of the original material), and secondly, many word forms and the truth turned out exotic.
Note (if anyone is interested). The frequency of the vocabulary we study begins with the end of the second thousand of the ranked by issuance frequency (out of almost 12 million tokens).
So, we build and watch graphics. The first graph is the absolute number of words found by groups:
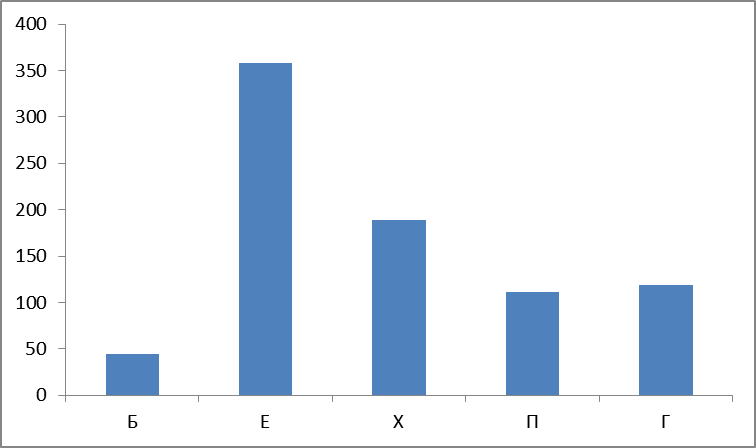
Figure 4. The absolute number of words found by groups.
And in frequency expression (more precisely, we operate with inverse or normalized frequencies)? But chart two:
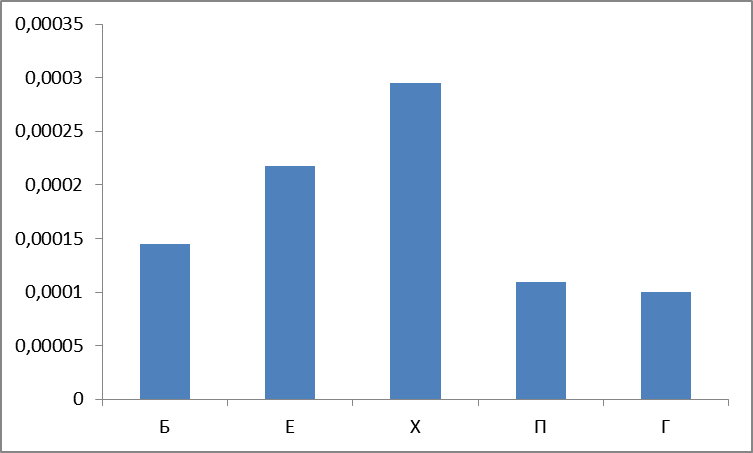
Figure 5. The sum of the normalized frequencies of the words found by groups.
And now the average: the sum of frequencies normalized to the absolute amount:

Figure 6. The average of the normalized frequencies of the words found by groups.
This is the first surprise : it is believed that the most frequent groups P , X , E (“ very frequency“ sexual ”triad ”) - but no, group B leads, and with a large margin.
And why do we always carry group G along? But why: on all the graphs it can be seen that the sum of P + X + B + E, both in absolute and in relative values, is definitely greater than the group G. That is, as expected, ourmother of the most abusive mat in the world belongs to the sexual type (Sex-culture), in spite of the Germans, Czechs and "other Swedes" with their Scheiss-culture - that's what Group G came in handy.
What else can you see? And let's calculate the variance?
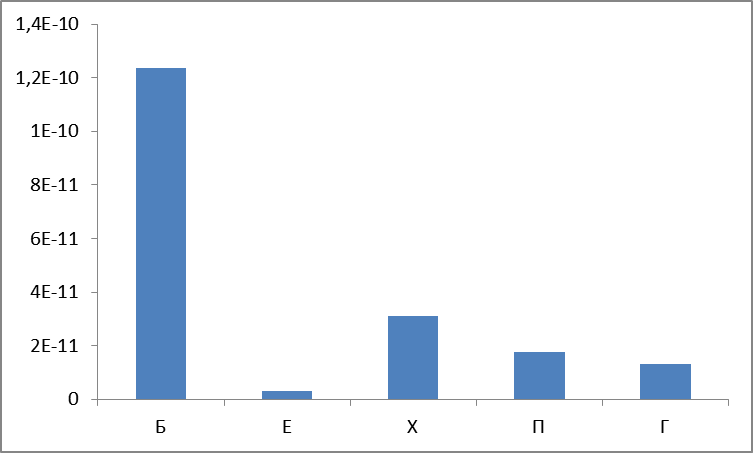
Figure 7. Variance by groups.
