How to clean up the mailbox using a neural network. Part 2

In our blog, we write a lot about creating emails and working with e-mail. In the modern world, people get a lot of letters, and in full growth there is a problem with their classification and ordering of the mailbox. An engineer from the USA, Andrei Kurenkov, in his blog told about how he solved this task using a neural network. We decided to highlight the course of this project - a few days ago we published the first part of the story , and today we present to you its continuation.
Deep learning is not suitable here.
When Kurenkov first began to study the Keras code, he thought (erroneously) that he would use a sequence reflecting the actual word order in the texts. It turned out that this is not the case, but this does not mean that such an option is impossible. What is really worth noting in the field of machine learning is recurrent neural networks that are great for working with large data sequences, the author writes. This approach implies that when working with words, a “preparatory” step is performed, in which each word is converted into a numerical vector, so that similar words are transformed into similar vectors.
')
Thanks to this, instead of converting letters into matrices of binary features, you can simply replace words with numbers, using the frequencies of their appearance in letters, and the numbers themselves with vectors reflecting the “meaning” of each word. Then it becomes possible to use the resulting sequence to train a recurrent neural network such as Long Short Term Memory or Gated Recurrent. And this approach has already been implemented : you can simply run an example and see what happens:
Epoch 1/15 7264/7264 [===========================] - 1330s - loss: 2.3454 - acc: 0.2411 - val_loss: 2.0348 - val_acc: 0.3594 Epoch 2/15 7264/7264 [===========================] - 1333s - loss: 1.9242 - acc: 0.4062 - val_loss: 1.5605 - val_acc: 0.5502 Epoch 3/15 7264/7264 [===========================] - 1337s - loss: 1.3903 - acc: 0.6039 - val_loss: 1.1995 - val_acc: 0.6568 ... Epoch 14/15 7264/7264 [===========================] - 1350s - loss: 0.3547 - acc: 0.9031 - val_loss: 0.8497 - val_acc: 0.7980 Epoch 15/15 7264/7264 [===========================] - 1352s - loss: 0.3190 - acc: 0.9126 - val_loss: 0.8617 - val_acc: 0.7869 Test score: 0.861739277323
Accuracy: 0.786864931846
Training took forever, and the result was far from being so good. Presumably, the reason may be that there was little data, and the sequences are generally not sufficiently effective to categorize them. This means that the increased complexity of learning in sequences does not pay off with the advantage of processing words of the text in the correct order (after all, the sender and certain words in the letter show well what category it belongs to).
But the additional “preparatory” step still seemed useful to the engineer because it created a wider idea of the word. Therefore, he considered it worthwhile to try to use it by connecting the convolution to search for important local features. And again there was an example of Keras, which performs the preparatory step and at the same time transfers the obtained vectors to the layers of convolution and subsampling instead of the LSTM layers. But the results are not impressive again:
Epoch 1/3 5849/5849 [===========================] - 127s - loss: 1.3299 - acc: 0.5403 - val_loss: 0.8268 - val_acc: 0.7492 Epoch 2/3 5849/5849 [===========================] - 127s - loss: 0.4977 - acc: 0.8470 - val_loss: 0.6076 - val_acc: 0.8415 Epoch 3/3 5849/5849 [===========================] - 127s - loss: 0.1520 - acc: 0.9571 - val_loss: 0.6473 - val_acc: 0.8554 Test score: 0.556200767488
Accuracy: 0.858725761773
The engineer really hoped that learning using sequences and preparatory steps would prove better than the N-gram model, since in theory the sequences contain more information about the letters themselves. But the widespread belief that in-depth training is not very effective for small data sets turned out to be fair.
All because of the signs, you fool
So, the tests carried out did not give the desired accuracy of 90% ... As you can see, the current approach to determining signs of 2500 most frequently encountered words is not suitable, since it includes such common words as “I” or “what” along with useful category-specific words like "home". But it’s risky to just remove popular words or reject any sets of words — you never know what will be useful for identifying signs, because perhaps I sometimes use this or that “simple” word in one of the categories more often than in others (for example in the section "Personal").
