Web Scraping with python
Introduction
Having recently looked at KinoPoisk, I discovered that over the years I managed to leave more than 1000 ratings and thought that it would be interesting to investigate this data in more detail: did my tastes in the cinema change over time? Is there an annual / weekly seasonality in activity? Do my ratings correlate with a KinoPoisk rating, IMDb or film critics?
But before you analyze and build beautiful graphics, you need to get the data. Unfortunately, many services (and KinoPoisk is not an exception) do not have a public API, so you have to roll up your sleeves and parse html pages. It is about how to download and parse the website, and I want to tell you in this article.
First of all, the article is intended for those who always wanted to deal with Web Scrapping, but did not reach out or did not know where to start.
Off-topic : by the way, New Film Search under the hood uses queries that return evaluation data in the form of JSON, so the task could be solved in a different way.
Task
The task will be to upload data about the films viewed at KinoPoisk: the name of the film (Russian, English), the date and time of viewing, the rating of the user.
In fact, you can divide the work into 2 stages:
- Stage 1: unload and save html pages
- Stage 2: parse html into a convenient format for further analysis (csv, json, pandas dataframe etc.)
Instruments
There are quite a few python libraries to send http requests, the most famous urllib / urllib2 and Requests. For my taste, Requests are more convenient and more concise, so I will use it.
You also need to select a library for parsing html, a small research gives the following options:
- re
Regular expressions, of course, will be useful to us, but to use only them, in my opinion, is too hardcore, and they are not a little for that . More convenient tools for parsing html were invented, so let's move on to them. - BeatifulSoup , lxml
These are the two most popular libraries for parsing html and the choice of one of them, rather, is due to personal preferences. Moreover, these libraries are closely intertwined: BeautifulSoup began to use lxml as an internal parser for acceleration, and the module soupparser was added to lxml. More about the pros and cons of these libraries can be found in the discussion . For comparison, I will parse the data using BeautifulSoup and using XPath selectors in the lxml.html module. - scrapy
This is no longer just a library, but a whole open-source framework for retrieving data from web pages. It has many useful functions: asynchronous requests, the ability to use XPath and CSS selectors for data processing, convenient work with encodings and much more (you can read more here ). If my task was not a one-time download, but a production process, then I would choose it. In the current production, this is overkill.
Data loading
First try
Let's start to upload data. To begin with, let's just try to get the page by url and save it to a local file.
import requests user_id = 12345 url = 'http://www.kinopoisk.ru/user/%d/votes/list/ord/date/page/2/#list' % (user_id) # url r = requests.get(url) with open('test.html', 'w') as output_file: output_file.write(r.text.encode('cp1251')) Open the resulting file and see that everything is not so simple: the site has recognized the robot in us and is not in a hurry to show the data.

We will understand how the browser works
However, the browser is great at getting information from the site. Let's see how it sends the request. To do this, use the "Network" panel in the "Developer Tools" in the browser (I use Firebug for this), the request we usually need is the longest.
')
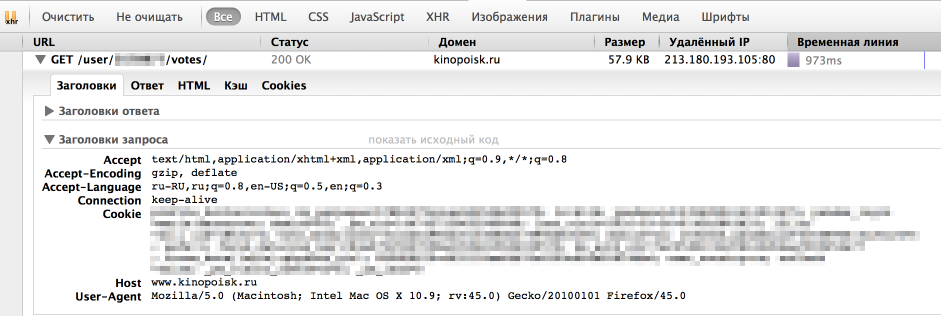
As we can see, the browser also passes in headers UserAgent, a cookie and a number of other parameters. For a start, let's just try to pass the correct UserAgent to the header.
headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:45.0) Gecko/20100101 Firefox/45.0' } r = requests.get(url, headers = headers) At this time everything turned out, now we are given the necessary data. It is worth noting that sometimes the site also checks the correctness of the cookie, in which case sessions in the Requests library will help.