In general, it is not surprising that the most frequency group has the greatest variance (a consequence of the notorious Zipf law ). Group E turned out to be the most stable, because its distribution is the most even and concentrated not in the extreme areas.
Good. We look further. It is interesting, and what is the distribution in parts of speech. This is not a simple question. Because out of context it is not always possible to unambiguously determine the part of speech in obscene language. Often a noun is used as an interjection, adverb, or even a particle (negation in group X , for example). Therefore, we build pie charts with some error. However:
Figure 8. The distribution of words of each group in parts of speech. Abbreviations: adj, adjectives, verb - verbs, noun - nouns, inter - interjections, part - particles, adv - adverbs.
What conclusions can we draw by looking at all this? Group B significantly lags behind the groups X , E and P in variation. And for reasons we do not understand, it almost does not form verbs. But the group X is just full of. But we will leave the analysis of this phenomenon to professionals in this field ...
And now the most interesting thing: what is the dynamics of the use of the object under study during the specified period, i.e. during the crisis of the end of 2014, passed into permanent? And here it becomes even more interesting:
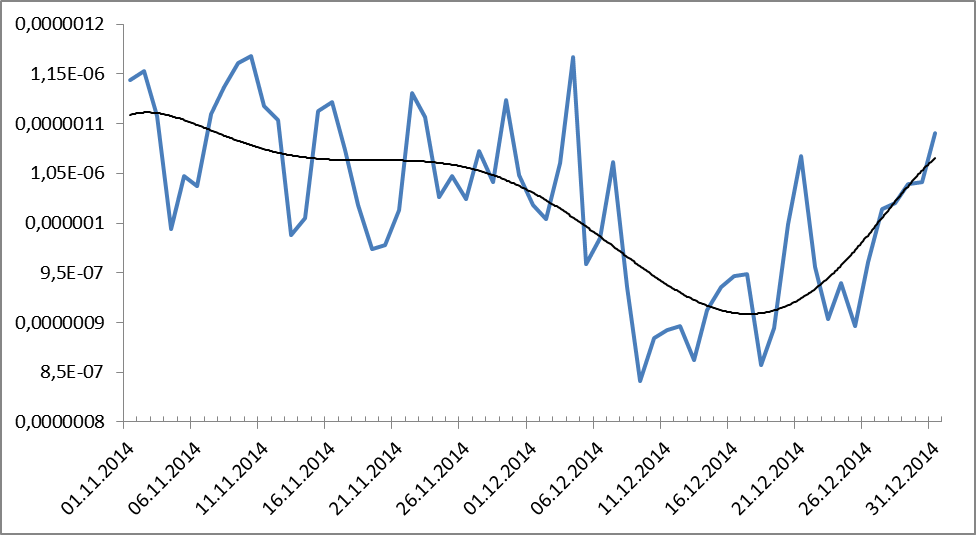
Figure 9. Dynamics of the frequency distribution of obscene vocabulary for the period from 1.11.2014 to 31.12.2014. Black shows the trend line (polynomial, 9th degree).
What does this work out? In crisis, the use of obscene language drops? So, yes.
We make intermediate conclusions:
Maybe somewhere a mistake? How to check? And let's see the dynamics of the complexity of the text, its perplexity ? It is difficult, of course, to work with such volumes, but what to do. Calculated received:

Figure 10. Dynamics of distribution of perplexity for the period from 11/01/2014 to 12/31/2014. Black shows the trend line (polynomial, 9th degree).
Note The great importance of perplexity is due to the fact that due to large volumes we used strong smoothing and imposed frequency restrictions. Counted on unigrams and bigrams.