Here we should move from guessing to using the method of selecting signs to select words that are really good, and filter words that do not work. For this, it is easiest to use scikit and its SelectKBest class, which is so fast that selection takes minimal time compared to the operation of a neural network. So does this help?
Dependence of test accuracy on the number of words processed:
Works - 90%!
Fine! Despite the slight differences in the final performance, it is clearly better to start with a larger set of words. However, this set can be quite reduced with the help of feature selection and without losing performance. Apparently, this neural network has no problems with retraining. Consideration of the “best and worst” words according to the version of the program confirms that it defines them well enough:
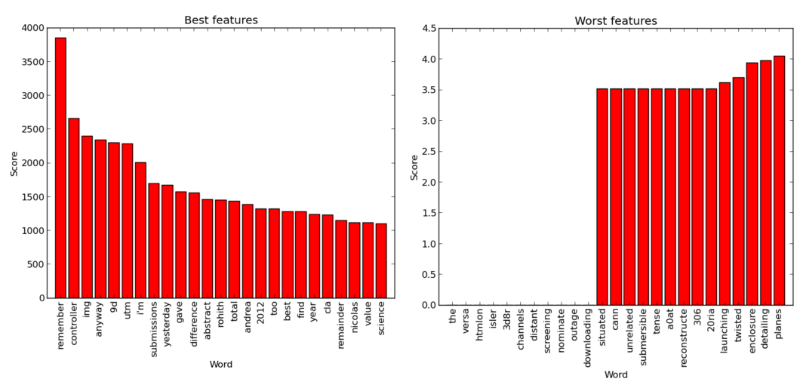
“Best” and “worst” words: feature selection using chi-square test (based on the code from the scikit example )
Many “good” words, as one would expect, are names or specific terms (for example, “controller”), although Kurenkov says that some words like “remember” or “total” would not have chosen. “Worst” words, on the other hand, are quite predictable, as they are either too general or too rare.
To summarize: the more words, the better, and the selection of signs can help to make work faster. It helps, but perhaps there is a way to further improve the test results. To find out, the engineer decided to take a look at what mistakes the neural network makes using the error matrix, also taken from scikit learn :
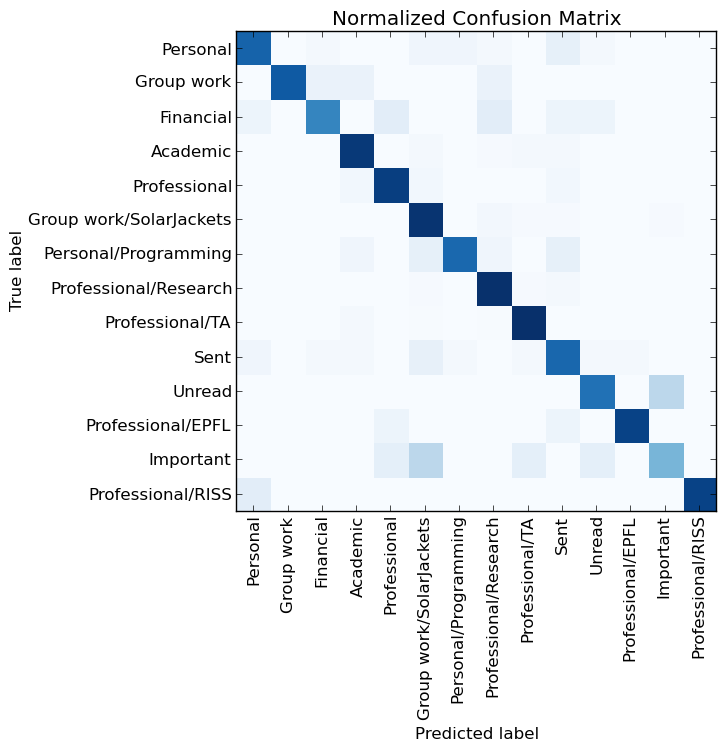
Error Matrix for Neural Network Performance
Great, most of the color blocks are located diagonally, however there are several other “annoying spots”. In particular, on the visualization, the categories “Unread” and “Important” are marked as problematic. But wait! I did not create these categories, and I don’t care how well the system handles them as well as the Sent category. Sure, I have to remove them and see how well the neural network works with the categories I created.
