Investigating the performance issues of calling ClassLoader.getResourceAsStream

If you're wondering how a call to the ClassLoader.getResourceAsStream () method in an Android application can take 1432ms and how dangerous some libraries can be - please under cat.
Description of the problem
Exploring performance problems in android applications, I noticed this method. The problem manifested itself only at the very first call, all subsequent took a few milliseconds. An interesting feature was that the problem is in a very large number of applications, ranging from Amazon's Kindle with more than 100,000,000 downloads to small ones with a couple of hundreds of downloads.
')
Another feature is that in different applications, this method took a completely different time. Here, for example, is the time for the most popular selfie application: B612 - Selfie from the heart

As we see, here the method takes 771ms, which is also not small, but much less than 1432ms.
Some more very popular apps to highlight how big the problem is.
(For profiling applications, the https://nimbledroid.com service was used)
| application | Runtime getResourceAsStream () |
|---|---|
| Yahoo Fantasy Sports | 2166ms |
| Timehop | 1538ms |
| Audiobooks from Audible | 1527ms |
| Nike + Running | 1432ms |
| Booking.com Hotel Reservations | 497ms |
And many more others.
Let's take a closer look at the call stack of some applications.
LINE: Free Calls & Messages :

As we can see, the call to getResourceAsStream is NOT in the main stream. This means that Line developers know how slow it is.
Yahoo Fantasy Sports :

The call does not occur in the application code, but inside the JodaTime library
Audiobooks from Audible

The call takes place in the library Logging Logback
After analyzing applications with this problem, it becomes clear that this call is mainly used in various libraries and SDKs that are distributed as jar files. This is logical, because in this way we can access resources, moreover, this code will work on Android, and in the world of great Java. Many come to Android development with Java experience and, of course, begin to use familiar libraries, not knowing how slow their applications are. I think now it is clear why so many applications are affected.
In fact, they know about the problem, for example, there were such questions on stackoverflow: Android Java - Joda Date is slow
Back in 2013, this post was written: http://blog.danlew.net/2013/08/20/joda_time_s_memory_issue_in_android/ and this library appeared https://github.com/dlew/joda-time-android .
BUT
- There are still many applications that use the regular version of JodaTime.
- There are many other libraries and SDKs with the same problem.
Now that the problem is clear, let's try to figure out what causes it.
Research problem
To do this, we will understand the source code of Android.
I will not dwell on where to find the sources, how to build AOSPs, etc., but get right down to business, for those who still want to try to figure it out on their own and repeat my path, start here: https: // source.android.com/
I will use the android-6.0.1_r11 branch
Let's open the libcore / libart / src / main / java / java / lang / ClassLoader.java file and look at the getResourceAsStream code:
public InputStream getResourceAsStream(String resName) { try { URL url = getResource(resName); if (url != null) { return url.openStream(); } } catch (IOException ex) { // Don't want to see the exception. } return null; } Everything looks quite simple, first we find the path to the resource, and if it is not null, then open it with the openStream () method, which is in java.net.URL
Let's look at the implementation of getResource ():
public URL getResource(String resName) { URL resource = parent.getResource(resName); if (resource == null) { resource = findResource(resName); } return resource; } Still nothing interesting, findResource ():
protected URL findResource(String resName) { return null; } Ok, so findResource () is not implemented. ClassLoader is an abstract class, which means we need to find which class is used in real applications. If we open the documentation: http://developer.android.com/reference/java/lang/ClassLoader.html , then we will see: Android provides you with some concrete implementations of the class, with PathClassLoader being one one used. .
I want to make sure of this, so I collected the AOSP by modifying getResourceAsStream () in the same way:
public InputStream getResourceAsStream(String resName) { try { Logger.getLogger("RESEARCH").info("this: " + this); URL url = getResource(resName); if (url != null) { return url.openStream(); } ... I got what was expected - dalvik.system.PathClassLoader , but if we check the source PathClassLoader , we will not find the implementation of findResource () . In fact, findResource () is implemented in the parent class BaseDexClassLoader .
/libcore/dalvik/src/main/java/dalvik/system/BaseDexClassLoader.java :
@Override protected URL findResource(String name) { return pathList.findResource(name); } Let's find the pathList (I do not specifically delete the comments of the developers to make it easier to understand what is what):
public class BaseDexClassLoader extends ClassLoader { private final DexPathList pathList; /** * Constructs an instance. * * @param dexPath the list of jar/apk files containing classes and * resources, delimited by {@code File.pathSeparator}, which * defaults to {@code ":"} on Android * @param optimizedDirectory directory where optimized dex files * should be written; may be {@code null} * @param libraryPath the list of directories containing native * libraries, delimited by {@code File.pathSeparator}; may be * {@code null} * @param parent the parent class loader */ public BaseDexClassLoader(String dexPath, File optimizedDirectory, String libraryPath, ClassLoader parent) { super(parent); this.pathList = new DexPathList(this, dexPath, libraryPath, optimizedDirectory); } Let's go to this DexPathList .