Again a surprise : and the complexity also falls. So, we thought we were right: emotionality is associated with complexity. But they made a mistake on “pi in half” on the assumption that during a crisis, emotions should “go off scale” - exactly the opposite.
Maybe it is connected with the change in the number of publications in a crisis? Then here is another graph of the number of word usage:
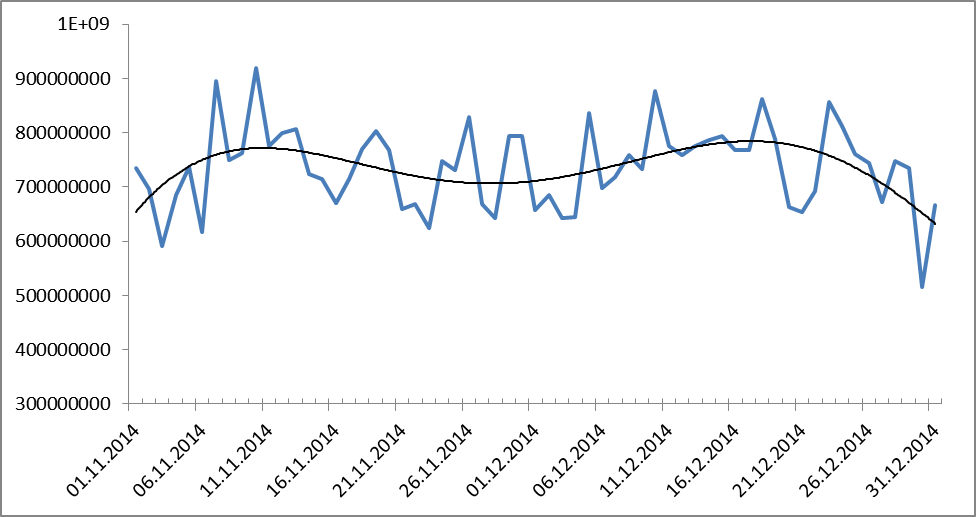
Figure 10. The dynamics of word usage for the period from 1.11.2014 to 31.12.2014. Black shows the trend line (polynomial, 9th degree).
It remains, perhaps, to calculate the correlation (perplexity vs obscene lexicon):
- correlation coefficient ~ 0,51, which, it seems, is not oh so much.
But everything is relative: the correlation of perplexity with prepositions ~ -0.04, and with personal pronouns -0.06.
We do not even know what to withdraw. For serious data analysis it is not enough (just one crisis), and trying to measure something else is a separate article. Maybe so: draw your own conclusions - to use or not to use. Perhaps this will somehow affect the economic crisis ...
Thanks for reading!
No, we are not going to believe that there are no good and bad words, but our assessment of them. Also, we will not talk about the origins and functions of the Russian battle, will not discuss the moral side of the issue, as well as look for the causal relationships of its use. We will conduct a small study of obscene vocabulary on the materials of the Russian-speaking soc. media, we will make a number of measurements and calculations on a large sample of Internet sources.
Mat. part
As a material, a two-month stream of the Russian-speaking segment of social services was processed. media collected by Brand-Analytics from the beginning of November 2014 to the beginning of January 2015 (why this period was chosen will become clear at the end of the article). About 45 billion words were processed (set Big Data tag). The processing consisted in building frequency dictionaries (unigrams and bigrams) for each day and building language models - the SRILM tool (set the Text Mining tag).
Thus, it was possible to see the dynamics of any word or phrase during this period. We looked different and much. Something like something not. For example, Figure 1 shows the frequencies of personal pronouns and prepositions:
')
Figure 1. Dynamics of frequency distributions for prepositions (blue color) and personal pronouns (red color).
Appeared in antiphase. Suddenly, right? And the peaks - as you guess - the weekend. And what did they say about money? We look:
Figure 2. Dynamics of frequency distributions for the names of monetary units.
There seems to be no questions, everyone remembers December 18, 2014. But if someone forgot, then we recall:
But this is a topic for a separate publication. Well, how can you not see what you can not say with the ladies, and even more so to write on a respected Habré! Yes, their - our, Russian, four
Ok, it is said - done. They took our filter Russian obscene vocabulary. And there are already more than five hundred unique words with morphotypes. Generated all word forms. Something around 8650 turned out. Wow, however, not a frail word formation ...