Therefore, let's conduct the last experiment, in which all inappropriate categories are missing, and where the most signs will be used - 10,000 words with a selection of 4,000 best:
Epoch 1/5 5850/5850 [==============================] - 2s - loss: 0.8013 - acc: 0.7879 - val_loss: 0.2976 - val_acc: 0.9369 Epoch 2/5 5850/5850 [==============================] - 1s - loss: 0.1953 - acc: 0.9557 - val_loss: 0.2322 - val_acc: 0.9508 Epoch 3/5 5850/5850 [==============================] - 1s - loss: 0.0988 - acc: 0.9795 - val_loss: 0.2418 - val_acc: 0.9338 Epoch 4/5 5850/5850 [==============================] - 1s - loss: 0.0609 - acc: 0.9865 - val_loss: 0.2275 - val_acc: 0.9462 Epoch 5/5 5850/5850 [==============================] - 1s - loss: 0.0406 - acc: 0.9925 - val_loss: 0.2326 - val_acc: 0.9462 722/722 [==============================] - 0s Test score: 0.243211859068
Accuracy: 0.940443213296
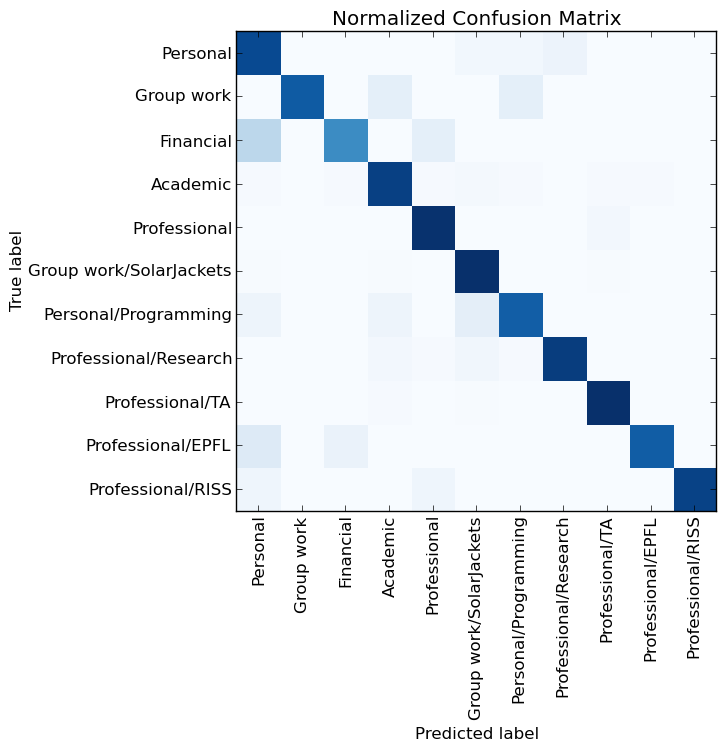
Error Matrix for New Neural Network Results
That's it! The neural network can guess categories with 94% accuracy. Although the effect is primarily due to a large set of features, a good classifier (the scikit learn Passive Agressive classifier) and by itself gives 91% accuracy on the same input data. In fact, there are ideas that, in this case, the support vector machine (LinearSVC) method can also be effective; using it, one can also obtain approximately 94% accuracy.
So, the conclusion is quite simple - “trendy” machine learning methods are not particularly effective on small data sets, and the old N-gram + TF-IFD + SVM approaches can work as well as modern neural networks. In short, the use of the Bag of Words method will work quite well, provided that there are few letters and they are sorted as clearly as in the example above.