libcore / dalvik / src / main / java / dalvik / system / DexPathList.java :
/** * A pair of lists of entries, associated with a {@code ClassLoader}. * One of the lists is a dex/resource path — typically referred * to as a "class path" — list, and the other names directories * containing native code libraries. Class path entries may be any of: * a {@code .jar} or {@code .zip} file containing an optional * top-level {@code classes.dex} file as well as arbitrary resources, * or a plain {@code .dex} file (with no possibility of associated * resources). * * <p>This class also contains methods to use these lists to look up * classes and resources.</p> */ /*package*/ final class DexPathList { It seems we have found a place where a resource search is actually performed.
/** * Finds the named resource in one of the zip/jar files pointed at * by this instance. This will find the one in the earliest listed * path element. * * @return a URL to the named resource or {@code null} if the * resource is not found in any of the zip/jar files */ public URL findResource(String name) { for (Element element : dexElements) { URL url = element.findResource(name); if (url != null) { return url; } } return null; } Element is just a static inner class in DexPathList . And inside it there is a much more interesting code:
public URL findResource(String name) { maybeInit(); // We support directories so we can run tests and/or legacy code // that uses Class.getResource. if (isDirectory) { File resourceFile = new File(dir, name); if (resourceFile.exists()) { try { return resourceFile.toURI().toURL(); } catch (MalformedURLException ex) { throw new RuntimeException(ex); } } } if (zipFile == null || zipFile.getEntry(name) == null) { /* * Either this element has no zip/jar file (first * clause), or the zip/jar file doesn't have an entry * for the given name (second clause). */ return null; } try { /* * File.toURL() is compliant with RFC 1738 in * always creating absolute path names. If we * construct the URL by concatenating strings, we * might end up with illegal URLs for relative * names. */ return new URL("jar:" + zip.toURL() + "!/" + name); } catch (MalformedURLException ex) { throw new RuntimeException(ex); } } Let's stop at this a little bit. As we know, APK is just a zip file. As we see:
if (zipFile == null || zipFile.getEntry(name) == null) { we are trying to find the ZipEntry by name, and if we find it, we return java.net.URL. This may be a rather slow operation, but if we check the getEntry implementation, we will see that this is just an iteration on LinkedHashMap:
/libcore/luni/src/main/java/java/util/zip/ZipFile.java :
... private final LinkedHashMap<String, ZipEntry> entries = new LinkedHashMap<String, ZipEntry>(); ... public ZipEntry getEntry(String entryName) { checkNotClosed(); if (entryName == null) { throw new NullPointerException("entryName == null"); } ZipEntry ze = entries.get(entryName); if (ze == null) { ze = entries.get(entryName + "/"); } return ze; } This is not a super fast operation, but it can not take a lot of time.
We missed one thing: before working with Zip files, we have to open them. If we again look at the implementation of the DexPathList.Element.findResource () method, we will see a call to maybeInit (); .
Let's check it out:
public synchronized void maybeInit() { if (initialized) { return; } initialized = true; if (isDirectory || zip == null) { return; } try { zipFile = new ZipFile(zip); } catch (IOException ioe) { /* * Note: ZipException (a subclass of IOException) * might get thrown by the ZipFile constructor * (eg if the file isn't actually a zip/jar * file). */ System.logE("Unable to open zip file: " + zip, ioe); zipFile = null; } } Here it is! This line is:
zipFile = new ZipFile(zip); open zip file for reading.
public ZipFile(File file) throws ZipException, IOException { this(file, OPEN_READ); } This is a very slow operation, here we initialize the entries LinkedHashMap. Obviously, the larger the zip file, the longer it will take to open it. Because of the initialized flag, we only open the zip file once, which explains why subsequent calls happen quickly.
To understand more about the internal structure of a Zip file, look at the sources:
https://android.googlesource.com/platform/libcore/+/android-6.0.1_r21/luni/src/main/java/java/util/zip/ZipFile.java
I hope it was interesting! Because it is only the beginning.