Download all ratings
Now we can save one page with ratings. But usually the user has a lot of ratings and you need to iterate through all the pages. The page number we are interested in can be easily transferred directly to the url. There remains only the question: "How to understand how many pages with ratings?" I solved this problem as follows: if you specify an oversized page number, then such a page without a table with films will return to us. Thus, we can iterate over the pages for as long as there is a block with movie ratings (
<div class = "profileFilmsList"> ).
Full data download code
import requests # establishing session s = requests.Session() s.headers.update({ 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:45.0) Gecko/20100101 Firefox/45.0' }) def load_user_data(user_id, page, session): url = 'http://www.kinopoisk.ru/user/%d/votes/list/ord/date/page/%d/#list' % (user_id, page) request = session.get(url) return request.text def contain_movies_data(text): soup = BeautifulSoup(text) film_list = soup.find('div', {'class': 'profileFilmsList'}) return film_list is not None # loading files page = 1 while True: data = load_user_data(user_id, page, s) if contain_movies_data(data): with open('./page_%d.html' % (page), 'w') as output_file: output_file.write(data.encode('cp1251')) page += 1 else: break Parsing
A little bit about XPath
XPath is a language for querying xml and xhtml documents. We will use XPath selectors when working with the lxml library ( documentation ). Consider a small example of working with XPath
from lxml import html test = ''' <html> <body> <div class="first_level"> <h2 align='center'>one</h2> <h2 align='left'>two</h2> </div> <h2>another tag</h2> </body> </html> ''' tree = html.fromstring(test) tree.xpath('//h2') # h2 tree.xpath('//h2[@align]') # h2 align tree.xpath('//h2[@align="center"]') # h2 align "center" div_node = tree.xpath('//div')[0] # div div_node.xpath('.//h2') # h2 , div You can also read more about XPath syntax at W3Schools .
Let's return to our task.
Now let's go directly to getting data from html. The easiest way to understand how the html-page is arranged using the function "Inspect element" in the browser. In this case, everything is quite simple: the entire table with estimates is enclosed in the
<div class = "profileFilmsList"> . Select this node: from bs4 import BeautifulSoup from lxml import html # Beautiful Soup soup = BeautifulSoup(text) film_list = soup.find('div', {'class': 'profileFilmsList'}) # lxml tree = html.fromstring(text) film_list_lxml = tree.xpath('//div[@class = "profileFilmsList"]')[0] Each movie is presented as
<div class = "item"> or <div class = "item even"> . Consider how to pull out the Russian title of the film and the link to the film page (also learn how to get the text and the value of the attribute).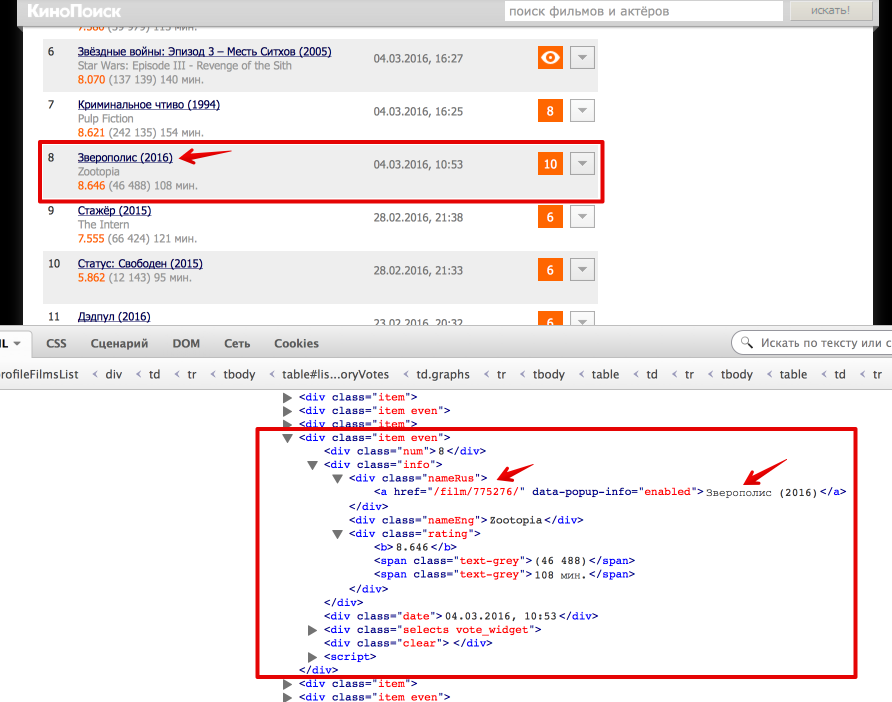
# Beatiful Soup movie_link = item.find('div', {'class': 'nameRus'}).find('a').get('href') movie_desc = item.find('div', {'class': 'nameRus'}).find('a').text # lxml movie_link = item_lxml.xpath('.//div[@class = "nameRus"]/a/@href')[0] movie_desc = item_lxml.xpath('.//div[@class = "nameRus"]/a/text()')[0] Another small hint for debug: in order to see that inside the selected node in BeautifulSoup, you can simply print it, and in the lxml use the
tostring() function of the tostring() module. # BeatifulSoup print item #lxml from lxml import etree print etree.tostring(item_lxml) Full code for parsing html-files under the cut