Perhaps few people use categories in gmail, but if you really create a good classifier so simply, it would be nice if gmail had a machine-learning system that defines the category of each letter for organizing mail in one click. At this stage, Kurenkov was very pleased that he improved his own results by 20% and met Keras in the process.
Epilogue: Additional Experiments
While working on his experiment, the engineer did something else. He ran into a problem: all the calculations were carried out for a long time, mostly because the author of the material did not use the now common trick of running machine learning using the GPU. Following excellent leadership , he did it and got great results:
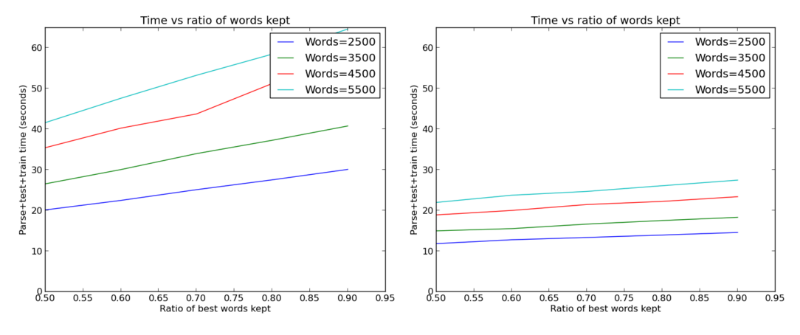
The time spent on achieving the above 90% with or without a graphics processor; great acceleration!
It should be noted that the Keras neural network, which demonstrates 94% accuracy, was much faster to train (and work with it) than the network, which is trained on the basis of the support vector machine; The first was the best solution of all that I tried.
The engineer wanted to visualize something else besides the error matrices. In this respect, little has been achieved with Keras, although the author came across a discussion of visualization issues . This led me to Keras fork with a good option to display the learning process. He is not very effective, but curious. After a small change, he generated excellent learning schedules:
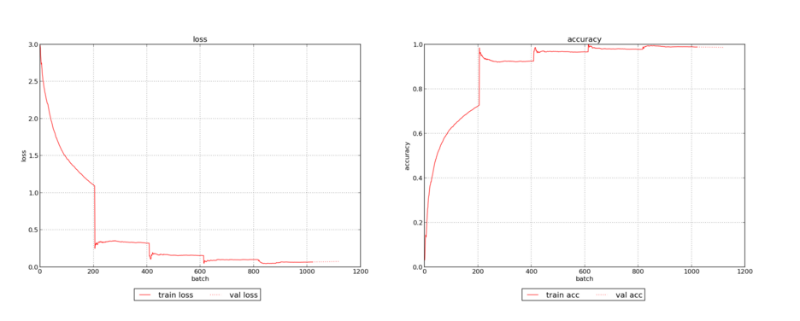
The neural network learning progress on a slightly modified example (with a large number of words being processed)
It clearly shows how the accuracy of training tends to unity and is aligned.
Not bad, but the engineer was more worried about the increase in accuracy. As before, the first thing he asked was: “Is it possible to quickly change the presentation of features to help the neural network?” The Keras module, which transforms text into matrices, has several options besides creating binary matrices: matrices with word counters, frequencies, or TF values -Idf.