In fact, while we dealt only with the challenge:
URL url = getResource(resName); But if we change the getResourceAsStream code like this:
public InputStream getResourceAsStream(String resName) { try { long start; long end; start = System.currentTimeMillis(); URL url = getResource(resName); end = System.currentTimeMillis(); Logger.getLogger("RESEARCH").info("getResource: " + (end - start)); if (url != null) { start = System.currentTimeMillis(); InputStream inputStream = url.openStream(); end = System.currentTimeMillis(); Logger.getLogger("RESEARCH").info("url.openStream: " + (end - start)); return inputStream; } ... If we compile AOSP and test a couple of applications, we will see that url.openStream () takes much more time than getResource () .
url.openStream ()
In this part I will omit some not very interesting moments. If we move along the call chain from url.openStream () , then we will go to /libcore/luni/src/main/java/libcore/net/url/JarURLConnectionImpl.java :
@Override public InputStream getInputStream() throws IOException { if (closed) { throw new IllegalStateException("JarURLConnection InputStream has been closed"); } connect(); if (jarInput != null) { return jarInput; } if (jarEntry == null) { throw new IOException("Jar entry not specified"); } return jarInput = new JarURLConnectionInputStream(jarFile .getInputStream(jarEntry), jarFile); } Let's check the connect () method:
@Override public void connect() throws IOException { if (!connected) { findJarFile(); // ensure the file can be found findJarEntry(); // ensure the entry, if any, can be found connected = true; } } Nothing interesting, we need to go deeper :)
private void findJarFile() throws IOException { if (getUseCaches()) { synchronized (jarCache) { jarFile = jarCache.get(jarFileURL); } if (jarFile == null) { JarFile jar = openJarFile(); synchronized (jarCache) { jarFile = jarCache.get(jarFileURL); if (jarFile == null) { jarCache.put(jarFileURL, jar); jarFile = jar; } else { jar.close(); } } } } else { jarFile = openJarFile(); } if (jarFile == null) { throw new IOException(); } } This is an interesting method and here we will stop. getUseCaches () through a call chain will lead us to
public abstract class URLConnection { ... private static boolean defaultUseCaches = true; ... This value is not overridden, so we will see the use of cache:
private static final HashMap<URL, JarFile> jarCache = new HashMap<URL, JarFile>(); In the findJarFile () method we see the second performance problem! Zip file opens again! Naturally this will not work quickly, especially for applications that are 40mb in size :)
There is another interesting point, let's check the openJarFile () method:
private JarFile openJarFile() throws IOException { if (jarFileURL.getProtocol().equals("file")) { String decodedFile = UriCodec.decode(jarFileURL.getFile()); return new JarFile(new File(decodedFile), true, ZipFile.OPEN_READ); } else { ... As you can see, we are creating NOT ZipFile , but JarFile . JarFile is the heir of ZipFile, let's check what it adds:
/** * Create a new {@code JarFile} using the contents of file. * * @param file * the JAR file as {@link File}. * @param verify * if this JAR filed is signed whether it must be verified. * @param mode * the mode to use, either {@link ZipFile#OPEN_READ OPEN_READ} or * {@link ZipFile#OPEN_DELETE OPEN_DELETE}. * @throws IOException * If the file cannot be read. */ public JarFile(File file, boolean verify, int mode) throws IOException { super(file, mode); // Step 1: Scan the central directory for meta entries (MANIFEST.mf // & possibly the signature files) and read them fully. HashMap<String, byte[]> metaEntries = readMetaEntries(this, verify); // Step 2: Construct a verifier with the information we have. // Verification is possible *only* if the JAR file contains a manifest // *AND* it contains signing related information (signature block // files and the signature files). // // TODO: Is this really the behaviour we want if verify == true ? // We silently skip verification for files that have no manifest or // no signatures. if (verify && metaEntries.containsKey(MANIFEST_NAME) && metaEntries.size() > 1) { // We create the manifest straight away, so that we can create // the jar verifier as well. manifest = new Manifest(metaEntries.get(MANIFEST_NAME), true); verifier = new JarVerifier(getName(), manifest, metaEntries); } else { verifier = null; manifestBytes = metaEntries.get(MANIFEST_NAME); } } Yeah, that's the difference! As we know, the APK file must be signed, and the JarFile class will verify this.
I will not go further if you want to understand how verification works, see here: https://android.googlesource.com/platform/libcore/+/android-6.0.1_r21/luni/src/main/java/java/util / jar / .
But what needs to be said is that this is a very very slow process.
Conclusion
When ClassLoader.getResourceAsStream () is called for the first time, the APK file opens as a zip file to find the resource. After that, it opens a second time, but with verification to open the InputStream. It also explains why there is such a big difference in call speed for different applications, it all depends on the size of the APK file and how many files are inside!