Now experiment and pictures
So that we are not banned for foul language, and plus, as they say, “when I ask the ladies I don’t express myself”, let's do this: conditionally combine them (by the way of the pronoun anaphora: vocabulary, I will not) on the morphological basis and call them in groups of their immutable components letters (well, yet these words know, no need to explain?):
- Group B
- Group X
- Group E
- And group P
Let's add two more:
- Group G (yes, one-root with beef), then it will be clear why.
- And the group O , in the sense of the rest on the letters Mu * , Pid * , etc.
Note We took into account all the word forms, including illiterately written (changing letters: bea ), lengthening the shock vowels ( * lyaia ) and the most frequent errors, you know yourself. Euphemisms did not take into account, i.e. any damn, fuck, bang - the normal words themselves.
At once we will say that from these 8,650 words about a thousand were found throughout the frequency distribution. First, the frequency dictionaries were cut off: 95% of the sum of the frequency distribution were taken into account (i.e., the tail was cut off - which would bring all the trash with it), which made it possible to reduce to 30-50% of the volume of the dictionary, but only 5% of the original material), and secondly, many word forms and the truth turned out exotic.
Note (if anyone is interested). The frequency of the vocabulary we study begins with the end of the second thousand of the ranked by issuance frequency (out of almost 12 million tokens).
So, we build and watch graphics. The first graph is the absolute number of words found by groups:
Figure 4. The absolute number of words found by groups.
And in frequency expression (more precisely, we operate with inverse or normalized frequencies)? But chart two:
Figure 5. The sum of the normalized frequencies of the words found by groups.
And now the average: the sum of frequencies normalized to the absolute amount:
Figure 6. The average of the normalized frequencies of the words found by groups.
This is the first surprise : it is believed that the most frequent groups P , X , E (“ very frequency“ sexual ”triad ”) - but no, group B leads, and with a large margin.
And why do we always carry group G along? But why: on all the graphs it can be seen that the sum of P + X + B + E, both in absolute and in relative values, is definitely greater than the group G. That is, as expected, our
What else can you see? And let's calculate the variance?
Figure 7. Variance by groups.
In general, it is not surprising that the most frequency group has the greatest variance (a consequence of the notorious Zipf law ). Group E turned out to be the most stable, because its distribution is the most even and concentrated not in the extreme areas.
Good. We look further. It is interesting, and what is the distribution in parts of speech. This is not a simple question. Because out of context it is not always possible to unambiguously determine the part of speech in obscene language. Often a noun is used as an interjection, adverb, or even a particle (negation in group X , for example). Therefore, we build pie charts with some error. However:
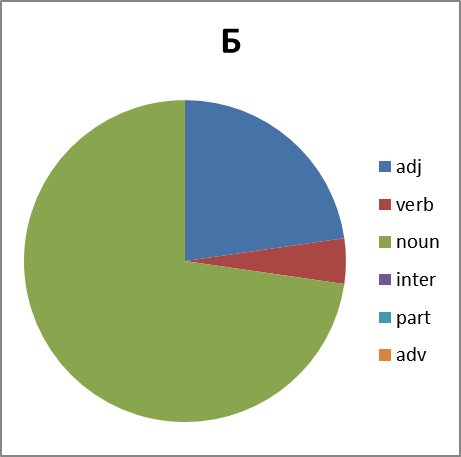 | 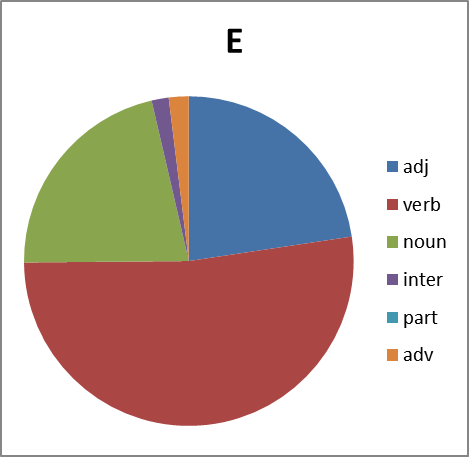 |
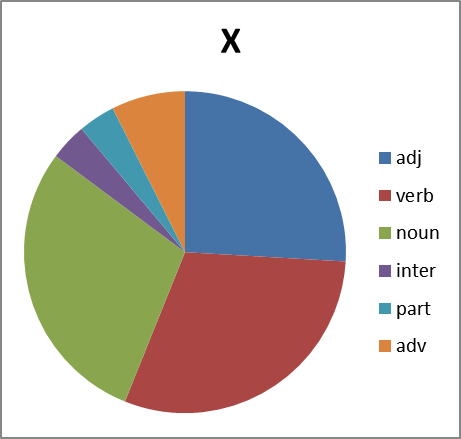 | 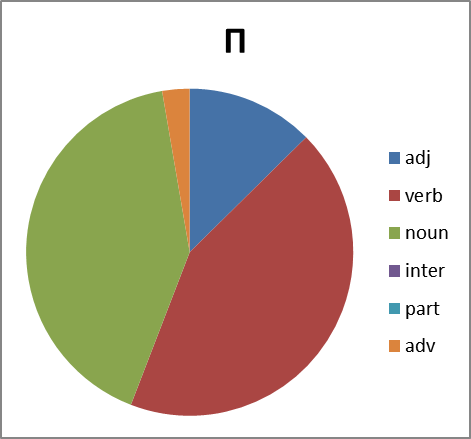 |
Figure 8. The distribution of words of each group in parts of speech. Abbreviations: adj, adjectives, verb - verbs, noun - nouns, inter - interjections, part - particles, adv - adverbs.
What conclusions can we draw by looking at all this? Group B significantly lags behind the groups X , E and P in variation. And for reasons we do not understand, it almost does not form verbs. But the group X is just full of. But we will leave the analysis of this phenomenon to professionals in this field ...
And now the most interesting thing: what is the dynamics of the use of the object under study during the specified period, i.e. during the crisis of the end of 2014, passed into permanent? And here it becomes even more interesting:
Figure 9. Dynamics of the frequency distribution of obscene vocabulary for the period from 1.11.2014 to 31.12.2014. Black shows the trend line (polynomial, 9th degree).
What does this work out? In crisis, the use of obscene language drops? So, yes.
We make intermediate conclusions:
- obscene vocabulary has strong word formation (some lexemes may have several morphotypes). This suggests that its use should increase the entropy of the text, its complexity;
- during a crisis, it seems, emotionality should increase, the use of emotive words should increase, but we see the opposite picture.
Maybe somewhere a mistake? How to check? And let's see the dynamics of the complexity of the text, its perplexity ? It is difficult, of course, to work with such volumes, but what to do. Calculated received:
Figure 10. Dynamics of distribution of perplexity for the period from 11/01/2014 to 12/31/2014. Black shows the trend line (polynomial, 9th degree).
Note The great importance of perplexity is due to the fact that due to large volumes we used strong smoothing and imposed frequency restrictions. Counted on unigrams and bigrams.
Again a surprise : and the complexity also falls. So, we thought we were right: emotionality is associated with complexity. But they made a mistake on “pi in half” on the assumption that during a crisis, emotions should “go off scale” - exactly the opposite.
Maybe it is connected with the change in the number of publications in a crisis? Then here is another graph of the number of word usage:
Figure 10. The dynamics of word usage for the period from 1.11.2014 to 31.12.2014. Black shows the trend line (polynomial, 9th degree).
It remains, perhaps, to calculate the correlation (perplexity vs obscene lexicon):
- correlation coefficient ~ 0,51, which, it seems, is not oh so much.
But everything is relative: the correlation of perplexity with prepositions ~ -0.04, and with personal pronouns -0.06.
findings
We do not even know what to withdraw. For serious data analysis it is not enough (just one crisis), and trying to measure something else is a separate article. Maybe so: draw your own conclusions - to use or not to use. Perhaps this will somehow affect the economic crisis ...
Thanks for reading!
Source: https://habr.com/ru/post/280450/
All Articles