It was also easy to change the number of words stored in the matrices in the form of features, so Kurenkov wrote several cycles evaluating how the type of features and the number of words affect the accuracy of the tests. The result was an interesting schedule:
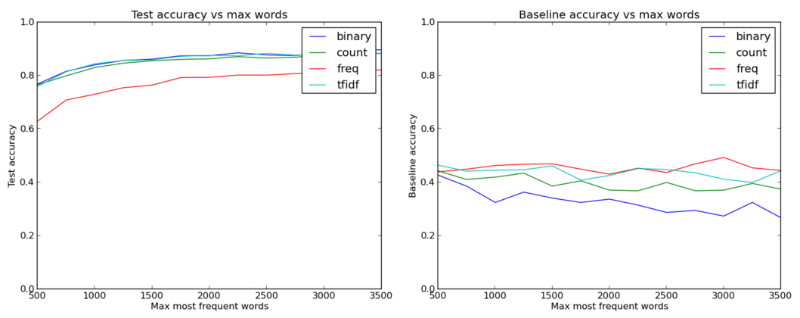
Accuracy of the test depending on the type of features and how many words are taken as features (the basic accuracy takes into account the k nearest “neighbors”)
Here, for the first time, it became clear that we need to increase the number of words to a value in excess of 1,000. It was also interesting to see that the type of features, which is characterized by simplicity and lowest information density (binary), turned out to be no worse and even better than other types that convey more information about data .
Although it is quite predictable - most likely, more interesting words like “code” or “grade” are useful for categorizing letters, and their single appearance in the letter is just as important as the greater number of mentions. Without a doubt, the presence of informative features may be useful, but it may also lower test results due to the increased likelihood of retraining.
In general, we see that binary signs showed themselves better than others and that increasing the number of words perfectly helps to achieve 87% -88% accuracy.
Inzener also reviewed the basic algorithms to make sure that something like the k-nearest-neighbor method ( scikit ) is not (in terms of efficiency) equivalent to neural networks - this turned out to be true. Linear regression worked even worse, so the choice of neural networks is quite reasonable.
An increase in the number of words, by the way, is not in vain. Even with the cached version of the data, when it was not necessary to parse mail every time and extract the signs, the launch of all these tests took a lot of time:
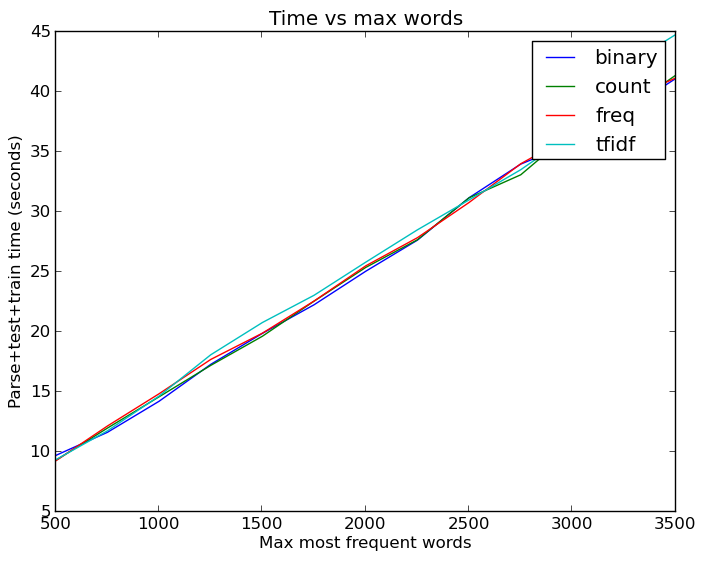
Linear dependence of the growth of time on the number of words. Actually not bad, linear regression was much worse.
