How to clean up the mailbox using a neural network. Part 1
In our blog, we write a lot about creating emails and working with e-mail. We have already discussed the complexity of the fight against spam , the future of email, the protection of postal correspondence , as well as the techniques of working with email , used by the leaders of large IT companies.
In the modern world, people get a lot of letters, and in full growth there is a problem with their classification and ordering of the mailbox. An engineer from the USA, Andrei Kurenkov, in his blog told about how he solved this task using a neural network. We decided to highlight the course of this project and present you the first part of the story.
')
The project code is available here .
Start
Kurenkov writes that one of his favorite mini-projects, EmailFiler , appeared due to the assignment on the course “Introduction to machine learning” at the Georgia Institute of Technology. The task was to take any data set, apply to it a number of controlled learning algorithms and analyze the results. The bottom line is that you could use your own data if desired. The developer did just that - exported his gmail data to investigate the capabilities of machine learning in solving the problem of email sorting.
Kurenkov writes that he long ago understood that it is better to always have e-mails on hand in case you ever need to contact them. On the other hand, he always wanted to reduce the number of unread incoming messages to zero, no matter how hopeless this idea was. Therefore, many years ago, an engineer began sorting emails by about a dozen folders, and by the time they entered machine learning courses, thousands of letters had accumulated in these folders.
Thus, the idea of a project to create a classifier, which could offer a single category for each incoming letter, appeared - so as to send a letter to the appropriate folder at the touch of a button.

Categories (folders) and the number of letters in each of them at the time of the start of the project
Letters were the input data, the categories of letters were included in the output data. The difficulty was that the developer wanted to use letter texts and metadata, but it was not easy to understand how to turn all this into a machine-readable data set.
Anyone who has studied the processing of natural languages will immediately suggest one simple approach — the use of the Bag of Words model. This is one of the simplest text classification algorithms — find N common words for all texts and create a table of binary signs for each word (sign is 1 if the given text contains a word, and 0 if it does not).
Kurenkov did this for a group of words found in all his letters, as well as for the top 20 senders of letters (as in some cases the sender strictly correlates with the category of the letter; for example, if the sender is the supervisor at the university, the category will be “Research” ) and for the top 5 domains from which letters were sent to him (since domains like gatech .edu strictly indicate categories such as, for example, “Training”). So, somewhere after an hour spent writing an email parser , he was able to receive data about his mailbox in csv format (values separated by commas).
How well did it all work? Not bad, but I wanted more. Kurenkov says that he was fond of the Orange ML machine learning framework for Python, and, as was the case for his assignment, tested several algorithms on his data set. Two algorithms stood out - decision trees showed themselves best of all, and neural networks worst of all:

So a small set of data coped decision trees

And so - neural networks
If you take a close look at these graphs from OpenOffice Calc, you can see that the best result of decision trees on the test is about 72%, and the neural networks are a measly 65%. Horror! This, of course, is better than expanding everything at random, given that there are 11 categories, but far from an excellent result.
Why were the results so depressing? The fact is that the signs obtained for the data set turned out to be very primitive - a simple search for the 500 most frequent words in letters will give us not too many useful indicators, but many commonly used constructions that are found in English, for example, “that” or “ is. " The engineer understood this and did the following: completely removed the words from three or less letters from the list and wrote some code to select the most common words for each category separately; but he still had no idea how to improve the result.
Attempt number two
After a couple of years, Kurenkov decided once again to try to solve the problem - even though the project at the university had already been delivered for a long time, I wanted to improve the results.
This time, the engineer decided to use Keras as one of the main tools, because it is written in Python and also gets along well with the NumPy , pandas and scikit-learn packages and is supported by Theano library.
In addition, it turned out that Keras has several easy examples in which to begin work, including the task of classifying various texts. And what is interesting is that this example uses the same functions that the engineer used earlier. It identifies the 1000 most common words in documents, binary signs, and trains a neural network with one hidden layer and dropout-regularization to predict the category of a given text based solely on these signs.
So, the first thing that comes to mind is to try this example on your own data - to see if Keras will improve the work. Fortunately, the old code for parsing the mailbox has been preserved, and Keras has a convenient Tokenizer class for receiving text attributes. Therefore, you can easily create a data set in the same format as in the example and get new information about the current number of emails:
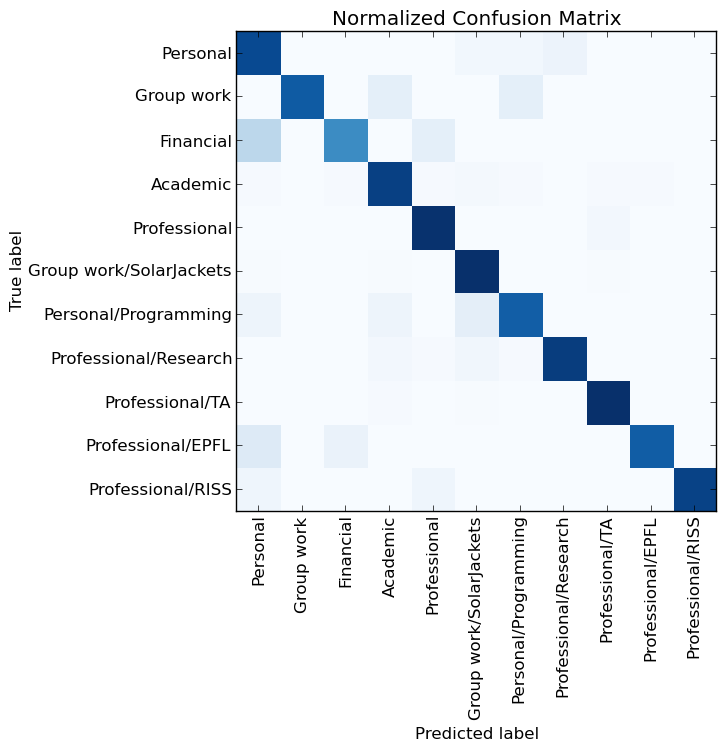
Using theano backend. Label email count breakdown: Personal: 440 Group work: 150 Financial: 118 Academic: 1088 Professional: 388 Group work / SolarJackets: 1535 Personal / Programming: 229 Professional / Research: 1066 Professional / TA: 1801 Sent: 513 Unread: 146 Professional / EPFL: 234 Important: 142 Professional / RISS: 173 Total emails: 8023
Eight thousand letters can not be called a large set of data, but still this is enough to work a little serious machine learning. After translating the data into the desired format, it remains only to see if the neural network training works on this data. An example using Keras makes it easy to do the following:
7221 train sequences 802 test sequences Building model ... Train on 6498 samples, validate on 723 samples Epoch 1/5 6498/6498 [==============================] - 2s - loss: 1.3182 - acc: 0.6320 - val_loss: 0.8166 - val_acc: 0.7718 Epoch 2/5 6498/6498 [==============================] - 2s - loss: 0.6201 - acc: 0.8316 - val_loss: 0.6598 - val_acc: 0.8285 Epoch 3/5 6498/6498 [==============================] - 2s - loss: 0.4102 - acc: 0.8883 - val_loss: 0.6214 - val_acc: 0.8216 Epoch 4/5 6498/6498 [==============================] - 2s - loss: 0.2960 - acc: 0.9214 - val_loss: 0.6178 - val_acc: 0.8202 Epoch 5/5 6498/6498 [==============================] - 2s - loss: 0.2294 - acc: 0.9372 - val_loss: 0.6031 - val_acc: 0.8326 802/802 [==============================] - 0s Test score: 0.585222780162
Accuracy: 0.847880299252
85% accuracy! This is much higher than the measly 65% of the old neural network. Fine.
But why?
The old code did, in general, the following - defined the most common words, created a binary matrix of attributes and trained a neural network with one hidden layer. Maybe all this is due to the new “relu” neuron, the dropout regularization, and the use of optimization methods other than the stochastic gradient descent? Since the signs found on the old data are binary and presented in the form of a matrix, they are very easy to turn into a data set for training this neural network. So, here are the results:
Epoch 1/5 6546/6546 [==============================] - 1s - loss: 1.8417 - acc: 0.4551 - val_loss: 1.4071 - val_acc: 0.5659 Epoch 2/5 6546/6546 [==============================] - 1s - loss: 1.2317 - acc: 0.6150 - val_loss: 1.1837 - val_acc: 0.6291 Epoch 3/5 6546/6546 [==============================] - 1s - loss: 1.0417 - acc: 0.6661 - val_loss: 1.1216 - val_acc: 0.6360 Epoch 4/5 6546/6546 [==============================] - 1s - loss: 0.9372 - acc: 0.6968 - val_loss: 1.0689 - val_acc: 0.6635 Epoch 5/5 6546/6546 [==============================] - 2s - loss: 0.8547 - acc: 0.7215 - val_loss: 1.0564 - val_acc: 0.6690 808/808 [==============================] - 0s Test score: 1.03195088158
Accuracy: 0.64603960396
So, the old decision to define the categories of emails was unsuccessful. Perhaps the reason was the combination of strong trait limitations (manually defined top senders, domains and words from each category) and too few words.
An example using Keras simply selects the 1000 most common words in a large matrix without additional filtering and transmits it to the neural network. If you do not severely limit the selection of features, more suitable ones can be chosen from them, which increases the overall accuracy of the algorithm.
The reason is either in this or in the presence of errors in the code: changing it in order to make the selection process of signs less restrictive leads to an increase in accuracy of only 70%. In any case, the engineer found out that it was possible to improve your old result using a modern machine learning library.
Now there was a new question - is it possible to achieve even higher accuracy?
To be continued…
Source: https://habr.com/ru/post/280198/
All Articles