One more thing
If in nimbledroid in the Full Stack Trace section in the upper right corner you click on the Expand Android Framework , you will see all the methods we went through:
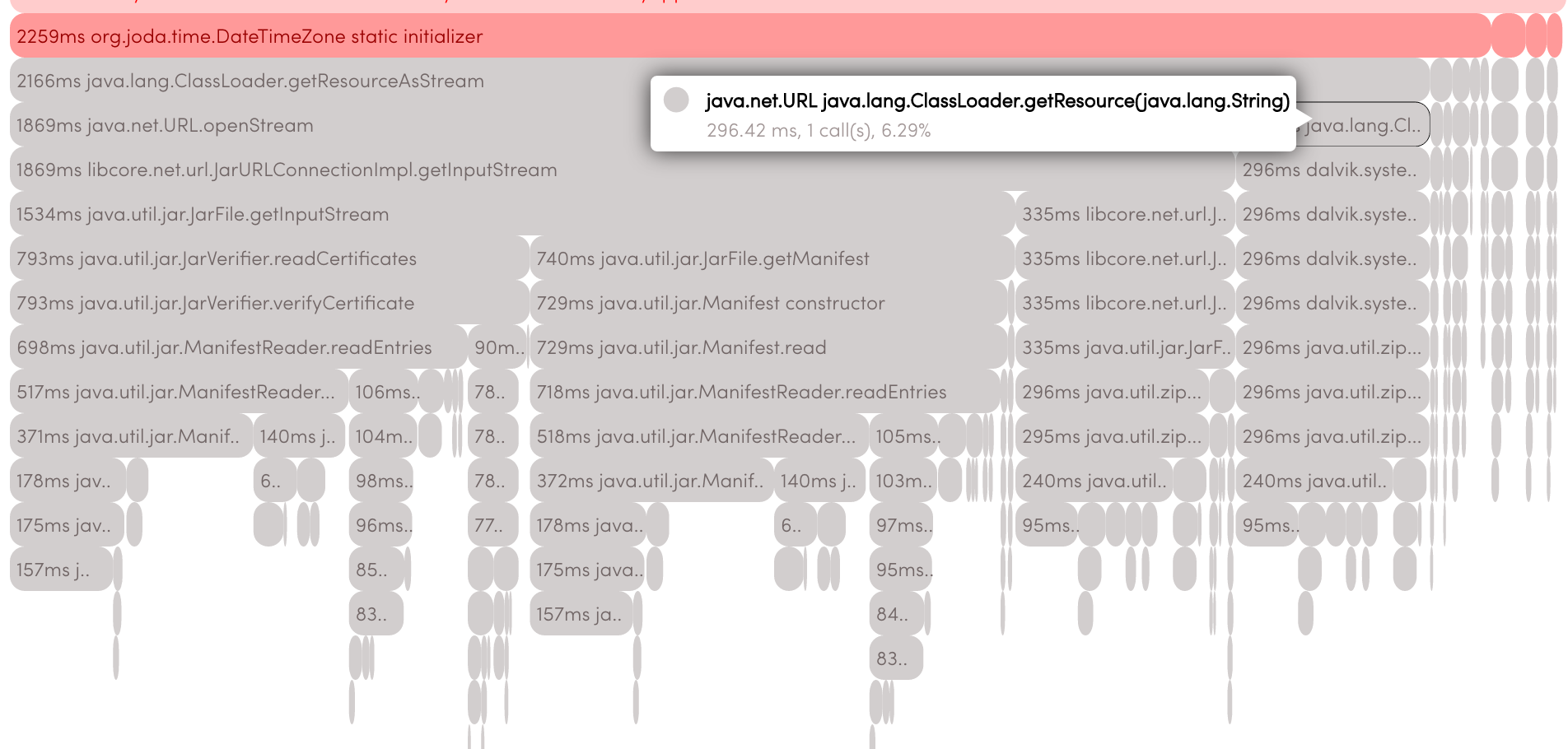
Q & A
Q: Is there any difference between the Dalvik and ART runtime and the work of the getResourceAsStream () call
A: Actually, no, I checked several AOSP branches android-6.0.1_r11 with ART and android-4.4.4_r2 with Dalvik. The problem is in both!
The difference between them is slightly different, but much has been written about this :)
Q: Why is there no such problem when calling ClassLoader.findClass ()
A: If we move to the class DexPathList , which is already familiar to us, we will see:
public Class findClass(String name, List<Throwable> suppressed) { for (Element element : dexElements) { DexFile dex = element.dexFile; if (dex != null) { Class clazz = dex.loadClassBinaryName(name, definingContext, suppressed); if (clazz != null) { return clazz; } } } if (dexElementsSuppressedExceptions != null) { suppressed.addAll(Arrays.asList(dexElementsSuppressedExceptions)); } return null; } Following the call chain we will come to the method:
private static native Class defineClassNative(String name, ClassLoader loader, Object cookie) throws ClassNotFoundException, NoClassDefFoundError; And then how it will work will depend on the runtime (ART or Dalvik), but as we see, no work with ZipFile .
Q: Why calls to Resources.get ... (resId) do not have this problem
A: For the same reason as ClassLoader.findClass ().
All these calls will lead us to /frameworks/base/core/java/android/content/res/AssetManager.java
/** Returns true if the resource was found, filling in mRetStringBlock and * mRetData. */ private native final int loadResourceValue(int ident, short density, TypedValue outValue, boolean resolve); Thanks for attention! Happy coding!
Source: https://habr.com/ru/post/280340/
All Articles