The increase in the number of words helped, but the experimenter still could not reach the desired threshold of 90%. Therefore, the next thought was to stick to 2,500 words and try to change the size of the neural network. In addition, as it turned out, the model from the example of Keras has a 50% dropout regularization on a hidden layer: the engineer was interested to see if this really increases the efficiency of the network. He launched another set of cycles and got another great schedule:
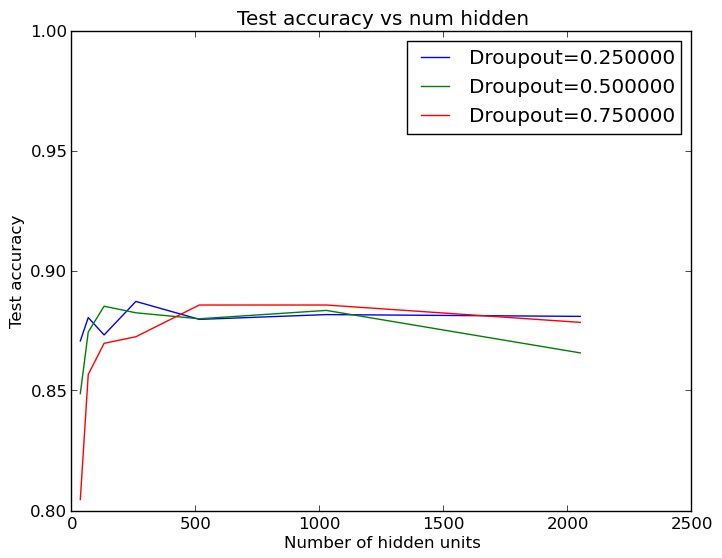
Graph of accuracy changes for different variants of dropout regularization and sizes of the hidden layer
It turns out that the size of the hidden layer does not have to be large enough for everything to work as it should! 64 or 124 neurons in the hidden layer can perform the task as well as the standard 512. These results, by the way, are averaged over five runs, so that the small scatter in the output data is not related to the capabilities of the small hidden layers.
From this it follows that a large number of words are needed only to identify useful signs, but there are not so many useful signs themselves - otherwise more neurons would be required for a better result. This is good, because we can save a lot of time using smaller hidden layers:
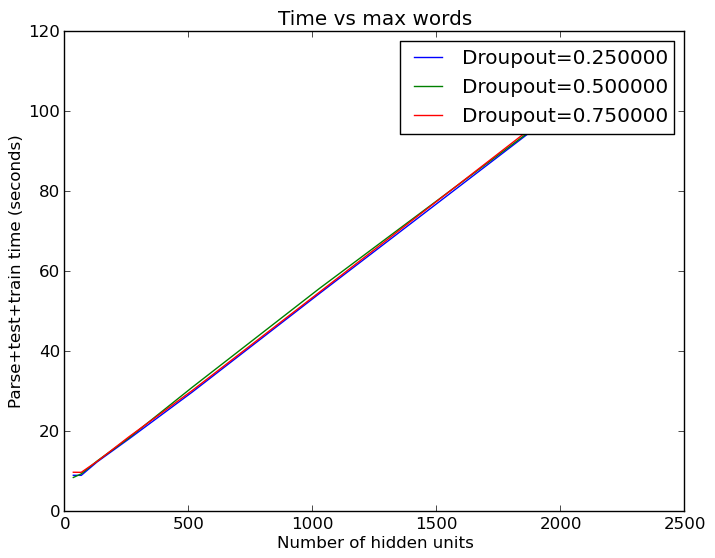
And again, the computation time grows linearly with increasing neurons in the hidden layer
But this is not entirely accurate. Having performed more launches with more signs, the engineer found that the standard size of the hidden layer (512 neurons) works much better than the smaller hidden layers:
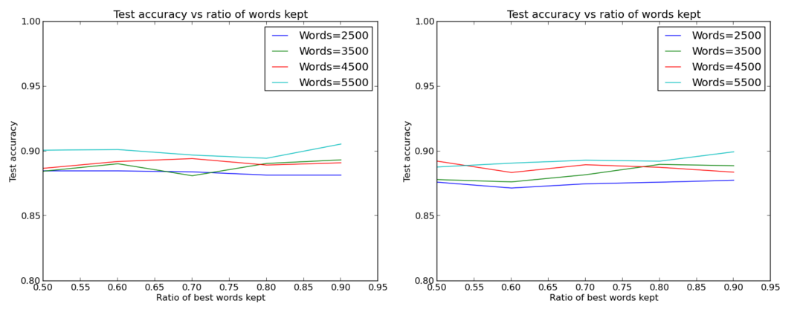
Comparison of the performance of layers with 512 and 32 neurons, respectively
It remains only to state what was already known: the more words, the better.
Source: https://habr.com/ru/post/280296/
All Articles