def read_file(filename): with open(filename) as input_file: text = input_file.read() return text def parse_user_datafile_bs(filename): results = [] text = read_file(filename) soup = BeautifulSoup(text) film_list = film_list = soup.find('div', {'class': 'profileFilmsList'}) items = film_list.find_all('div', {'class': ['item', 'item even']}) for item in items: # getting movie_id movie_link = item.find('div', {'class': 'nameRus'}).find('a').get('href') movie_desc = item.find('div', {'class': 'nameRus'}).find('a').text movie_id = re.findall('\d+', movie_link)[0] # getting english name name_eng = item.find('div', {'class': 'nameEng'}).text #getting watch time watch_datetime = item.find('div', {'class': 'date'}).text date_watched, time_watched = re.match('(\d{2}\.\d{2}\.\d{4}), (\d{2}:\d{2})', watch_datetime).groups() # getting user rating user_rating = item.find('div', {'class': 'vote'}).text if user_rating: user_rating = int(user_rating) results.append({ 'movie_id': movie_id, 'name_eng': name_eng, 'date_watched': date_watched, 'time_watched': time_watched, 'user_rating': user_rating, 'movie_desc': movie_desc }) return results def parse_user_datafile_lxml(filename): results = [] text = read_file(filename) tree = html.fromstring(text) film_list_lxml = tree.xpath('//div[@class = "profileFilmsList"]')[0] items_lxml = film_list_lxml.xpath('//div[@class = "item even" or @class = "item"]') for item_lxml in items_lxml: # getting movie id movie_link = item_lxml.xpath('.//div[@class = "nameRus"]/a/@href')[0] movie_desc = item_lxml.xpath('.//div[@class = "nameRus"]/a/text()')[0] movie_id = re.findall('\d+', movie_link)[0] # getting english name name_eng = item_lxml.xpath('.//div[@class = "nameEng"]/text()')[0] # getting watch time watch_datetime = item_lxml.xpath('.//div[@class = "date"]/text()')[0] date_watched, time_watched = re.match('(\d{2}\.\d{2}\.\d{4}), (\d{2}:\d{2})', watch_datetime).groups() # getting user rating user_rating = item_lxml.xpath('.//div[@class = "vote"]/text()') if user_rating: user_rating = int(user_rating[0]) results.append({ 'movie_id': movie_id, 'name_eng': name_eng, 'date_watched': date_watched, 'time_watched': time_watched, 'user_rating': user_rating, 'movie_desc': movie_desc }) return results Summary
As a result, we learned how to parse web-sites, got acquainted with the libraries of Requests, BeautifulSoup and lxml, and also received data suitable for further analysis about watched films on KinoPoisk.

The complete project code can be found on github'e .
UPD
As noted in the comments , the following topics may be useful in the context of Web Scrapping:
- Authentication: often in order to obtain data from the site you need to pass authentication, in the simplest case it is just HTTP Basic Auth: login and password. Here the Requests library will help us again. In addition, oauth2 is widespread: how to use oauth2 in python can be read on stackoverflow . Also in the comments there is an example from Terras of how to authenticate in a web form.
- Controls: The site can also have additional web-forms (drop-down lists, check boxes, etc.). The algorithm for working with them is about the same: we look at what the browser sends and send the same parameters as data to a POST request ( Requests , stackoverflow ). I can also recommend to see the 2nd lesson of the course "Data Wrangling" at Udacity , where an example of scrapping the site of the US Department of Transportation and sending the data of web forms is described in detail.
Source: https://habr.com/ru/post/280238/
All Articles